谷粒商城--分布式高级篇P129~P339(完结)
谷粒商城--分布式高级篇P129~P339
视频地址:https://www.bilibili.com/video/BV1np4y1C7Yf?p=339&vd_source=510ec700814c4e5dc4c4fda8f06c10e8
代码地址:https://gitee.com/empirefree/gullimall/tree/尚硅谷--高级篇/
个人总结:学了里面很多架构设计思想,代码没怎么实敲,整个项目从前端到服务端到后端完整走一遍比较费时,建议有针对性学习。后面如果实际用到了设计思想再重新温习一遍
【谷粒商城--分布式基础篇P1~P27】: https://blog.csdn.net/Empire_ing/article/details/118860147
【谷粒商城--分布式基础篇P28~P101】https://mp.weixin.qq.com/s/5kvXjLNyVn-GBhNMWyJdpg
🔥1.Kibana--启动报错
突然发现kibana报错超时了,时间改成了60000重启解决了,然后设置kibana自动重启时又发现docker没有转发,设置后即改好了。
1.1.Kibana--Request Timeout after 30000ms
网上都说设置成40000,但是我设置后发现还是超时,应该是服务器性能太差了,改成60000就解决了(另外也可以改es内存,但我服务器内存不够用,改了连es都起不来了,所以没改es,而且变相改的kibana时间)
[root@VM-8-11-centos ~]# docker exec -it kibana /bin/bash
bash-4.2$ vi /opt/kibana/config/kibana.yml
elasticsearch.requestTimeout: 60000
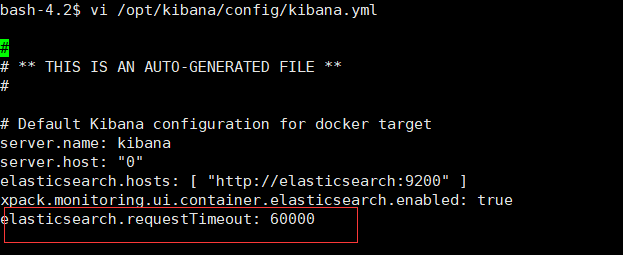
注:关于kibana是否超时可以通过docker logs kibana查看最后日志就能知道kibana是否成功启动以及失败原因了。
1.2 Docker--IPv4 forwarding is disabled. Networking will not work
重新配置转发,然后重启docker里面服务即可
# 1.配置转发
vim /etc/sysctl.conf
net.ipv4.ip_forward=1
# 2.重启服务,让配置生效
systemctl restart network
# 3.查看是否成功,如果返回为“net.ipv4.ip_forward = 1”则表示成功
sysctl net.ipv4.ip_forward
# 4.重启docker服务
service docker restart
# 5.查看运行过的容器
docker ps -a
注:如果network启动报错unit network.service could not be found,可以使用如下方法:
# 1.下载network
yum install network-scripts -y
# 2.查看network状态,正常即可以重启network了
systemctl status network
上述步骤完成后,就能看到正常的Kibana了。
🔥2.性能测试--Jmeter
P129~P140是后台上架商品整合ES与本地Nginx部署,由于我用的公网服务器,所以没整合域名,简单过了一遍。不过上架商品里面的逻辑与Nginx.conf文件讲解还是拓展了不少东西,可以好好学下,下面开始过Jmeter压力测试内容。
2.1.基本介绍
- 影响性能考虑点:(下方加黑的应该是开发需要注意的点,其余的可以交给运维去考虑)
数据库(索引,库表设计,分库分表等等)、应用程序(避免频繁操作数据库与请求第三方接口等等)、中间件(tomcat,Nginx)、网络与操作系统性能等方面。
- 应用属性
- CPU密集型:应用程序需要频繁计算
- IO密集型:应用程序需要频繁读写
#解决服务启动端口占用情况
netstat -ano | findstr "8080"
taskkill /F /pid 3572
2.2.Jmeter报错--Address Already in use
当Jmeter访问本地10000端口时,会报错端口已占用,解决方法如下:
1. 进入计算机\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters
2. 右键paramters, 新建Dword32的文件夹MaxUserPort,输入65534,基数十进制
3. 右键paramters, 新建Dword32的文件夹TCPTimedWaitDelay,输入30,基数十进制
4.重启电脑即可.
2.3 Jvm垃圾回收--简单流程介绍
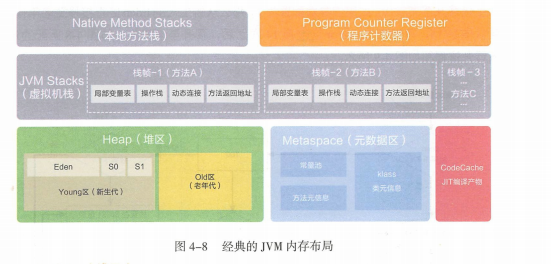
JVM内存布局涉及到Java线程内存的申请分配管理,而JVM中堆是线程共享,就不可避免的设计到Java多线程安全问题,所以其实JVM和并发编程都是不可分割开来的。
下面简单介绍JVM垃圾回收流程吧,后面重新整理篇详情的JVM。
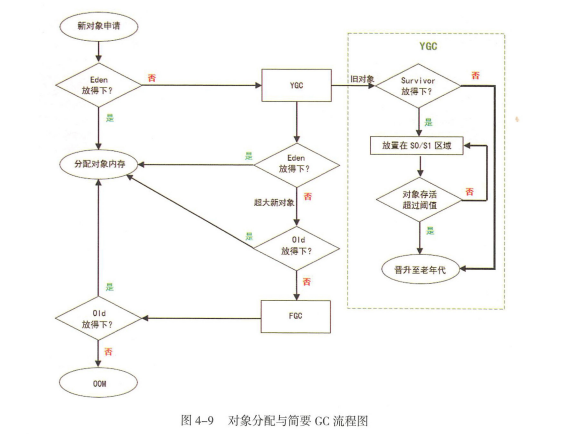
1.对象向堆中Eden区申请,能放下则放,放不下进行一次小YGC(针对新生代的GC,垃圾回收算法:MS,MC,CP,GC)。小YGC后存活对象放入survivor0,survivor1。survivor0满后也进行小YGC移入survivor1。多次存活下来的移入老年代。上述小YGC后如果Eden放不下,则放入老年代(每次YGC若某块内存没被GC调,存活就+1,达到阈值15就升级成老年代),老年代也放不下,报错OOM。
2.在survivor0/1移动的时候若老年代放得下则放,放不下者要进行一次FGC,FGC后也无法移动到老年代中,报错OOM。
3.FGC后老年代放得下放,放不下报OOM内存溢出
🔥3.缓存--本地、redis
3.1 本地缓存
类似于全局变量,不会被GC,会一直存在,直到进程结束,代码如下:
List<Student> menu = Stream.of(
new Student("刘一", 721, true, Student.GradeType.THREE),
new Student("陈二", 637, true, Student.GradeType.THREE),
new Student("张三", 666, true, Student.GradeType.THREE),
new Student("李四", 531, true, Student.GradeType.TWO),
new Student("王五", 483, false, Student.GradeType.THREE),
new Student("赵六", 367, true, Student.GradeType.THREE),
new Student("孙七", 1499, false, Student.GradeType.ONE)).collect(Collectors.toList());
@GetMapping("/testLocalCache")
public void testLocalCache(){
if (!CollectionUtils.isEmpty(menu)){
menu.remove(0);
System.out.println(JSON.toJSONString(menu));
} else {
menu.add(new Student("胡宇乔", 1499, false, Student.GradeType.ONE));
System.out.println(JSON.toJSONString(menu));
}
}
3.2 Redis缓存
- Redis基本概念:
缓存击穿:大量请求redis的key,但是该key过期了,全部去db查询 解决办法:大量并发请求加锁,第一个人先查,将查到的结果写入redis。后续查询也是加锁访问redis
缓存雪崩:大量请求redis的key,但是大量key过期,全部去db查询 解决办法:将key过期时间在原始过期时间基础上再加上一定的随机过期时间
缓存穿透:请求一个不存在于redis、db的key,类似于恶意攻击 解决办法:将缓存中存入一个短暂过期的null值。
-
Redis序列化--TypeReference
Reids一般是<string,jsonobject>存入,但是取出之后需要转化成原来的对象,除了可以用具体的类,还可以用TypeReference
//1、redis转化--转化成某个具体的类 Student student = JSONObject.parseObject(result, Student.class); //2、redis转化--转化成map或list数组 Map<String, List<Student>> resultMap = JSONObject.parseObject(result, new TypeReference<Map<String, List<Student>>>(){});- Redis--分布式锁
单体项目:synchronized锁住对象,static synchronized锁住方法,因为多个访问都是同一个项目,所以不会出现重复查库问题
分布式项目:
synchronized就不管用了,因为每个项目都独立运行。可以看到10000和10001都去查了数据库.
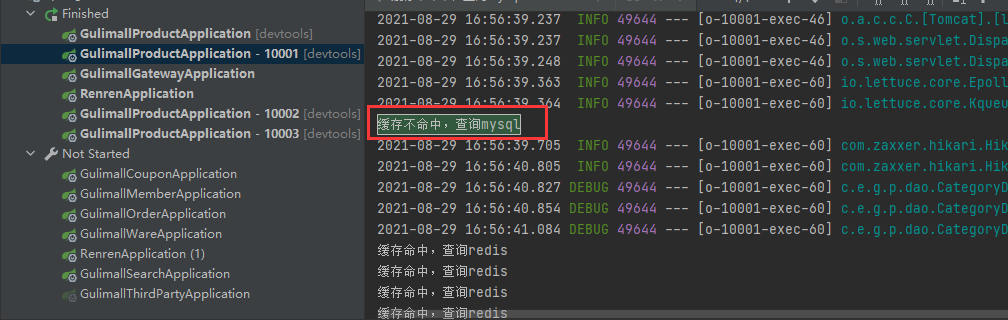

所以需要改成redis分布式锁,即用redis控制。
需要注意的点:(设置setIfAbsent和del值都要保证原子性)
1.设置value值要唯一、要有过期时间:如果value都是固定的值,那么其他进程删除分布式锁的时候会把所有进程的锁一起删掉,所以每个进程设置分布式锁value值要唯一。过期时间是为了保证加锁后,服务宕机了,后续就算启动了也没办法获得锁。故而设置分布式锁代码如下
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", uuid, 30, TimeUnit.SECONDS);2.删除value值:采用lua脚本保证删除的原子性,即如果上面设置过期时间太短,导致第一个进程还没运行到删除脚本这里来时,其他进程都发现可以获取锁了,然后第一个一删除,就会把库里多数进程的值都会删掉,这样就会有更多进程发现又可以获得锁了,高并发下依然会出现和上面一样,查了2次库的情况,而当采用lua脚本保证原子性操作后,redis发现第一个进程的key已经过期了,就不会删了,所以删除value值要保证原子性。故而删除分布式锁代码如下
String script = "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end"; Long lockResult = stringRedisTemplate.execute(new DefaultRedisScript<>(script, Long.class), Arrays.asList("lock"), uuid);完整代码如下:
/**
* Author: HuYuQiao
* Description: redis--设置、删除分布式锁--保证原子性
*/
@Override
public Map<String, List<Catelog2Vo>> getCatelogJsonFromDBWithRedisLock(){
// 1、占用分布式锁,设置30秒自动删除
String uuid = UUID.randomUUID().toString();
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", uuid, 30, TimeUnit.SECONDS);
if (lock){
System.out.println("获取分布式锁成功..");
Map<String, List<Catelog2Vo>> data = null;
try {
data = getCatelogJsonFromDb();
System.out.println("查库成功");
} finally {
String script = "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end";
Long lockResult = stringRedisTemplate.execute(new DefaultRedisScript<>(script, Long.class),
Arrays.asList("lock"), uuid);
System.out.println(lockResult);
}
System.out.println("返回成功");
return data;
} else {
System.out.println("获取分布式锁失败..");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
return getCatelogJsonFromDBWithRedisLock();
}
}
3.2 Redisson缓存
3.2.1 基本配置
上面使用了redis实现了分布式锁,下面介绍redisson来实现分布式锁
1.配置相关环境:dependency、config文件
<!-- https://mvnrepository.com/artifact/org.redisson/redisson -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.16.1</version>
</dependency>
package com.empirefree.gulimall.product.config;
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.io.IOException;
/**
* @program: renren-fast
* @description:
* @author: huyuqiao
* @create: 2021/09/05 11:28
*/
@Configuration
public class MyRedissonConfig {
@Bean(destroyMethod="shutdown")
public RedissonClient redisson() throws IOException {
Config config = new Config();
/* config.useClusterServers()
.addNodeAddress("127.0.0.1:7004", "127.0.0.1:7001");*/
config.useSingleServer().setAddress("redis://82.156.202.23:6379");
return Redisson.create(config);
}
}
2.redisson配置了看门狗机制,共有2点:(针对没有定义过期时间的key)
2.1.redisson的key值续期:在redisson实例过期之前,看门狗会不断续期key值过期时间,默认是自动续到30秒
2.2.redisson实例关闭后key值自动删除:为了防止某个实例宕机后死锁(之前redis是设置了过期时间,也可避免死锁),当redisson实例过期,比如A服务获得锁后宕机了,这时看门狗就不会续期了,30秒(默认时间)后删除key值,B服务就能获得锁了。
补充:看门口自动续期时间是 【自定义时间或 30】 / 3,如果设置自定义时间过小,业务还没处理完,redisson的key过期就会删了,然后业务执行完毕就会去删除其他业务的锁。
@Autowired
private RedissonClient redissonClient;
@ResponseBody
@RequestMapping("/hello")
public String hello(){
RLock lock = redissonClient.getLock("my-lock");
lock.lock();
try {
System.out.println("加锁成功...." + Thread.currentThread().getId());
TimeUnit.SECONDS.sleep(30);
} catch (Exception e) {
e.printStackTrace();
} finally {
System.out.println("释放锁..." + Thread.currentThread().getId());
lock.unlock();
}
return "hello";
}
3.2.2 Redisson三个阻塞情况
1.RReadWriteLock读写锁
读锁即共享锁,大家都可以读,写锁是排他锁,一个人写时其他人都得阻塞等待,所以当写操作进行时,读操作会阻塞,即:
A读,B读:不会阻塞
A读,B写:B会等A读完再写
A写,B写:阻塞,B要等A写完
A写,B读:B要等A写完
@Autowired
private RedissonClient redissonClient;
@Autowired
private StringRedisTemplate stringRedisTemplate;
@GetMapping("/write")
@ResponseBody
public String writeValue(){
RReadWriteLock lock = redissonClient.getReadWriteLock("rw-lock");
String s = "";
RLock rLock = lock.writeLock();
try {
rLock.lock();
s = UUID.randomUUID().toString();
TimeUnit.SECONDS.sleep(30);
stringRedisTemplate.opsForValue().set("writeValue", s);
} catch (Exception e) {
e.printStackTrace();
} finally {
rLock.unlock();
}
return s;
}
@GetMapping("/read")
@ResponseBody
public String readValue(){
RReadWriteLock lock = redissonClient.getReadWriteLock("rw-lock");
String s = "";
RLock rLock = lock.readLock();
rLock.lock();
try {
s = stringRedisTemplate.opsForValue().get("writeValue");
} catch (Exception e) {
e.printStackTrace();
} finally {
rLock.unlock();
}
return s;
}
2.RSemaphore信号量
分成阻塞等待获取与非阻塞获取(获取不到直接返回false)
阻塞等待获取:获取到就-1,减到0时就要阻塞,直到释放一个
非阻塞获取:获取到就-1,减到0就返回false
释放:不断+1,无上限
@GetMapping("/park")
@ResponseBody
public String park() throws InterruptedException {
RSemaphore park = redissonClient.getSemaphore("park");
// park.acquire(); //阻塞等待
boolean b = park.tryAcquire(); //非阻塞,直接返回false
return "ok" + b;
}
@GetMapping("/go")
@ResponseBody
public String go(){
RSemaphore park = redissonClient.getSemaphore("park");
park.release();
return "ok";
}
3.RCountDownLatch
分成countDown与Latch
countDown:不断-1
Latch:类似门阀,上面-1积累到指定值后就要触发,否则一直阻塞
@GetMapping("/lockDoor")
@ResponseBody
public String lockDoor() throws InterruptedException {
RCountDownLatch door = redissonClient.getCountDownLatch("door");
door.trySetCount(5);
door.await();
return "放假了..";
}
@GetMapping("/gogogo/{id}")
@ResponseBody
public String gogaogao(@PathVariable("id") Long id) throws InterruptedException {
RCountDownLatch door = redissonClient.getCountDownLatch("door");
door.countDown();
return id + "走了....";
}
3.3 @Cacheable缓存
3.3.1 使用
1.导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
2.启动类使用@EnableCaching
3.使用@Cacheable({"category"})注释即可
3.4 OAuth2社交登录
流程介绍:前端写入重定向地址,第三方授权后返回code码,页面实现重定向跳转,可由后台实现获取第三方信息.
3.5 分布式Session共享
问题一:cookie保存了sessionid,对于不同域名会有跨域问题(CORS,前端后台都可以解决),但是可能会导致CSRF攻击,可以改成jwt的token校验
问题二:在集群多台服务器情况下,需要用到分布式session共享。
即:整合SpringSession+redis实现不同主次域名下面session共享问题,但是却无法解决不同域名下面session共享问题,由此引申出SSO单点登录
3.6 SSO单点登录
参考链接:https://www.yuque.com/zhangshuaiyin/guli-mall
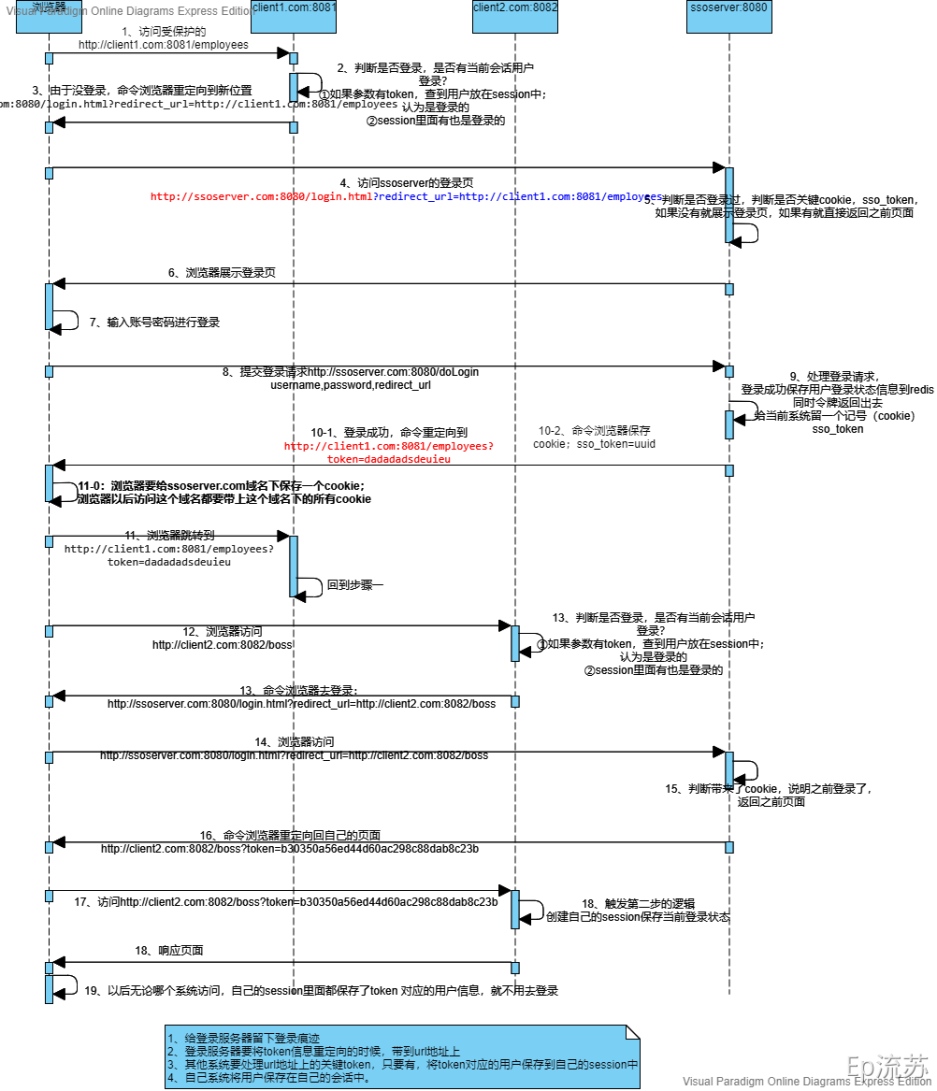
上述步骤解析如下:
1~6步:在本地host配置不同的域名分别代表客户端与SSO服务端。客户端访问时附带上redirect_url然后SSO服务器获取并返回即可(初始未登录情况下)
7~11步:客户端在服务器返回的界面进行登录,服务器收到信息后需要重定向到客户端(客户端入参会携带redirect_url),由于客户端也没有登录,会循环重定向到服务器,报错302,所以服务端需要返回一个token给客户端进行判断,同时redis存一份,并在Cookie中存一份(核心:后续其他域名登录SSO服务端的时候携带上来免登陆)然后客户端收到token后就代表不需要跳转到服务器了
注:客户端需要做2件事:一是初始登录访问SSO的时候携带redirect_url方便后续SSO服务器跳转回来,二是对于SSO服务器跳转回来的参数进行校验,防止302报错
服务器需要做2件事:一是提取客户端重定向地址进行跳转,二是保存已登录者信息,后续就可以实现单点登录
12-19步:上述服务端除了保存token返回给客户端,redis存入数据外,还要保存一份Cookie,用于后续其他客户端跳转的时候免登录,然后客户端收到token后,可以使用restTemplate访问获取redis中用户信息。
注:这里主要核心点是在于服务端要生成cookie保存。
🔥4.RabbitMQ消息队列
4.1 基本知识点
4.1.1 功能特点:
1.异步处理:传统异步可能需要等待异步返回,这个过程是耗时的,但是直接放入消息队列就减少了这些时间
2.应用解耦:各个模块直接对接接口可能会经常变化,用消息队列处理能减低耦合性,各个模块互不干涉
3.流量削峰:秒杀活动、消息回调这种会导致大量请求,放入队列让后台应用慢慢处理即减轻了后台服务器的压力。
4.1.2 消息服务
消息服务分成如下2种内容
1.消息代理:即消息服务中间件
2.目的地:即如何发送。分成队列(点对点消息通信)、主题(发布/订阅)
消息服务有2种实现方式
1.JMS:Java Api,即上面的队列与主题模式
2.AMQP:网络线级协议,5种消息模型(direct,fanout,topic,headers,system【后四种就是主题的细化】)
4.1.3 Rabbitmq内部流程
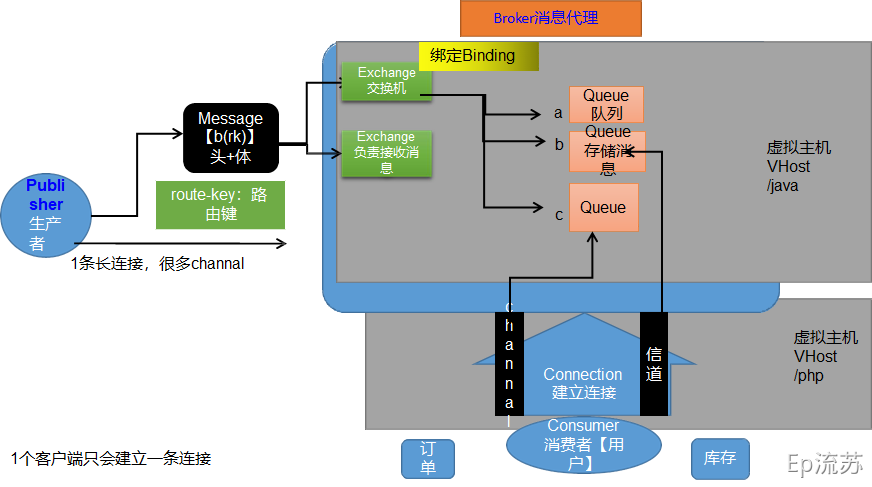
整体流程如下:
1.生产者与消费者先与消息队列建立一条长连接Connection(内部多个Channel,可以多路复用,某个消费者宕机后rabbmitmq会保存消息,不会再次发送),然后发送Message消息(内部分成消息头(内部包含route-key路由键,即发给哪个队列)与消息体(真正的消息内容))。
2.发送消息时是发送到某个虚拟主机(多个服务下面都有消息队列,则要隔离开来),然后内部由交换机Exchange发送给Query队列,后续队列发送给消费者。
4.2 基本使用
#安装rabbitmq
docker run -d --name rabbitmq -p 5671:5671 -p 5672:5672 -p 4369:4369 -p 25672:25672 -p 15671:15671 -p 15672:15672 rabbitmq:management
docker update rabbitmq --restart=always
4.2.1 rabbitmq消息队列
1. Direct模式:一对一指定routekesy进行Exchange与Queue的发送
1. Fanout模式:发送给所有binding了Exchange的Queue。
1. Topic模式:进行Routekeys主题的匹配(XXX.#代表0或多个,*.XXX代表至少要一个)
4.3 消息确认机制
4.3.1 基本流程
1. 由发送者到broker代理,有一个confirmCallback回调(发送端确认机制)
1. 由Exchange发送给Queue,有retureCallback回调(发送端确认机制)
1. 由Queue发送给消费者,有ack确认机制。(消费端确认机制)
🔥5.分布式事务
5.1 基本概览
5.1.1 CAP原理
C(Consistency):一致性,分布式系统中同一时刻数据一致
A(Availability):可用性,一部分结点故障后,集群整体是否还能响应客户端请求。
P(Partition tolerance):分区容错性,分布式系统下子系统之间可能存在通信失败。
注:3者最多只能保证2点,一般都是保证分区容错性。一致性与可用性之间二选一
CP:由于raft算法的自旋与心跳选择leader机制,在分布式系统故障情况下,未选出领导的时候是无法对外部做出响应,即出现系统不可用情况。
AP(默认,保证系统后面99.N个9可用性):即系统故障后,保证系统能正常返回,虽然会出现系统数据不一致情况,但是可以后续业务处理恢复(比如A->B订单入库,但是A回滚了B订单没回滚,后续可以使用删除B订单操作)
5.1.2 BASE理论
由于CAP保证了数据的强一致性(数据更新立刻就能访问请求到),实际分布式某些业务难以保证,所以引入了Base理论
原理:
1. 即基本可用,比原始响应迟一点、或者跳转到404界面。(弱一致性,可以等待或者可以访问不到)
2. 软状态:缓冲状态,比如未支付->成功支付中加入一个已支付
3. 最终一致性:可以过一段时间访问到更新数据,比如上面已支付到->成功支付可以过一会。
5.1.3 分布式事务方案
1、2PC 事务:也叫二阶段提交,两个事务先判断是否可以提交阶段与提交数据阶段,有一个事务不能提交就回滚
2、柔性事务-TCC事务
1. 刚性事务:严格遵循ACID原则
2. 柔性事务:遵循Base理论最终一致性,即一定时间内,不同节点数据可以不一致,但最终要要求一致
5.1.4 SpringBoot-整合Seata
- 启动seata-server-0.7.1.bat(内部register.conf写成nacos可注册到nacos中)
- 把事务管理的多个服务都配置数据库、事务。主事务开启全局事务管理(内部放入file.conf,register.conf,然后file.conf修改)
- 主事务报错,若已调用次事务,则会一起回滚
注:但这种同一的事务管理需要加锁,非常耗时,不适合高并发,适合后台管理系统。柔性TCC事务这种是采用发送给消息队列,让消息队列进行回滚
5.1.5 RabbitMq延时队列
定时扫描:若刚扫描完就有人下单,则下次扫描发现不了,下下次才能处理
TTL: time to live
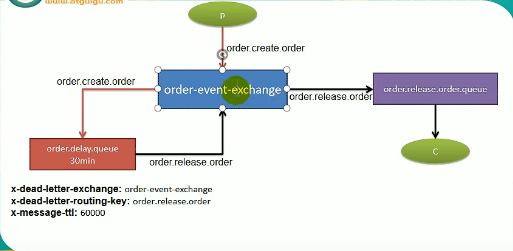
延时队列:60分钟过期的订单由交换机扔给60分钟延迟的队列(也叫死信队列)中,然后延时队列对进来的数据每60分钟再丢给处理队列处理
5.1.6 常见问题
1. 消息丢失(比如先入库一条待发送消息,然后队列确认了改成待回复,消费者确认了改成已确认,如果中途失败了没修改成功可以定时补偿):
1. publisher-Broker的消息确认机制,broker->consumer消息手动确认
2. 发送消息在数据库做好记录
2. 消息重复
1. 数据库设置防重表,保证消息幂等:采用jwt-token令牌
3. 消息积压
1. 多上线几个消费者。先存数据库,后来异步慢慢处理
5.2 订单服务
5.2.1 对称/非对称加密
1. 对称加密:加密与解密方用同一把秘钥
1. 非对称加密:加密方存私钥和解密方公钥,解密方存自己私钥和加密方公钥
5.2.2 内网穿透
就是用一台网站代理自己本机的机器(软件:花生壳、哲西)
5.3 秒杀服务
5.3.1 基本配置
1. 秒杀活动应单独开启一个微服务。分为场次表(sms_seckill_session)与场次名下关联的商品表(sms_seckill_sku_relation)。
1. Idea-service中加入内存限制
5.3.2 定时任务
每天定时把前一天秒杀商品加入到库存中
Cron表达式:秒 分 时 日 月 周 年(日和周可能会存在冲突,所以其中之一要用?通配符)
1, 3, 5 * * * * ? : 每1,3,5秒执行
7-20 * * * * ? : 7到20秒每秒执行
5.3.3 高并发问题
1. 秒杀服务单独部署
2. 秒杀链接加密
3. 库存预热和快速扣减
4. nginx的动静分离
5. 恶意请求拦截
6. 流量错峰:加验证码,购物车这些
7. 限流&熔断&降级:限制访问次数,阻塞,跳转其他界面
8. 队列削峰:秒杀成功请求进入队列,慢慢扣减库存
5.3.4 秒杀设计
1. 秒杀链接加密,对某个产品名下统一用同一加密方式,服务器校验秒杀时间和随机码的合法性
1. 创建订单给MQ,后续慢慢读
5.4 Sentinel(略 没成功)
5.4.1 基本概念
熔断:调用某个服务一直失败,后续直接不允许调用了
降级:在服务器资源紧张情况下,把某个不常用服务停掉
限流:类似于Semaphore,cyclicbarrier, countdownLatch这些只允许指定数量线程访问
5.5 Sleuth(略)
🔥6. 总结
高并发口诀:
- 缓存
- 异步
- 队列排好顺序
我曾七次鄙视自己的灵魂:
第一次,当它本可进取时,却故作谦卑;
第二次,当它在空虚时,用爱欲来填充;
第三次,在困难和容易之间,它选择了容易;
第四次,它犯了错,却借由别人也会犯错来宽慰自己;
第五次,它自由软弱,却把它认为是生命的坚韧;
第六次,当它鄙夷一张丑恶的嘴脸时,却不知那正是自己面具中的一副;
第七次,它侧身于生活的污泥中,虽不甘心,却又畏首畏尾。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本