搭建hadoop2.x环境
搭建环境前期准备:
1.初始的liunx系统,我这里用的是centos6.4
2.联网方式是:NAT
3.JDK和Hadoop安装包,我这里jdk是1.7,hadoop是2.5.0
重要说明:在这里我在/opt目录下创建了两个目录,一个是app目录,作用是:放解压后的文件,另外一个是softwore目录,作用是:放解压前的文件,大家也可以不和我一样!
一、.打开linux系统,查看IP地址:

我这里IP地址是192.168.174.141,然后使用远程工具进行连接,远程工具的使用,在这里我就不进行介绍了,我用的远程连接工具是CRT
二、修改主机名,配置IP地址与域名的映射和安装JDK(这些操作均在root用户下完成)
1、切换root用户,编辑/etc/sysconfig/network文件,将HOSTNAME=*****,改成你喜欢的一个名字,我这里改成hadoop.test.com,最好改成域名的形式

2、编辑/etc/hosts文件,在最后一行这里加上ip地址映射
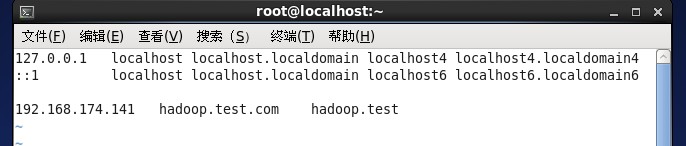
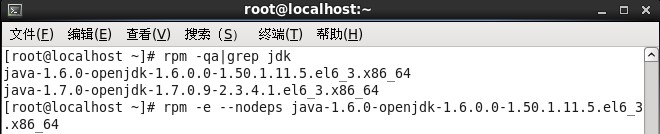
3、删除系统自带的jdk,执行rpm -qa|grep jdk命令,查找系统自带的jdk,然后使用rpm -e --nodeps 进行删除

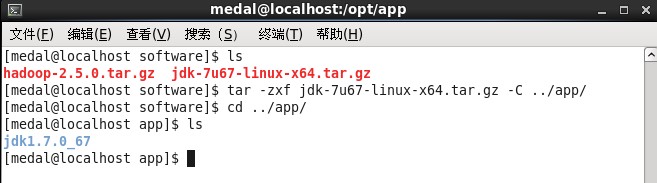
4、安装jdk1.7,第一步:上传jdk安装包,我这里用的是WinSCP(WinSCP软件,我就不介绍了),将/software下的jdk安装包解压到/app下
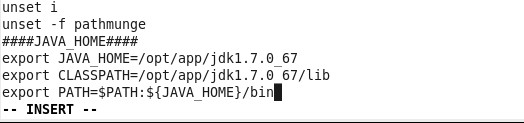
第二步:配置java环境变量,在root用户下,编辑/etc/profie文件,在最后加上如下内容:
第三步:重启系统,在命令行输入java - version,如出现以下信息,说明jdk安装成功

5、使用远程连接工具进行连接,我这里是直接用域名进行连接,用域名连接,需要在物理机上配地址映射,大家用ip地址连接就好
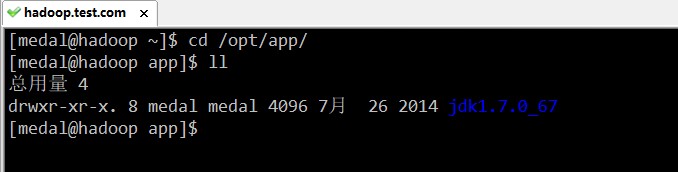
三、安装hadoop
第一步:上传安装包,将/opt/software下的hadoop安装包,解压到/opt/app目录下

第二步:进入/opt/app/hadoop2.5.0目录下,执行如下操作:
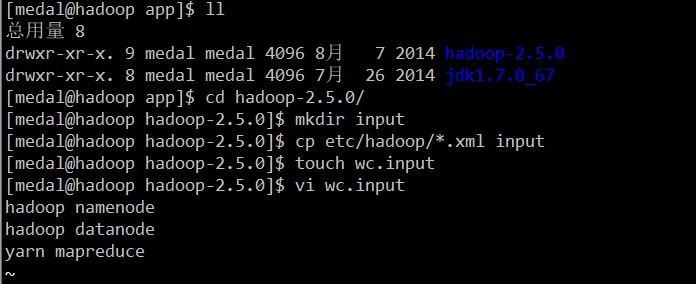
保存退出,然后执行命令:bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount wc.input output
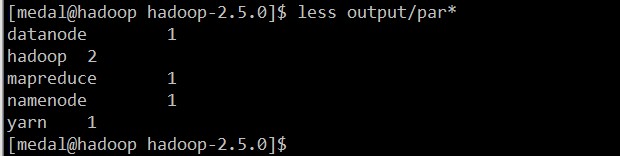
如果你的界面和我这一样,那单机配置成功
四、下面介绍伪分布式搭建
1、进入etc/hadoop下,配置core-site.xml
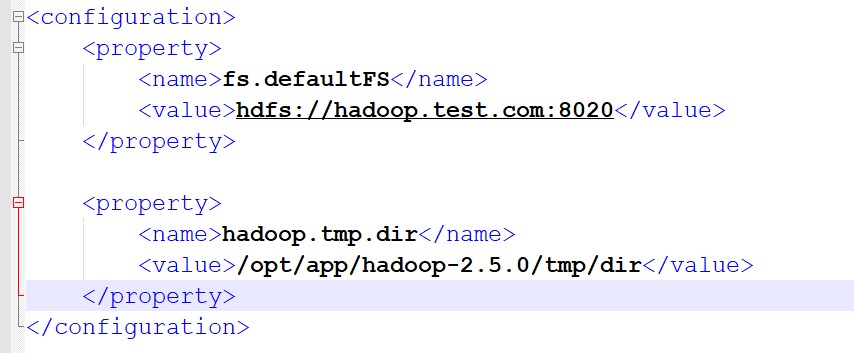
在这里,我的主机名是hadoop.test.com,HDFS现在默认端口号是8020,所以我将其改成hdfs://hadoop.test.com:8020
hadoop.tmp.dir是hadoop临时缓存目录,默认是在hdfs上,我将其配置到本地,/opt/app/hadoop2.5.0/tmp/dir,这个目录需要在本地创建
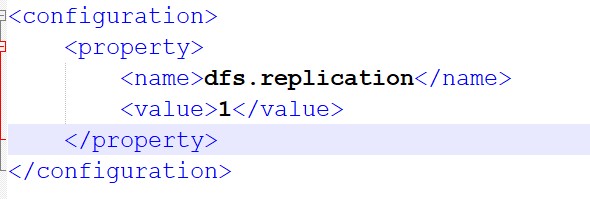
配置 hdfs-site.xml
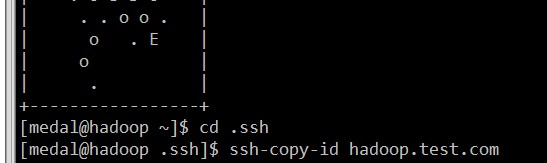
2、配置免密钥登录
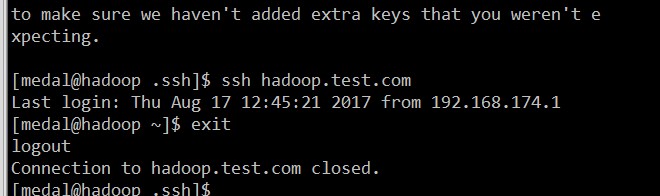
进入用户的家目录,执行ssh-keygen -t rsa,然后敲4个回车,进入.ssh目录,执行ssh-copy-id 目标主机,yes,用户密码,最后就可以直接sshl连接了

3.格式文件系统,命令:bin/hdfs namenode -format
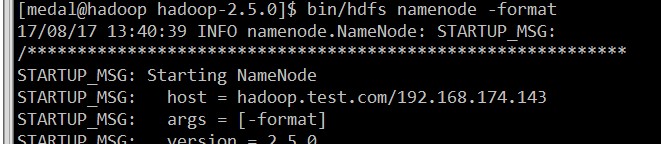
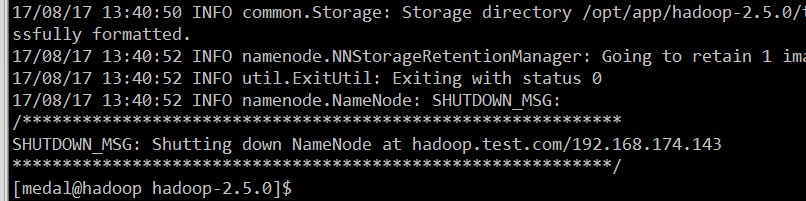
格式化后,出现上述信息,说明格式化成功,如果格式化出错,请大家查看错误信息,并进行相应的改正
4、启动namenode和datanode,并创建用户user目录
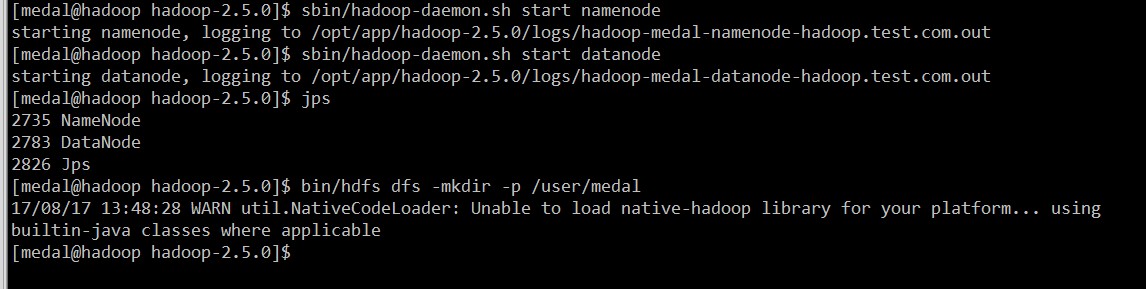
5、将本地文件上传到HDFS上,并在HDFS上测试wordcount程序,最后查看程序运行的结果


如果出现上述信息,则说明成功,出错了,请大家查看错误信息,并进行改正
6、配置yarn环境,将mapred-site.xml文件重命名为mapred-site.xml
修改配置文件mapred-site.xml

修改配置文件yarn-site.xml

修改配置文件slaves,将里面的localhost改成你的主机名,我的主机名是hadoop.test.com
7.启动nodemanager和resourcemanager,并将wordcount程序运行在yarn上,最后查看程序结果


如果出现上述信息,则说明成功,至此,hadoop环境初步搭建好,后续还有在此基础上搭建hive环境
