
MegEngine 架构系列:静态内存分析
作者:周瑞亮 | 旷视科技 MegEngine 架构师
在正式进入本文前,先通过一组简单的对比来直观地感受一下,静态内存优化带来的内存占用上的提升。分别对 1batch/128batch 的 vgg16/resnet50/mobilenetv2 模型,使用 tflite tools 得到 tflite 的峰值内存,与 megengine 内存优化前后的峰值内存进行对比:
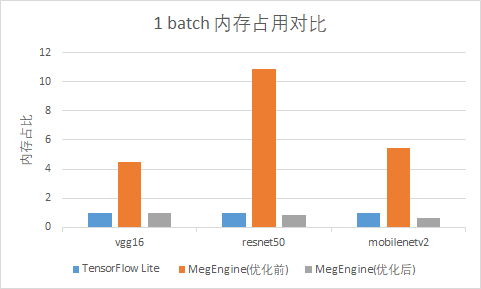
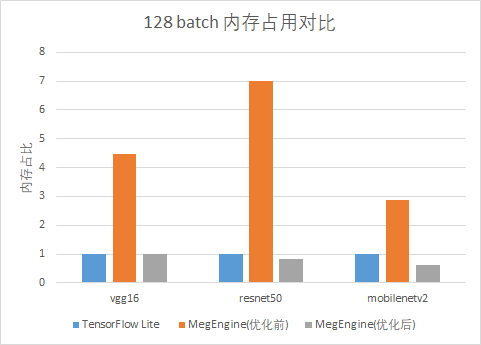
从上图可以看出,通过静态内存优化,模型占用的内存空间显著减小。接下来,将为大家揭秘 MegEngine 深度学习框架的静态内存是如何管理优化的。
1、降低内存占用——为什么以及怎么做
why
近几年深度学习都在蓬勃发展,并被应用于各行各业。随着业务场景对精度要求的不断提高,深度学习模型的规模也越来越大。 广大的深度学习研究人员无论是使用何种运算平台,内存的占用都是绕不开的话题:内存的占用量直接关系到可训练模型的规模,以及部署时的性能表现。鉴于内存的大小有限,内存管理成为深度学习系统的重要研究课题。
how
内存管理是深度学习系统的重要研究课题。针对这个问题外界已经存在许多方案,典型方案如下:
- 模型压缩,例如量化方法、模型剪枝等。
- 计算换内存:例如往期分享的 DTR 技术,丢弃计算成本相对较低的值,并在反向传播时重新计算它们。
- 通信换内存:将未使用的变量从当前运算设备的内存空间交换到其它内存空间,并在下次访问之前将它们交换回来,会产生通信和同步的开销。
- 对顺序程序图中的数据流进行分析,以允许重用内存。
2、MegEngine 中静态内存管理
MegEngine 中采用了多种降低内存的解决方案,本次主要介绍的是 MegEngine 静态内存管理模块是如何利用顺序程序图中的数据流分析,实现内存重用以达到降低内存占用的效果。MegEngine 的思路是在运行前计算得到所有的静态内存总共需要的内存池的大小,然后为每个静态内存请求指定其在内存池中的偏移地址,运行时使用已经预先指定好的空间即可。所以,整个算法的核心在于如何获取总的内存池大小以及为每个静态内存请求分配偏移地址。该算法大致可以分为三步:
- 获取原始数据流信息,从中解析得到静态内存的需求信息、依赖关系等。
- 将静态内存的需求信息抽象为 memory chunk,通过依赖关系对 memory chunk 进行初步优化,将繁琐的静态内存需求信息缩减为干练的 memory chunk。
- 按照依赖关系对 memory chunk 的申请流程进行仿真实现,根据仿真结果得到总的内存池大小以及为每个 memory chunk 分配偏移地址。
从上述三步可以看出 MegEngine 的静态内存 接下来详细拆解这三步的实现方法。
a、获取原始数据流信息
MegEngine 会将图通过编译得到一个拓扑排序的算子执行序列,在运行时会按照算子的执行序列顺序执行。通过这个算子序列,以及这些算子的输入/输出节点的信息,可以轻松地观察到在整个模型运行时,数据是如何被传输使用的。这便是一个完整的顺序程序图的数据流信息。
b、建立最小内存管理单元 Memory Chunk
根据顺序程序图的数据流信息,通过内存管理模块,建立最小内存管理单元 memory_chunk,得到它们的读/写依赖关系以及生命周期。
(1)遍历算子(opr)执行序列,并根据定义在算子中的方法来推断该算子输入(input)/输出 (output) 节点之间依赖关系,依据依赖关系,为每个输入/输出节点创建 memory chunk:
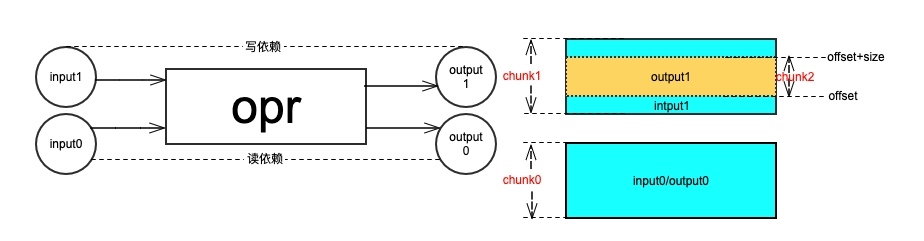
(readonly 和 writable 地址关系示意图)
如上图所示,input0/output0 是读依赖,input1/output1 是写依赖,它们在地址上的映射关系如图中右侧所示,每个矩形对应于一个 memory chunk 的概念。memory chunk 之间的依赖关系以及创建规则如下:
- 读依赖关系,要求某个输出节点复用输入节点的内存,并且保证不会修改内容。这种情况下,输出节点不创建新的 memory chunk, 而是直接复用输入节点的 memory chunk。如图所示,input0 和 output0 这两个节点共用一个 memory chunk 即 chunk0。
- 写依赖关系,输出节点会复用输入节点的全部或部分内存。这种情况下,输出节点会创建新的 memory chunk(chunk2),并记录写操作执行后的 memory chunk(chunk2) 在原先 memory chunk(chunk1) 中的偏移地址以及占用的空间大小。
- 和之前的输入都没有关系,单独创建一个 memory chunk,记录占用空间的大小等信息。
(2)获取每个 meory chunk 的生命周期:
- 先将所有 memory chunk 的起始生命周期(begin)和终止生命周期(end)都记为 0。
- 顺序遍历算子执行序列
- 获取输出节点,如果该输出节点首次被统计,那么该节点的 memory chunk 的起始生命周期记为算子的执行序号 id,意味着该 memory chunk 的数据在第 id 个算子执行后产生;
- 获取输入节点,将该节点的 memory chunk 的终止生命周期(end)和 id+1 对比,并将 end 更新为两者中的较大值,即 end=max(end, id+1)。id+1 意味着要在第 id 个 opr 执行结束后才能释放。
需要注意的是,在上述步骤中“首次统计”以及“max(end, id+1)”的描述都是因为读依赖关系导致存在多个输入/输出节点是共用一个 memory chunk,该 memoy chunk 会被多次统计到,利用算子执行序列的拓扑性质以及上述方法来确保生命周期统计的正确性。
在获取每个 meory chunk 的生命周期的步骤中,读依赖的性质已经被用于内存优化:它不断地延长该 memory chunk 的生命周期,以减少不必要的内存操作。
c、内存优化算法对 Memory Chunk 进行优化
接下来,内存优化算法会利用上文 b(1) 处得到的 memory chunk 之间的写依赖的性质以及 b(2) 处得到的 memory chunk 的生命周期进行进一步的优化。主要分为两步:
- 按照依赖关系对 memory chunk 的申请流程进行仿真实现,获取到每个 memory chunk 申请时,前置空间的 memory chunk。
- 根据仿真实现返回的结果,推算得到总的内存池大小以及为每个 memory chunk 分配偏移地址。
(1)memory chunk 申请空间的仿真实现
首先,介绍算法中内存管理方法以及 free()/alloc()/alloc_overwrite() 的逻辑。
为了模拟内存的调度过程,维护了两个内存信息队列:
- 全部内存信息队列(后简称内存队列):按地址顺序记录所有已经申请的内存,包括使用中(灰色部分标记)和空闲(白色部分标记)两种状态。
- 空闲内存信息队列(后简称空闲内存队列):按空间大小从小到大顺序记录的处于空闲状态的内存。
维护的原则是:内存队列中不存在连续的空闲内存,因为在模拟调度过程中,会将连续空闲内存合并为一个大的空闲内存,方便后续的调度,减少不必要的内存碎片的产生。

(内存管理链表)
free() 逻辑:释放指定地址空间,并维护内存队列和空闲内存队列。主要有两种情况,如下图所示:
-
情况一:free 之后的空闲空间前后无其它空闲空间,不需要合并空闲空间的操作。
![free() 示意图]()
-
情况二:free 之后的空闲空间前后有其它空闲空间存在,需要进行合并空闲空间的操作。
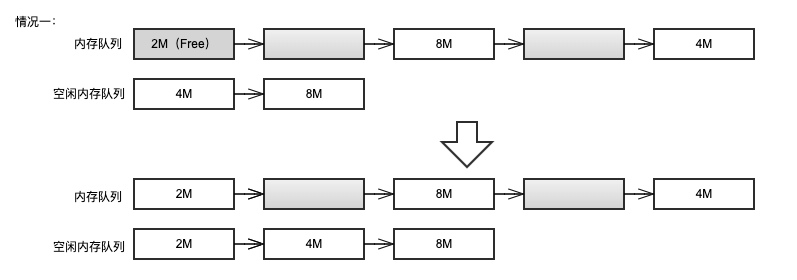
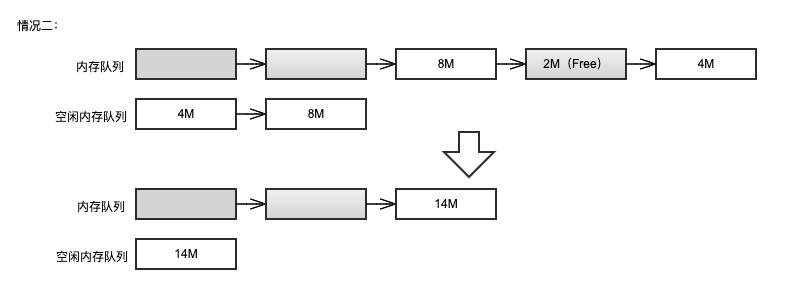 )
)
alloc() 逻辑:申请 size 大小的空间,并维护内存队列和空闲内存队列。主要有三种情况,如下图所示:
-
情况一:空闲内存队列为空,则直接申请一块 size 大小的内存,并记录在内存队列末尾;
![alloc() 示意图]()
-
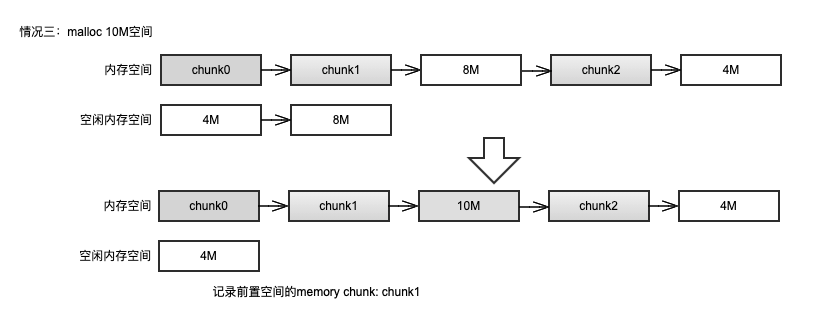
情况二:空闲内存队列不为空,且有大于或等于 size 的空间,则从空闲内存队列中申请一块大于或等于 size 的最小空间。截取所需空间,并维护内存队列和空闲内存队列。
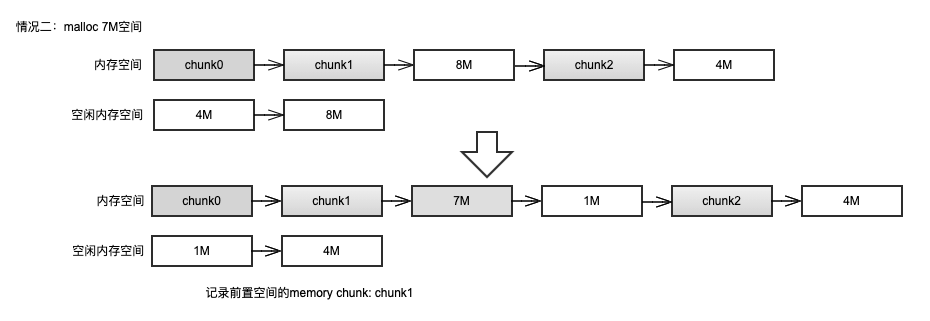
- 情况三:空闲内存队列不为空,但是所用空间的大小均小于 size,则取出空闲内存队列中最大的空闲空间(即队尾记录的内存)并扩展至 size 大小。
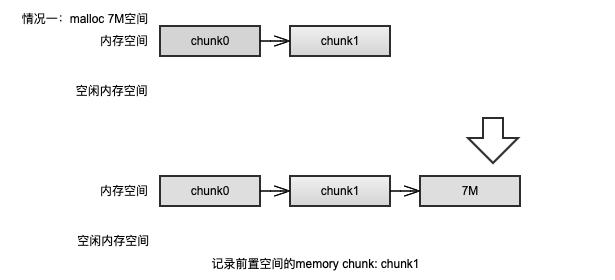
alloc() 成功后,记录前置空间的 memory chunk(即前一个非空闲块的 memory chunk)。
alloc_overwrite() 逻辑:上文 b(1) 处提到写依赖关系,可以看到写依赖的节点可能只使用写依赖对象节点原空间的一部分空间(也可能是全部,基于建立写依赖关系时记录的偏移地址和大小信息可以推导)。所以进行写操作之后,前后可能会有空闲空间产生,将这部分空间释放,并维护内存队列和空闲内存队列。成功之后,记录前置空间的 memory chunk。
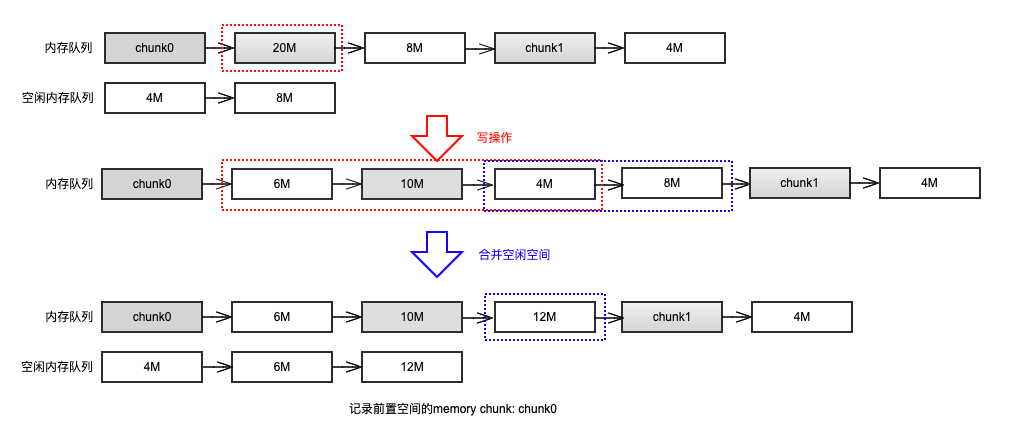
举一个例子进行说明,假设有一个写依赖关系如 b(1) 图示:chunk2 对 chunk1 进行写操作,且 offset = 6M,size = 10M,chunk1 的大小为 20M。由此可以推断出,在写操作完成后,原 chunk1 的 20M 空间被分解为前面 6M 的空闲空间,中间 10M 的写覆盖的空间,后面 4M 的空闲空间。那么将前后空闲空间释放的操作就如下图所示:
接下来,根据 b(2) 处得到的 memory chunk 的生命周期,创建 time=>(alloc, free) 的数据结构(time 为 opr 序列,alloc 为该时间点 alloc 的 memory chunk 的指针数组,free 为该时间点 free 的 memory chunk 的指针数组),并依据 b(1) 处获得的写依赖的性质,模拟整个内存管理的流程:
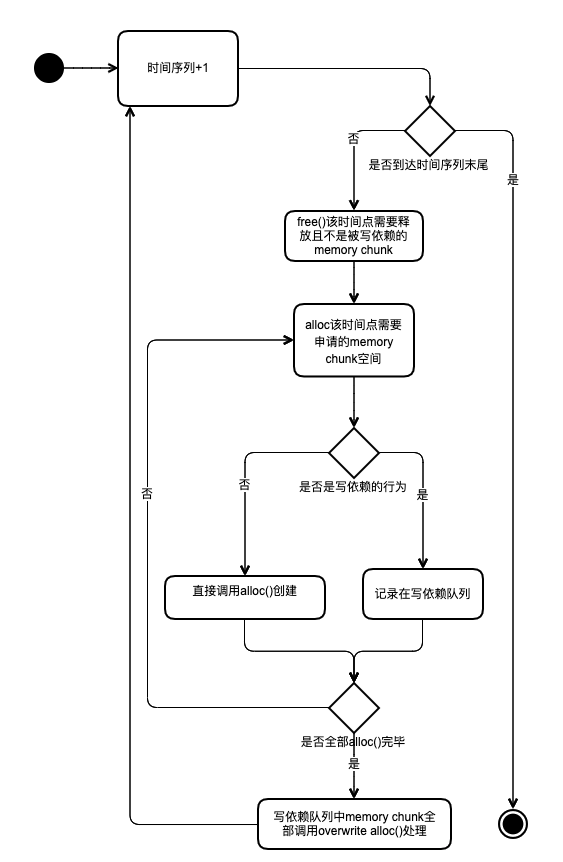
(算法模拟 alloc 和 free 流程图)
如上图所示,整个流程可以划分为三步,也对应之前提到的三种方法:
- 将该时间点需要释放的且不被写依赖的 memory chunk 调用 free() 方法进行释放。
- 将该时间点需要申请的且不是写依赖行为的 memory chunk 调用 alloc() 方法进行申请。
- 在上述两步完成后,将具有写依赖行为的 memory chunk 调用 alloc_overwrite() 进行处理。
(2) 推导总的内存池大小以及为每个 memory chunk 分配偏移地址
为了便于理解 memory chunk 的偏移地址的记录方式。对上述已经提及的内容进行一个专门的汇总说明,所有的 memory chunk 可以分为两类:通过 alloc() 申请的没有写依赖行为的 memory chunk(也称为 memory_chunk_root)和通过 alloc_overwrite() 申请的有写依赖行为 memory chunk。memory chunk 可以依据写依赖关系建立一组链表,如下图,以其中一个链表为例(memory_chunk_n 写依赖于 memroy_chunk_n-1,...,memory_chunk_1 写依赖于 memory_chunk_root,这就构成一个写依赖链表,分析所有的 memory chunk 写依赖可以得到多个写依赖链表)。由于写依赖关系是会记录 offset 和 size 信息,那么链表中的每个 memory_chunk 都可以推导出与 memory_chunk_root 的 offset_root。那么对于这整个链表上的 memory chunk 只需要调整 memory_chunk_root 的起始地址 (root_addr_begin),就可以完成对整个链表上 memory chunk 地址的调整。
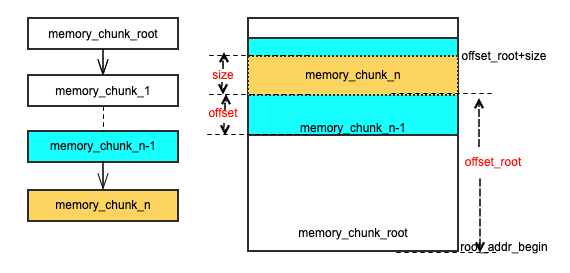
(overwrite 链表与内存关系)
接下来,介绍如何推导所有的 memory chunk 的偏移地址。根据之前仿真记录的前置空间的 memory chunk 得到前置空间的大小。通过前置空间大小,对 memory chunk 的分配空间进行调整,得到 memory chunk 的偏移地址。 在实际实现中存在递归调用,使用 map 减少了重复了查询和计算。这里提及的前置空间即仿真记录的前置空间的 memory chunk 以及该 memroy chunk 的迭代推导出的所有前置空间的 memory chunk 占用空间的总和,形象地理解就是分配空间时,地址空间上从 0 开始前方已经被占用的空间。
如下图所示,纵向表示逻辑地址空间,左侧红色区域表示的是前置空间占用的地址空间,右侧 memory_chunk_n 则是此次需要进行调整空间安排的 memory_chunk。root_addr_begin 的初始值为 0,调整时有两种情况:
- 情况一:前置空间已占用大小 <= root_addr_begin + offset_root,这意味着 memory_chunk_n 实际使用空间和前置空间不会产生冲突,所以 root_addr_begin 并不需要调整。
- 情况二:前置空间已占用大小 > root_addr_begin + offset_root,这意味着 memory_chunk_n 实际使用空间和前置空间会产生冲突,所以 root_addr_begin 需要调整至 root_addr_begin + offset_root = 前置空间已占用大小,以避免冲突同时不产生空间的浪费。
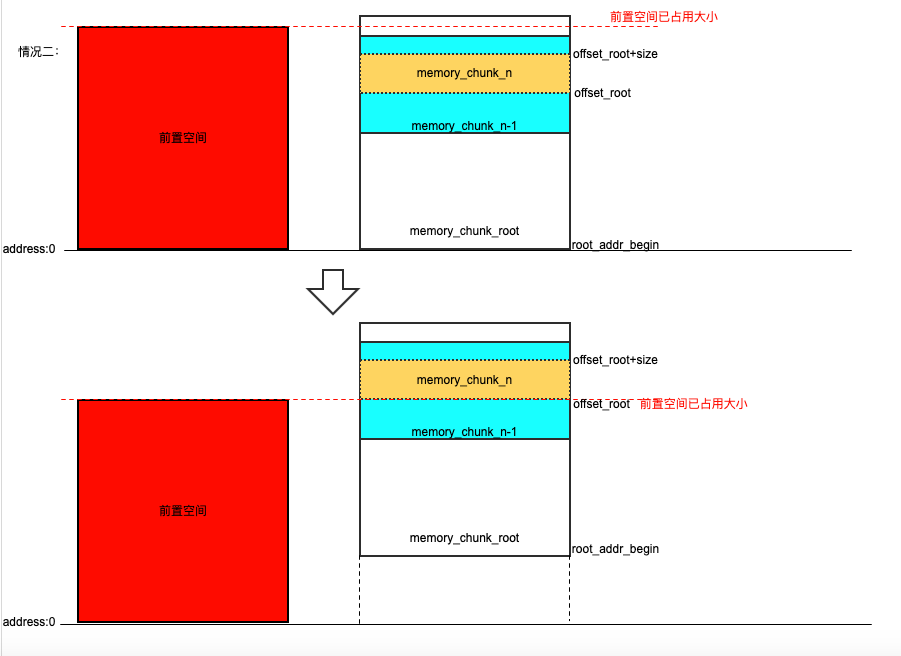
(逻辑地址分配示意图)
在此轮调度过后,可以获取到总的内存池大小以及为每个 memory chunk 分配偏移地址:
- 总的内存池大小:所有 memory_chunk_root 中,root_addr_begin 加上自身大小所达到的最大值。
- memory chunk 的偏移地址:root_addr_begin + offset_root
在实际运行时,只需要申请一块峰值显存大小的内存,并依据各个 memory chunk 的偏移地址进行显存空间的调度分配,就可以保证程序的正常运行。
3、总结
最后,对 MegEngine 采用“顺序程序图中的数据流分析,以允许重用内存”的方法进行内存优化的优点进行一个总结:
- 可以降低模型的显存占用量。
- 对于模型完全透明,不会对模型精度产生影响。
- 是纯粹的内存方向的优化,不会带来计算/通信上的损失。
- 内存优化是在模型运行前做的,内存管理的运行时开销几乎为零。
- 能提前获取到静态内存的峰值显存,在一定程度上,避免程序运行到一半由于显存不够导致训练失败浪费时间的情况。
- 统一的内存申请,降低存储设备上的内存管理成本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号