

SQL Server 索引
SQL Server 2008-索引 简介
在SQL Server 20008中提供的索引类型主要有以下几类:
聚集索引 非聚集索引 唯一索引 包含性索引 索引视图 全文索引 空间索引 筛选索引 XML索引
在SQL Server 2008中按照存储结构的不同,可以将索引分为聚集索引和非聚集索引两类。 而这两类索引正是以上其他索引的基础
索引的设计原则
选择性
选择性表示符合你查询条件的记录占总记录的百分比,也就是
选择性=符合查询条件的记录数量/总记录数量
这个值越小越好,越小代表选择越高,越适合采用索引
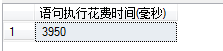
表中有1000万条数据,且表中无任何索引

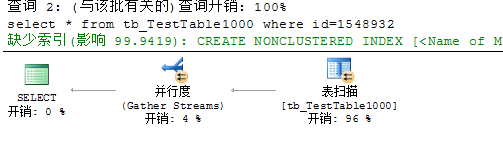

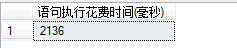

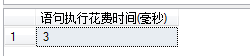
表中有1000万条数据,且为id列添加非聚集索引

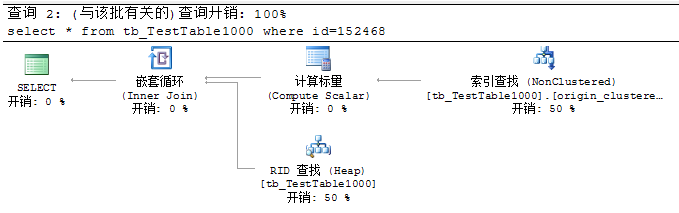
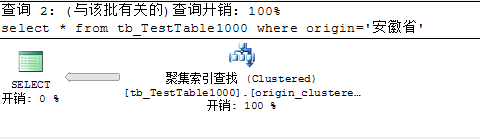
表中有1000万条数据,且为origin列添加非聚集索引

表中有1000万条数据,且为id列添加聚集索引

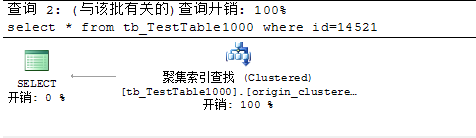
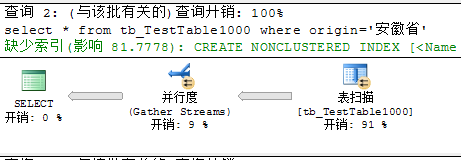
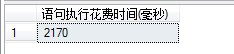
表中有1000万条数据,且为origin列添加聚集索引

使用窄索引
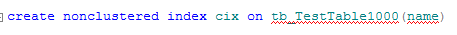





检查建立索引字段的数据类型
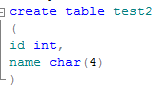
新建一个test2表,该表有id和name两个字段,数据类型分别为int和char(4),在SQL Server 2008中两者的大小都是4字节(失败)
聚集索引与非聚集索引
聚集索引
当我们创建主键约束时,如果不存在聚集索引并且该索引没有明确指定为非聚集索引,SQL Server 会自动将其创建为唯一的聚集索引。

1.何时使用聚集索引
①检索一定范围内的数据
②读取预先排序的数据





2.何时不使用聚集索引
①频繁更新的表
②宽的关键字
③太多的并行的顺序插入(实验出错)
非聚集索引
因为聚集索引的关系,将表分为两种 堆表和聚集表,所以也有了两种非聚集索引
1.堆表上的非聚集索引
工作方式:通过扫描堆上的非聚集索引,找到RID,再通过RID获取数据
2.聚集表上的非聚集索引
工作方式:通过扫描聚集表上的非聚集索引,找到聚集键值,再通过聚集键值获取数据

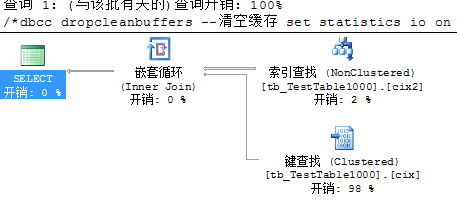
注意:如果表没有聚集索引,建立了非聚集索引,那么非聚集索引使用的是行号。如果此时又添加了聚集索引,那么所有的非聚集索引引用的RID都要改为聚集索引建。这对性能的消耗非常大,因此应该先建立聚集索引,再建立非聚集索引
非聚集索引的覆盖、连接、交叉和过滤
非聚集索引之覆盖
建立的索引使得T-SQL查询不用到基本表,仅仅通过索引查找就得到了所需数据

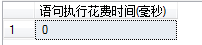
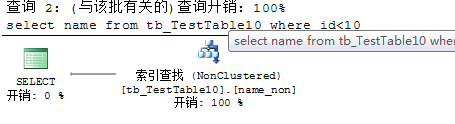

由于SQL Server 数据库对索引键的大小和列数有限制,其中最大为900字节和16列。如果组合列的大小超过900字节或者是列数多余16列,系统就会报错。因此产生了一种特殊的覆盖索引结构-非聚集索引之include
非聚集索引之include
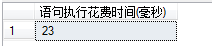
在10万条数据的表中,添加非聚集索引


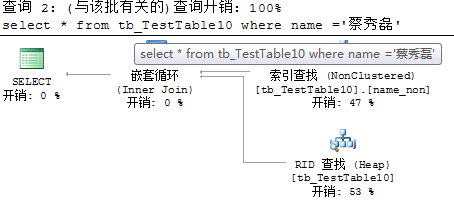
在10万条数据的表中,添加非聚集索引,并且用include包含其他列



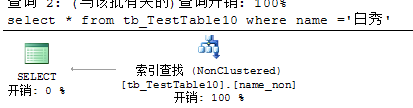
非聚集索引的交叉
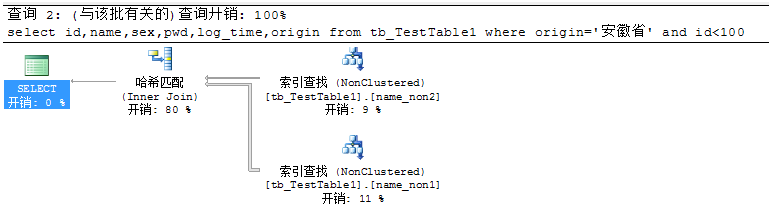
如果表中有多个索引,那么就可以使用多个索引来执行一个查询。根据每个索引选择小的数据子集,然后执行两个子集的一个交叉集



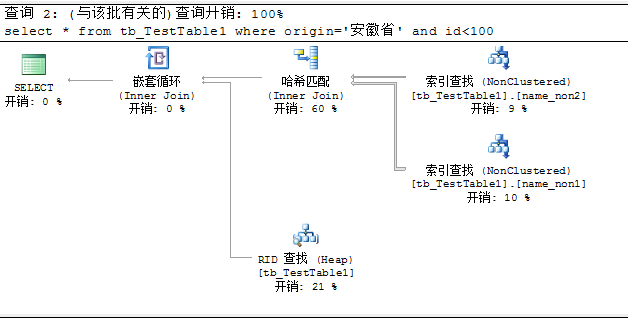
非聚集索引的连接
索引连接是索引交叉的特例,它将覆盖索引技术应用到索引交叉。如果没有单个覆盖查询而存在多个索引一起可以覆盖该查询,SQL Server可以使用索引连接来完全满足查询而不需要转到基本表

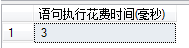

索引的维护
实际上,索引的维护主要包括以下两个方面:页拆分、碎片,虽然两者的表现形式本质上有所区别,但是故障排除工具是一样的。
碎片
一个表中有大量的碎片并不只有坏处。对于一个插入频繁的表来说,有大量的碎片在数据插入时几乎不用担心页拆分的问题,所以大量的碎片意味着较差的读取性能,但也意味着极好的插入性能
碎片分两种:外部碎片和内部碎片
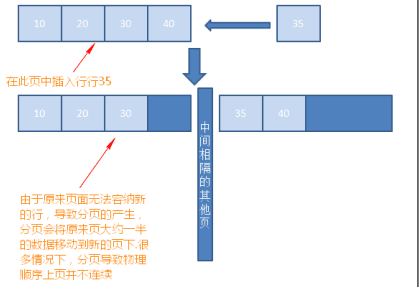
1.外部碎片
外部碎片指的是页拆分而产生的碎片。如向表中插入一行,而这一行导致现有的页空间无法容纳新插入的行,则导致页拆分
2.内部碎片
内部碎片时页拆分后,导致索引页的数据并不满,有空行。
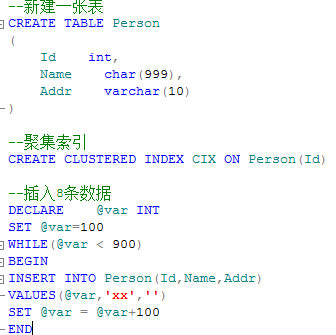







之后又往表中插入50条数据
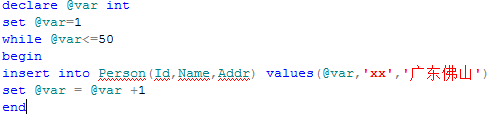


3.碎片的解决办法
删除索引并重建
缺点:
1.在删除其间,索引不可用
2.卸载并重建索引会造成阻塞,也可能被其他请求所阻塞
3.当表中既有聚集索引,又有非聚集索引时,删除聚集索引,会导致对应的非聚集索引重建两次
使用DROP_EXISTING语句重建索引



这种方式不会造成非聚集索引重建两次,但也会造成阻塞
使用ALTER INDEX REBUILD语句重建索引
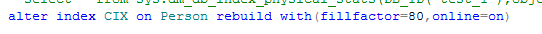


使用这个语句同样也是重建索引,但是通过动态重建索引不需要卸载并重建索引,优于前两种方法,但依然会造成阻塞。可以通过online关键字减少锁,但会重建时间加长。
因为该操作是一个原子操作,如果它在结束前结束,所有到那时为止进行的碎片整理操作都将丢失
使用ALTER INDEX REORGANIZE 重整索引



这种方式不会重建索引,也不会生成新的页,仅仅是整理叶级数据,不涉及非叶级,当遇到加锁的页时跳过,所以不会造成阻塞。但同时,整理效果会差于前三种
查询查询语句执行情况
SQL Server 数据库提供了——执行计划

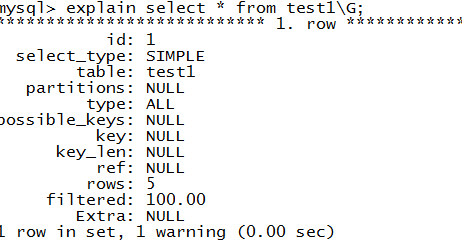
MySQL 数据库提供了——explain命令
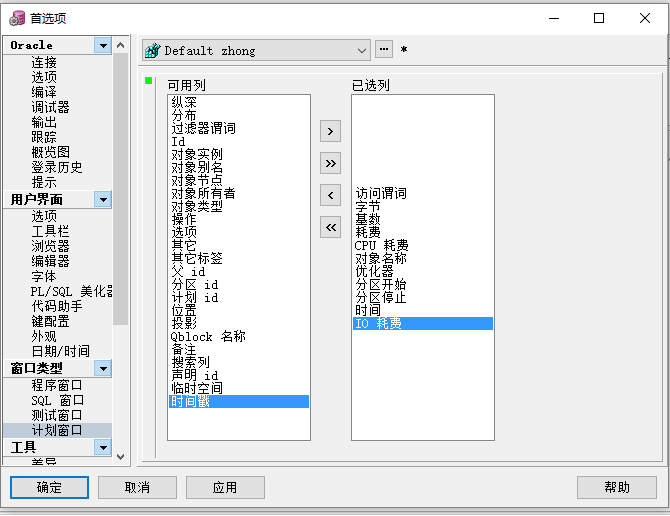
Oracle数据库提供了——可以手动配置的执行计划
SQL Server 的5种查询记录方式:
[Table Scan] 表扫描(最慢),对表记录逐行进行检查
[Clustered Index Scan] 聚集索引扫描(较慢),按聚集索引对记录逐行进行检查
[Index Scan] 索引扫描(普通),根据索引滤出部分数据再进行逐行检查
[Index Seek] 索引查找(较快),根据索引定位记录所在位置再取出记录
[Clustered Index Seek] 聚集索引查找(最快),直接根据聚集索引获取记录
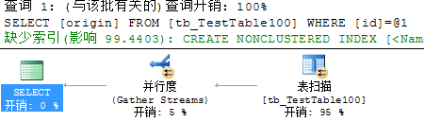
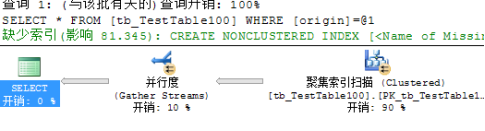

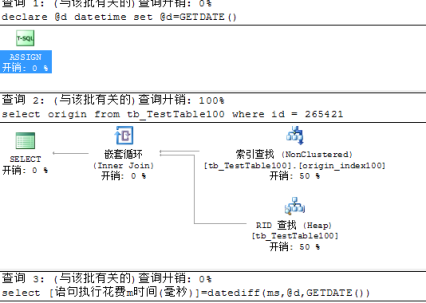
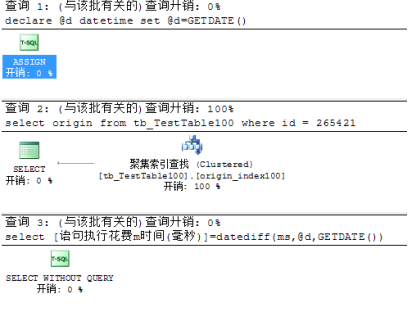
其中表中无任何索引结构,检索表中数据时,使用的是表扫描
使用表中的聚集索引进行检索数据时,会有两种检索数据方式,分别为聚集索引扫描和聚集索引查找
使用表中的非聚集索引进行检索数据时,会有两种检索数据方式,分别为索引扫描和索引查找
以下情形会使得索引查找变成索引扫描
隐式转换
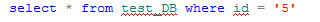
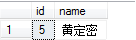
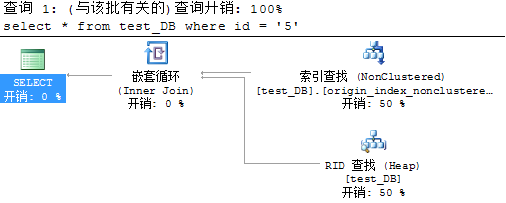

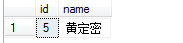

非SARG谓词导致执行计划从索引查找变为索引扫描
不满足SARG形式的语句最典型的情况就是包括非操作符的语句,如:NOT、!=、<>、!<、!>、NOT EXISTS、NOT IN、NOT LIKE、谓词使用函数、谓词进行运算,以下对几种情况进行图示说明
索引字段使用函数会导致索引扫描
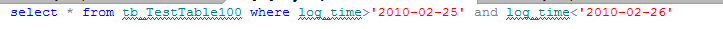
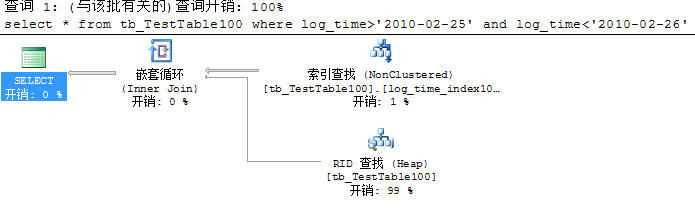

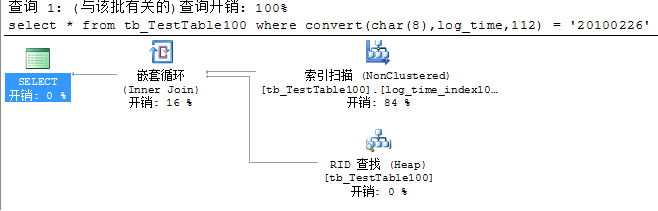
索引字段进行运算会导致索引扫描



LIKE模糊查询会导致索引扫描




警告:
1.当表中只有非聚集索引,没有主键或聚集索引,这时候搜索走表搜索
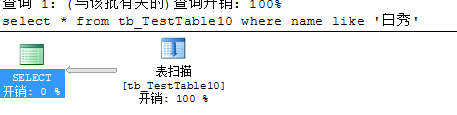

2.当表中既有主键(默认聚集索引),又有非聚集索引。如果非聚集索引无法单独删除,这时搜索走聚集查找/扫描
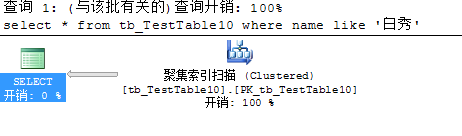
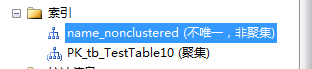
3.当表中既有主键(聚集索引)和非聚集索引,且非聚集索引可以单独删除。这时搜索走索引查找/扫描


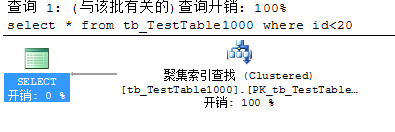
SQL查询返回数据页达到了临界点会导致索引扫描或表扫描
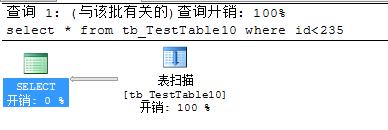
经过调试发现1万(24条),10万(234条),100万(2137条),1000万(19570条),所以初步统计临界点在0.0024%以下,且随着表中总数据量的增长而降低
谓词不是联合索引的第一列会导致索引扫描
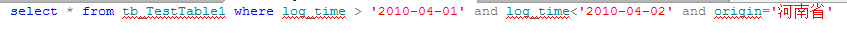


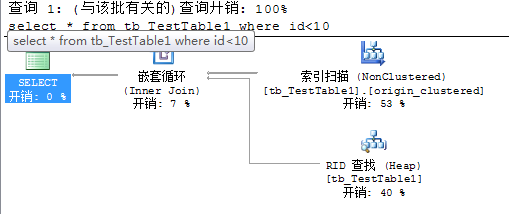
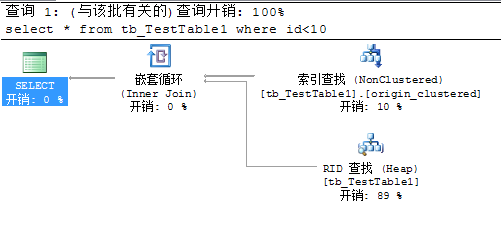
如果不是联合索引,只是单独在id列建立非聚集索引


 浙公网安备 33010602011771号
浙公网安备 33010602011771号