Python爬虫实战系列4:天眼查公司工商信息采集
Python爬虫实战系列1:博客园cnblogs热门新闻采集
Python爬虫实战系列2:虎嗅网24小时热门新闻采集
Python爬虫实战系列3:今日BBNews编程新闻采集
Python爬虫实战系列4:天眼查公司工商信息采集
一、分析页面
打开天眼查网址 https://www.tianyancha.com/ ,随便搜索一个公司【比亚迪】

查看地址栏URL变化,由https://www.tianyancha.com变成https://www.tianyancha.com/search?key=比亚迪&sessionNo=1710895900.05751652
然后分析cookie情况,当不登陆,直接访问首页https://www.tianyancha.com时,网站会自动生成一堆cookie
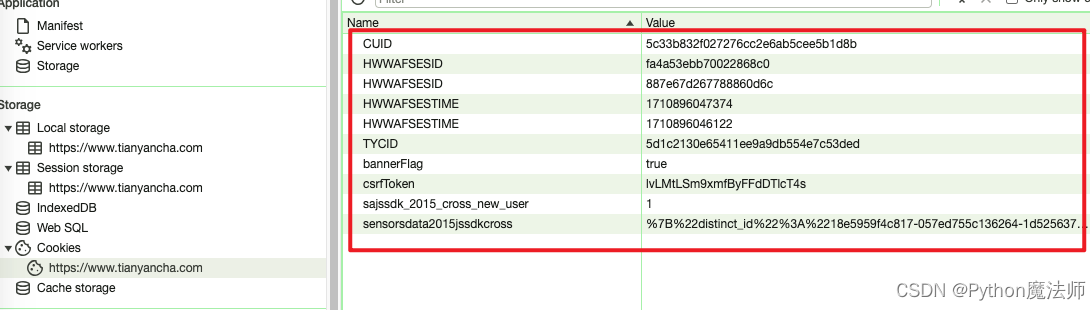
接下来查看公司详情页面,每个公司详情页都会有天眼查自己的公司id拼接出来的URL
例如:https://www.tianyancha.com/company/11807506
这个详情页面就是我们真正需要数据的页面
1.1、分析请求
开始分析请求,F12打开开发者模式,点击Network,然后刷新页面
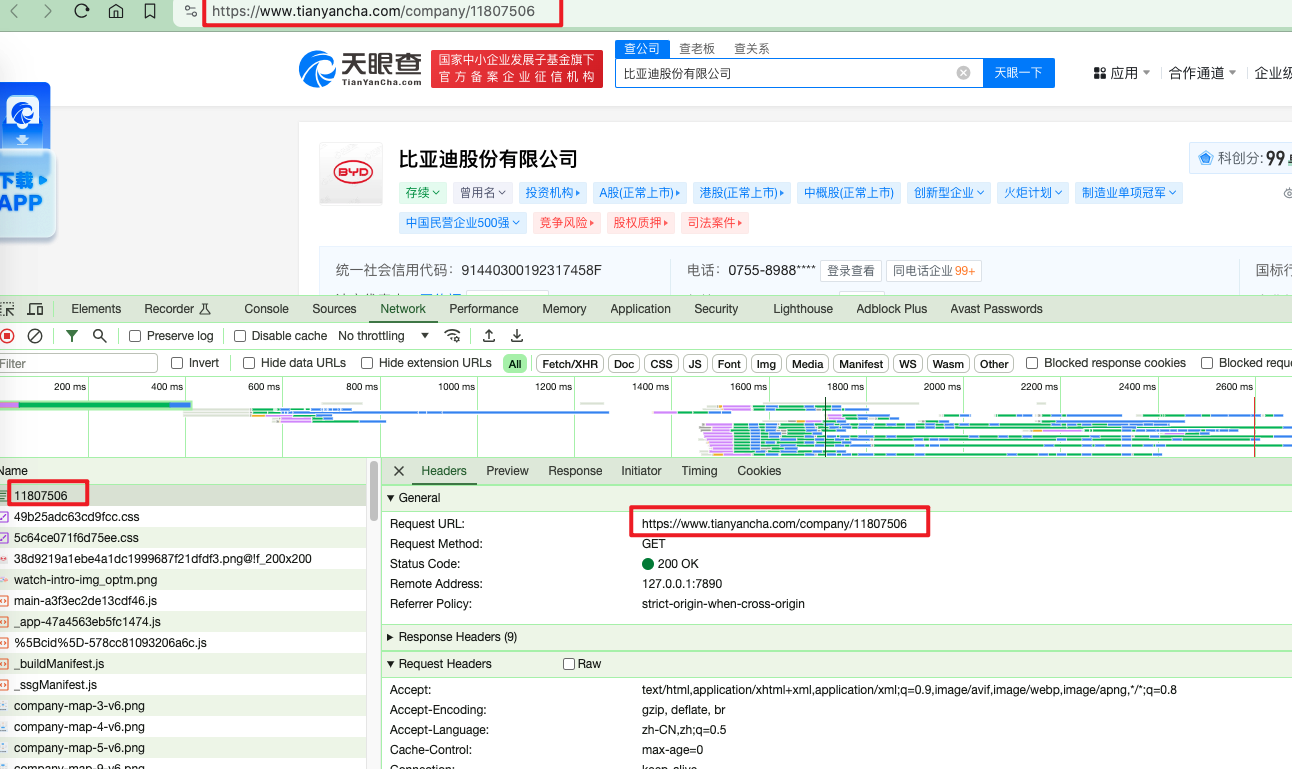
由于公司详情页都是新标签页打开的,所以请求地址也就是当前页面地址https://www.tianyancha.com/company/11807506并且该请求Response的是HTML源码,我们只需要分析该HTML代码解析处理数据即可。
右键请求=》copy curl=》
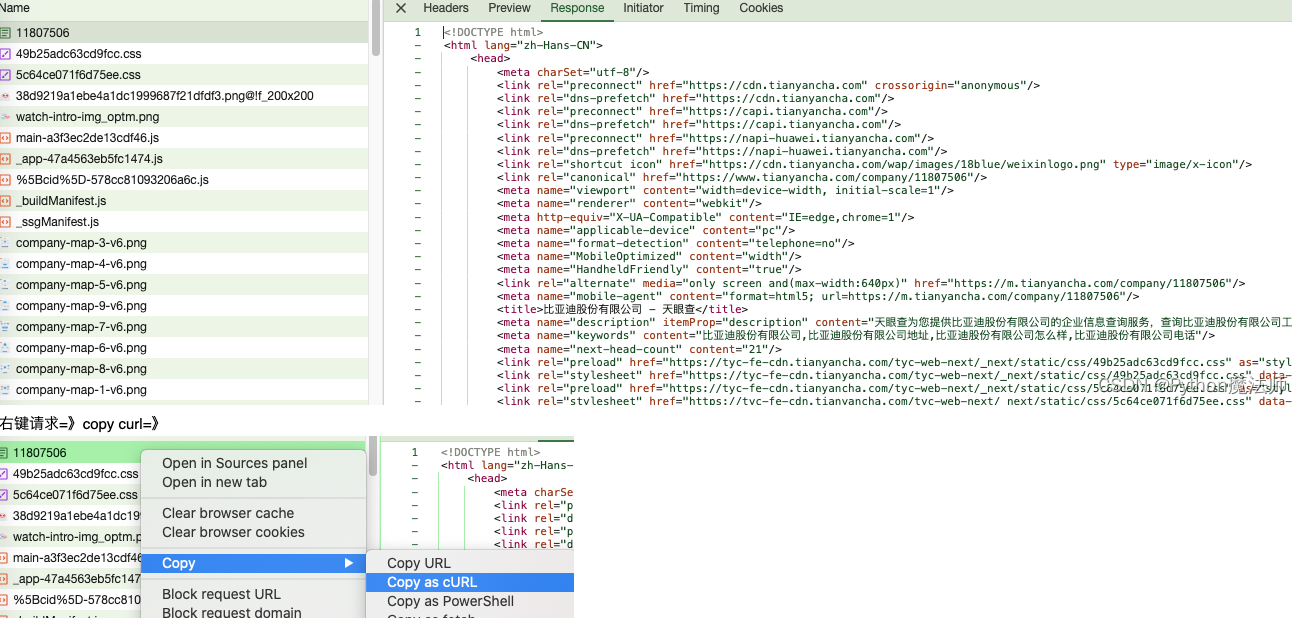
curl代码如下
curl 'https://www.tianyancha.com/company/11807506' \
-H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8' \
-H 'Accept-Language: zh-CN,zh;q=0.5' \
-H 'Cache-Control: max-age=0' \
-H 'Connection: keep-alive' \
-H 'Cookie: HWWAFSESID=887e67d267788860d6c; HWWAFSESTIME=1710896046122; csrfToken=lvLMtLSm9xmfByFFdDTlcT4s; TYCID=5d1c2130e65411ee9a9db554e7c53ded; CUID=5c33b832f027276cc2e6ab5cee5b1d8b; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2218e5959f4c817-057ed755c136264-1d525637-855961-18e5959f4c913dd%22%2C%22first_id%22%3A%22%22%2C%22props%22%3A%7B%7D%2C%22identities%22%3A%22eyIkaWRlbnRpdHlfY29va2llX2lkIjoiMThlNTk1OWY0YzgxNy0wNTdlZDc1NWMxMzYyNjQtMWQ1MjU2MzctODU1OTYxLTE4ZTU5NTlmNGM5MTNkZCJ9%22%2C%22history_login_id%22%3A%7B%22name%22%3A%22%22%2C%22value%22%3A%22%22%7D%2C%22%24device_id%22%3A%2218e5959f4c817-057ed755c136264-1d525637-855961-18e5959f4c913dd%22%7D; sajssdk_2015_cross_new_user=1; bannerFlag=true; searchSessionId=1710896089.33230042' \
-H 'Referer: https://www.tianyancha.com/search?key=%E6%AF%94%E4%BA%9A%E8%BF%AA&sessionNo=1710896089.33230042' \
-H 'Sec-Fetch-Dest: document' \
-H 'Sec-Fetch-Mode: navigate' \
-H 'Sec-Fetch-Site: same-origin' \
-H 'Sec-Fetch-User: ?1' \
-H 'Sec-GPC: 1' \
-H 'Upgrade-Insecure-Requests: 1' \
-H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36' \
-H 'sec-ch-ua: "Chromium";v="122", "Not(A:Brand";v="24", "Brave";v="122"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "macOS"'
然后逐个测试哪些是请求必要参数
大部分情况下,一个请求必要参数是如下这些
- User-Agent:标识发送请求的客户端
- Content-Type:内容类型
- cookie或者Authorization
所以可以删除不必要参数进行测试,经过测试,其他不重要参数可以删除,但是删除cookie不可行,说明接口需要cookie信息
但是这个cookie怎么来的呢?
还记得上面说过,我们观察得到当我们访问首页时会自动注入一些cookie吗?
我们截止目前也没有登录,所以直接对比首页cookie和详情页cookie是否有区别即可。
分析结论:
- 详情页面请求需要cookie信息,但是该cookie可以从首页获取到
- 详情页面有反爬策略,同ip多次访问会提示需要登录,但是一个ip第一次请求时无需登录也可以请求到结果
二、代码实现
分析完请求后,我们开始代码实现,由于需要先从访问一次首页后拿到cookie才能再请求详情页
所以我们采用Python的requests的session功能,利用该session发起get和post请求,这样每次session发起请求时都会携带cookie,那我们只需要在获取session前先请求一次首页即可。
def new_session():
"""
获取session
:return:
"""
session = requests.session()
while True:
try:
session.get(url='https://www.tianyancha.com', headers=headers, timeout=(2, 2), proxies=proxies)
return session
except Exception as e:
Print.print("异常,重试...", e)
update_proxies()
注意这里我演示使用了代理proxies,当出现异常无法访问时需要更新一下代理update_proxies()
拿到session后就可以请求详情页面了
def get_co_detail(url):
"""
公司详情
:param url:
:return:
"""
session = new_session()
response = session.get(url=url, headers=headers, timeout=(2, 2), proxies=proxies)
restext = response.content.decode('utf-8', errors='ignore')
tree = etree.HTML(restext)
title = str(tree.xpath('//title/text()'))
# 公司名称
coName = tree.xpath("//h1[@class='index_company-name__LqKlo']/text()")
注意详情页面这里是先获取session,然后get请求时同样增加代理
本次学习演示只获取页面中的公司名称信息,如需请求信息可自行分析页面源码然后xpath获取
总结
- 分析请求时多注意cookie信息,分析cookie是后端生成还是前端js生成
- 如遇需要携带cookie请求时,可以采用
requests.session()创建一个session来请求
本文章代码只做学习交流使用,作者不负责任何由此引起的任何法律责任。
由于信息安全问题,这里不放源码。
各位看官,如对你有帮助欢迎点赞,收藏,转发,关注公众号【Python魔法师】获取更多Python魔法~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号