
阅读笔记:Sybilla DLT任务重启判定系统
论文简介
Sibylla: To Retry or Not To Retry on Deep Learning Job Failure 这篇论文发表在ATC 2022上,主题是提出了一个基于半监督学习的深度学习训练(DLT)作业调度的系统,该系统减少了GPU集群中不必要的作业重启操作。
背景知识
深度学习作业调度中的错误类型与处理机制
目前的大规模GPU训练任务集群中存在后端分布式存储系统专门用于存储在整个集群中训练期间生成的stdout和stderr日志。这些日志中记载了不同虚拟机或者容器的启动,运行情况。
论文中将深度学习作业中发生的错误(failure),分类为决定性(DT failure)或非决定性(NDT failure),以此来确定后续需要针对这些错误的响应机制。决定性错误(或DT failure)是由固有的代码语法错误、API误用、错误配置的设置等引起的,这种错误一般无法正常恢复,即使重启虚拟机或者容器镜像也不能正常运行。与此相对,非决定性错误(或NDT failure)是偶然的,通常与临时网络连接丢失或作业分配节点的瞬态问题有关,这种错误可能会因为重启或者在运行而得到恢复。下图展示了论文中认为的这些错误。
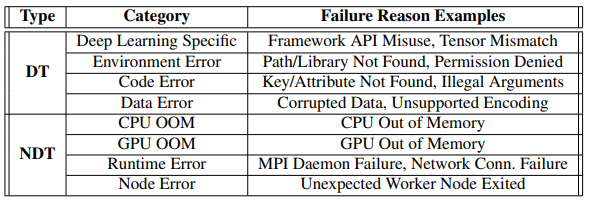
在目前Microsoft Philly深度学习训练集群中,失败的训练作业会重启(Retry)固定次数,以克服NDT failure,并在重启后继续或开始运行深度学习训练作业。除了这种重启的作业异常处理机制,企业中的NoRetry机制则会终止每一个发生错误的作业,以避免在DT failure中毫无价值地尝试重新执行作业,占用固定的GPU资源。
Observation
在调度初始作业和失败后重启作业中,使用日志追踪,我们可以估计作业重启率(即经历重启的作业÷所有作业)以及重启期间花费的GPU时间占所有GPU时间的比例。

其中可以发现,深度学习训练作业的重启率在分布式任务上大约为20-40%,这也就说明实际集群中深度学习作业失败率并不容忽视。除开显而易见的结论,论文中还提到了一些重要的观察。具体而言,使用更多GPU的作业更频繁地重试执行,而重试期间消耗的GPU时间占作业大小的12.3-19.9%。我们记一个深度学习作业从正常运行到出现异常的时间为RTF(runtime to failure),那么对于失败的作业,DT failure和NDT failure的中值RTF为614秒和2458秒。这也表明重启的开销也并不低。
如果坚持Retry策略,例如retry所有出现问题的作业固定次数,那么势必会造成严重的资源浪费。但是坚持NoRetry策略是否合适呢?作者提到这样做的训练成功率将下降4.5%左右,其实对于那些可以通过重启正常运行的作业而言的体验会非常不好。
论文方法
论文提出的Sibylla是一个判定出现failure的深度学习作业是否需要重启的系统。其设计目标是高精度、易用、易集成。前两个都好解释,易集成则需要简单说明。Sibylla设计在一个独立的agent中运行,或者在应用程序端运行(例如,Apache YARN中的application Master)以与调度器独立交互。所以并不需要更改原集群的调度器就能将Sibylla集成入集群调度系统中。
Sibylla的思路非常简单,将本问题建模为一个二分类问题再利用AI的方法解决。具体思路是将原本集群中的stdlog和stderr文件作为输入训练一个神经网络,由神经网络的输出判定是否需要重启改作业。有此基础,下面我们来看看它的具体方法。
training workflow
data preprocessing
虽然思路是将log文件作为输入,但实际的log文件信息量并不小,且大部分是与出现failure无关或不起太大作用的。而神经网络如果一次性接受整个不加处理的文件,那么信息提取的结果也会相当有限。如何减少信息的输入呢,论文的思路是选择在出现与特定的failure相关关键字的行之后最多5行。Sibylla还包括关键字前面的一些行,因为它们可能指示导致失败的日志子序列。这样有效的完成了信息提取的第一步。
但仅仅如此问题依然存在,因为log文件是一个具备大量信息的半结构化数据,其中很多类似用户定义的error表达,或者特定的类型名称,函数路径等等都会极大得增加输入长度的不确定性。这些信息很多对最终判定的帮助也并不大。论文的思路是,在解析阶段,每个日志行被分类到一个结构化模板中,该模板主要重新移动与判定语义无关的单词,如非字符单词和停止单词。就如下图的左侧显示的那样:
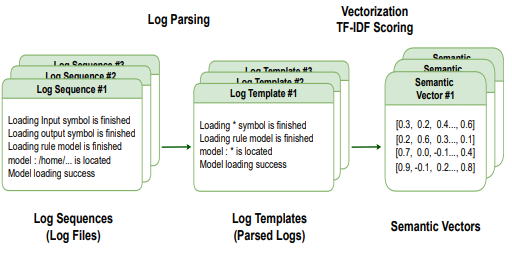
解决了输入信息量的问题,下面就是如何完成输入的embedding了。Sibylla的思路是采用非深度学习方法进行embedding,这个过程如上图右侧。首先将每个单词数字化为一个矢量。然后,它通过基于TF-IDF(术语频率逆文档频率)得分对每个单词进行加权,将模板中每行的所有单词向量累积到单个语义向量条目中。
Model training
Embedding完成后的语义向量序列用作模型训练的输入。有两种具有代表性的RNN模型参与训练Sibylla:LSTM和基于注意力的GRU。所以模型本身比较简单,但值得一提的是其训练方式选择了半监督训练,采用投票自标注的方法进行模型训练。Sibylla用部分标记的数据开始模型训练,并通过在线方式自动标记未标记的数据来不断更新模型。
Automatic sample labeling
训练和自动标注的流程如下:
Sibylla利用了对预测结果进行投票的集成方法来决定失败类型,从而减轻了单个模型错误预测的影响。总的来说就是自标注的半监督学习+集成学习的方式构成其模型训练的整个过程。
神经网络的训练数据则是从操作NoRetry的公司获得了97个错误日志文件,并通过手动搜索Stack Overflow收集了另外159条错误消息得到的。此外这点数据很容易过拟合,所以论文还使用了两种流行的文本数据增强方法,WordNet和Word2Vec,用于用认知同义词替换原始日志文件中的单词,并创建一个新的数据增强文件。
实验
实验需要提到的并不多,本篇论文的实验纯模拟,通过深度学习集群数据集the Philly trace of MS来作业调度性能。
讨论
总的来说,这是一篇应用深度学习方法的典型文章,主要突出的创新点在于问题的切入点非常新,考虑了以往深度学习作业调度中基本被避开的失败问题。
本文作者:ytcboy
本文链接:https://www.cnblogs.com/medianet-ytc/p/notes_Sibylla_paper.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步