如何设计一个高内聚低耦合的模块——MegEngine 中自定义 Op 系统的实践经验
作者:褚超群 | 旷视科技 MegEngine 架构师
背景介绍
在算法研究的过程中,算法同学们可能经常会尝试定义各种新的神经网络层(neural network layer),比如 Layer Norm,Deformable Conv 等。为了实现这些层以进行实验,算法同学可以使用神经网络框架或者 numpy 中提供的基础操作(如张量/标量的加减乘除等)去组合出所需的层的功能。然而这通常会造成这些层的性能断崖式的下跌,大大影响了算法同学们尝试新算法的效率。所以很多情况下,算法同学们会选择为自己定义的层实现高性能的 kernel,并希望可以将之集成入框架作为框架中的 Op(Operator) 使用。
然而在一般情况下,算法同学必须要对框架本身十分了解,才可以灵活自由的将我们的 kernel 接入框架中去使用。但这并不是一件简单的事,神经网络框架作为一个规模庞大的系统,其结构之复杂远超常规的软件项目。为了保证这样的机器学习系统的可维护性以及可拓展性,系统中往往会做各种各样的层次,模块设计,并对各种概念(比如 Op)进行抽象,各个层次各个模块间的交互又非常复杂。
以 MegEngine 中的 Op 系统为例,图 1 中展示 Op 这一最基本的概念在 MegEngine 中不同层的各种抽象。
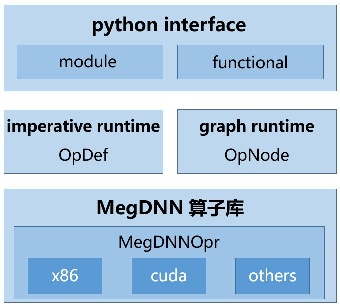
图 1:MegEngine 中不同层次的 Operator 的抽象
- 在底层的 MegDNN 算子库中,Op 被抽象成了 MegDNNOpr 类,其中封装了各个 Op 在 x86,nvidia gpu 等硬件平台上的具体 kernel 实现以及相关硬件的 context 管理。
- 在静态图(graph runtime)中,Op 被抽象成了 OpNode 类,其主要目的并非是用于计算而是图优化,故而这个数据结构的设计上又有了相当多这方面的考量。
- 在动态图(imperative runtime)中,Op 又会被抽象为 OpDef 类,配合动态图解释器进行任务的调度。
- 在 python 中,Op 会被封装成 functional 和 module,这才是符合一般算法同学认知的 Op。
而从 python 中执行一个操作时,这些 Op 会逐层向下调用,分别在每一层完成一部分工作,直到最后才调用了 MegDNN 算子库中具体的 kernel。这个过程中,任何一个层次的 Op 概念都是缺一不可的。其实不只是 Op,包括 Tensor 在内的很多其他概念,在 MegEngine 系统中都存在着类似的多种抽象。学习了解这样的一个框架设计需要花费大量的时间和精力,这个代价往往是算法同学难以接受的。
然而即使算法同学牺牲了大把时间和头发,学习了解了 MegEngine 的系统设计,完成了自己 kernel 到 MegEngine 的集成,事情还远远没有结束。kernel 的集成过程通常与框架本身是高度耦合的。其构建 Op 的过程需要获取框架的所有源码,修改编译框架中的绝大多数模块。如果之后框架内部的相关抽象发生变化,则之前构建的 Op 则又变为不可用的状态。
为了允许把算法同学的 kernel 快速的集成入框架去进行使用,并且集成出来的 Op 既可以与框架内的原生 Op 有着一致的行为,同时其又与框架本身相解耦,MegEngine 提出了一套工具 Custom Op。其可以很简单便捷的将算法同学自己编写的 c++/cuda kernel 封装成 Op 并自动化的编译成动态链接库并集成入 MegEngine 中。
然而,编写高性能的 c++/cuda kernel 对于一般没有体系结构/并行计算背景的算法研究人员依然是一件很困难的事情。所以为了避免算法同学自行编写 kernel 的种种问题,MegEngine 基于 Custom Op 进一步提出了 Custom Op Generator,尝试利用神经网络编译器代码生成的方式去自动化端到端的生成 kernel 和 Custom Op 代码,并将之集成入 MegEngine,使算法同学无需编写任何 c++ 代码,即可在 MegEngine 中添加高性能的 kernel 并使用。
正常的 Op 集成与 Custom Op
为了便于理解 Custom Op 设计,我们首先对传统 Op 的集成过程和 Custom Op 的集成过程进行对比,建立其 Custom Op 的初步印象。
一般而言,我们的算法同学想将自己编写的 c++/cuda kernel 集成为 MegEngine 的 Op,那么他首先必须了解:
- MegEngine 整个的系统结构。
- MegEngine 中各种层次模块的功能。
- 诸如 Op,Tensor 等概念在不同层次模块的设计目的以及实质含义。
在对这样一个系统有了十足了解之后,其需要:
- 在 MegDNN 算子层中对自己的 kernel 进行封装,将之封装成 MegDNNOpr 类。
- 基于 MegEngine 中静态图中的相关组件将自己的 Op 封装成 OpNode 类。
- 基于 MegEngine 中动态图中的相关组件将自己的 Op 封装成 OpDef 类。
- 编写 python 和 C++ 的交互代码,将自己的 Op 暴露到 python 环境中。
而为了简化这个过程,Custom Op 中提供了一套框架无关的十分简洁的 Op 的模型,算法用户在添加 Op 时无需对框架本身做任何了解。其唯一需要做的就是基于这套模型去设置一些 Op 的基本信息,比如 Op 有几个输入输出,调用哪个 kernel 等,从而建立起关于自己 Op 的描述,其画风一般如下代码所示。
CUSTOM_OP_REG(MatMulScale) // 定义一个名为 MatMulScale 的 Op
.add_inputs(2) // 两个输入 Tensor
.add_outputs(1) // 一个输出 Tensor
.add_param("scale", 1.0f) // 一个名为 scale 的 Parameter,默认值为 1.0f
.set_shape_infer(shape_infer) // 设置这个 Op 的 shape 推导函数
.set_compute("cuda", compute); // 设置这个 Op 的 计算函数
而这些设置过程一般使用几行至十几行的代码就可以表达,大大简化了用户集成 kernel 时的工作量。更多的关于 Custom Op 的使用可以参考 MegEngine Custom Op 使用说明。
然后 Custom Op 会自动的将用户的 Op 封装成 MegEngine 中静态图与动态图中的 OpNode 与 OpDef,并为之生成和原生算子一致的 python 接口,从而使用户的 Custom Op 可以与系统中的原生 Op 在接口和底层行为上保持统一。
Custom Op 的设计
Custom Op 同时面向用户(即上述需要编写 kernel 的算法同学)与 MegEngine 系统,使两者可以简单便捷的进行交互。而为了达到这个目的,Custom Op 需要具备以下特性:
- 面向用户,Custom Op 需要提供一套简洁统一的,与框架无关的,且编写 Op 所必须使用的抽象概念。用户可以使用这些抽象接口去将自己的 c++/cuda kernel 封装成 Op。
- 面向系统,Custom Op 需要给 MegEngine 提供一套完备的 Op 的适配与管理工具,从而允许系统对 Custom Op 进行调用及维护管理。
基于此,我们设计出了 Custom Op 的整体架构,如图 2 所示。
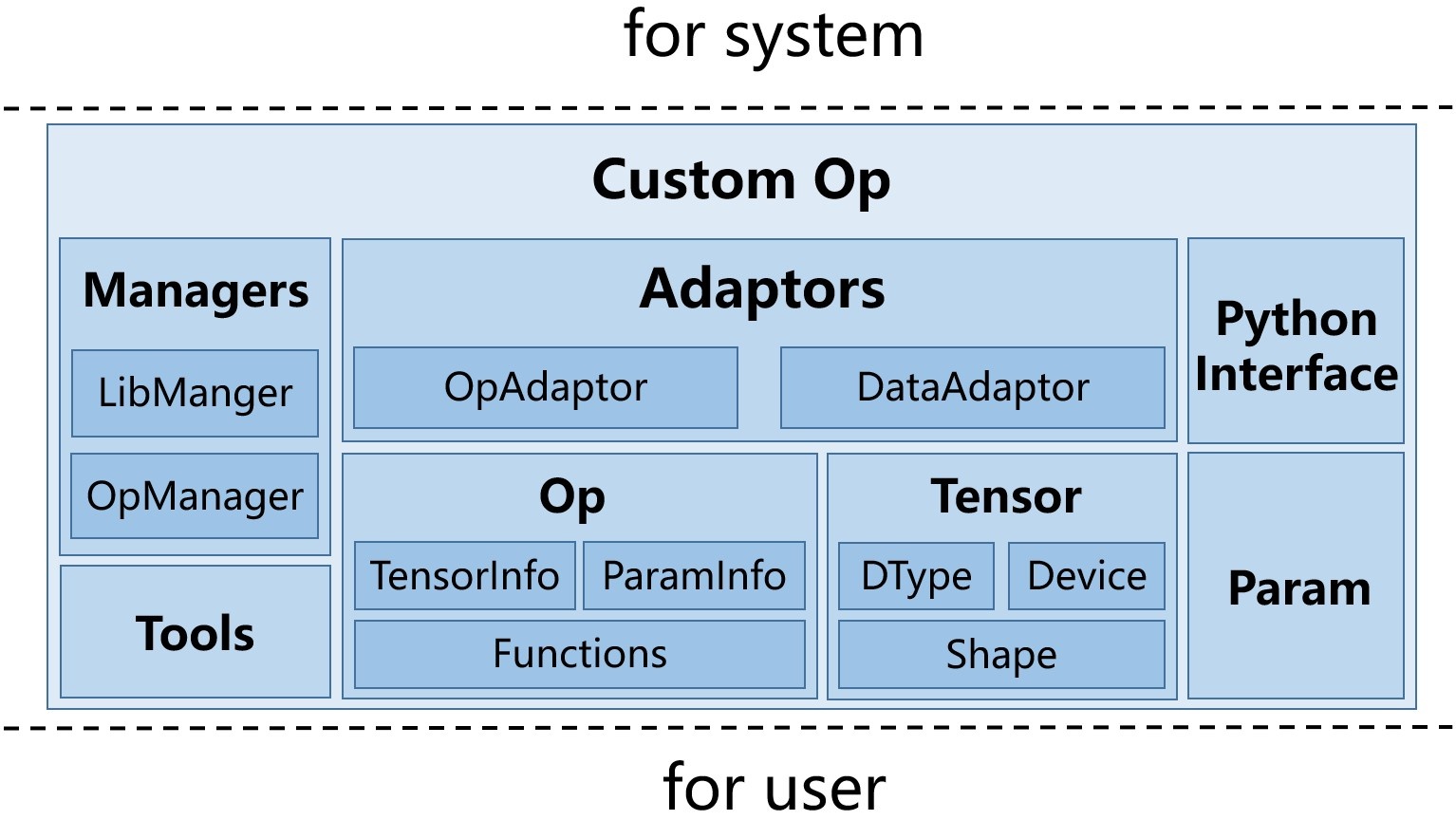
图 2:Custom Op 的整体结构
在一般算法用户的认知里,Op 就是个计算函数,接受一些输入,完成计算,然后得到一些输出。而这里的输入输出又分为张量型数据(即一般的输入输出 Tensor)和非张量型数据(即 Param,比如卷积中的 padding,stride 等等),如图 3 所示。

图 3:用户视角的 Op
为了契合算法用户对于 Op 的认知,Custom Op 主要向用户提供了三个抽象 Tensor,Param 以及 Op。
- Tensor 是 Op kernel 主要计算和操作的对象,与 MegEngine python 中的 Tensor 有着基本一致的抽象和行为。
- Param 是用于记录传输一些 Op 的非张量的输入(比如卷积中的 padding,stride 等等)。
- Op 是对用户的 c++/cuda kernel 计算函数的一个封装,同时记录着这个 Op 的输入输出 Tensor 以及 Param 的信息。
而面向 MegEngine 系统,Custom Op 一方面给 MegEngine 提供了一套完备的 Adaptors,可以根据 MegEngine 系统中不同层次的需要,将用户的 Op 和 Tensor 适配成 MegEngine 的 runtime 可以处理的 Op 和 Tensor。另外一方面,Custom Op 同时还向 MegEngine 提供一套用户 Op 的 Managers,从而允许 MegEngine 对 Custom Op 进行维护管理。
下面我们将分别介绍 Custom Op 的这些模块。
Tensor
在算法用户的视角中,Tensor 是一个多维数组,同时其还有着一些如形状,量化信息等属性,故而 Custom Op 中的 Tensor 也被设计为数据以及数据的相关属性的集合。 其中数据由一个指向数据存储空间的指针管理。而这些属性则告诉我们该如何去解析数据空间中的数据。如图2中 Tensor 部分所示,这些属性主要包含 Device,DType,Shape 这三者:
- Shape 代表的是 Tensor 维度信息。
- DType 对应 Tensor 中元素的数据类型,如 float32,uint8 等。
- Device 则表示这个 Tensor 在什么设备(cpu/gpu)上。
通过这些属性可以建立起对 Tensor 的完备的描述。
事实上 Tensor 及其附属的这些属性在 MegEngine 系统都会有另一套功能丰富,但对用户而言略显冗余的表达。为了降低使用难度,Custom Op 简化了这些概念,只留下编写 Op 时需要的功能。
具体来说,Shape 提供给用户的行为类似于 c++ 的原生数组,我们可以使用如下的代码来构建和使用它:
Shape shape = {16, 3, 224, 224}; // 构建 shape
bool equal = (shape[3] == 224); // 获取 shape 特定维度的值
shape = {128, 100}; // 修改 shape 的值
至于 Device 以及 DType,用户并不需要知晓其背后实现,只需要通过这些属性知道数据在什么设备上,是什么类型就够了。故而 Custom Op 中的 Device 和 DType 的行为均类似于 string,用户可以以直接设置字符串值的形式去设置具体的 Device 和 DType 类型。
Device device = "x86"; // 创建一个 x86 这种设备类型
device = "cuda"; // 设备类型改为 cuda
bool equal = (device == "cuda"); // 判断某个 device 是否是 cuda
DType dtype = "float32"; // 构建 dtype
bool equal = (dtype == "int8"); // 判断 dtype 是否相等
而为了使这些类型的接口与 MegEngine 解耦,其实现时均使用了 pimpl 手法,隐藏了这些类型的内存布局,而用户通过一系列的接口去 set/get 其中的数据。
Param
Param 主要用于表达 Op 的非 Tensor 的输入(比如卷积中的 padding,stride 等等),然而不同的 Op 的这些非 Tensor 输入的差别往往非常大。可能 Op A 的 Param 是一系列的 string 而 Op B 的 Param 是一个 int 类型。所以我们需要设计一套机制以将这些彼此差异很大的 Param 统一起来,供用户和 MegEngine 系统进行使用。为了实现这个目的,Custom Op 中设计了 ParamVal。ParamVal 中会擦除各个 Op Param 的静态类型,使这些 Param 静态类型统一,以解决不同 Op 的 Param 类型不一致的问题,然后另外定义一套运行时的动态类型系统去进行 Param 实际类型的管理。
说起来可能比较复杂,实际上其可以简化成下面的这个数据结构。其中使用 void* 进行类型擦除,并将擦除后的数据放在 data 中进行存储,而 type 中则记录着这个数据所对应的动态类型。
class ParamVal {
void *data; // 类型擦除后的数据
DynamicDataType type; // 数据的动态类型
};
这样的设计不仅能解决不同 Param 类型不统一的问题,同时这个动态类型的存在同时也大大缓解了 c++ 中没有反射所带来的一些不便。Custom Op 根据此动态类型系统设计了一套统一的参数解析 (Param Parse) 和序列化机制,而无需用户为自己的 Param 去编写这部分代码。
同时为了进一步方便用户去使用,Custom Op 中还为 ParamVal 定义了非常多的运算符,以及其与静态类型之间相互转换的函数。最终展现在用户视角,ParamVal 的行为与 python 中的变量是很接近的。
ParamVal a = 1.0, b = 2, c = false, d = {1, 2}; // 表达不同类型的数据
ParamVal e = a + b; // ParamVal 彼此间的计算
ParamVal f = e - 2; // ParamVal 与静态类型数据的计算
d = c;
Op
在一般算法用户的视角里,Op 是对一个计算过程的描述而不记录保存任何数据信息。为了与算法用户的认知相统一,Custom Op 中的 Op,也被设计为无状态的,即 Op 中只保存相关的函数以及输入输出的一些布局信息,而不记录输入输出的具体值。
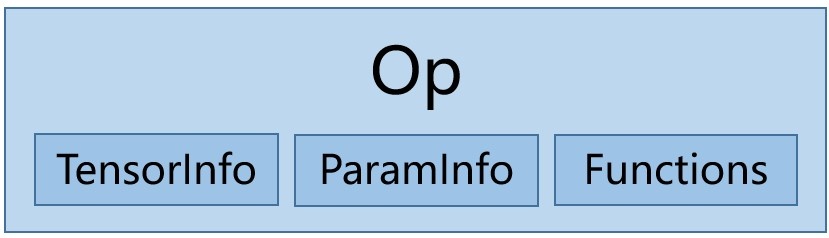
图 4:Op 及其组件
具体来说,在 Custom Op 中,Op 是输入输出 Tensor 信息(TensorInfo),Param 信息(ParamInfo),以及 Op 相关函数的集合(Functions),如图4所示。TensorInfo 中记录了这个 Op 的输入输出 Tensor 的数量,名字,合法类型,维度以及内存分配策略等信息。ParamInfo 则记录着这个 Op 的各个 Param 的名字,默认类型以及默认值等。至于 Functions 其实际包含两部分,kernel 计算函数和 Tensor 属性推导函数。
- kernel 计算函数主要负责将 Tensor,Param 的值传递给用户的 c++/cuda kernel,并将计算结果返回。
- Tensor 属性推导函数则是根据输入 Tensor/Param 的一些属性在 kernel 执行前完成输出 Tensor 的数据布局的推导,从而将算子执行和算子内存分配解耦,以进行内存规划。
其中大部分函数 Custom Op 均提供了默认的实现,用户可以通过 override 这些函数的默认行为去定制化自己的 Op。
Manager 与 Adaptor
考虑到 Custom Op 是一套与 MegEngine 系统解耦的 Op 抽象,根据 Custom Op 定义出来的 Op,MegEngine 并不能直接与之进行交互。为了解决这个问题,Custom Op 中额外设计了一组 Adaptors 和 Managers。其中 Adaptor 允许 MegEngine 使用 Custom Op,而 Manager 允许 MegEngine 感知和管理 Custom Op。
Adaptor 的设计目的主要包含两个方面:一方面其需要允许 MegEngine 去操作使用 Custom Op 去构建网络等,另一方面其需要允许 MegEngine 与 Custom Op 进行数据交互完成计算。
- 对于前者,Adaptors 可以将 Custom Op 包装成 MegEngine 中动态图与静态图中的 Op 抽象,使之行为与 MegEngine 中内置 Op 保持一致。
- 对于后者,Adaptors 可以将 Custom Op 中面向用户的 Tensor 抽象与 MegEngine 中的 Tensor 结合起来,使两者间可以互相转换,允许数据可以自由的在 MegEngine 与 Custom Op 之间流动。
而对于 Manager 模块,其提供了对 Custom Op 所编译成的动态链接库以及 Custom Op 本身的管理。具体来说,Custom Op 在使用时会以动态链接库的形式被加载入 MegEngine 系统中,因此我们基于 RAII 机制去管理这些动态链接库。动态库的加载与卸载和 Lib 类的构造与析构绑定起来,从而避免资源泄漏。而对于 Op 本身,Manager 提供了一些基本的增删改查的操作去允许 MegEngine 对 Custom Op 进行管理。
Custom Op 的编写
用户在使用 Custom Op 编写 Op 时,用户可以使用上述这些概念去将自己写好的 kernel 封装成 Custom Op,并使用 Custom Op 提供的构建工具将之编译成动态链接库,在运行时将之加载入 MegEngine 进行使用。
具体来说,假如现在我们需要为 MegEngine 添加一个名为 MatmulScale 的算子,这个算子在计算时首先会对两个输入 Tensor,lhs 和 rhs 执行矩阵乘,然后再将这个矩阵乘的结果再乘以标量 Scale。
该算子数学上的执行过程的伪代码如下:
def MatMulScale(lhs, rhs, scale):
result = lhs.dot(rhs)
result = result * scale
return result
对于这样的一个操作,假设我们已经为之写好了一份 cuda kernel 代码,并提供如下的接口函数用于调用:
void matmul_scale(const float *lhs, const float *rhs, float *result, size_t M, size_t K, size_t N, float scale);
这些的参数中,lhs,rhs,以及 result 是三个 float 类型的指针, 分别代表这个 Op 的两个输入 Tensor 和一个输出 Tensor,其均需要指向一片已经分配好的 cuda memory。 而 M,K,N 是矩阵的维度信息,表示一个 M*K 的矩阵乘以一个 K*N 的矩阵。 而 scale 则代表着矩阵乘的结果需要乘以的那个系数。
对于这种情况我们可以编写如下的 c++ 代码,就可以将之封装成 MegEngine 的 Op。
void shape_infer(const std::vector<Shape> &inputs, const Param ¶ms, std::vector<Shape> &outputs) {
outputs[0] = {inputs[0][0], inputs[1][1]};
}
void compute(const std::vector<Tensor> &inputs, const Param ¶ms, std::vector<Tensor> &outputs) {
matmul_scale(inputs[0].data<float>(), inputs[1].data<float>(), outputs[0].data<float>(), ...);
}
CUSTOM_OP_REG(MatMulScale) // 定义一个名为 MatMulScale 的 Op
.add_inputs(2) // 两个输入 Tensor
.add_outputs(1) // 一个输出 Tensor
.add_param("scale", 1.0f) // 一个名为 scale 的 Parameter,默认值为 1.0f
.set_shape_infer(shape_infer) // 设置这个 Op 的 shape 推导函数
.set_compute("cuda", compute); // 设置这个 Op 的 计算函数
这段代码主要包含两个部分,第一个部分是一些函数的定义,包括输出 Tensor 属性推断函数和计算函数。 其中前者会根据输入 Tensor 的属性(比如 shape)去推导输出 Tensor 的对应属性,而后者则是在其中调用 cuda kernel,完成计算。 第二部分是 Op 的注册,主要用于定义 Op 有几个输入输出 Tensor,有几个 Param,并将上面定义的属性推断函数和计算函数的指针也注册给 Op。到此就完成了 Custom Op 的构建。
Custom Op Generator
通过 Custom Op 可以将用户编写好的 c++/cuda kernel 简单方便的集成入 MegEngine。然而,让用户自己去编写 kernel 总是最后的选择,如何能够将用户编写 kernel 的这一步的工作也给省掉呢?MegEngine 正在尝试基于 AI 编译器提出一个工具 Custom Op Generator 去解决这个问题。
在 Custom Op Generator 中用户可以直接使用 AI 编译器提供的简单的 python 原语去建立其 Op 的表达,而不需要写任何 c++/cuda 的代码。然后 AI 编译器会自动生成 Op 所对应的 kernel 以及 Custom Op 的装饰代码将这个 kernel 封装成 MegEngine 的 Custom Op,并自动化的进行构建并将之集成入 MegEngine中。全过程用户只需编写一些 python 代码即可,避免了用户自己编写 kernel 的问题。
一般而言,框架与编译器结合的 workflow 都是框架在前编译器在后,由框架去构建一个模型用于训练,然后将训练好的模型送给编译器进行优化部署。然而在 Custom Op Generator 中两者的位置恰恰相反,而在这样的一个 workflow 中,编译器在前而框架在后,编译器利用其代码生成的能力为框架提供拓展支持。从某种意义上来说,这是一种 AI 编译器与框架结合的一种新思路。
总结
Custom Op 作为沟通用户 kernel 和系统 Op 的桥梁,其面向用户提供了一套简洁统一且与框架无关的 Op 抽象,面向系统提供一套完备的 Op 适配与管理工具。为了这个目的,在设计实现 Custom Op 的过程中,我们分析用户编写 Op 时所必须的概念并进行抽象,设计出了一套框架无关的 Op 模型并提供简洁的接口给用户,从而实现了用户侧与系统侧的解耦,使用户编写的 Op 无需随着系统的更新迭代而做对应变化。而同时为了允许 MegEngine 系统去管理使用这些 Op,Custom Op 中又设计了相关管理与适配模块,其会自动化的将用户的 Op 封装适配成 MegEngine 动态图与静态图中的 Op,使用户 Op 在系统中行为与原生 Op 保持一致,从而便于系统的使用管理。通过这样的设计,用户在集成 Op 时无需了解 MegEngine 框架本身,只需二十行代码即可快速的将 kernel 集成入 MegEngine 并使用,可以大大降低算法用户集成 kernel 时的难度与工作量。
原文地址:https://megengine.org.cn/blog/design-custom-operator-system

 浙公网安备 33010602011771号
浙公网安备 33010602011771号