

shell 命令 - 三剑客 与 管道
三剑客
一. grep (基于正则表达式查找满足条件的行,global search regular expression(RE) and print out)
- 内容检索
grep pattern file # 获取file中包含pattern的行
grep -o pattern file # 获取内容符合pattern的内容,而不是整行
grep -A num1 -B num2 -C num3 pattern file # 获取上下文
-A num1: 同时获取满足 pattern 那一行的后 num1 行 (After Context)
-B num2: 同时获取满足 pattern 那一行的前 num2 行 (Before Context)
-C num3: 同时获取满足 pattern 那一行的前 num3 行和后 num3 行 (Context)
- 文件检索
grep pattern -r dir/ : 递归搜索dir目录下文件内容可以满足pattern的信息:信息包含文件名及匹配到的内容
grep -h pattern /tmp/: 输出的信息中只展示匹配pattern的内容
grep -l pattern /tmp/ : 输出的信息中只展示匹配pattern文件名
- 范围约束
grep -i pattern file: 忽略大小写
grep -v pattern file: 不显示匹配的行
grep -e pattern file:
-e 只能指定一个关键字,但可以使用多个 -e 来实现匹配多个关键字
grep -e pattern1 -e pattern2 filename
等价于
grep -E "pattern1|pattern2" filename
满足任意一个 pattern 就会匹配
grep -E pattern file: 使用扩展正则表达式
grep -E "word1|word2|word3" file.txt
匹配 file.txt 中包含 word1 或 word2 或 word3 的行。
满足其中任意条件(word1、word2和word3之一)就会匹配。
grep pattern1 -r dir/ --include pattern2: 文件范围和目录范围约束---> --include pattern2 限定搜索的文件为dir目录下文件名能够符合pattern2 的文件
- 进程检索
ps -ef | grep 进程pattern :搜索满足pattern的进程
(grep 本身会开启新进程,所以导致输出结果中会有grep 进程pattern 这个进程,所以在过滤进程时,应将grep 本身这个进程过滤掉
ps -ef | grep 进程pattern | grep -v grep)
二. awk (根据定位到的数据行处理其中的分段)
awk 是 linux 下的一个命令,同时也是一种语言解析引擎
awk 具备完整的编程特性。比如执行命令,网络请求等
语法:awk 'pattern{action}'
awk 上下文变量
| BEGIN | 开始(用于初始化) |
|---|---|
| END | 结束(打印统计数据) |
| NR | 行数(number of record) |
| $1 $2 ... $NF NF | 字段与字段数 (NF: number of field,$NF: 最后一列,$1: 第一列,$(NF-1): 倒数第二列) |
| $0 | 整行 |
| FS | 字段分隔符(field separator) |
| OFS | 输出数据的字段分隔符(output field separator) |
| RS | 记录分隔符(record separator,记录其实就是行) |
| ORS | 输出字段的行分隔符(output record separator) |
-F 分隔符: 指定字段的分隔符,可以用'<|>' 指定多个分隔符
BEGIN{FS="_"} : 也可以表示分隔符
正则匹配
'$num~/pattern/[{action}]': 输出第num个字段可以满足pattern的行, {action} 可以忽略不写,默认的是{print $0},即将符合的行输出,(~ 代表匹配后面的正则表达式)
'/pattern/[{action}]': 可以满足pattern的行
比较表达式
'$2 > 2 或者 $3 == "b"':第二个字段大于2,第三个字段=="b"
区间表达式
'/pattern1/, /pattern2/': 输出从满足pattern1的行开始直到满足pattern2的行结束
action行为表达式 {action}
{print $0} 或者 {print $2}: 打印
{$1="abc"} : 赋值
处理函数
原始内容 $0
更新后内容 {$1=$1; print $0}$ echo 1:2:3 | awk 'BEGIN {RS=":"}{print $0}'
1
2
3
$ echo '1
2
3
' | awk 'BEGIN{RS="";FS="\n";OFS=":"}{$1=$1;print $0}'1:2:3
$ echo '1
2
3' | awk 'BEGIN{ORS=":"}{$1=$1;print $0}'1:2:3:
求第二列的平均数
$ echo '1,10
2,20
3,30' | awk 'BEGIN{total=0;FS=","}{total+=$2}END{print total/NR}'20
awk 的词典结构 array
array 是稀疏矩阵,类似python的的字典类型
统计多家机构的营业额,营业额的平均值:机构名,月份,营业额$ echo "
a, 1, 10
a, 2, 20
a, 3, 30
b, 1, 5
b, 2, 6
b, 3, 7" | awk '{datas[$1]+=$3}END{for(k in datas) print k,datas[k]}'0
a, 60
b, 18
$ echo "
a, 1, 10
a, 2, 20
a, 3, 30
b, 1, 5
b, 2, 6
b, 3, 7" | awk '{datas[$1]+=$3;counts[$1]+=1}END{for(k in datas) print k,datas[k]/counts[k]}'0
a, 20
b, 6
前两个例子中输出会有0,是因为第一行只有一个换行符,其值为空,打印输出了 k 为空的datas[k] ,可以过滤掉
echo "
a, 1, 10
a, 2, 20
a, 3, 30
b, 1, 5
b, 2, 6
b, 3, 7" | awk '{datas[$1]+=$3}END{for(k in datas) if ( k !="") print k, datas[k]}'a, 60
b, 18
三. sed (stream editor : 定位并修改数据,偏重于对数据的编辑)
语法机构 sed [pattern][action]
sed -n '2p' : 打印第二行 (只显示匹配处理的行,否则会输出所有,也就是关闭默认的输出),p的作用是在终端输出匹配的行,如果没有p的话,sed -n '2' 将不会输出
sed 's#hello#world#': 修改
行数匹配:num # 第 num 行, $ 表示最后一行
行数范围:num1,num2 # 第 num1 行~第 num2 行
正则匹配:/pattern/
区间匹配://,//
-e 表达式
-i: 直接修改源文件
-E: 扩展表达式
-debug: 调试
-n: 只显示匹配处理的行(否则会输出所有)(即关闭默认的输出)
sed action 表达式
p:打印,通常结合-n参数:sed -n '2p'
s:查找替换:s/pattern/replacement/[FLAGS]s 表示替换,s后面表示分隔的字符可以是任意的:/ 或 # 都是可以的
用replacement 替换pattern匹配到的内容
FLAGS: g ->表示全局匹配 , 若不加g,则只替换该行匹配到的第一个内容,g 表示会把该行中所有匹配的内容都进行替换
& : 表示匹配的整个内容本身$ echo "a, 1, 10
a, 2, 20
a, 3, 30
b, 1, 5
b, 2, 6
b, 3, 7" | sed 's/a/Great &/'Great a, 1, 10
Great a, 2, 20
Great a, 3, 30
b, 1, 5
b, 2, 6
b, 3, 7
sed 's#([0-9])|([a-z])#\1\2#':分组匹配与字段提取
使用 () 对数据进行分组
使用\1 \2 反向引用匹配的内容,\num 表示引用匹配的第num个组
d:删除,删除前两行 sed '1, 2d'
a:'/pattern/a要追加的内容' ;在匹配行的后面追加指定的内容
mac OS 上需要这样的格式'/pattern/a
要追加的内容'
c:'/pattern/c要改变的内容'; 将匹配的行改成指定的内容
mac OS 上需要这样的格式
'/pattern/c
要改变的内容'
i:'/pattern/i要插入的内容' ;插入内容到匹配行之前
mac OS 上需要这样的格式
'/pattern/i
要插入的内容'
e:执行命令
管道
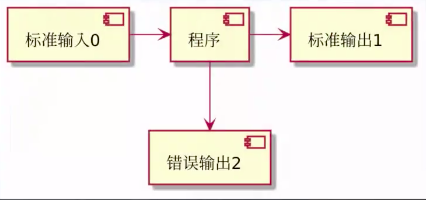
0 : 标准输入 (read)
1 : 标准输出
2 : 错误输出
管道重定向
管道与管道之间可以重定向;管道与文件之间可以重定向
- 输入重定向:command < inputfile 将文件的内容重定向到命令,
<: 将文件内容读取到command命令中,必须指定文本文件来进行输入 - 输出重定向:command [> | >>] outputFile 将命令的输出重定向到文件
> : 将命令command的输出保存到outputFile,文件不存在则创建文件,文件存在,则会清除文件已有内容,再将输出保存到文件中
>>: 将命令command的输出保存到outputFile,文件不存在则创建文件,文件存在,则在文件已有内容之后添加保存command的输出
> :重定向默认的是将标准输出重定向到指定文件,对于想要将错误输出重定向到指定文件的话,需要在重定向命令后加 2>&1
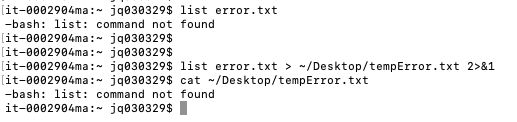
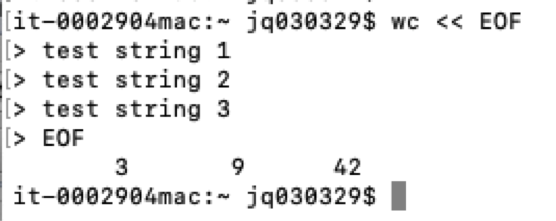
3.内联输入重定向:<<
<< : 用于将字符串信息作为输入的场景,而且必须指定一个文本标记来标记输入数据的开始和结尾
管道连接
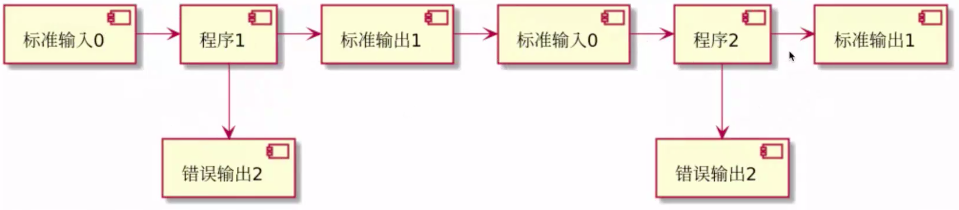
管道连接符是 ' | ',可以使用管道连接符 ' | ' 连接多个程序的执行(管道连接是以子进程的方式启动的)
当 管道连接符 ' | ' 后连接的命令有多个时,需要使用{} 将多个命令形成一个命令块,命令之间用分号隔开 (命令与{} 之间是有空格的,不然会报错)
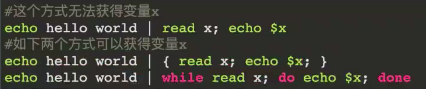
三剑客结合管道的使用


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现