JavaGuide--Java篇
本文避免重复造轮子,也是从JavaGuider中提取出来方便日后查阅的手册
参考链接:
JavaGuider:https://javaguide.cn/java/basis/java-basic-questions-01/
JVM内存结构:https://blog.csdn.net/rongtaoup/article/details/89142396
🔥1.基础概念与常识
1.1.Java语言特点
跨平台、面向对象(封装继承多态)、一次编写到处运行、多线程可靠安全、编译与解释并存
1.2字节码与编译和解释并存
被编译成.class后缀的文件就是字节码。而经过解释器JIT第一次解释后,后续热点代码(频繁使用的代码。消耗大部分系统资源的只有一小部分代码,这就是热点代码)的字节码对应的机器码就会被保存下来,然后每次代码执行的时候都会优化,这样就会越来越快
1.3 字符常量和字符串常量区别
字符常量是单引号,占一个字节(但java中char是2个字节),字符串常量是双引号,占若干字节
1.4 Java关键字
| 分类 | 关键字 | ||||||
|---|---|---|---|---|---|---|---|
| 访问控制 | private | protected | public | ||||
| 类,方法和变量修饰符 | abstract | class | extends | final | implements | interface | native |
| new | static | strictfp | synchronized | transient | volatile | ||
| 程序控制 | break | continue | return | do | while | if | else |
| for | instanceof | switch | case | default | |||
| 错误处理 | try | catch | throw | throws | finally | ||
| 包相关 | import | package | |||||
| 基本类型 | boolean | byte | char | double | float | int | long |
| short | null | true | false | ||||
| 变量引用 | super | this | void | ||||
| 保留字 | goto | const |
1.5.泛型
Java泛型是伪泛型,即java运行期间所有类型擦除,数据类型被转换成一个参数。比如:
-
泛型类:public Class Study
{} 实例化方式 Study genericInteger = new Study (123456); -
泛型接口:public interface Study
{} 实例化方式 class StudyImpl implements Study {} -
泛型方法:public static
void printArray()
项目哪里用到了泛型?
- 项目接口返回Result
参数的时候 - ExcelUtil
生成excel的时候 - 工具类Collections.sort这些地方
(注:个人觉得泛型适用性强,在和外部接口对接的时候,为防止外部参数类型经常变更,可以改成泛型。或者自己复用引用高的代码块的时候,也可以把代码块改成泛型。)
1.6. ==和equals(),HashCode()
==比较地址equals()比较对象,
HashCode是对堆上的对象产生独特值(不唯一,因为因hash算法也会产生不同对象相同hash值),如果重写equals不重写hashcode,那两个相同对象也会有不同的hashcode
1.7 基本数据类型
这 8 种基本数据类型的默认值以及所占空间的大小如下:
| 基本类型 | 位数 | 字节 | 默认值 |
|---|---|---|---|
int |
32 | 4 | 0 |
short |
16 | 2 | 0 |
long |
64 | 8 | 0L |
byte |
8 | 1 | 0 |
char |
16 | 2 | 'u0000' |
float |
32 | 4 | 0f |
double |
64 | 8 | 0d |
boolean |
1 | false |
引用类型Byte,Short,IntegerLong创建了[-128,127]的缓存,Character创建了[0,127]的缓存
注:频繁拆箱装箱也非常影响系统性能
1.7 基本数据类型
序列化:数据结构或对象转成二进制字节流
反序列化:序列化生成的二进制转成数据结构或对象
1.8 I/O操作
分为InputStream/Reader:字节输入流与字符输入流
OutputStream/Writer:字节输出流与字符输出流
1.9 I/O操作
反射:程序在运行时分析类和执行类方法的能力。(比如@Value就能在运行时给某个对象赋值,相比正射的set,get方法更灵活)
1.10 Java值传递
1.11 静态代理与动态代理
静态代理是由代理对象和目标对象实现一样的接口
动态代理是利用反射机制在运行时创建代理类。
动态代理:JDK动态代理实现了接口的类或直接代理接口,而CGLIB可代理未实现任何接口的类。与基于Java字节码实现的Javassist
动态代理更灵活,不需要实现接口就可以代理实现类。静态代理是在编译时将接口、实现类、代理类生成.class文件
动态代理底层:反射
Proxy:生产代理实例
InvocationHandler:处理代理实例并返回结果
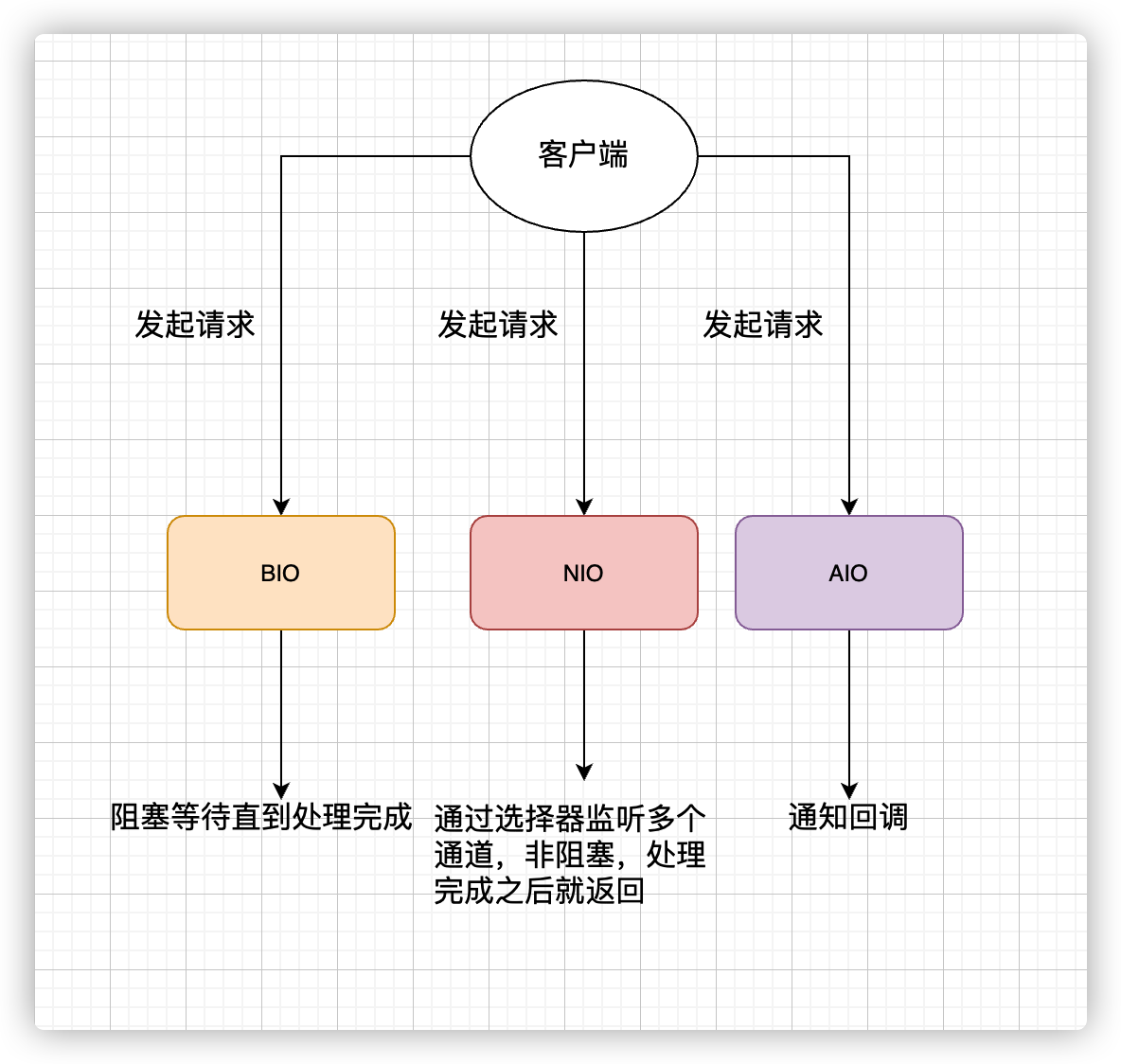
1.12 IO模型
同步阻塞IO:BIO
同步非阻塞IO:NIO
异步IO:AIO
🔥2.容器
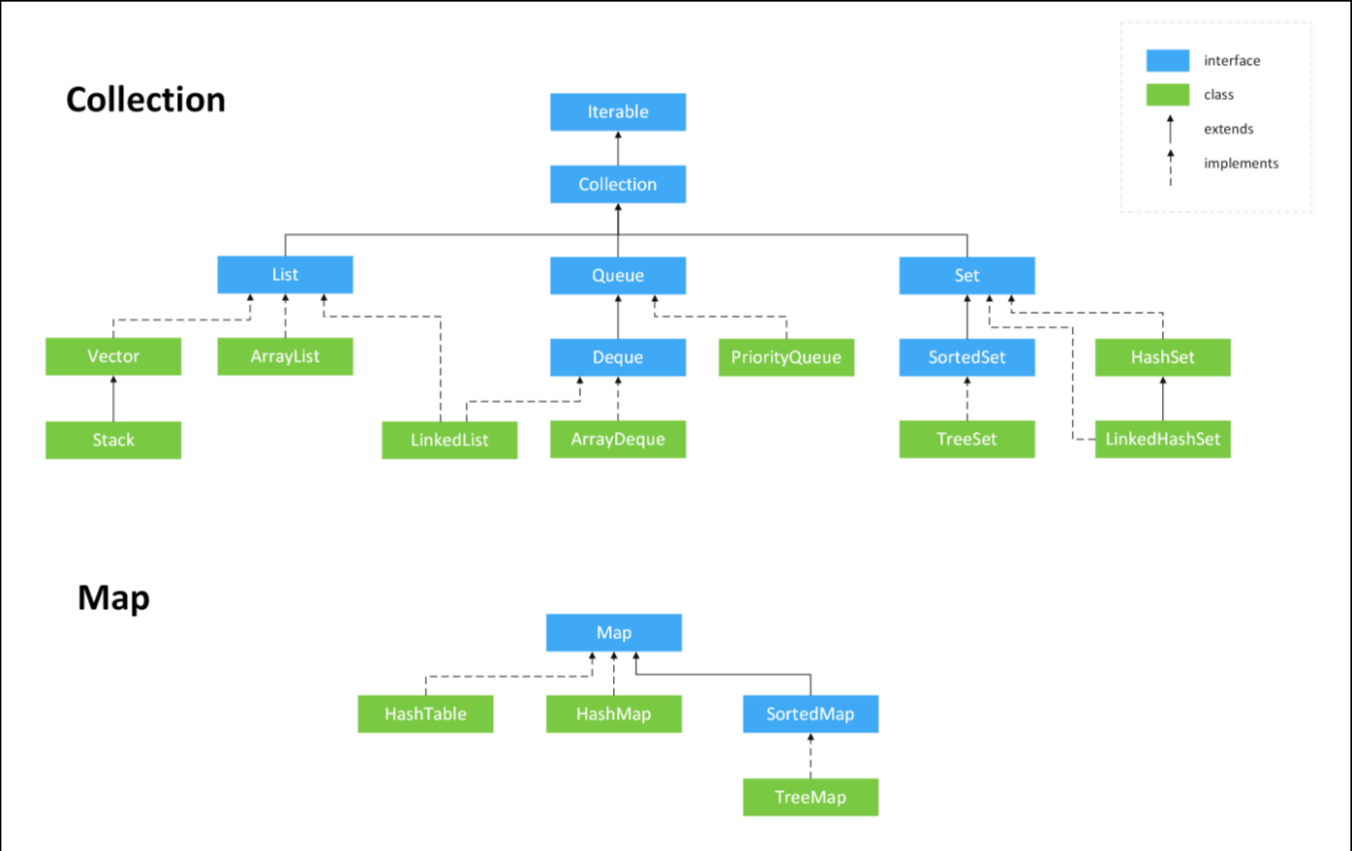
2.1.Java集合
Java集合:
1. Collection接口:list,queue,set
2. Map接口
2.2.==与 equals 的区别
对于基本类型来说,== 比较的是值是否相等;
对于引用类型来说,== 比较的是两个引用是否指向同一个对象地址(两者在内存中存放的地址(堆内存地址)是否指向同一个地方);
对于引用类型(包括包装类型)来说,equals 如果没有被重写,对比它们的地址是否相等;如果 equals()方法被重写(例如 String),则比较的是字符串值是否相等。
2.3 HashMap底层实现(JDK1.8前后)
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。
JDK1.8之后HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
(put逻辑:如果定位到的数组位置没有元素 就直接插入。
如果定位到的数组位置有元素就和要插入的 key 比较,如果 key 相同就直接覆盖,如果 key 不相同,就判断 p 是否是一个树节点,如果是就调用e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)将元素添加进入。如果不是就遍历链表插入(插入的是链表尾部)。)
相比于之前的版本, JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
2.4 ConcurrentHashmap底层原理
JDK1.8之后ConcurrentHashMap 取消了 Segment 分段锁,采用 CAS 和 synchronized 来保证并发安全。数据结构跟 HashMap1.8 的结构类似,数组+链表/红黑二叉树。Java 8 在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为 O(N))转换为红黑树(寻址时间复杂度为 O(log(N)))
synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,效率又提升 N 倍
2.6 Synchronized的升降级
对象分为对象头(MarkWord)、实例变量、填充字节。
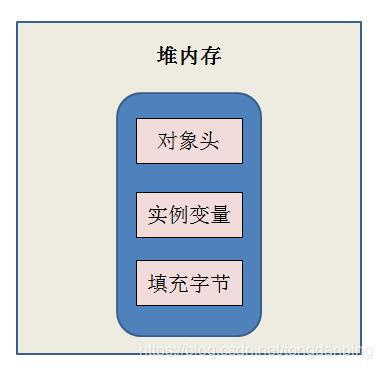
锁的4中状态:无锁状态、偏向锁状态(弄人开启)、轻量级锁状态、重量级锁状态(级别从低到高)
Java8 中的 ConcurrentHashMap 使用的 Synchronized 锁加 CAS 的机制。结构也由 Java7 中的 Segment 数组 + HashEntry 数组 + 链表 进化成了 Node 数组 + 链表 / 红黑树,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表。
🔥3.并发编程
3.1.进程与线程
进程:启动一个程序(启动main函数就是启动了一个jvm进程),而main函数的的线程就是这个进程中的一部分
多个线程共享内存中的堆与方法区,但是各个线程又有自己的虚拟机栈、本地方法栈、程序计数器。

3.2.上下文切换
线程会有主动阻塞(Sleep,wait)让出CPU、时间片用完、IO阻塞等线程切换情况,这时需要保留现场方便后续CPU调用,同时加载下一次线程用CPU的上下文,这就叫上下文切换。
3.3 Sleep与wait区别
Sleep没有释放锁,会自动唤醒,而wait释放了锁,必须要notify/notifyall唤醒
3.4 start与run
start启动线程做了线程准备工作后调用run方法并让线程进入就绪状态,CPU分配了时间片后就可以开始执行,而run方法并不会在某个线程中执行,不属于多线程。
3.5 Synchronized关键字
挂起或唤醒一个线程,都需要OS操作用户态到核心态的转换,这个过程非常耗时。
Synchronized作用域
- 修饰实例方法:作用于对象实例
- 修饰静态方法,作用于类.class
- 修饰代码块,作用域对象的锁(this,OBject)或类的锁(类.calss)
3.6 其他参数
以下内容见《JUC并发编程》
volatile(非线程安全)
ThreadLocal(线程本地变量)
线程池(三大方法、七大参数,四种拒绝策略)
3.7 AQS
简介:是juc下具体类
核心原理:多线程情况下,空闲的共享资源加锁,非空闲的共享资源使用CLH队列锁(内部是虚拟的双向队列,FIFO)进行线程队列等待与唤醒的锁分配策略
定义资源的共享方式:
1. Exclusive(独占):Reentranlock,synchronized
2. Share(共享):Countdownlatch,semaphore,cyclicBarrier,readwriteLock
3.8 补充
this逃逸:构造函数返回之前其他线程就持有该对象引用,其他线程调用尚未构造完全的对象方法引发错误
🔥4.JVM
4.1 JVM内存区域详解
4.1.0 JVM内存区域
1. PC程序计数器:线程中的信号指示器,用于用来读取下一条指令功能。、
2. Java虚拟机栈:包含一个个栈帧(局部变量表等等,局部变量表又包含8个基本数据类型(),对象应用)
3. 本地方法栈:虚拟机栈为java服务,本地方法栈为虚拟机用到的Native服务(也有本地方法的局部变量表等待)
4. 堆:存放分配几乎所有对象实例与数组内存、**字符串常量池、静态变量(jdk1.8之后)**
1. 字符串常量池:存放"asd" + "abc"(**常量折叠**)
5. 方法区:存储已被虚拟机加载的类信息(类如何放入方法区,reference如何指向就是这里)、常量。**方法区和永久代的关系很像 Java 中接口和类的关系**
1. 运行时常量池:类的版本、字段、方法、接口等描述信息外,还有常量池表(类的相关信息)
2. **jdk1.8之后是把永久代实现方法区方式换成了元空间实现方式**
6. 直接内存(堆外内存):NIO
4.1.1对象的创建
Java对象创建分如下5步:
- 类加载检查:遇到new 指令时,进行类的检查与加载。
- 分配内存:在堆中分配内存,有指针碰撞与空闲列表2种分配方式。Java堆是否规整由垃圾回收算法决定。

保证内存分配的线程安全:
CAS+失败重试: CAS 是乐观锁的一种实现方式。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。虚拟机采用 CAS 配上失败重试的方式保证更新操作的原子性。
TLAB: 为每一个线程预先在 Eden 区分配一块儿内存,JVM 在给线程中的对象分配内存时,首先在 TLAB 分配,当对象大于 TLAB 中的剩余内存或 TLAB 的内存已用尽时,再采用上述的 CAS 进行内存分配
- 初始化零值:给每个new 对象有初始化值
- 设置对象头:markword
- 执行init方法:按照代码进行init,比如定义数组大小。上述可以说只是定义分配了内存位置,这里根据init定义具体大小。
new ArrayList<>(3);
4.1.2 对象访问
- 句柄访问:Java栈的本地变量表访问堆中的句柄池中的实例对象指针(类似于操作系统中的虚拟地址表),然后访问堆或者方法区中的实例对象。缺点就是多访问了一次指针定位实例数据的时间。
- 直接指针:Java栈的本地变量表存的就是直接访问堆中的实例对象的地址。访问方法区就是堆中存了实例对象地址。缺点就是后续垃圾回收移动对象地址的时候,需要改变栈中的本地变量表。
// 上面说了new ArrayList<3>,这里说的2种方法就是一整条语句了。
List<Integer> list = new ArrayList<>(3);
4.2 JVM垃圾回收详解
4.2.1 Jvm垃圾回收相关问题
注:JVM垃圾回收在于线程共享区域:即堆、方法区(已被虚拟机加载的静态变量、常量等代码与运行时常量池)
下面介绍JVM垃圾回收具体流程:

4.2.2 对象是否死亡
1.如何判断对象是否死亡:引用计数器与可达性算法
2.指向对象的引用:强引用,软引用,弱引用,幻想引用(虚引用)
目前尚有一个疑问?
目前垃圾回收器普遍都是分代回收算法,但是又说JDK1.8是默认采用Parallel scavenge+Serial Old收集器,但这2个收集器并不是GC算法,是否冲突?
答:相当于所有垃圾回收器都默认使用了分代回收算法
4.2.3. 垃圾回收(算法与工具)
垃圾回收算法:
1. Mark-sweep(标记-清除 MS算法):标记全部堆中可回收资源进行回收
2. Copying(复制 CP算法):堆内存分成2半,一半用完了复制并整理整齐到另一半上,然后把这一半清空。
3. Mark-Compact(标记-整理 MC算法):MS与CP结合,将全部堆内容标记,然后整理整齐清空。
4. Generation Collection(分代收集 GC算法):根据对象存活周期将内存分为新生代与老生代进行收集。垃圾收集器:
1. Serial Old收集器:MC算法
2. ParNew收集器:Serial的多线程版本,MC算法
3. Parallel Scavenge:Cp算法
4. Parallel Old:MC算法
5. CMS:MS算法
6. G1:MS算法
4.3 类文件结构、类加载过程(略)
4.4 JVM性能调优(待续)
能力有限,暂时用不到这些,后面用到了进一步了解。
学习链接:https://javaguide.cn/java/jvm/jvm-parameters-intro/#_3-2-gc记录
4.5 JVM排查命令
参考命令:https://javaguide.cn/java/jvm/jdk-monitoring-and-troubleshooting-tools/#jps-查看所有-java-进程
注:Jdk1.8默认采用Parallel Scavenge(新生代) + Serial Old(老年代)
🔥5.新特性
5.1 Java8新特性实战、《Java8指南》、JDK9~15、小技巧(略)
权当手册查了。
书山有路勤为径,学海无涯苦作舟。程序员不仅要懂代码,更要懂生活,关注我,一起进步。

我曾七次鄙视自己的灵魂:
第一次,当它本可进取时,却故作谦卑;
第二次,当它在空虚时,用爱欲来填充;
第三次,在困难和容易之间,它选择了容易;
第四次,它犯了错,却借由别人也会犯错来宽慰自己;
第五次,它自由软弱,却把它认为是生命的坚韧;
第六次,当它鄙夷一张丑恶的嘴脸时,却不知那正是自己面具中的一副;
第七次,它侧身于生活的污泥中,虽不甘心,却又畏首畏尾。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY