Python爬虫实战系列1:博客园cnblogs热门新闻采集
实战案例:博客园热门新闻采集
一、分析页面
打开博客园网址https://www.cnblogs.com/,点击【新闻】再点击【本周】
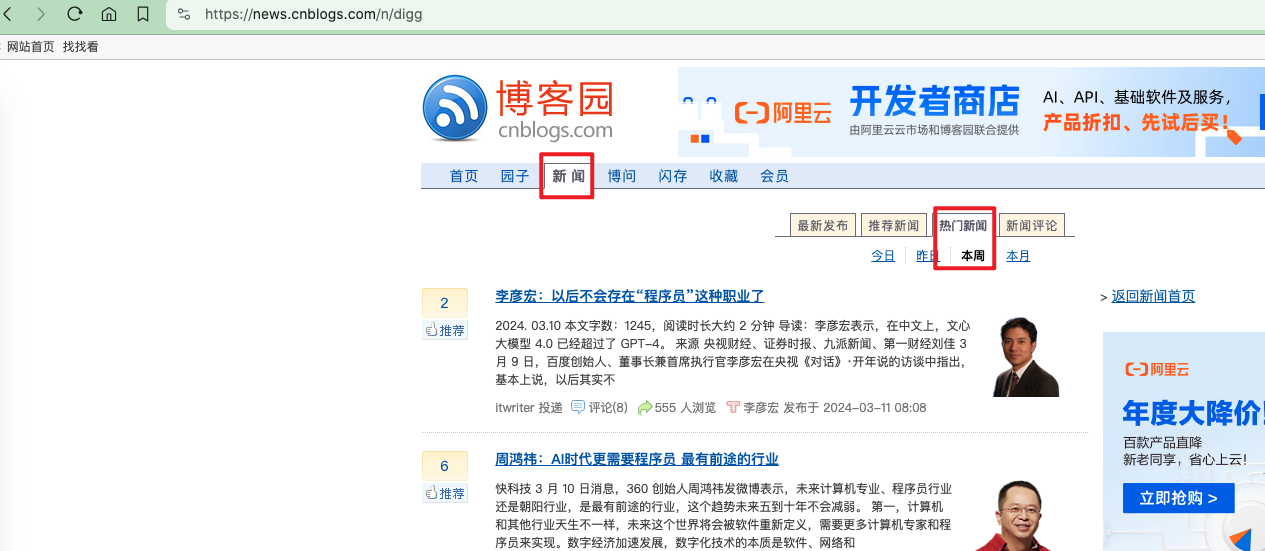
本次采集,我们以页面新闻标题为案例来采集。这里可以看到标题“ 李彦宏:以后不会存在“程序员”这种职业了”。
1.1、分析请求
F12打开开发者模式,然后点击Network后点击任意一个请求,Ctrl+F开启搜索,输入标题李彦宏:以后不会存在“程序员”这种职业了 ,开始搜索
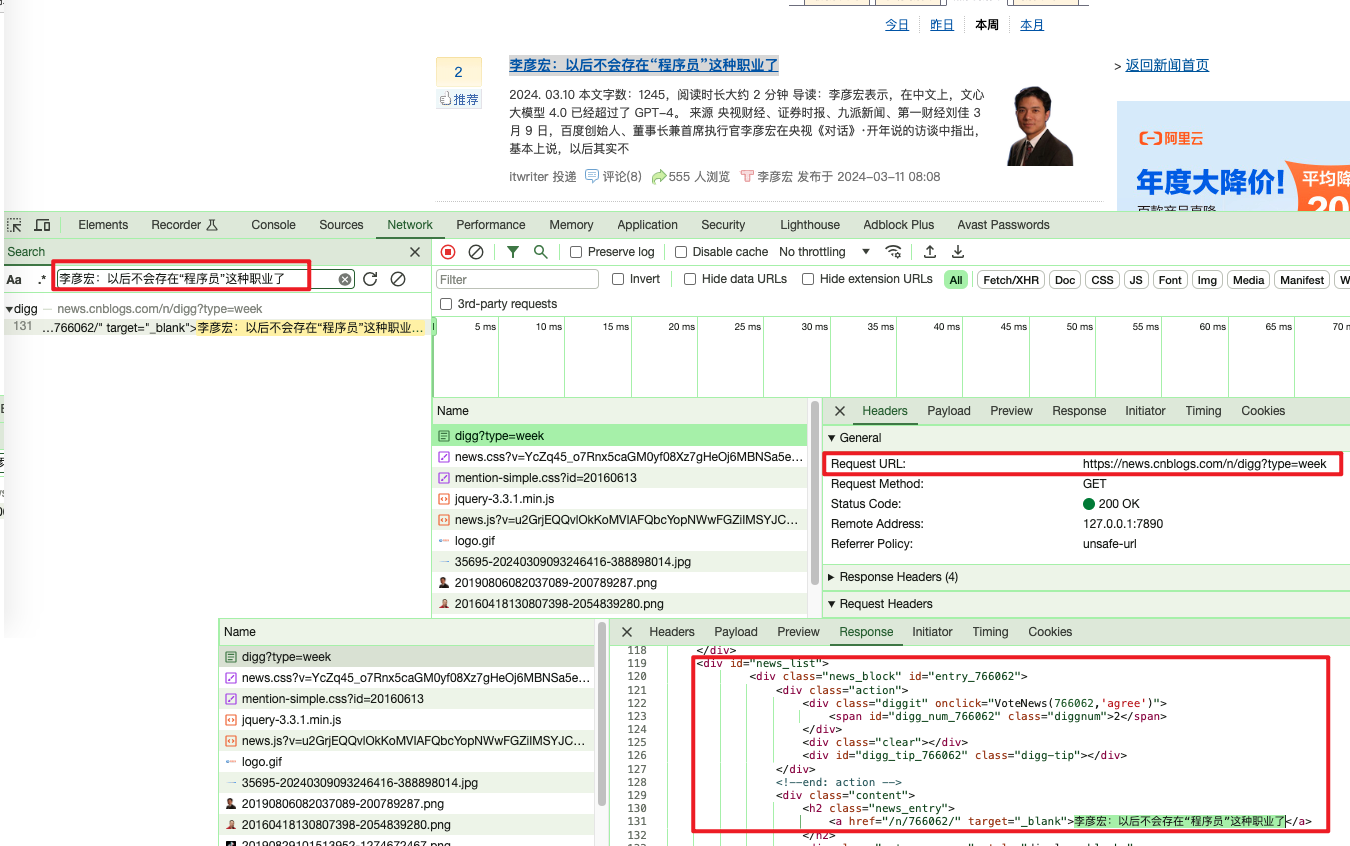
可以看到请求地址为https://news.cnblogs.com/n/digg?type=week 但是返回的内容不是json格式,而是html源码,说明该页面是博客园后端拼接html源码返回给前端的,这里我们就不能简单的直接通过API接口来获取数据了,还需要对html源码进行解析。
1.2、分析页面
点击查看元素,然后点击新闻标题。
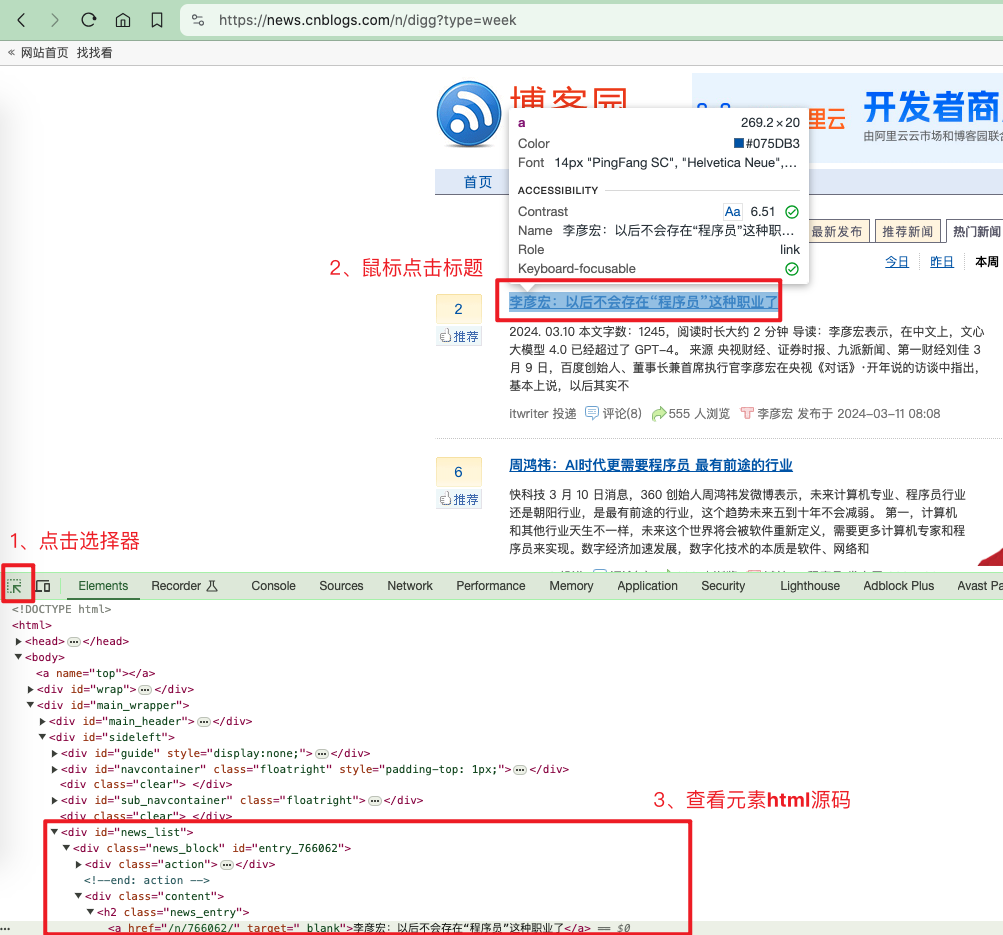
对应的html源码是<a href="/n/766062/" target="_blank">李彦宏:以后不会存在“程序员”这种职业了</a>
通过源码我们可以看出,标题是被一个id=news_list的div包裹,然后news_div下还有news_block这个div包裹,然后是逐级向下,一直到a标签才是我们想要的数据。

1.3、分页信息处理
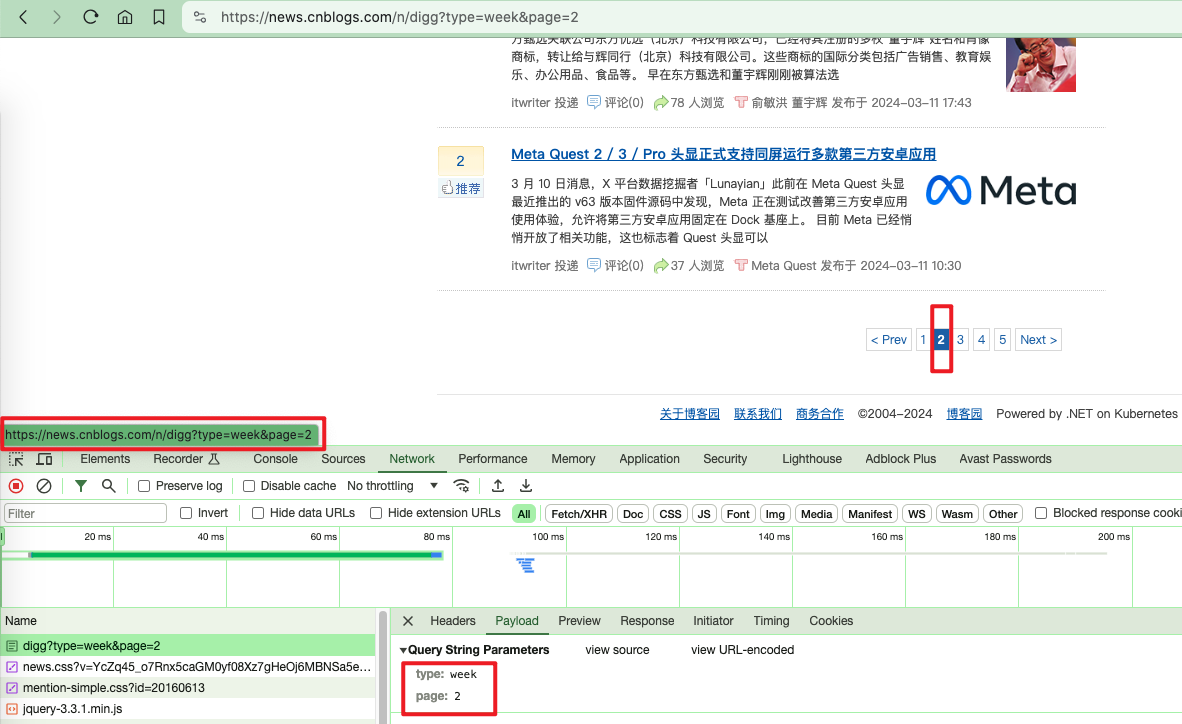
通过页面分析,可以看到分页很简单,直接在Query String QueryParamters里传入type: week、page: 2两个参数即可。
1.4、判断反爬及cookie
如何判断该请求需要哪些header和cookie参数?或者有没有反爬策略
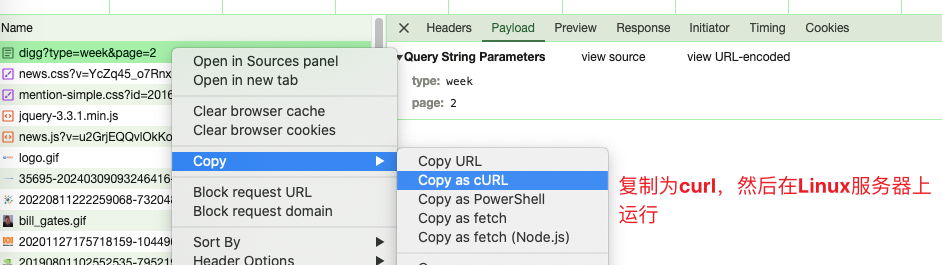
首先拷贝curl,在另一台机器上运行,curl代码如下
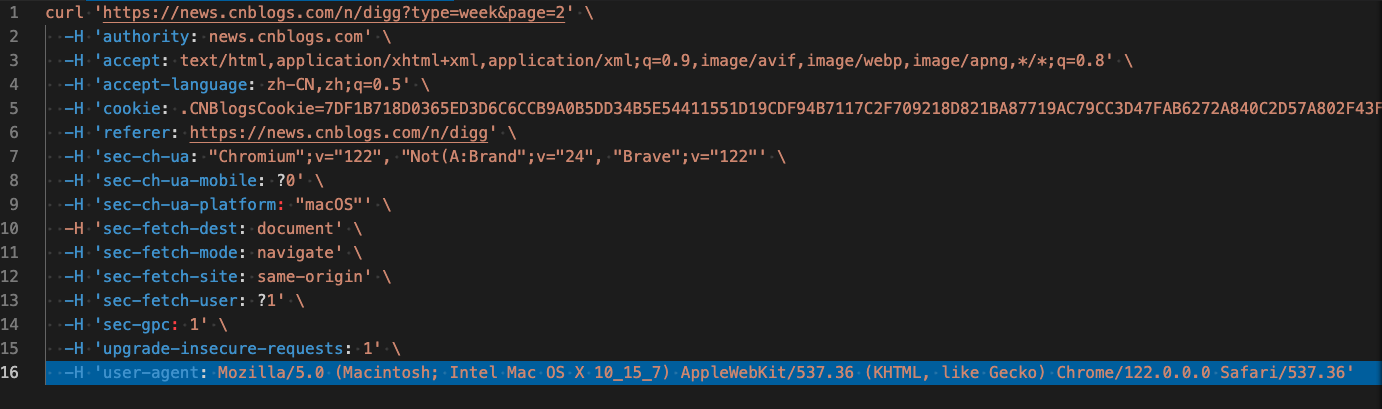
通过逐步删除代码中header参数来判断哪些是必要的参数,首先把cookie参数删除试试,发现可以获取到结果。由此判断,该网站没有设置cookie请求机制。
那就很简单了,直接发请求,解析html源码。
二、代码实现
新建Cnblogs类,并在init里设置默认header参数
class Cnblogs:
def __init__(self):
self.headers = {
'authority': 'news.cnblogs.com',
'referer': 'https://news.cnblogs.com/n/digg?type=yesterday',
'user-agent': USERAGENT
}
新建获取新闻get_news函数
def get_news(self):
result = []
for i in range(1, 4):
url = f'https://news.cnblogs.com/n/digg?type=today&page={i}'
content = requests.get(url)
html = etree.HTML(content.text)
news_list = html.xpath('//*[@id="news_list"]/div[@class="news_block"]')
for new in news_list:
title = new.xpath('div[@class="content"]/h2[@class="news_entry"]/a/text()')
push_date = new.xpath('div[@class="content"]/div[@class="entry_footer"]/span[@class="gray"]/text()')
result.append({
"news_title": str(title[0]),
"news_date": str(push_date[0]),
"source_en": spider_config['name_en'],
"source_cn": spider_config['name_cn'],
})
return result
代码主要使用了requests和lxml两个库来实现
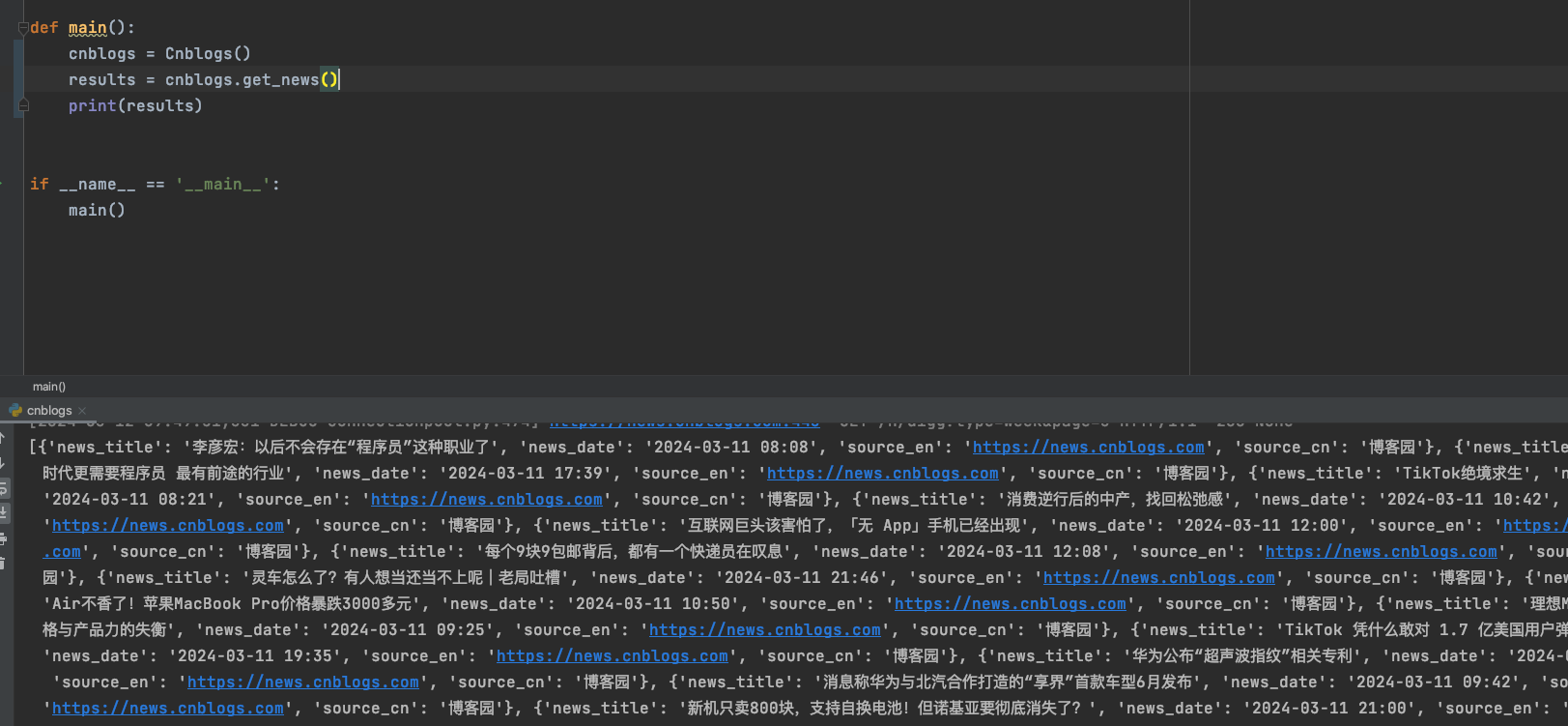
测试运行
def main():
cnblogs = Cnblogs()
results = cnblogs.get_news()
print(results)
if __name__ == '__main__':
main()
完整代码
# -*- coding: utf-8 -*-
import os
import sys
import requests
from lxml import etree
opd = os.path.dirname
curr_path = opd(os.path.realpath(__file__))
proj_path = opd(opd(opd(curr_path)))
sys.path.insert(0, proj_path)
from app.utils.util_mysql import db
from app.utils.util_print import Print
from app.conf.conf_base import USERAGENT
spider_config = {
"name_en": "https://news.cnblogs.com",
"name_cn": "博客园"
}
class Cnblogs:
def __init__(self):
self.headers = {
'authority': 'news.cnblogs.com',
'referer': 'https://news.cnblogs.com/n/digg?type=yesterday',
'user-agent': USERAGENT
}
def get_news(self):
result = []
for i in range(1, 4):
url = f'https://news.cnblogs.com/n/digg?type=week&page={i}'
content = requests.get(url)
html = etree.HTML(content.text)
news_list = html.xpath('//*[@id="news_list"]/div[@class="news_block"]')
for new in news_list:
title = new.xpath('div[@class="content"]/h2[@class="news_entry"]/a/text()')
push_date = new.xpath('div[@class="content"]/div[@class="entry_footer"]/span[@class="gray"]/text()')
result.append({
"news_title": str(title[0]),
"news_date": str(push_date[0]),
"source_en": spider_config['name_en'],
"source_cn": spider_config['name_cn'],
})
return result
def main():
cnblogs = Cnblogs()
results = cnblogs.get_news()
print(results)
if __name__ == '__main__':
main()
总结
通过以上代码,我们实现了采集博客园的功能。
本文章代码只做学习交流使用,作者不负责任何由此引起的法律责任。
各位看官,如对你有帮助欢迎点赞,收藏,转发,关注公众号【Python魔法师】获取更多Python魔法~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号