尚硅谷-ShardingSphere
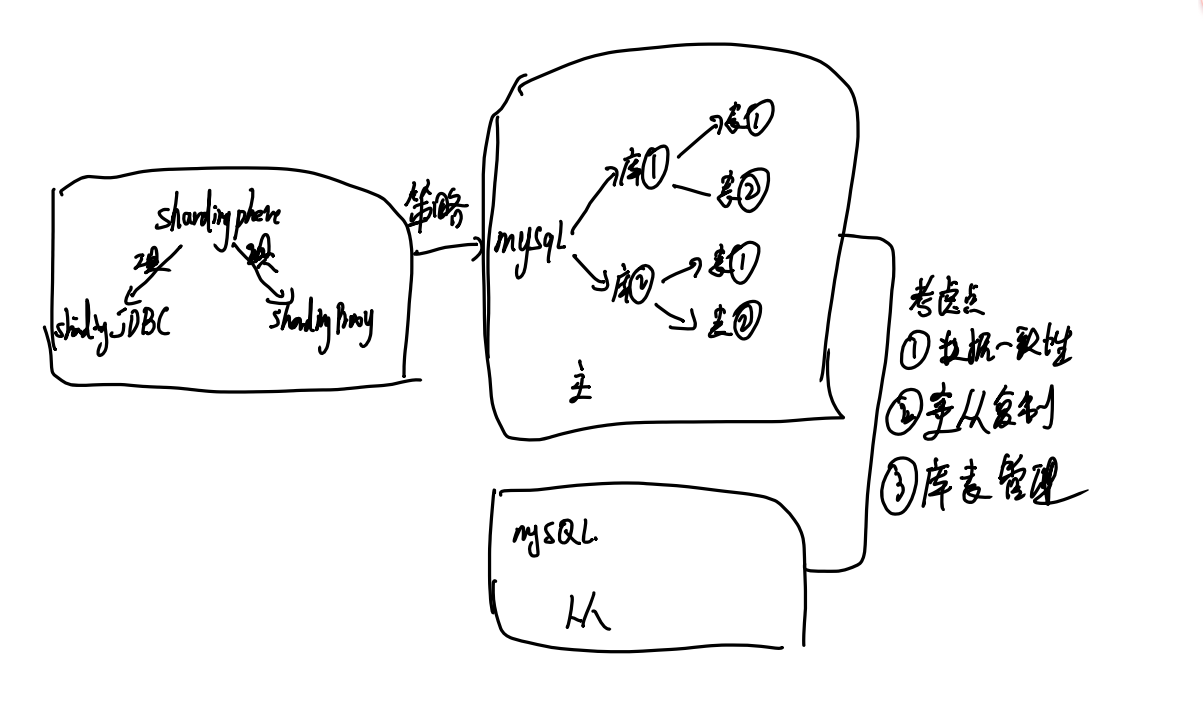
分库分表重点还是在于数据一致性,主从复制和库表管理底层原理,本质上根据配置文件入不同库,入不同表还是很简单的。
学习链接:https://www.bilibili.com/video/BV1LK411s7RX?p=23&vd_source=510ec700814c4e5dc4c4fda8f06c10e8
目录
🔥1. 基本概念
1.1. 基本名词
1.1.1 ShardingSphere
分布式数据库中间件
1.1.2 产生场景
由于数据量不断增大,原始可以使用硬件优化,现在需要增加分库分表
分库分表分为垂直切分和水平切分
1. 垂直切分
1. 垂直分表:同一张表拆分字段存入不同表
2. 垂直分库: 不同业务表存入不同业务的数据库
2. 水平切分
1. 水平分表:可以根据id拆分表数据导不同表中
2. 水平分库:表数据水平存到不同数据库中,避免请求打到同一个库中。不同库中库表结构都是一样的
1.1.3 场景变迁
1. 数据库设计的时候考虑垂直分库、垂直分表
1. 数据量增加,优先考虑缓存、读写分离、索引、数据库硬件、数据库选择等方式解决,实在解决不了了再考虑水平分库分表
但存储几个问题:不同服务器数据库之间如何管理
1.2 基本使用
1.2.1 Sharding-JDBC
用于数据分片和读写分离,操作不同数据库的表,并不是分库分表
1.2.1.1 水平分表
-
导入shardingshpere、druid依赖包
-
把原始spring.datasource删除,使用sharding-datasource的properties配置文件
-
配置bean的覆盖策略
spring.main.allow-bean-definition-overriding=true -
后续就能实现原始代码也能正常CRUD,course_1, course_2的插入和查询采用分片策略进行查询与插入
1.2.1.2 垂直分库、公共表(略)
1.2.1.3 读写分离(略)
就是主写从读,从数据库通过读取binlog实时把数据拉取过来
1.2.2 Sharding-Proxy
数据库代理端
1.3 个人小结
我曾七次鄙视自己的灵魂:
第一次,当它本可进取时,却故作谦卑;
第二次,当它在空虚时,用爱欲来填充;
第三次,在困难和容易之间,它选择了容易;
第四次,它犯了错,却借由别人也会犯错来宽慰自己;
第五次,它自由软弱,却把它认为是生命的坚韧;
第六次,当它鄙夷一张丑恶的嘴脸时,却不知那正是自己面具中的一副;
第七次,它侧身于生活的污泥中,虽不甘心,却又畏首畏尾。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix