Python爬虫实战系列2:虎嗅网24小时热门新闻采集
一、分析页面
打开虎嗅网,点击【24小时】
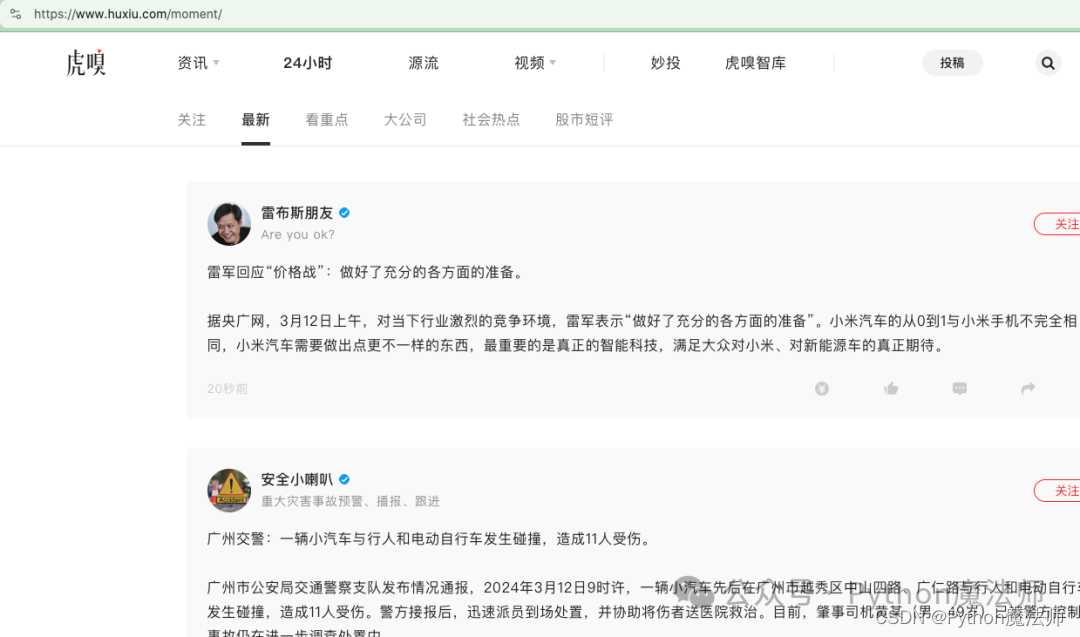
本次采集,我们以这24小时的热门新闻为案例。
1.1、分析请求
F12打开开发者模式,然后点击Network后点击任意一个请求,Ctrl+F开启搜索,输入标题雷军回应 ,开始搜索
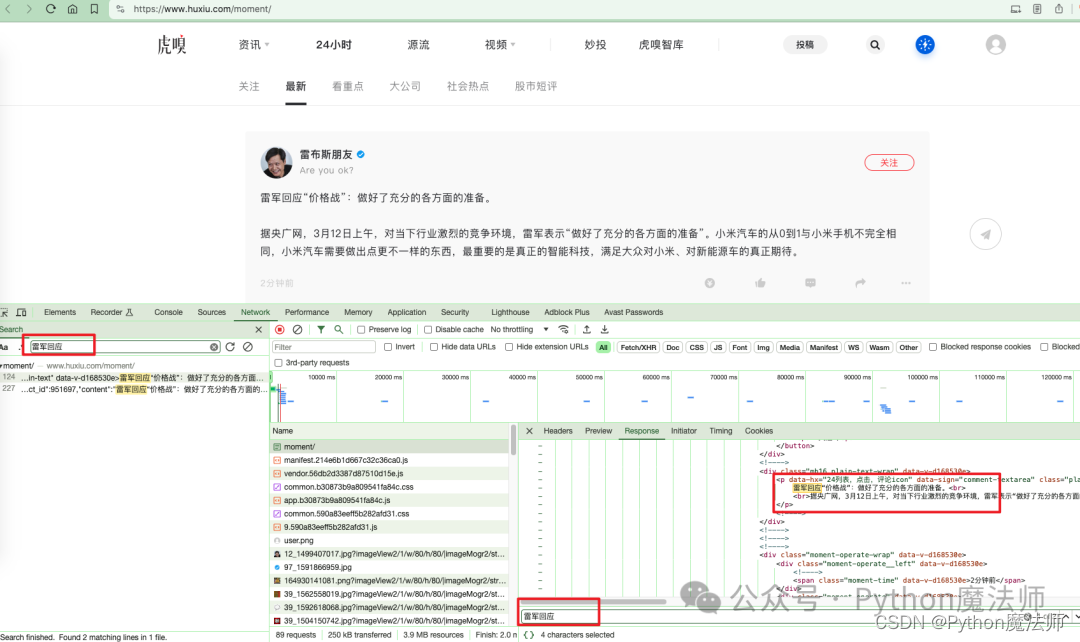
可以看到请求地址为https://www.huxiu.com/moment/ 但是返回的内容不是json格式,而是html源码,结合上次博客园采集经验我们需要解析html源码来获取数据,但是如果我们再细心一点,进一步搜索就会有惊喜。
通过直接在返回内容里搜索关键字,发现有一个js变量window.__INITIAL_STATE__; 存储了页面所需数据。
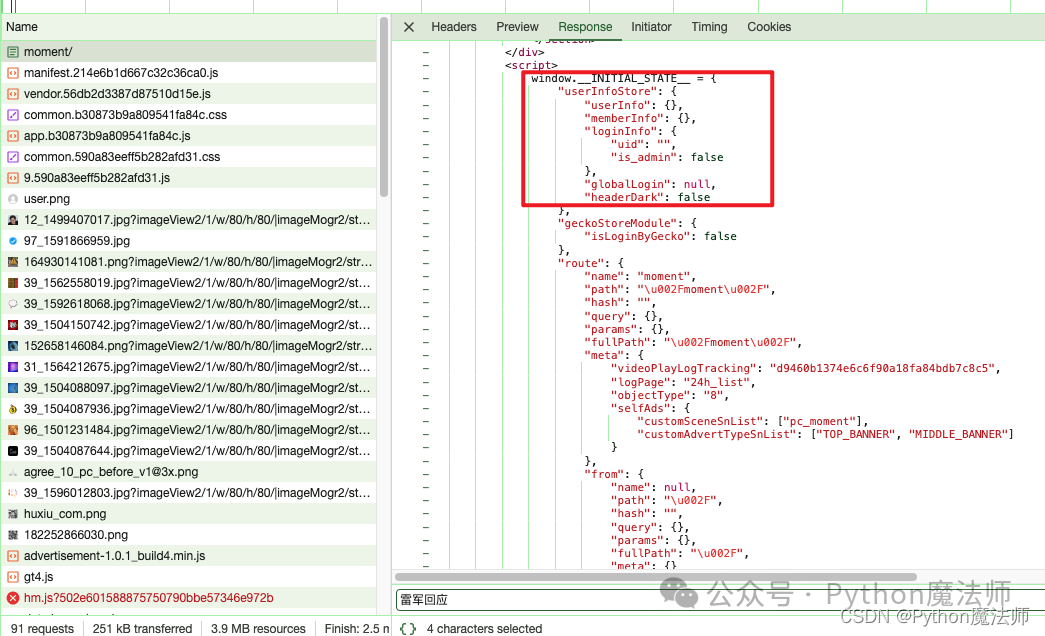
而这个变量里的['moment']['momentList']['moment_list']['datalist'][0]['datalist']内容则就是新闻具体数据
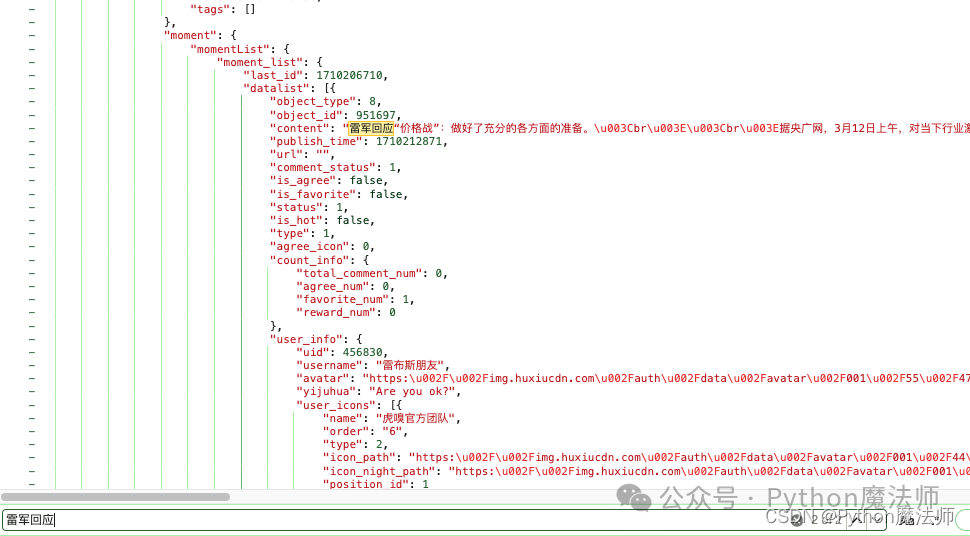
接下来就简单了,同样的套路,分析请求必需参数和cookie反爬策略,然后我们通过请求后获取js变量结果方式来进行爬取。
二、代码实现
本次技术实现使用如下库:
1.playwright:用来打开URL,执行JavaScript代码,获取js变量值
源码如下
# -*- coding: utf-8 -*-
import os
import sys
import time
from playwright.sync_api import sync_playwright
opd = os.path.dirname
curr_path = opd(os.path.realpath(__file__))
proj_path = opd(opd(opd(curr_path)))
sys.path.insert(0, proj_path)
# http请求默认agent
USERAGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
spider_config = {
"name_en": "https://www.huxiu.com/moment/",
"name_cn": "虎嗅"
}
def extract_title(text):
if text:
first_sentence = str(text).split('。')[0]
return first_sentence
else:
return text
class Huxiu:
def __init__(self):
self.headers = {
'authority': 'www.huxiu.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8',
'user-agent': USERAGENT
}
def get_news(self):
results = []
with sync_playwright() as playwright:
browser = playwright.chromium.launch(
headless=True,
slow_mo=1000,
args=['--start-maximized']
)
context = browser.new_context(
no_viewport=True,
accept_downloads=True
)
page = context.new_page()
page.set_default_timeout(200000)
page.goto('https://www.huxiu.com/moment/')
page.wait_for_load_state('load')
# 获取动态JavaScript内容
initial_state = page.evaluate('(function() { return window.__INITIAL_STATE__; })()')
datalist = initial_state['moment']['momentList']['moment_list']['datalist'][0]['datalist']
for data in datalist:
results.append(
{
"news_title": extract_title(data['content']) + "。",
"news_date": data['format_time'],
"source_en": spider_config['name_en'],
"source_cn": spider_config['name_cn'],
}
)
browser.close()
return results
def main():
huxiu = Huxiu()
results = huxiu.get_news()
print(results)
if __name__ == '__main__':
main()
源码中核心内容:获取动态JavaScript内容
initial_state = page.evaluate('(function() { return window.__INITIAL_STATE__; })()')
总结
1.分析页面,有些页面请求返回的是html,但是也有可能会将数据拼接在js里来渲染页面
2.Python中执行JavaScript代码一种推荐的方式是使用playwright这种库,内置浏览器引擎,且很少被认为是暴力请求,并且自带等待机制
本文章代码只做学习交流使用,作者不负责任何由此引起的法律责任。
各位看官,如对你有帮助欢迎点赞,收藏,转发
关注公众号【Python魔法师】带你了解更多Python魔法


 浙公网安备 33010602011771号
浙公网安备 33010602011771号