尚硅谷-JVM-内存和垃圾回收篇(P1~P203)
老师好喜欢讲一些题外话,适合上学的人听,挺有意思的。找工作的话就快进。而且发现JavaGuide上有些东西讲的是不准确的,还是要以尚硅谷为准
本文默认环境:
HotSpot虚拟机JDK1.8
JVM上篇:内存与垃圾回收篇:
链接:https://pan.baidu.com/s/1TcHFE6YEk32Td_zXpZRSrg
提取码:7jc7
JVM中篇:字节码与类的加载篇:
链接:https://pan.baidu.com/s/1k6TmnpRqXro5DjCMBz0Qgg
提取码:sdxw
JVM下篇:性能监控与调优篇:
链接:https://pan.baidu.com/s/1MZoq_tsNCg2Cx_xIasSJng
提取码:qrbt
🔥1. 内存和垃圾回收篇(P1~P203)
1.1. 基本概念
1.1.1 名词解释
1.1.1.1 JVM概念
Java虚拟机(默认HotSpot虚拟机,内部提供JIT编译器):各种语言经过编译器后只要编译后的字节码符合JVM规则,则都能在JVM上运行
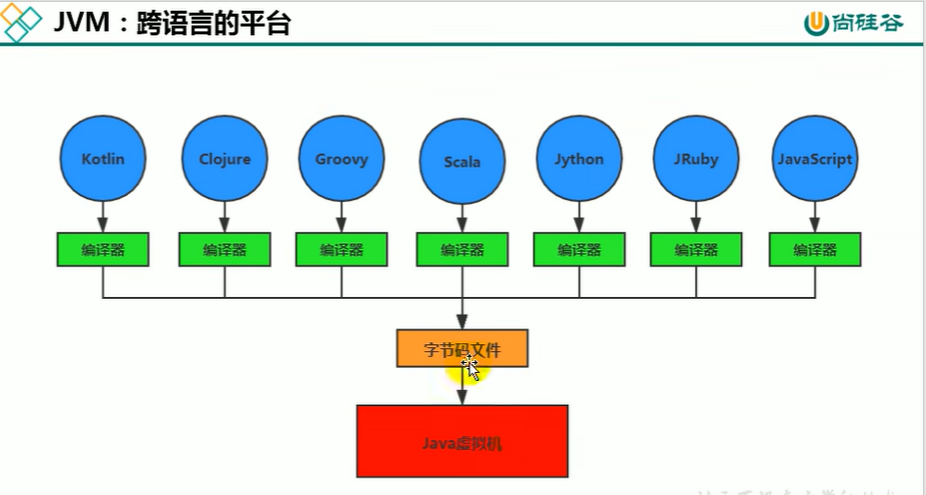
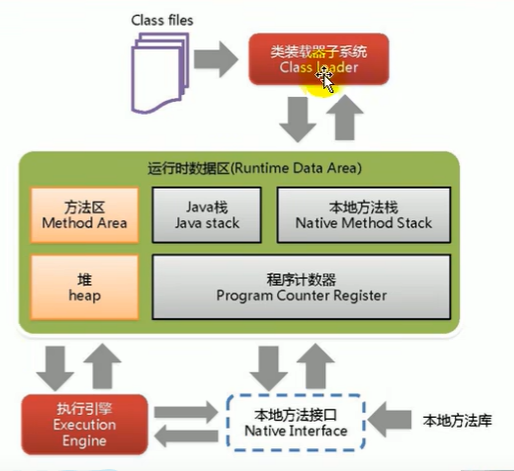
1.1.1.2 JVM整体结构
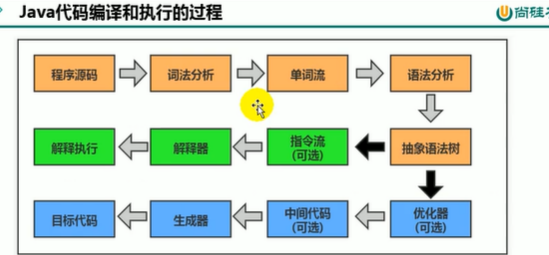
1.1.1.3 Java执行流程
1. Java源码进行编译成.class字节码
2. 字节码进入Jvm执行
3. 整个流程由OS控制
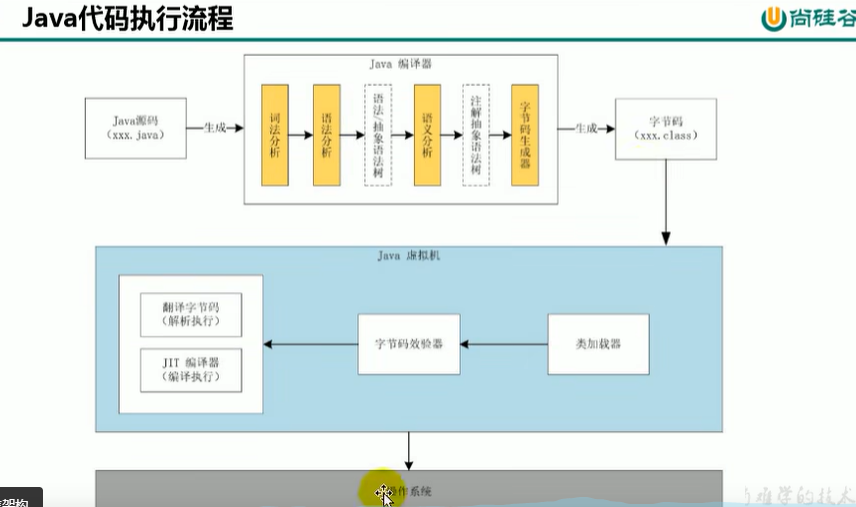
-- 对字节码文件进行反编译
javap -v JavaTest.class
1.1..1.4 JVM生命周期
- JVM启动是由类加载器加载一个初始类完成
- JVM执行就是执行一个JAVA程序
- JVM正常或异常退出
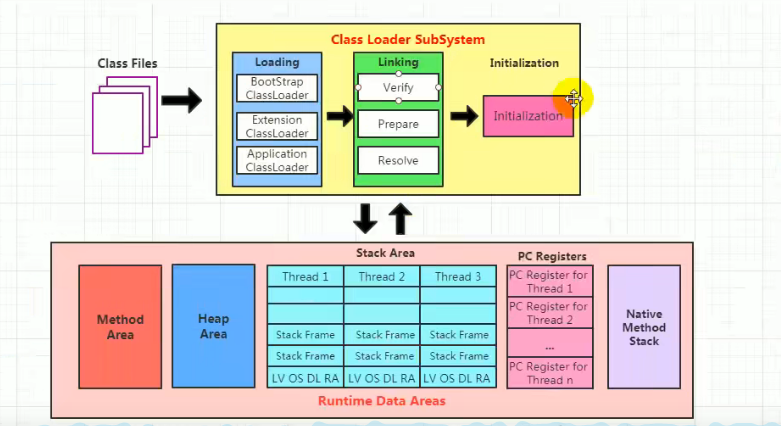
1.2 类加载子系统
1.2.1 基本概念
作用:把字节码.class文件加载到内存当中,生成一个大的class实例。所实现的三步骤就是加载、链接、初始化
1.2.2 双亲委派机制
原理:当类加载器收到加载一个class类加载请求时,会先递归给最顶级父类加载器加载,若找不到就递归返回让子类加载器依次加载寻找(比如定义了一个String类和java核心包中相同的类)
优点:
1. 避免类重复加载
2. 保护核心API被随意修改
沙箱:就是在一个受保护的虚拟环境下的环境,用户可以任意修改,不会对实际程序产生影响
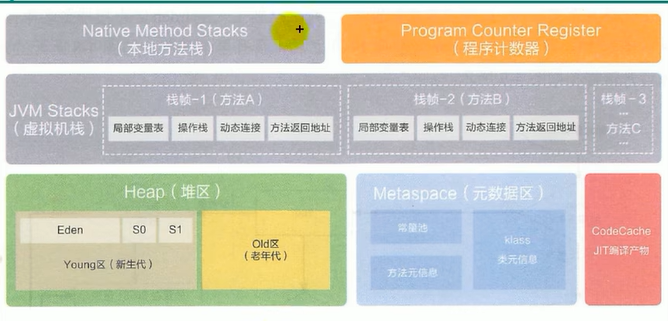
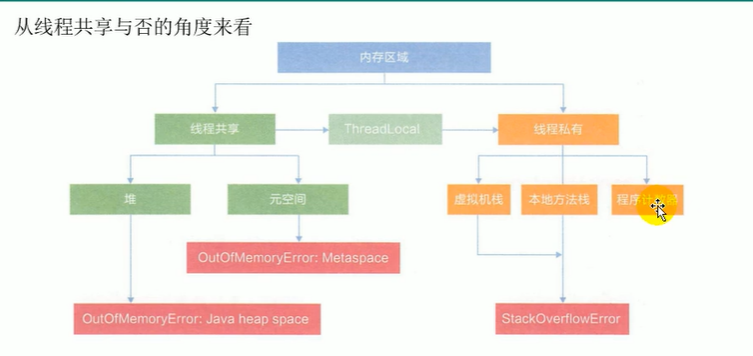
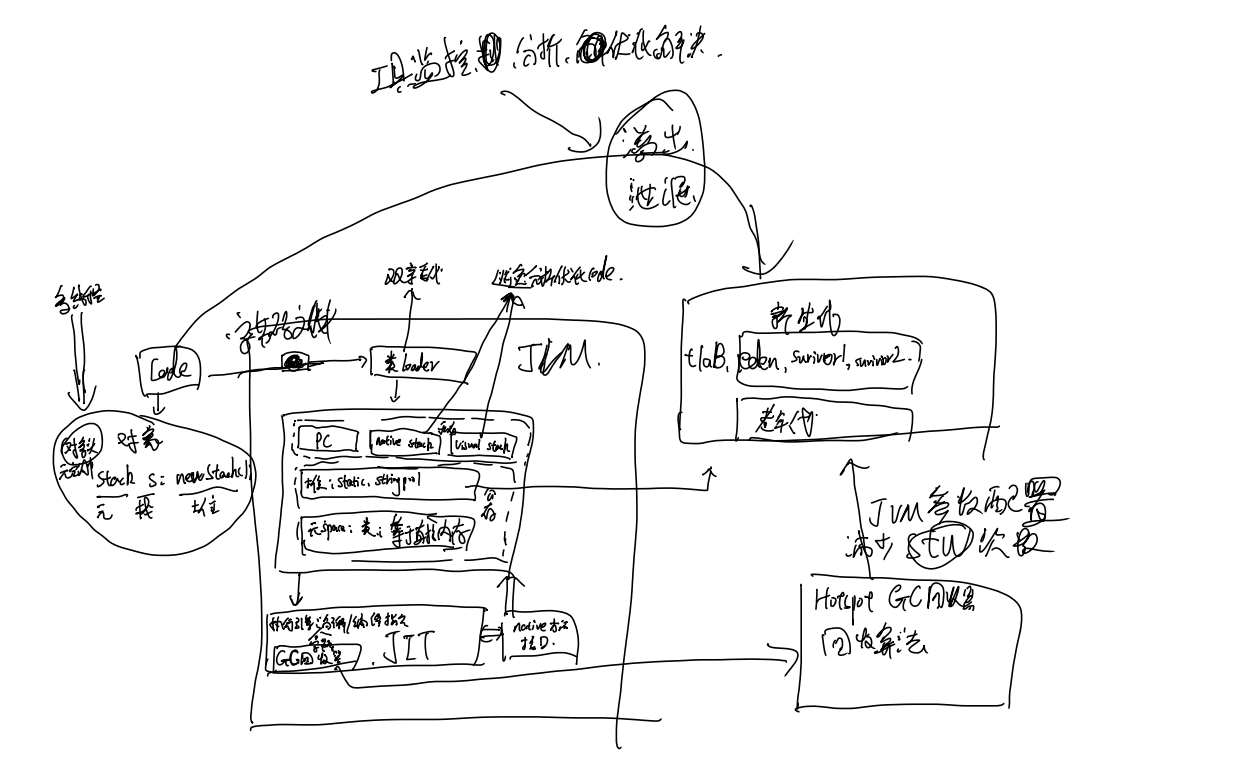
1.3 运行时数据区
1.3.1 基本架构
JVM启动后其实就是对应一个运行时环境,5个组件如下
1. 堆、元数据区:线程共享
1. 虚拟机栈、PC、本地方法栈
1.3.2 PC
PC寄存器:用于存下一条指令地址
1.3.3 虚拟机栈
1.3.2.1 基本概念
生命周期和线程一样,保存方法的局部变量,并参与方法的调用与返回。保存了局部变量表,内部包含基本数据类型和对象引用
1.3.3.2 栈异常
虚拟机栈大小是动态或者固定不变的
- StackOverFLowError: 线程申请栈容量超过Java虚拟机栈允许的最大容量
- OutOfMemoryEoor:线程拓展时申请不到内内存,或者创建线程申请虚拟机栈申请不到内存,就会报OOM
-Xss256k 设置栈空间大小
1.3.3.3 存储结构(略)
栈中数据以栈帧格式存在。
1.3.4 本地方法接口/本地方法库
不属于运行时数据区,但是供本地方法栈来调用
1.3.4 本地方法栈
虚拟机栈管理Java方法调用,本地方法栈管理本地方法调用
1.3.5 堆(*)
1.3.5.1 基本概念
1. 一个JVM实例只有一个堆内存,在启动时就创建了堆
2. 堆在物理上不连续,逻辑上连续
3. 堆中可以给不同线程划分私有的空间:TLAB
4. 对象实例几乎都在堆上分配(有些在栈上)
/*
当执行完s1后,s1在栈中就出栈了,s1在堆中指向的实例不会立马GC,s1所在的方法也保存在方法区中,如下图所示
*/
String s1 = new SimpleHeap()
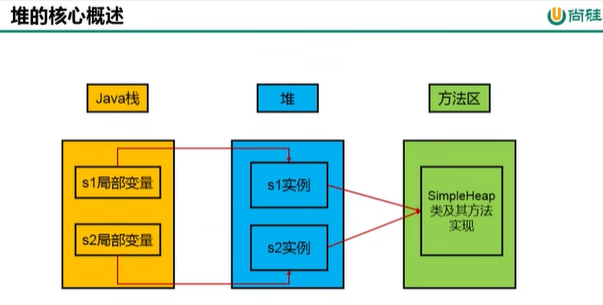
//设置堆的最小和最大空间 每启动一个main程序都会申请一个堆内存
-Xms10m -Xms10m
1.3.5.2 基本结构
- 新生代:分为Eden区和Survivor区。
- 老年代
- 元空间:(jdk1.7之前叫永久代)
// 输出3个空间大小情况。程序执行完才打印
-Xms20m -Xms20m -XX:+PrintGCDetails
1.3.5.3 堆空间参数设置
初始内存大小:物理内存 / 64
最大内存大小:物理内存 / 4
// -Xms和-Xmx一般设置成一样,避免扩容产生的不必要系统压力
-Xms 堆空间(新生 + 老年)初始内存大小
-Xmx 对空间最大内存大小
/*
1. 查看空间容量:-XX:+PrintGCDetails
2. jsp查看进程 jstat -gc 进程号 查看容量
3. -XX:+PrintFlagsInitial 查看所有参数默认值
4. -XX:+PrintFlagsFinal 查看所有参数最终值
*/
1.3.5.4 新生代/老年代参数设置
1. 大部分Java对象都是在Eden中new出来,也是在新生代销毁
1. 新生代和老年代内存比例默认是1: 2
-XX:NewRatio: 设置老年代所占比例
-XX:Survivorratio: Eden空间和Survivor默认比例8:1:1,但是由于自适应分配策略,可能是6:1:1
1.3.5.5 对象分配
- 先在新生代-Eden区分配,满了进行YGC,存活下来的进入Survivor-from并给age+1
- 下次新生代-Eden满了YGC,Eden存活下来的和Survivor-From进入Survivor-To,然后Survivor-to变成survivor-from,原始survivor-from变成survivor-to,让age+1。每次GC都会对eden和survivor进行回收。
- survovor-from达到阈值15之后会进入老年代。
注意点:
- survivor中s0, s1不会进行触发YGC,只是每次Eden中YGC时会顺便把survivor中回收。YGC后复制之后有交换,谁空谁是to
- 频繁在新生代回收,很少在老年代回收,几乎不在元空间回收
- Eden中GC后就空了。Survivor中如果存不下就会放入老年代
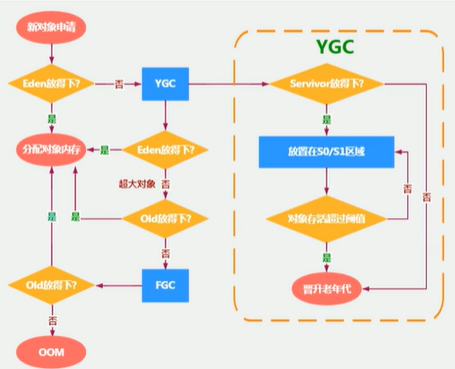
1.3.5.6 回收策略
由于GC单独有回收线程,会暂停用户线程的运行,所以实际调用就是需要减少GC频率
1. 部分收集
1. 新生代收集:MinorGC/YoungGC
2. 老年代收集:MajorGC/OldGC (CMS GC会单独收集老年代)
3. 混合收集:新生代和老年代混合收集(G1 GC特有)
2. 整堆收集:整个java堆和方法区的垃圾回收
Minor GC:
- Java对象大多朝生夕灭,所以MinorGC非常频繁
- MinorGC会引发STW(stop the world),暂停用户线程,等待回收完再恢复执行
Major GC:
1. Major GC速度比MinorGC慢10倍以上,STW时间也更长
1.3.5.7 TLAB
TLAB(Thread Local Allocation Buffer):在Eden中为每一个线程快速分配私有缓存。但所占空间很小
-- 查看TLAB:默认开启
jps
jinfo -flag UseTLAB 进程号
- 字节码文件经过类加载子系统
- 先由TLAB分配,不行JVM用加锁机制走Eden那一套内存分配
- 分配好后进行对象实例化,对象引用入栈,PC+1
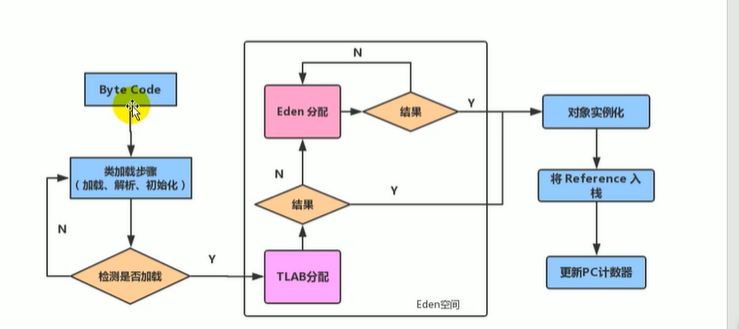
1.3.5.8 逃逸分析--栈上分配对象
- 堆可以分配对象
- 栈上也可以分配对象:若一个对象实例只在方法内部使用,那么JIT编译器在编译期间经过逃逸分析就能再栈上分配,方法一退出就能回收对象。XXX.getInstance获取对象实例会发生逃逸
//默认开启
-XX:+DoEscapeAnalysis
//未逃逸,栈上分配
public static String createStringBuffer(String s1, String s2){
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append(s1);
stringBuffer.append(s2);
//内部重新new String,方法中堆stringBuffer采用栈上分配,没有发生逃逸,方法退出就能回收对象实例
return stringBuffer.toString();
}
1.3.5.9 逃逸分析--同步省略
经过逃逸分析,如果一个对象只能从一个线程访问到,那么对于对象的同步可以不考虑,提高并发性和性能,叫锁消除
/**
* Author: HuYuQiao
* Description:
* 由于每次来都会new个新对象,所以synchronized实际锁失效了,所以可以同步省略,
* 免去加锁流程.
*
*/
public static void f(){
Object o = new Object();
// 以下JIT编译阶段优化成:System.out.println(o.toString());
synchronized (o){
System.out.println(o.toString());
}
}
1.3.5.10 逃逸分析--标量替换
类:聚合量 基本数据类型:标量
经过逃逸分析,若一个类的对象实例只在某个方法中使用,就把类替换成各个标量。也是默认开启
1.3.5.11 逃逸分析--总结
- 逃逸分析:是JIT编译优化时的一种分析方法
- 逃逸分析目前并不成熟,但是JVM也是引入了
- 静态变量分配在堆上,其实也可以默认对象都分配在堆中,结合栈上分配讲解即可
1.3.6 方法区
1.3.6.1 基本概念
- PC没有异常,也没有GC
- 虚拟机栈、本地方法栈有异常,没有GC
- 堆、元空间,有异常,有GC
元空间使用的是本地内存(电脑内存,而不是JVM内存)。若系统定义过多类,方法区也会报错OOM:metaspace。
1.3.6.2 方法区/栈/堆--交互关系
/*
User: 类的信息在方法区
user: 引用变量或基本数据类型在栈
new User(): 对象实例在堆
*/
User user = new User();
1.3.6.3 OOM简单排查思路
先看OOM是内存溢出还是泄漏
1. 内存泄漏:用GC ROOT查看泄漏代码位置
1. 内存溢出:查看是堆还是方法区溢出,调整参数大小
1.3.6.4 内部结构
- 存储类相关信息
存储静态变量:定义一个空对象,也能直接调用对象的静态变量,说明静态变量是存在方法区的- 运行时常量池:类的相关信息,
字符串常量池(代码定义的"字符串")
1.3.6.5 运行时常量池
字节码文件中存在常量池,类加载子系统把常量池加载到方法区中,就是运行时常量池。所以需要分析常量池
常量池:内部包含了各种符号引用:比如下面存的String, System指向父类引用,"存储在运行时常量池中"这种字符串常量池符号,在运行时才会加载其父类
运行时常量池:把常量池中存的符号引用转成真实地址,String,System这些真实的父类
public static void main(String[] args) {
Order order = null;
System.out.println(order.count + "存储在运行时常量池中");
}
1.3.6.6 字符串常量池、静态变量
堆:
- 字符串常量池:就是代码定义的"字符串",包括一些常量折叠什么的(之所以放到堆中,就是因为实际代码中定义字符串情况很多,放到堆中便于GC回收)。(区分字符串常量池和运行时常量池,两者是不同的东西)
- 静态变量:static int a这种
方法区:依然保存类的相关信息
(人都傻了,关于字符串常量池、静态变量这2个东西网上众说纷纭,感觉不用太较真,先默认在堆中,说不定面试官都不晓得在哪里)
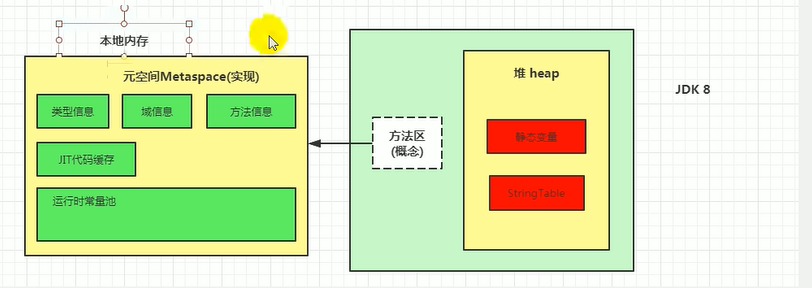
1.3.7 直接内存
1.3.7.1 基本概念
元空间的具体实现就是直接内存(也叫本地内存,直接内存包含了元空间)
1.3.7.2 IO/NIO
| IO | NIO(非阻塞IO) |
|---|---|
| Byte/char | Buffer |
| Stream | Channel |
1.3.7.3 基本流程
原始流程:CPU(线程) -> 内存(JVM)->(需要进行用户态和内核态切换) 磁盘
直接内存:CPU->磁盘(减少了用户态到内核态切换),适合频繁读写磁盘
1. 直接内存回收成本高,不受JVM内存回收管理
1. 也会导致OOM
1.4 对象实例化
1.4.1 创建对象方式
- new
- Class.newInstance,Constructor.newInstance
- clone()
- 反序列化获取
- 第三方库
1.4.2 创建对象步骤
-
判读对象所属的类是否加载、链接、初始化
-
为对象分配内存
- 内存规整:指针碰撞
- 内存不规整:空闲列表
-
处理分配内存时候的并发安全问题
-
初始化分配到空间
-
设置对象的对象头
-
执行构造器相关的init方法进行初始化
1.4.3 对象内存布局
- 对象头
- 运行时元数据markword(hashcode, 哪个线程持有锁,锁次数,GC分代年龄)
- 类型指针:对象所属类的信息
- 实例数据:父类继承、本类的实际字段
- 对齐填充:为了补位填充的无用数据
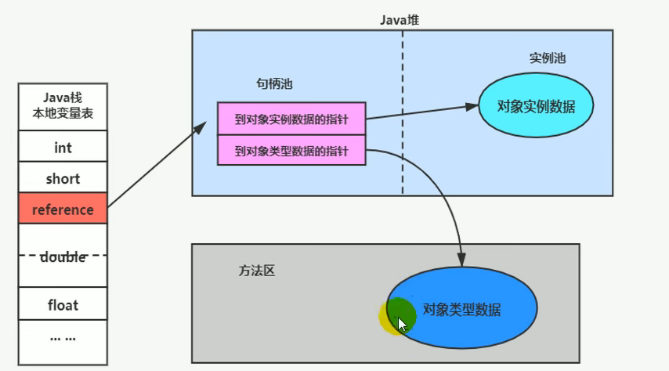
1.4.4 对象访问方式
-
句柄访问:栈先访问到堆中句柄池,然后一个指向实际数据,一个类型指针指向对象所属类信息
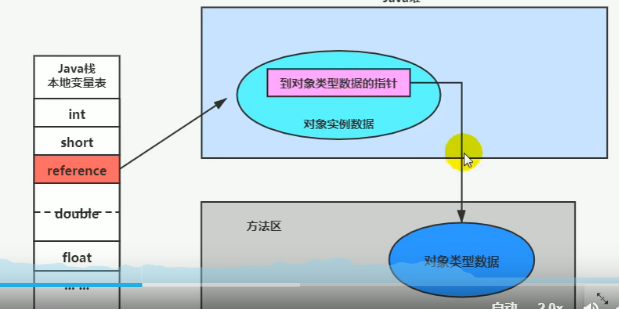
-
直接指针(HotSpot默认):
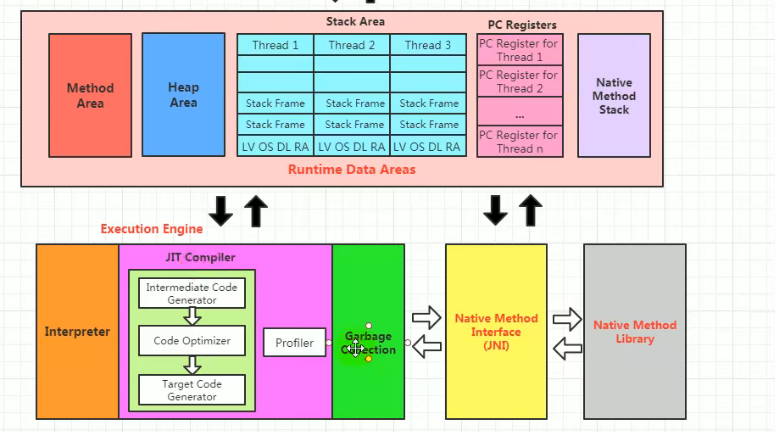
1.5 执行引擎
1.5.1 基本概念
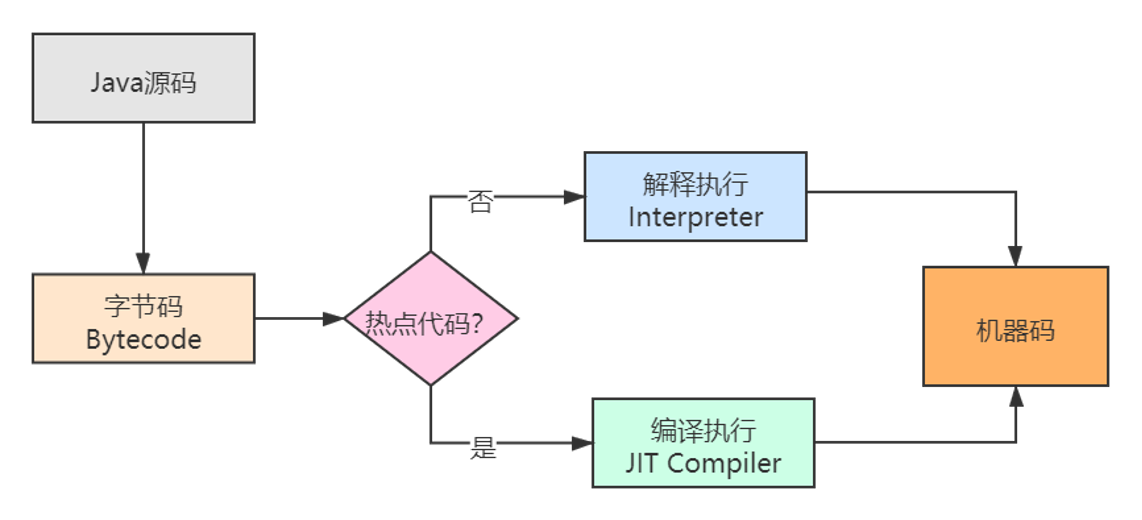
执行引擎是将字节码指令解释/编译成平台上的机器指令。依赖于PC计数器识别一条条指令
1.5.2 编译与解释
Java也是对代码进行JIT编译(快)和解释执行(慢,但是启动的时候就可以发挥作用)一起执行。
栈上替换:JIT编译器把热点代码编译成本地机器指令
1.5.3 垃圾回收
1.5.3.1 基本概念
垃圾:没有任何指针指向的对象(和基本数据类型无关)
垃圾回收:回收永久代和堆中(频繁回收新生代,较少老年代,几乎不动永久代),(类似于理财管理,也提供了对理财管理的监控),垃圾回收又分标记和清除(类执行完成之后可以进行回收,代码执行的时候内存不足也会触发)
1.5.3.2 GC--标记
1. 引用计数(Java没使用):给每个对象分一个引用计数器,没有引用指向就回收
1. 可达性分析(Java使用):从对象集合GC Roots 从上到下进行引用链搜索,不能查到的就是垃圾对象
finalize:对象销毁前做的调用的操作
1.5.3.3 Jprofile--OOM排查
1. 配置参数:-Xms8m -Xmx8m -XX:+HeapDumpOnOutOfMemoryError
1. Java VisualVM打开XXX.hprof,然后就能查看到相关内存情况
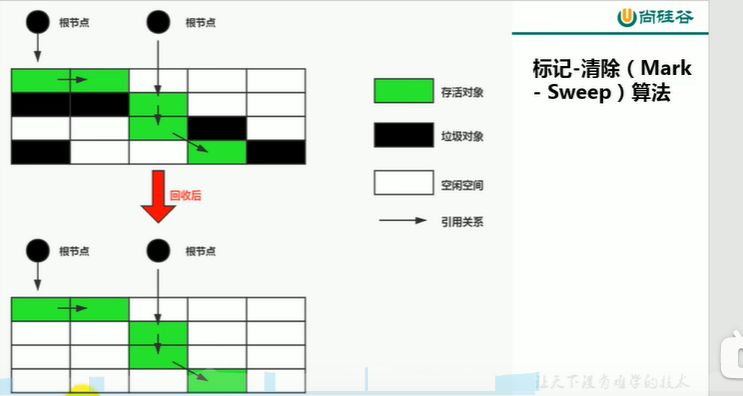
1.5.3.4 GC--清除
1. MS(mark-sweep标记-清除):先利用可达性标记,然后清除,容易产生内存碎片,还会STW用户线程。**清除也不是真的置Null,而且把对象放入空闲空间,下次新对象使用就能复用这一块地址**
1. 
2. MC(Mark-Compact标记-整理算法):先标记,然后清除,然后整理排好,避免内存碎片
3. CP(coping复制算法):内存分2半,每次用一般,然后把可达对象复制到另一半中(和survivor2个区一样 )
4. 分代收集算法(常见):就是分成新生代和老年代,不同对象采用不同的收集算法(Http的session对象、线程就生命周期长。String就生命周期短,内部还是上面MS,MC,CP)
5. 增量收集算法:处理stw下垃圾回收线程和用户线程的冲突,底层还是MS,CP,MC
1.5.3.5 System.gc
System.gc:进行一次full GC,但是不确定是否立刻GC,但是最终会GC
1.5.3.6 内存溢出/泄漏
内存溢出:可用内存不够,无法申请
内存泄漏:无用内存太多,却无法回收
1. 单例的Runtime生命周期很长,分配一个引用对象的话,那么那个引用对象就很难回收
1. 和外部的数据库连接、socket连接,如果不关闭的话就无法回收
1.5.3.7 STW
stop the world ,由于GC Root 是不断变化的,在垃圾回收的时候要保证数据一致性,就需要暂停用户线程,根据GC Root 进行垃圾回收,这种在GC时候暂停用户线程就叫STW
1.5.3.8 垃圾回收--并发与并行
垃圾回收-并行:多条垃圾回收线程并行工作,用户线程STW
垃圾回收-并发:垃圾回收线程和用户线程并发工作,中间穿插STW
1.5.3.8 安全点和安全区域
在程序执行的时候,对于选定STW时间点很重要,在那种循环、调用方法执行时间长的地方选定STW,就叫安全点。如果程序阻塞了,那么程序这一段区域内也能进行STW,然后进行GC,这一段区域就叫安全区域
1.5.3.9 强软弱虚引用(略)--JUC讲过
1.5.4 垃圾回收器
1.5.4.1 性能指标
在下面2个指标中找个折中办法
1. 吞吐量 : 运行用户代码时间 / (运行用户代码时间 + 垃圾收集时间)
1. 暂停时间
1.5.4.2 基本分类
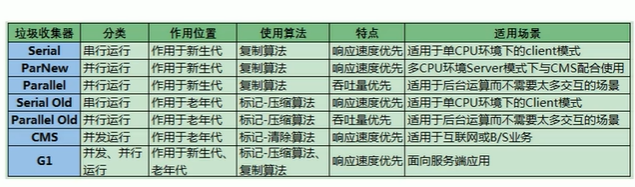
1. 串行回收器:Serial, Serial Old
1. 并行回收器: ParNew, Paralled Scavenge, Parallel Old
1. 并发回收器:CMS, G1
1.5.4.3 jdk8默认垃圾回收器
默认UseParallelGC(新生代 cp算法 吞吐量优先) + ParallelOldGC(老年代 mc算法) 。 可以在JVM参数中配置相应的垃圾回收器
C:\Users\EDY>jps
14416 GCUseTest
22576 Jps
45240 RemoteMavenServer36
13484 Launcher
14556 RemoteMavenServer36
39372
C:\Users\EDY>jinfo -flag UseParallelGC 14416
-XX:+UseParallelGC
C:\Users\EDY>jinfo -flag UseParallelOldGC 14416
-XX:+UseParallelOldGC
1.5.4.4 垃圾回收器选择
最小化内存用Serial GC
最大化吞吐量用Paralled GC
最小化GC中断时长用CMS
1.5.5 GC--回收日志与导出
--打印GC日志
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:gc.log

1.6 String
1.6.1 基本概念
1.6.1.1 不可变
内部是final的char数组,申明的话是在堆的字符串常量池重新创建,然后赋值,且字符串常量池中相同字符串数据唯一
private final char value[]
1.6.1.2 实现原理
String的字符串池是采用HashTable(数组+链表)实现,因为有Hash值计算,所以字符串常量池数据不重复。
1.6.1.3 面试考点
1. String s1 = s2 + "":出现了s2这种变量,返回结果就是重新在堆new了个对象 new String()。底层是StringBuilder非线程安全(StringBuilder.toString就是重新new String()),所以并发环境下拼接字符串应该用StringBuffer(final String的话就没有这种情况,因为就变成常量了)
1. s1.intern():返回s1常量池中字符串,没有则重新在常量池创建一个返回
1.7 个人小结
我曾七次鄙视自己的灵魂:
第一次,当它本可进取时,却故作谦卑;
第二次,当它在空虚时,用爱欲来填充;
第三次,在困难和容易之间,它选择了容易;
第四次,它犯了错,却借由别人也会犯错来宽慰自己;
第五次,它自由软弱,却把它认为是生命的坚韧;
第六次,当它鄙夷一张丑恶的嘴脸时,却不知那正是自己面具中的一副;
第七次,它侧身于生活的污泥中,虽不甘心,却又畏首畏尾。

