当然不是草台班子 云译网 原型设计+概要设计
| 作业所属课程 | 软件工程2024 |
|---|---|
| 作业要求 | 2024秋软工实践团队作业-第二次 |
| 作业目标 | 设计出原型与后端架构 |
| 团队名称 | 当然不是草台班子 |
| 团队成员学号 | 姓名 |
|---|---|
| 102201427 | 侯丽珂 |
| 102201426 | 郑嘉祺 |
| 102201241 | 戴康怡 |
| 102201218 | 肖晗涵 |
| 112200328 | 谢李东 |
| 292300304 | 陈鹭 |
| 102201242 | 魏儀阳 |
| 082100170 | 朱胤帆 |
| 112200629 | 赵弈茗 |
| 102202132 | 郑冰智 |
原型设计
一、界面结构
1. 顶部导航栏
- 网站logo:位于导航栏左部,显示“云译网”字样,作为品牌标识。
- 搜索框:位于导航栏显眼位置,用户可输入关键词进行站内搜索,快速找到所需内容。
- 用户操作按钮:包括登录、注册和个人中心等,位于导航栏右上角,方便用户进行账号管理和个人设置。
2. 侧边栏
- 主要功能模块:列出网站的主要功能模块,如首页、个性化定制、翻译校对等,方便用户快速导航至所需功能。
3. 主内容区
- 展示功能内容:根据用户选择的功能模块,展示相应的主要内容,占据页面的大部分空间。
二、页面设计
1 前台应用原型
链接:https://rp.mockplus.cn/run/kl8hNh9g6F/b503_uY-bs
1. 登录页面
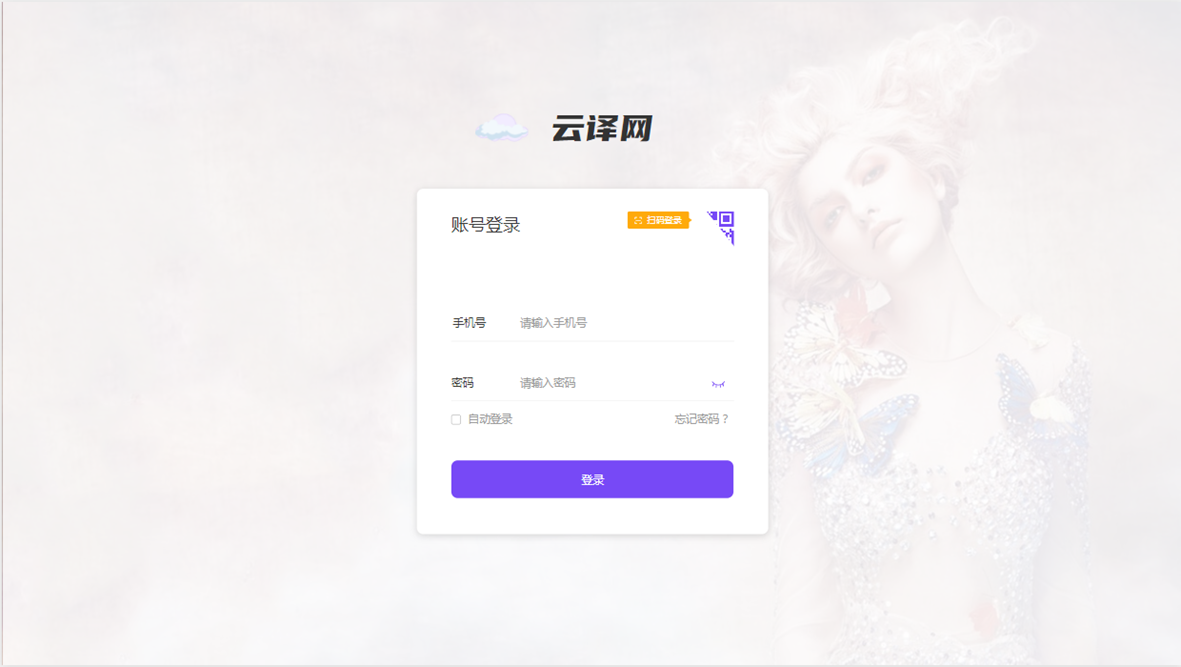
- 具体功能:
- 用户登录/注册区域:方便新用户快速注册或登录,提升用户转化率。
2. 首页
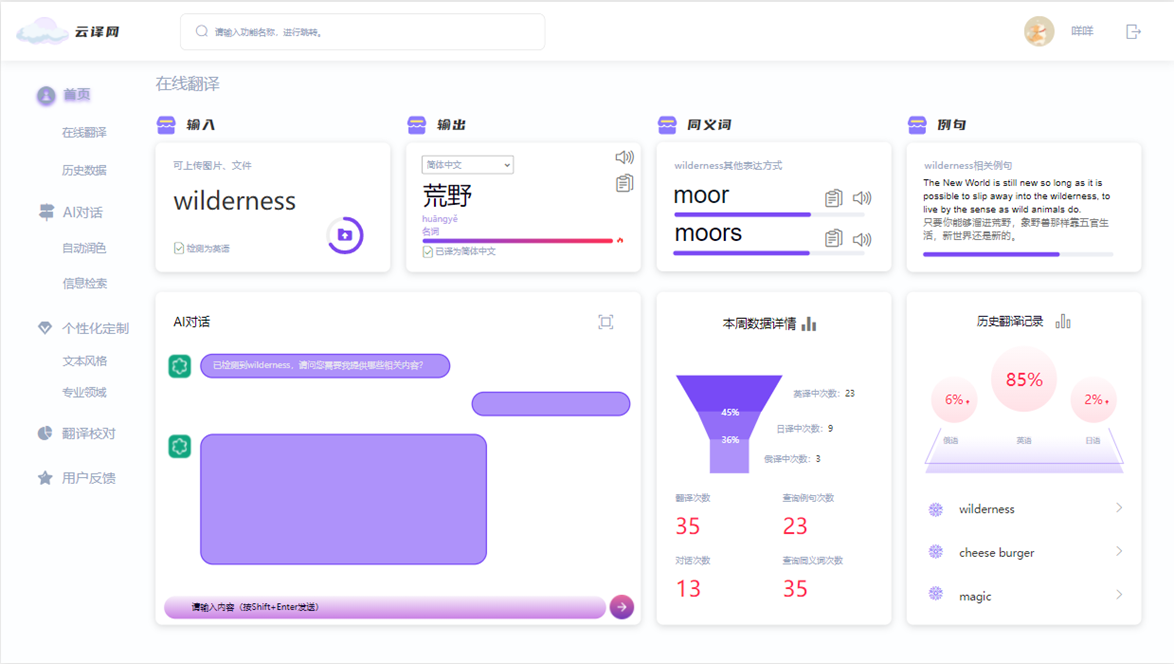
- 意义:作为用户访问的起始页面,提供用户输入文本或图片、文件进行实时翻译的功能页面,展示云译网的核心功能和推荐内容,展示用户最近的翻译记录,方便用户回顾和再次翻译。
- 具体功能:
- 在线翻译入口:提供显眼的按钮,引导用户快速进入在线翻译功能。
- 特色功能介绍:通过图文结合的方式展示个性化定制和AI对话等特色功能。
- 输入区:包含文本输入框及语言选择菜单,用户可输入待翻译文本并选择源语言和目标语言。
- 操作区:包括翻译按钮、语音输入和图片上传等功能,用户可通过多种方式提交翻译请求。
- 结果展示区:显示翻译结果,并提供复制和保存功能,方便用户使用翻译结果。
- 记录列表:按时间顺序显示用户的历史翻译记录和数据信息,便于用户查找。
3. AI对话页面
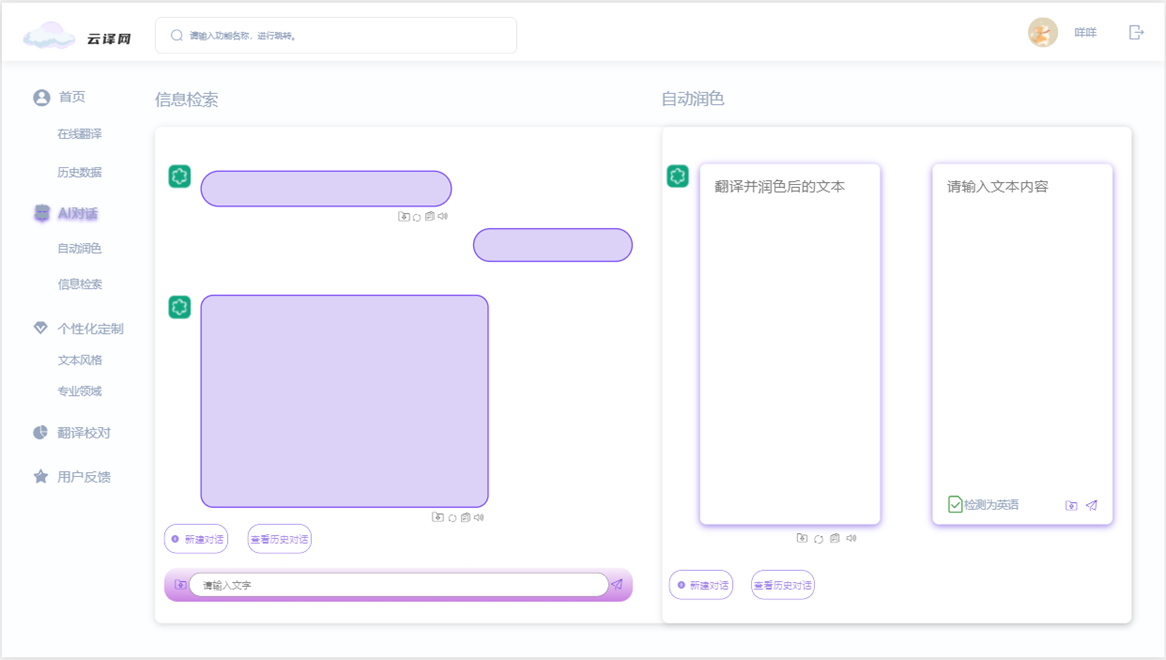
- 意义:提供用户与AI进行互动的平台,获取实时翻译和建议。
- 具体功能:
- 对话输入区:用户可在此输入内容与AI进行对话,获取翻译或相关建议。
- 响应展示区:显示AI的回答和建议,提供实时互动体验。
4. 个性化定制页面
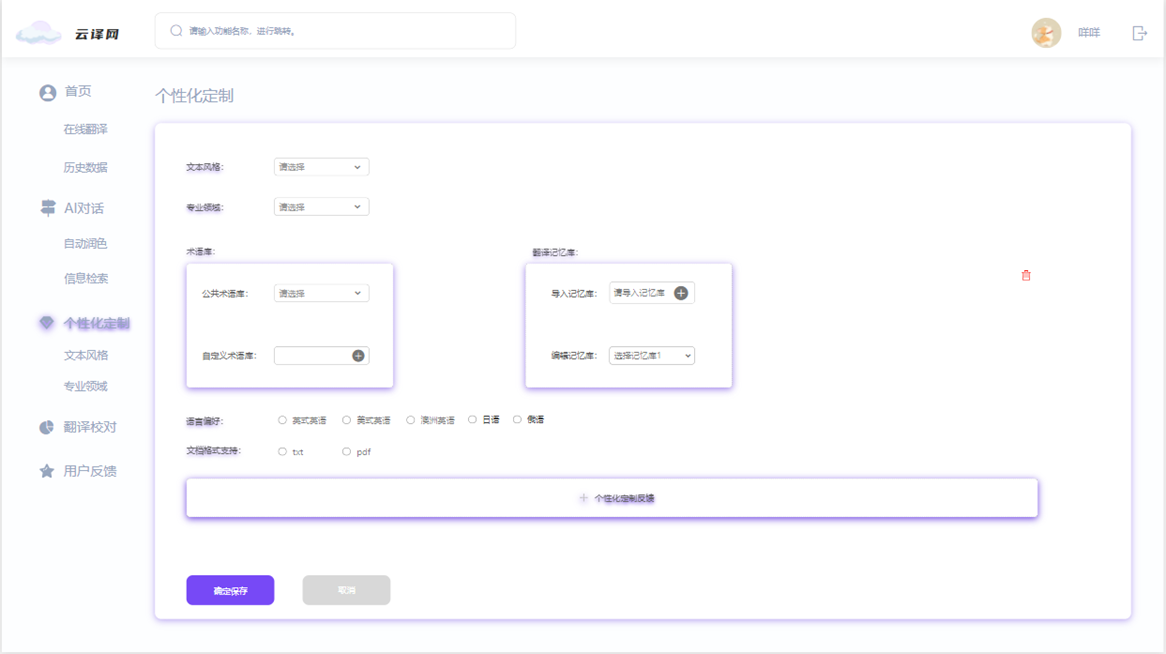
- 意义:允许用户设置翻译风格与专业领域,以获得更符合个人需求的翻译结果。
- 具体功能:
- 风格选择:提供多种翻译风格供用户选择,如正式、口语化等。
- 专业领域设置:用户可选择适用的专业领域和管理术语库,以提高翻译的专业性和准确性。
- 保存设置按钮:保存用户的个性化设置,以便在未来的翻译中自动应用。
5. 翻译校对页面
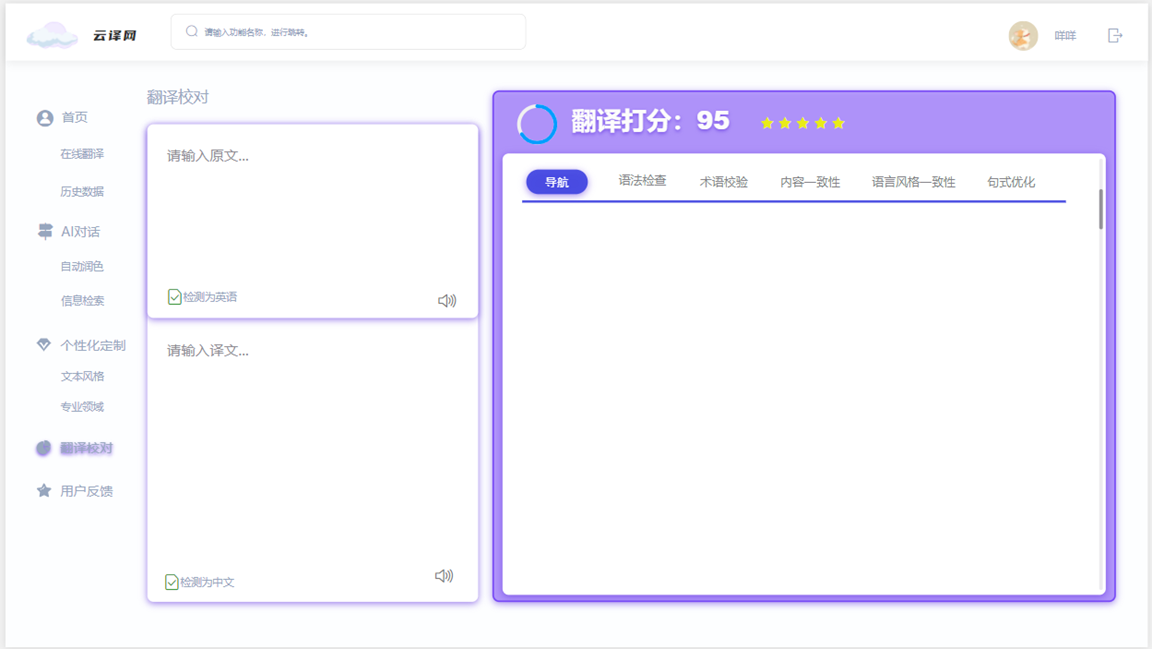
- 意义:提供用户校对和优化翻译内容的功能页面,方便用户了解自己的翻译水平和优势劣势。
- 具体功能:
- 原文与译文输入区:用户可分别输入原文和译文进行校对,确保翻译质量。
- 校对功能按钮:提供语法检查、术语校验等功能,帮助用户提高翻译准确性。
- 翻译打分功能:显示翻译质量得分,为用户提供翻译质量的参考。
6. 用户反馈页面
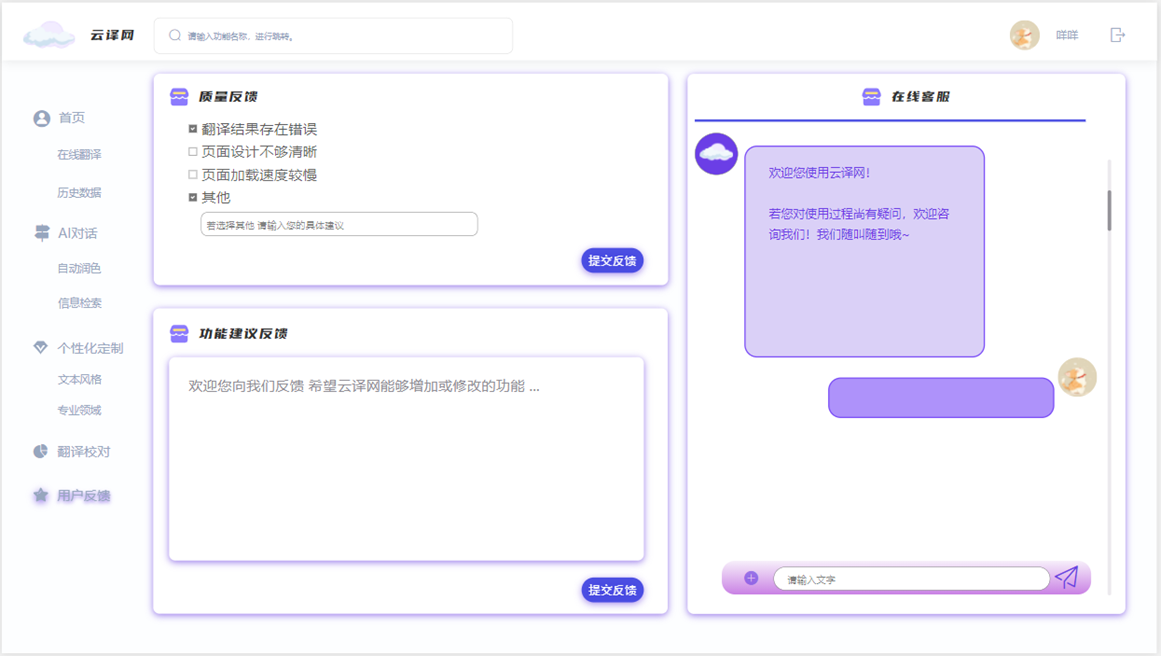
- 意义:提供用户反馈和建议的渠道,帮助云译网收集用户意见,不断优化服务和功能。
- 具体功能:
- 质量反馈:用户可以报告翻译结果中的错误,帮助提升翻译质量。
- 功能建议反馈:用户可以提出对云译网功能增加或修改的建议,促进产品迭代。
- 提交反馈:用户填写完反馈内容后,可以提交给云译网团队,以便团队进行后续处理。
7. 用户个人中心页面
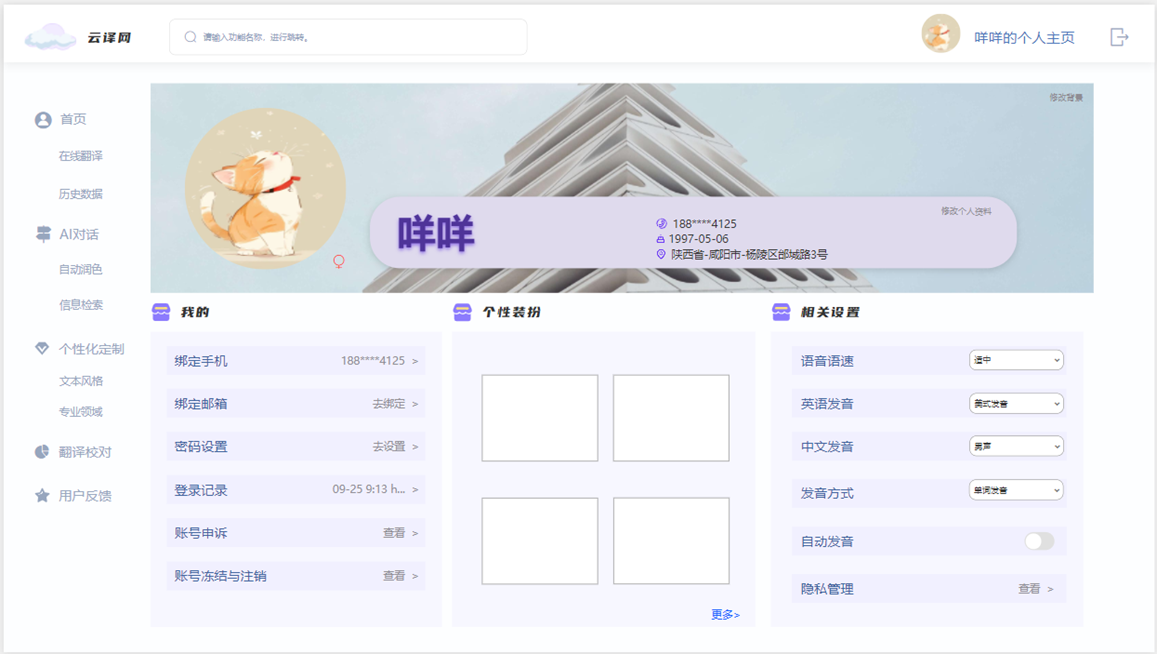
- 意义:用户查看和修改个人信息的页面。
- 具体功能:
- 用户信息展示:显示用户名、头像、绑定手机号和邮箱等信息,方便用户管理个人信息。
- 个性化设置快捷入口:提供快捷入口,方便用户调整个性化设置。
- 相关设置选项:包括语音设置、发音方式和隐私管理等,让用户全面控制个人账户。
2 后台管理系统原型
链接:https://rp.mockplus.cn/run/GN5wyZx9NE/y7vEr9Pml
1. 仪表盘页面
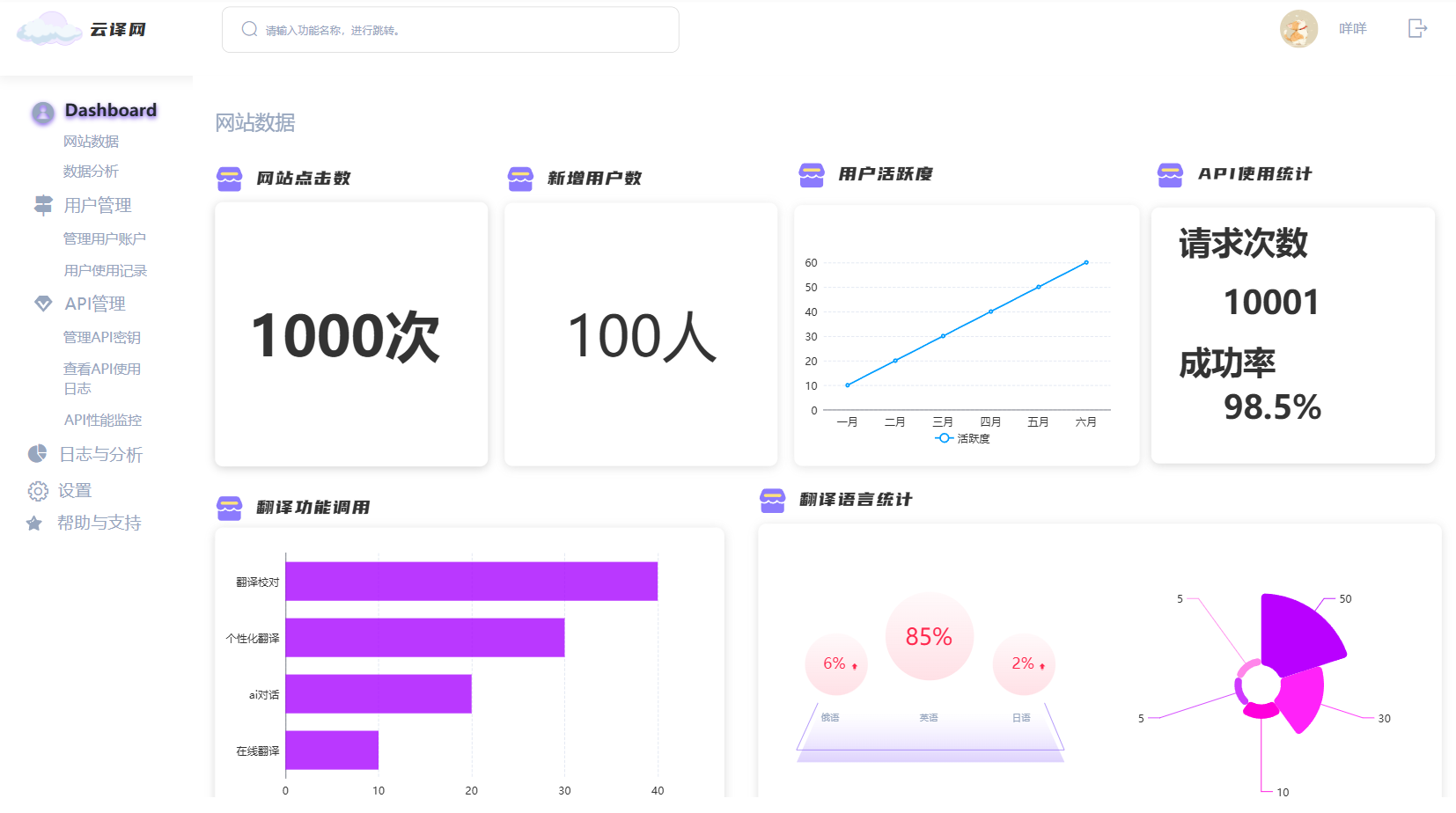
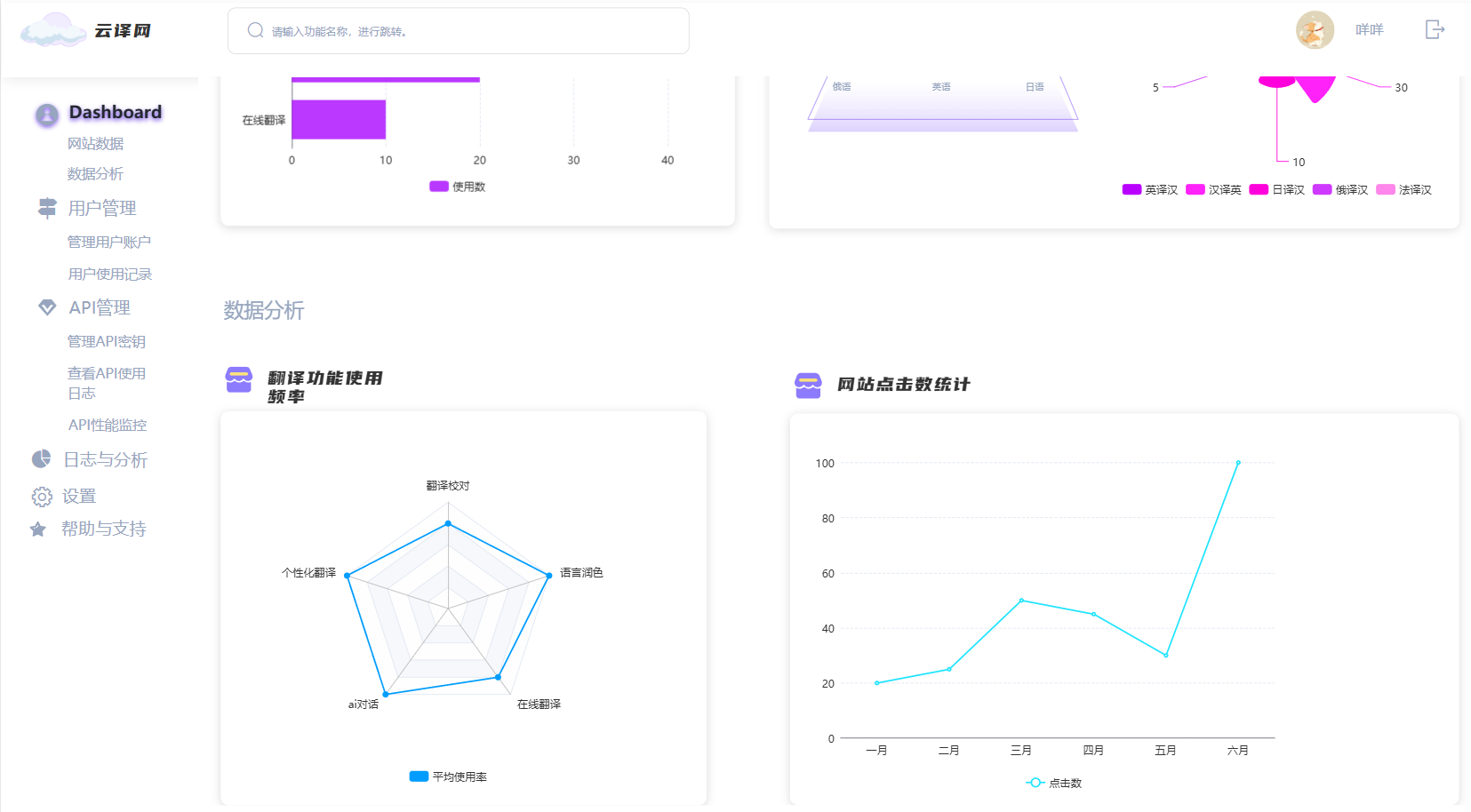
- 意义:提供网站整体运行情况的概览,包括关键数据指标和统计信息。
- 具体功能:
- 网站数据:展示网站点击数、新增用户数、用户活跃度等关键数据。
- API使用统计:显示API的请求次数、成功率等统计信息。
- 用户管理:提供用户账户管理和请求次数的概览。
- 日志与分析:展示日志记录和数据分析的结果。
2. 用户管理页面
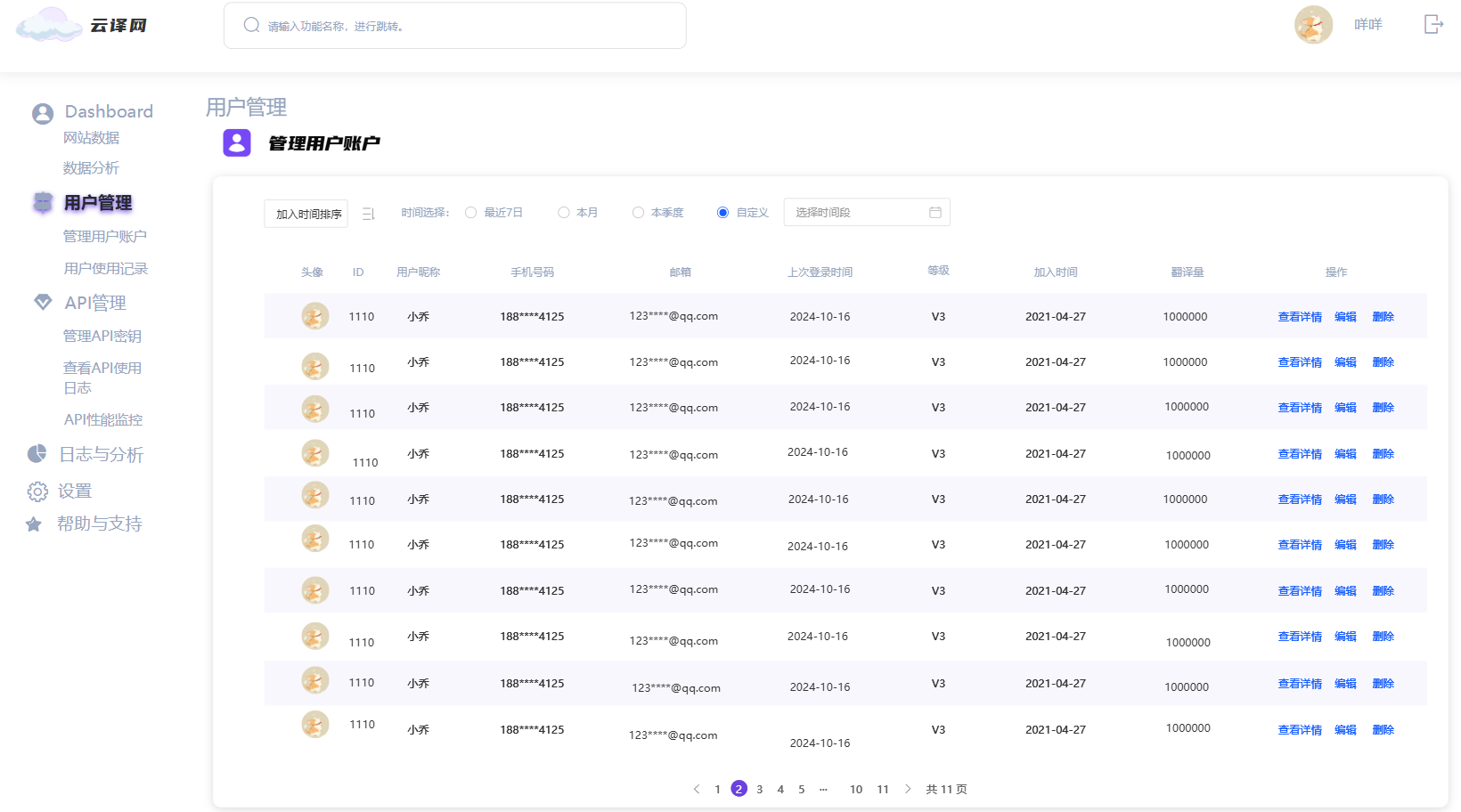
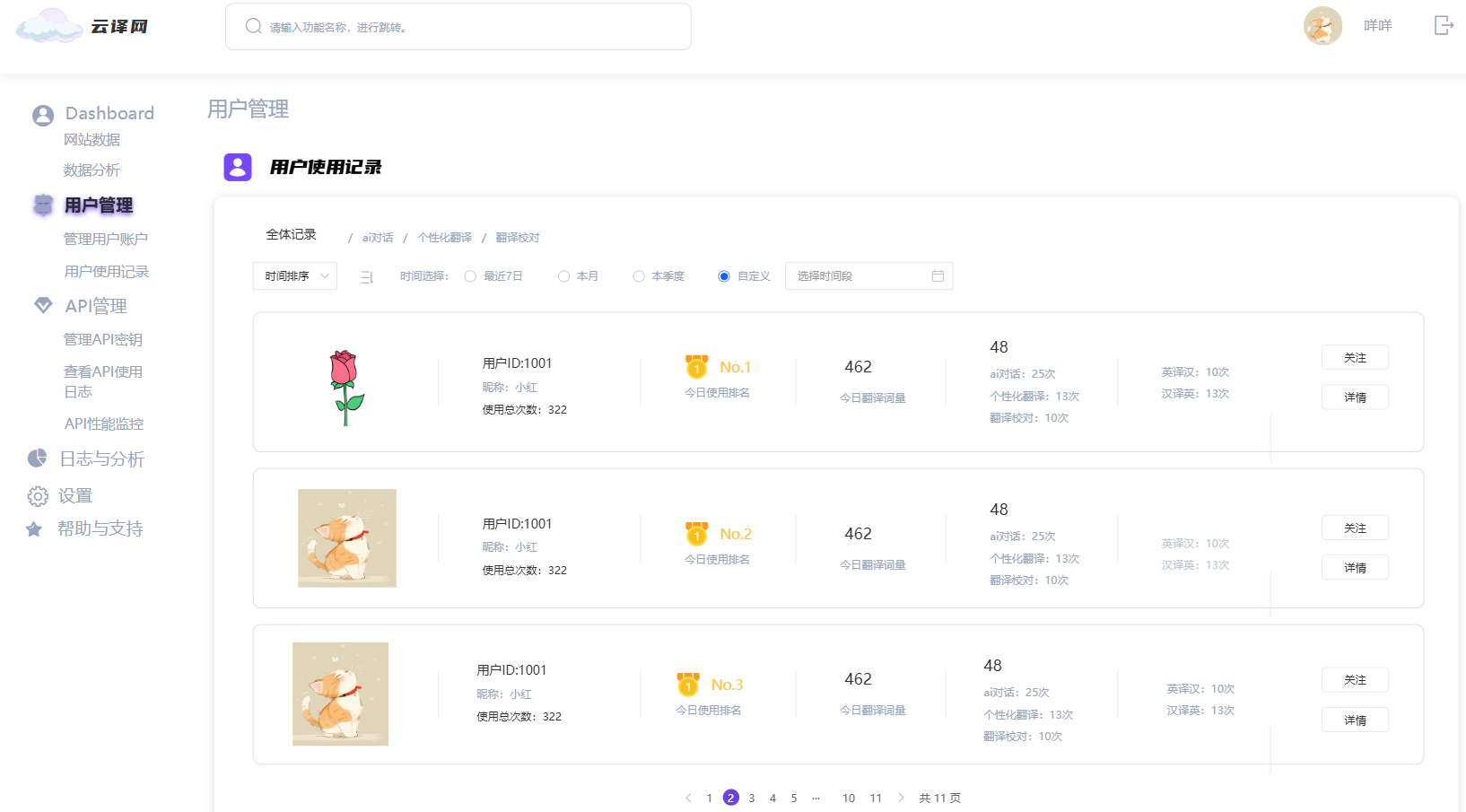
- 意义:管理员管理用户信息的页面,用于维护用户数据和权限。
- 具体功能:
- 用户列表展示:以表格形式列出用户信息,包括用户ID、用户名、手机号、邮箱、上次活动时间等,方便管理员查看和管理。
- 操作按钮:提供查看、修改和封禁用户的功能,增强用户管理的灵活性。
3. API管理页面
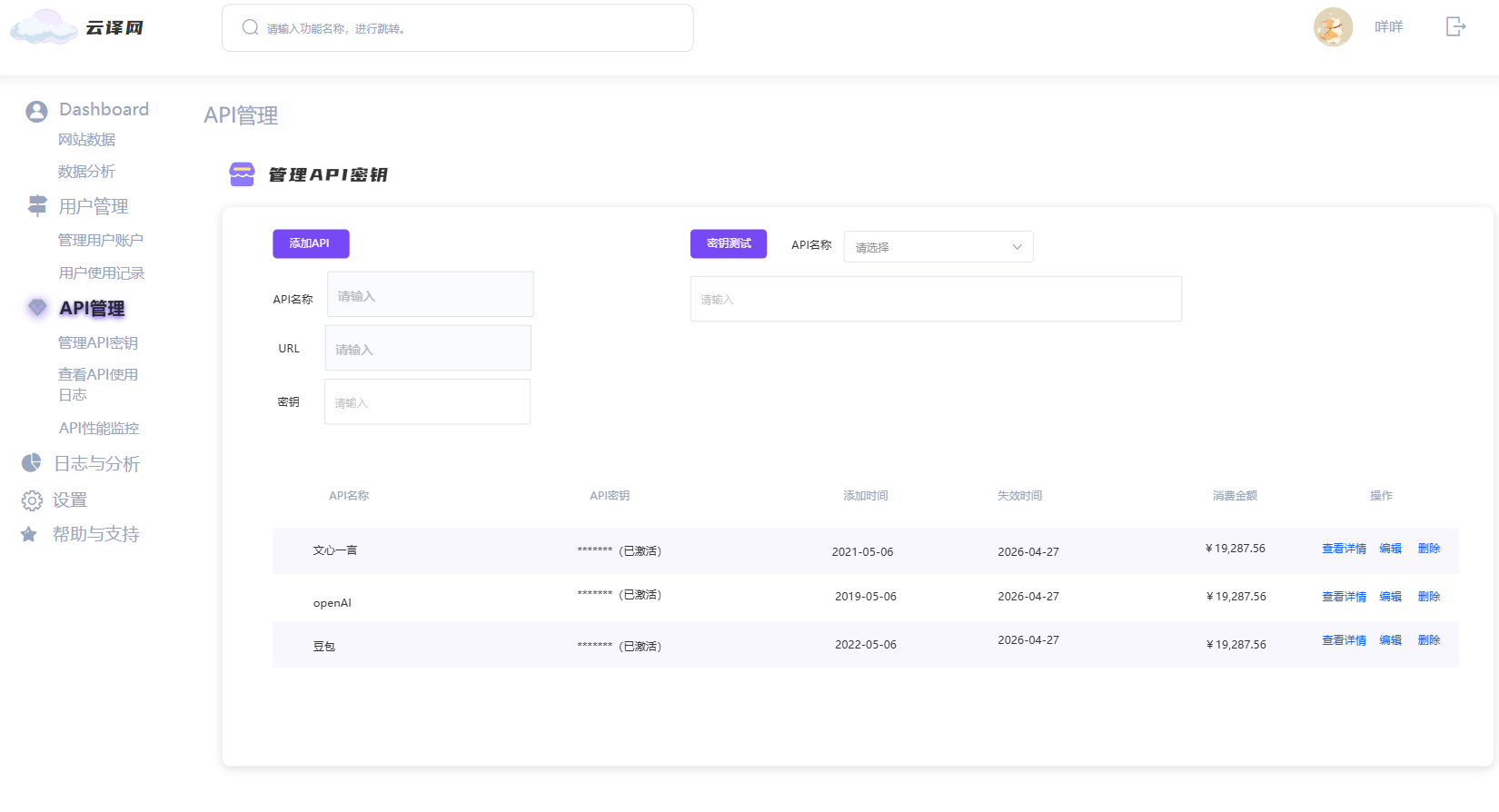
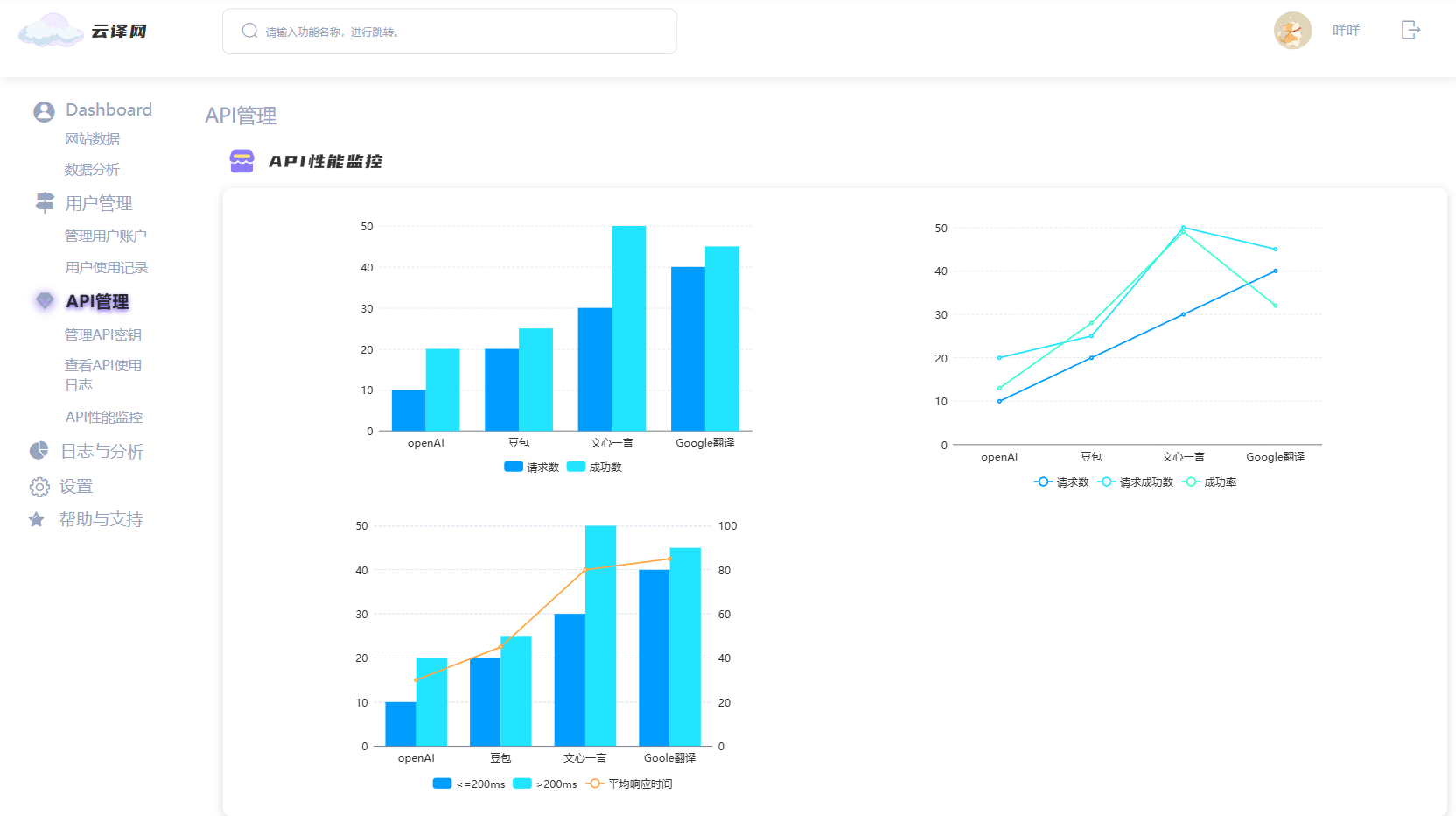
- 意义:管理API密钥和监控API使用情况的页面。
- 具体功能:
- 管理API密钥:允许管理员查看和修改API密钥,确保API的安全性。
- API使用统计:展示API的请求次数、成功率等统计信息,帮助管理员监控API的使用情况。
- API性能监控:提供API响应时间和性能的监控,确保API的稳定性。
4. 日志与分析页面
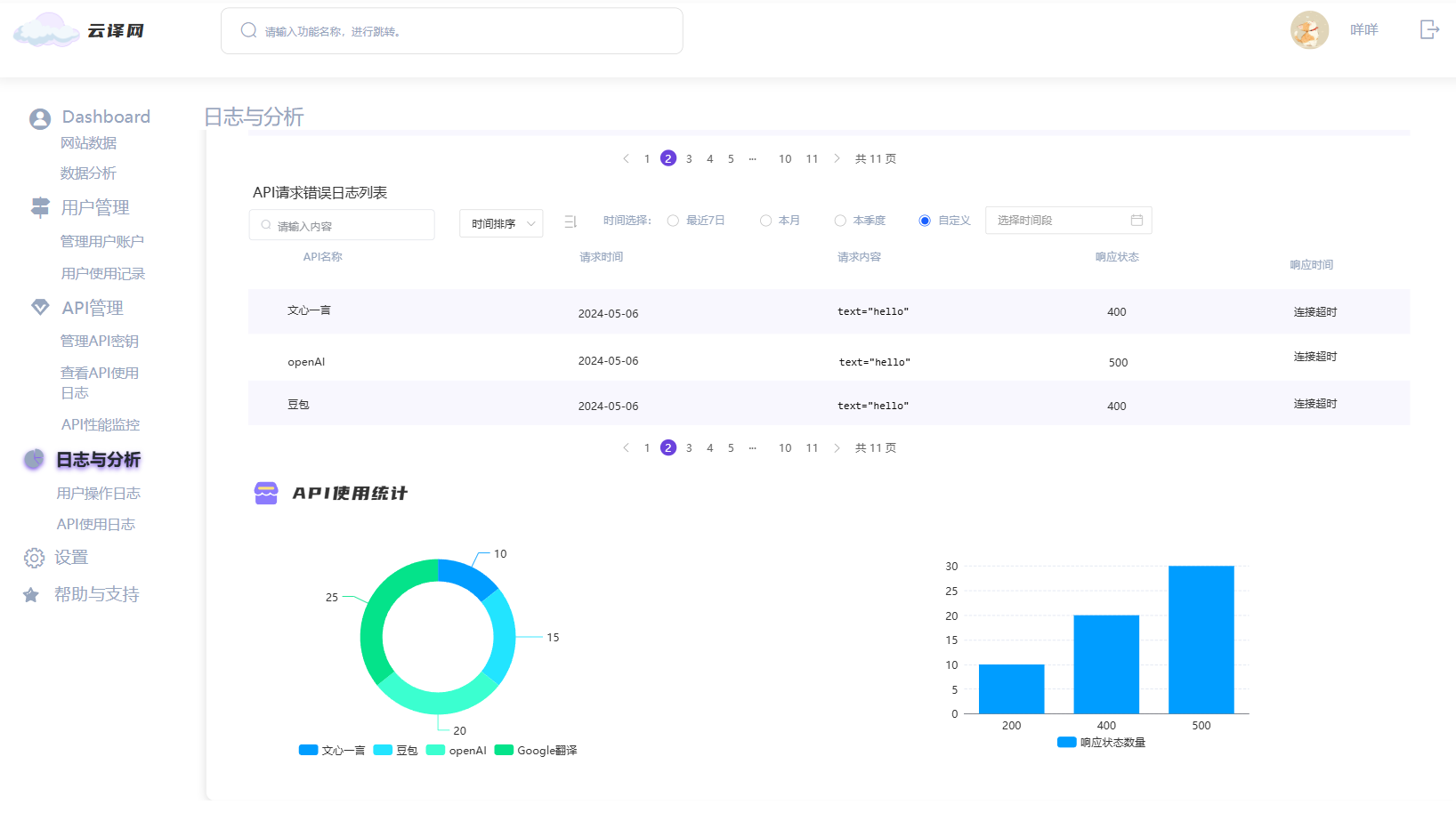
- 意义:记录和分析系统日志,帮助管理员了解系统运行情况和用户行为。
- 具体功能:
- 日志记录:展示系统运行日志,包括用户操作日志和API请求日志。
- 数据分析:提供数据分析工具,帮助管理员从日志中提取有价值的信息。
5. 设置页面
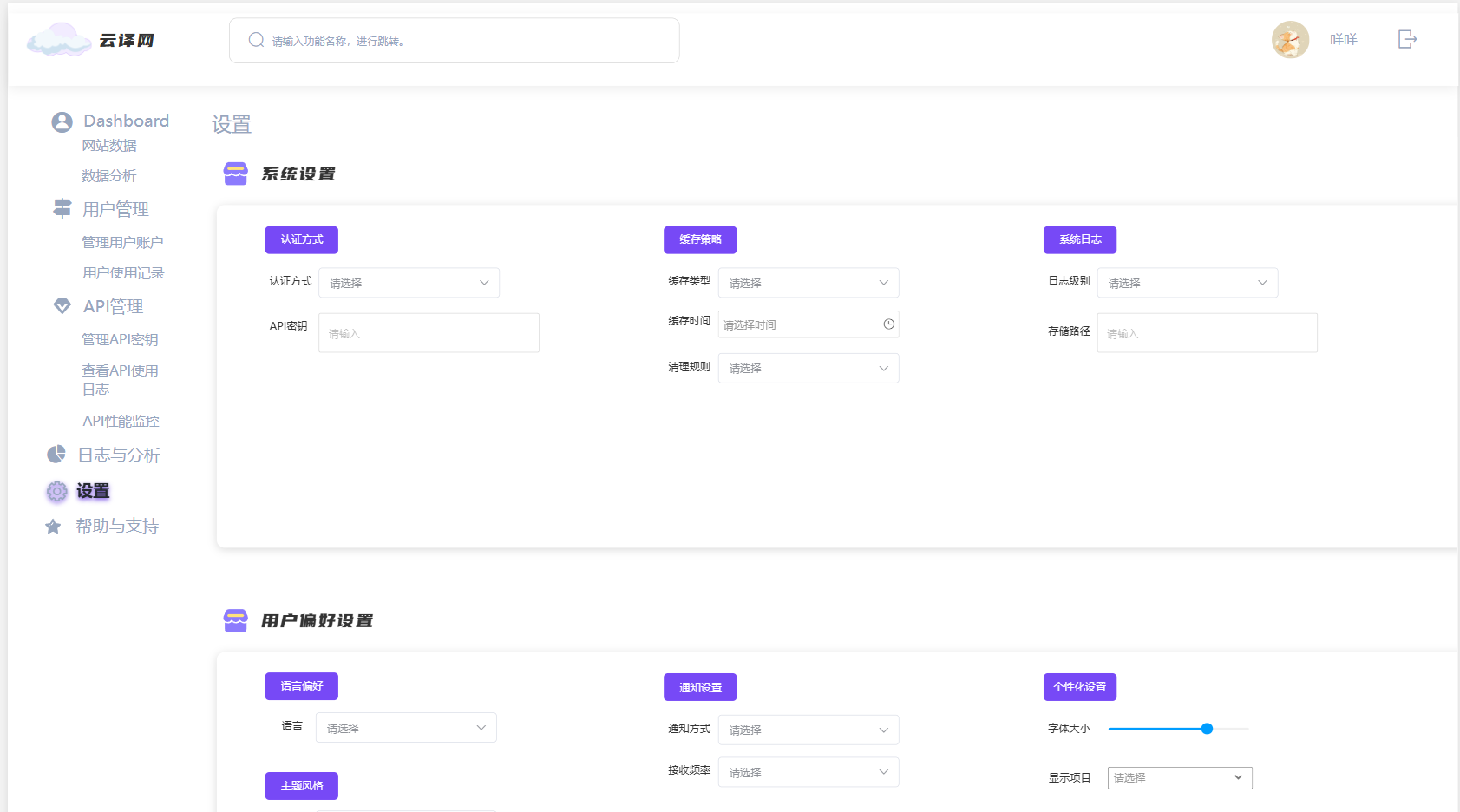
- 意义:提供系统设置和个性化选项的页面。
- 具体功能:
- 用户设置:允许管理员配置用户相关的设置,如认证方式、通知方式等。
- 系统设置:提供系统级别的设置选项,如语言偏好、字体大小等。
6. 帮助与支持页面
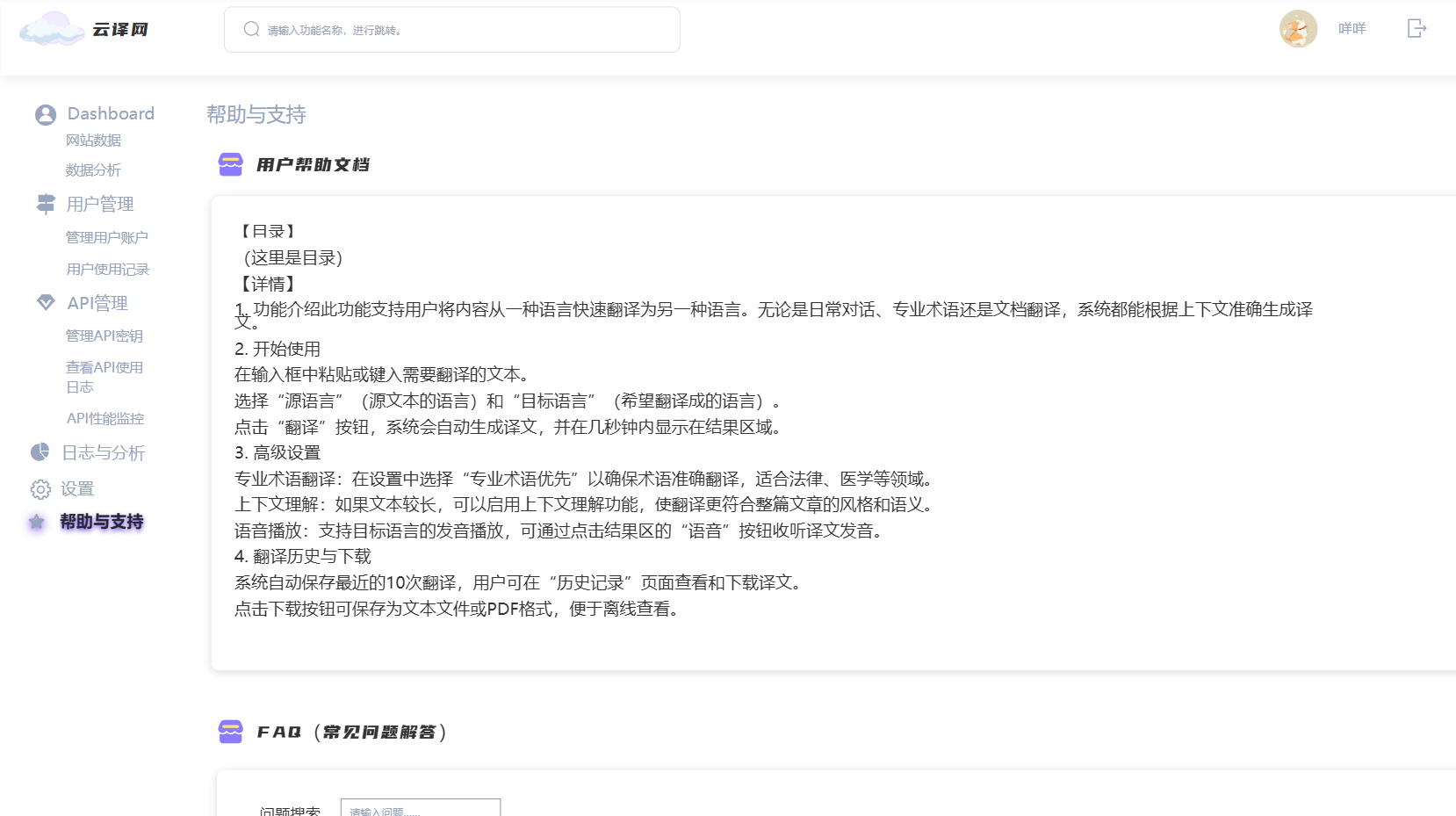
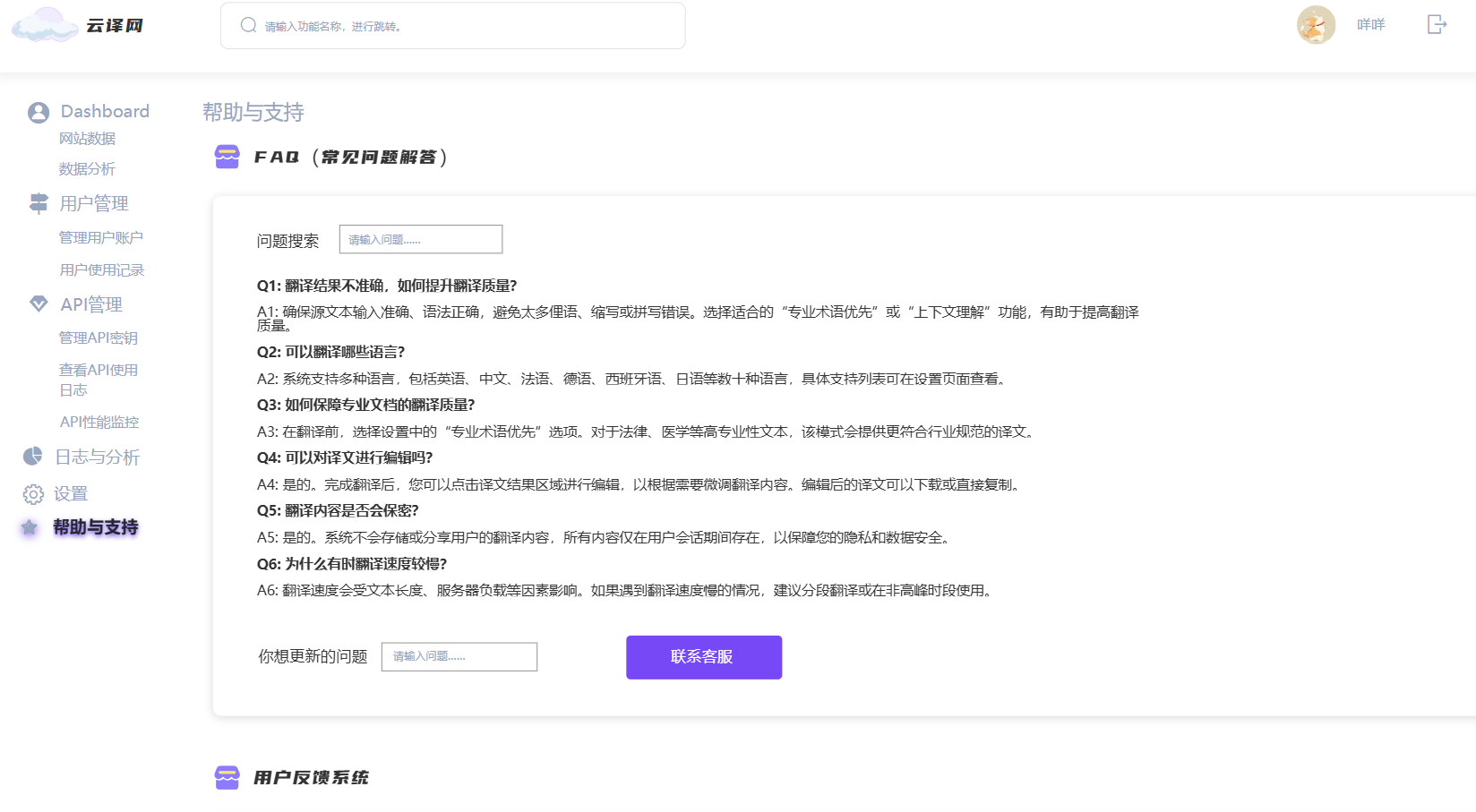
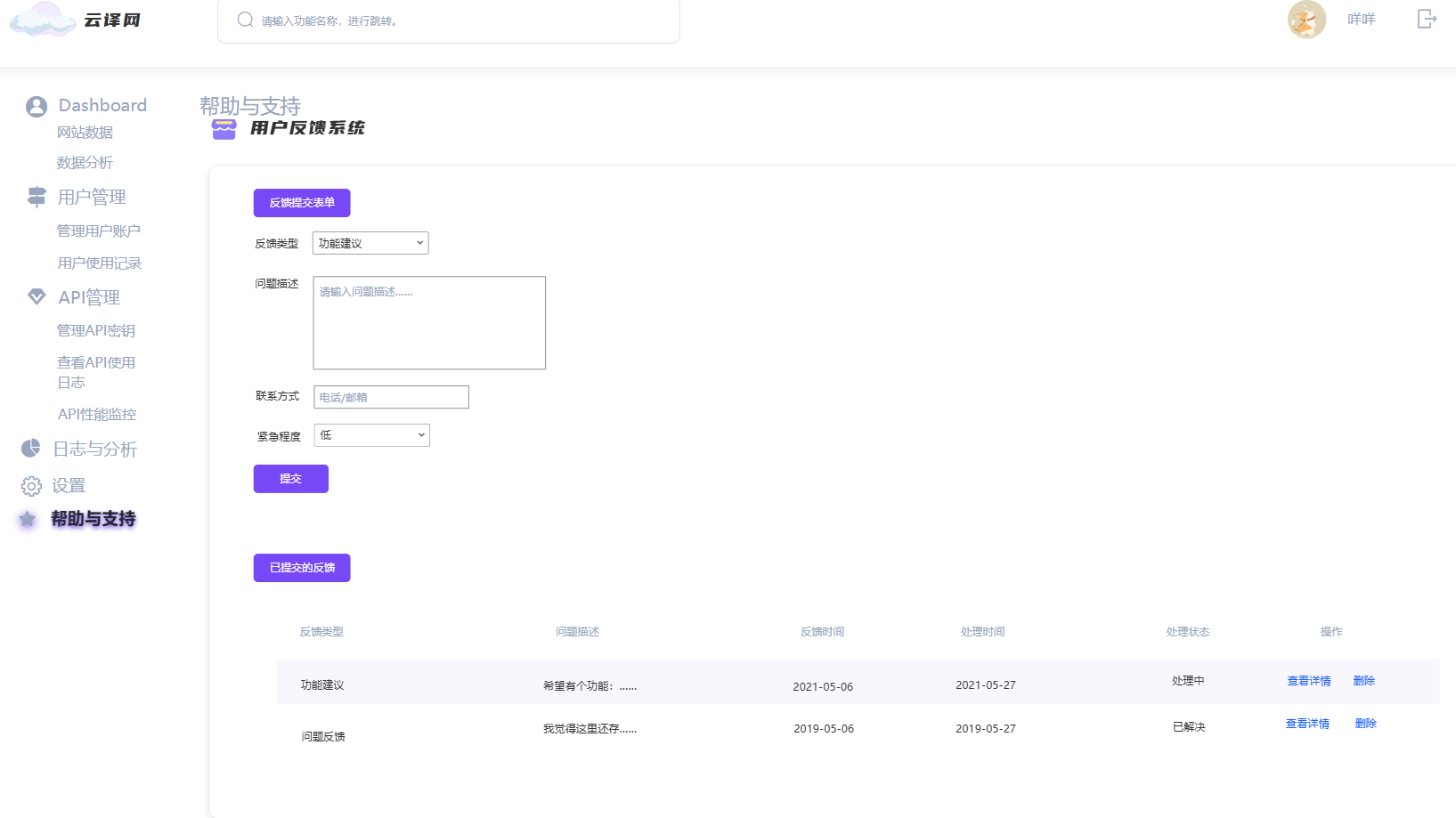
- 意义:提供用户帮助文档和联系方式,帮助用户解决问题。
- 具体功能:
- 用户帮助文档:提供详细的使用指南和常见问题解答。
- 联系方式:展示客服的联系方式,方便用户在遇到问题时能够及时联系到支持团队。
三、用户交互
1 交互逻辑
- 导航交互:用户可通过顶部导航栏和侧边栏进行页面切换,实现快速导航。
- 操作交互:用户通过点击按钮、输入文本、选择菜单等方式与系统进行交互,实现功能操作。
2 导航设计
- 前台导航:设计简洁明了,主要功能入口通过顶部导航栏展示,方便用户快速找到所需功能。
- 后台导航:侧边栏列出页面主要管理功能,方便管理员快速切换至不同管理模块。
3 反馈机制
- 操作反馈:系统在用户完成操作后提供实时反馈,如翻译完成提示,增强用户体验和操作的直观性。
后端设计
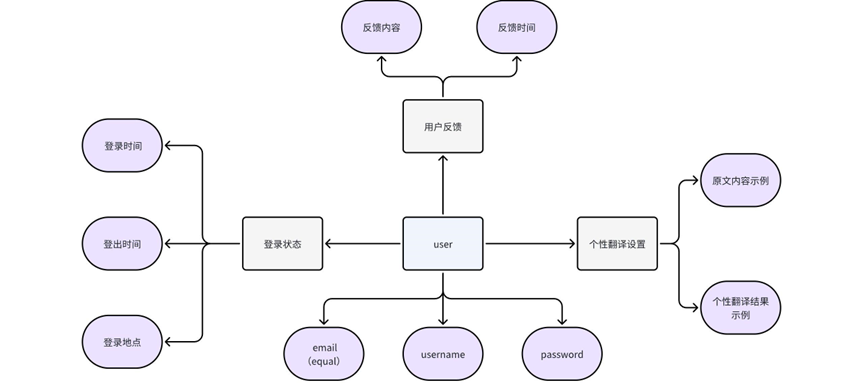
本次数据库设计主要使用 MongoDB,相比于传统的 Mysql 数据库,MongoDB 有着更强大的灵活性,其JSON 文档结构能更自然地表示嵌套对象和数组,适合存储个性化翻译内容和用户反馈等复杂数据。用户模型、翻译记录等数据结构可能随业务变化而调整,MongoDB 的灵活性也使数据结构的改变更便捷
一、数据库设计
1 数据结构设计
用户(userInfo + termLibrary + feedback + loginRecords)
{
"_id": "ObjectId", // 用户在 MongoDB 中的唯一标识符
"username": "String", // 用户名,添加唯一索引
"password_hash": "String", // 密码哈希值
"email": "String", // 用户邮箱,添加唯一索引
"created_at": "Date", // 注册时间
"updated_at": "Date", // 最后登录时间
"term_library": [ // 用户的个性翻译记录,嵌套数组
{
"original_content": "String", // 原文内容
"translation": "String" // 个性翻译内容
}
],
"feedbacks": [ // 用户反馈嵌套数组
{
"feedback_text": "String", // 反馈内容
"created_at": "Date" // 反馈时间
}
],
"login_records": [ // 登录记录嵌套数组
{
"login_time": "Date", // 登录时间
"login_location": "location" // 登录地点
"logout_time": "Date" // 登出时间
}
]
}
-
通过将userInfo + termLibrary + feedback + loginRecords嵌套起来,避免跨集合(collection)查询
-
考虑为 email 或者 username 添加唯一索引,以防止重复注册
翻译和对话记录(Translation_Conversation_Records)
{
"_id": "ObjectId", // 翻译记录的唯一标识符
"user_id": "ObjectId", // 关联用户ID,引用 Users 集合
"original_content": "String", // 原文内容
"translated_content": "String", // 译文内容
"dialogs": [ // 多轮对话嵌套数组
{
"text": "String", // 对话内容
"timestamp": "Date" // 时间戳
}
],
"original_language": "String", // 原语言
"target_language": "String", // 翻译目标语言
"created_at": "Date" // 创建时间
}
-
将翻译内容和对话内容进行结合,有利于大模型根据上下文来提供体验更好的翻译结果
-
将多轮对话 dialog 设计为嵌套数组,方便保存多轮对话信息
-
为 user_id 和 created_at 建立复合索引,优化查询效率
翻译校对记录集合(Translation_Proofread_Records)
{
"_id": "ObjectId", // 校对记录的唯一标识符
"user_id": "ObjectId", // 关联用户ID,引用 Users 集合
"original_content": "String", // 原文内容
"translated_content": "String", // 译文内容
"proofread_time": "Date", // 校对时间
"checks": [ // 校对内容的嵌套数组
{
"type": "String", // 检查类型,如 "grammar" 或 "content"
"result": "String" // 检查结果,得分
}
]
}
2 完整数据库设计
1.关系数据模型
Ⅰ 用户表(Users)
Ⅱ 个性翻译表(Term_Library)
Ⅲ 用户反馈表(User_Feedback)
Ⅳ 翻译和对话记录表(Translation_Conversation_Records)
Ⅴ 登录记录表(Login_Records)
Ⅵ 翻译校对记录表
- Ⅰ 用户表(Users)
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| user_id | VARCHAR(20) | 用户id (主键) |
| username | VARCHAR(255) | 用户名 |
| password_hash | VARCHAR(255) | 密码哈希值 |
| VARCHAR(255) | 用户邮箱 | |
| created_time | DATETIME | 注册时间 |
| updated_time | DATETIME | 最后登录时间 |
- Ⅱ 个性翻译表(Term_Library)
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| term_id | INT | 个性翻译表唯一标识 (主键) |
| user_id | VARCHAR(20) | 用户ID(外码) |
| original_content | VARCHAR(255) | 原文内容 |
| translation | VARCHAR(255) | 对应个性翻译 |
- Ⅲ 用户反馈表(User_Feedback)
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| feedback_id | INT | 反馈唯一标识 (主键) |
| user_id | VARCHAR(20) | 用户ID(外码) |
| feedback_text | TEXT | 反馈内容 |
| created_time | DATETIME | 反馈时间 |
- Ⅳ 翻译和对话记录表(Translation_Conversation_Records)
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| record_id | INT | 记录唯一标识 (主键) |
| user_id | VARCHAR(20) | 用户ID(外码) |
| translation_type | INT | 翻译类型(0表示文本,1表示图片) |
| original_content | TEXT | 原文内容 |
| original_image_path | VARCHAR(255) | 原图路径 |
| translated_content | TEXT | 译文 |
| diaglog | TEXT | 对话内容 |
| original_language | VARCHAR(10) | 源语言 |
| target_language | VARCHAR(10) | 目标语言 |
| created_time | DATETIME | 创建时间 |
- Ⅴ 登录记录表(Login_Records)
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| login_id | INT | 登录记录唯一标识 (主键) |
| user_id | VARCHAR(20) | 用户ID(外码) |
| login_time | DATETIME | 登录时间 |
| logout_time | DATETIME | 登出时间 |
- Ⅵ 翻译校对记录表
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| check_id | INT | 翻译校对记录唯一标识(主键) |
| user_id | VARCHAR(20) | 用户id(外码) |
| original_content | TEXT | 原文内容 |
| translated_ontent | TEXT | 译文 |
| grammer_check | TEXT | 语法检查 |
| content_check | TEXT | 内容及风格一致性检查 |
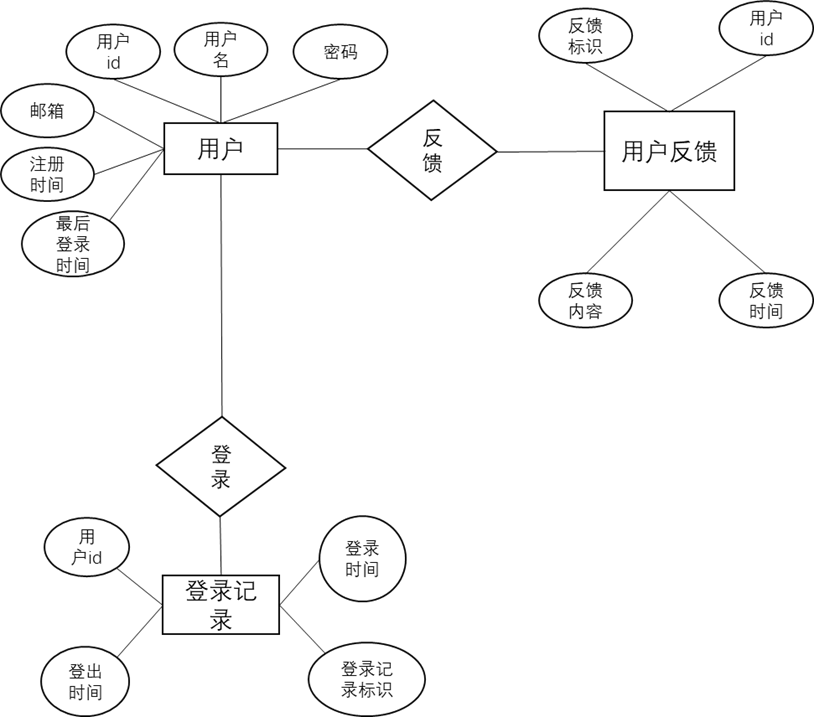
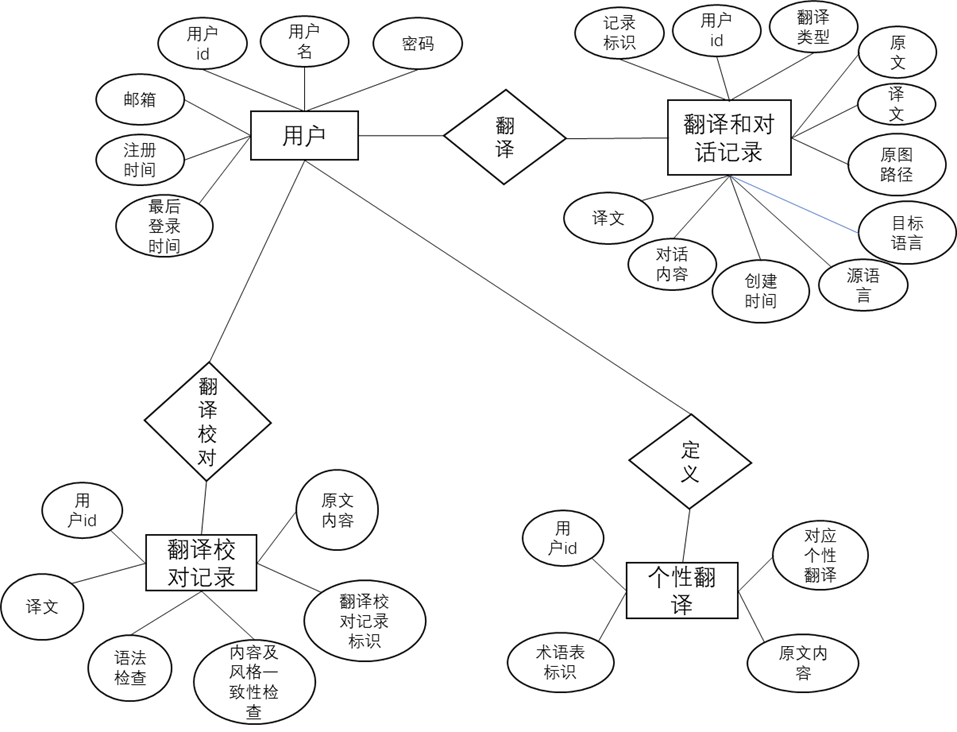
2.ER图
- 用户表、登录记录表和用户反馈表的关系
- 用户表、翻译对话记录、翻译校对、个性翻译表的关系
3.对象关系映射
-
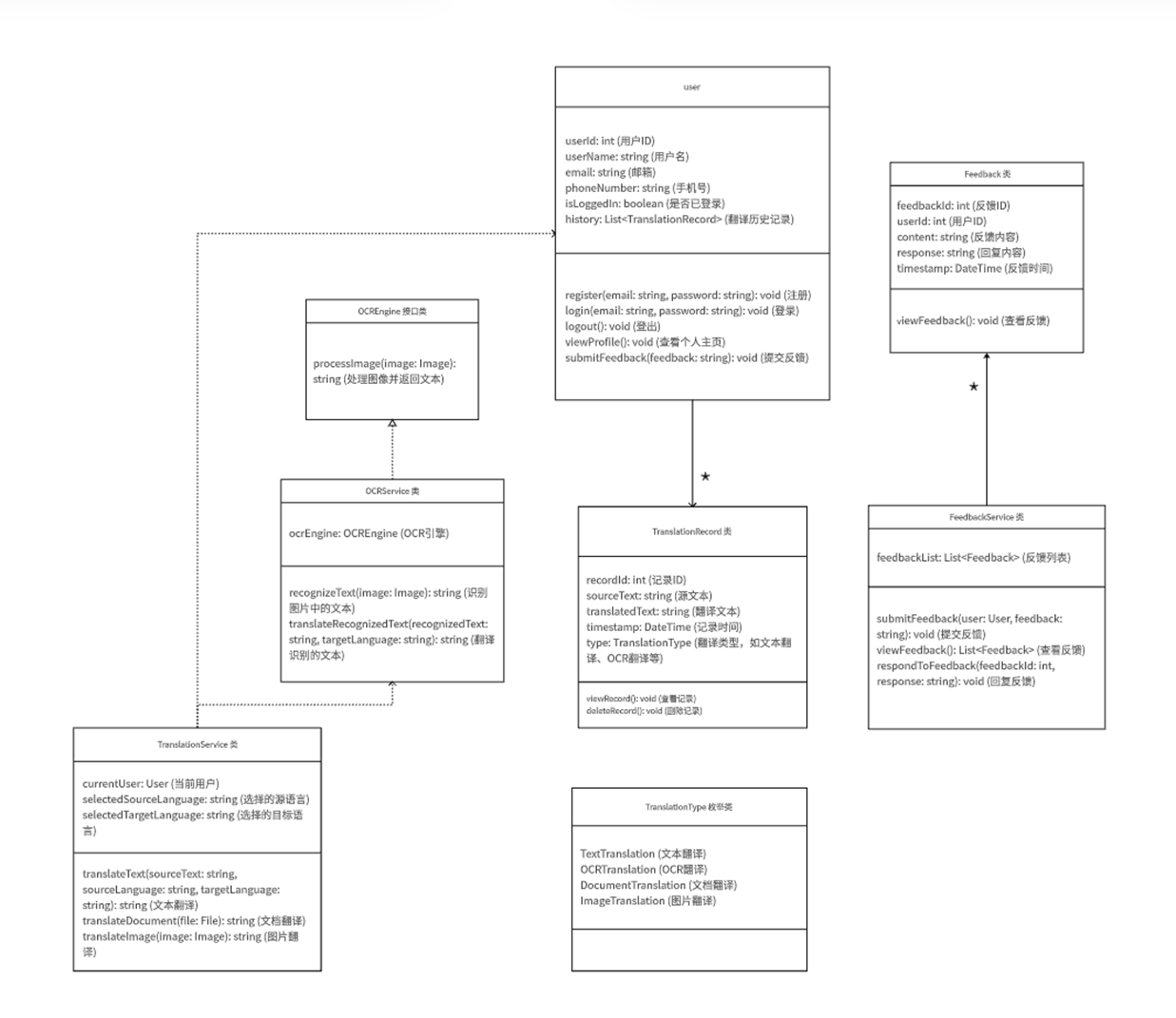
用户表、登录记录表与 User 类:
- user_id -> User类中的属性: userId
- username -> User类中的属性: username
- email -> User类中的属性: email
-
翻译和对话记录表与 TranslationRecord 类、TranslationService类:
- record_id -> TranslationRecord类中的属性: recordId
- user_id -> user类中的属性: userId
- original_content -> TranslationRecord类中的属性: sourceText
- translated_content -> TranslationRecord类中的属性: translatedText
- translation_type -> TranslationRecord类中的属性:TranslationType
- original_language -> TranslationService类中的属性: selectSourceLanguage
- target_language -> TranslationService类中的属性: selectedTargetLanguage
- original_image_path -> TranslationService类中的方法:translateImage
- created_time -> TranslationRecord类中的属性:DateTime
-
用户反馈表与 Feedback 类:
- feedback_id -> Feedback类中的属性:feedbackId
- user_id -> user类中的属性:userId
- feedback_text -> Feedback类中的属性: content
- created_time-> Feedback类中的属性: DateTime
-
个性翻译表:对应用户个性化翻译功能
-
翻译校对记录表:对应翻译校对功能
二、后端架构
1 架构图
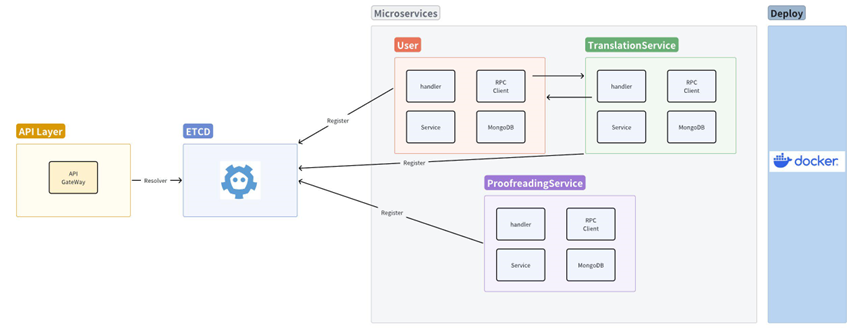
API层:
- 接受并转发前端的请求,从微服务层获取结果并做整理返回给前端
ETCD
- 保存管理 RPC 的 server 端和 client 端
微服务层:
- translationService:负责翻译相关的请求
- ProofreadingService:负责文本的校对和修正工作
- 该微服务通过RPC进行通信,实现服务之间的解耦和独立部署,提高系统的灵活性和可扩展性
- 使用MongoDB作为数据存储,确保数据的持久化和高效访问
部署层:
- 采用Docker容器化技术,将各个微服务器打包成容器进行部署
- 容器化技术使系统更加灵活,便于系统的拓展和维护
2 架构概述
云译网的后端架构需要支持高质量翻译服务、个性化翻译、用户界面优化、实时翻译与优化以及未来功能拓展等核心和辅助功能。因此,在设计后端架构时,我们需要考虑系统的可扩展性、高性能、高可用性和安全性。
3 核心组件
翻译引擎
基于LLM的翻译模型:这是云译网的核心组件,负责处理用户输入的文本、语音或图片,并生成高质量的翻译结果。
自定义术语库:存储用户自定义的专业术语翻译,以便在翻译过程中使用。
用户管理
用户信息存储:存储用户的个人信息,包括注册信息、偏好设置等。
权限管理:管理用户的访问权限,确保只有授权用户才能访问特定功能。
实时翻译系统
缓存机制:用于存储常见的句子和翻译结果,以提高响应速度。
实时翻译处理:处理用户的实时翻译请求,并返回翻译结果。
后端服务
API接口:提供RESTful接口,供前端或其他应用程序调用。
数据库:存储用户数据、翻译记录等。
4 架构设计
微服务架构
-
将翻译引擎、用户管理、实时翻译系统等核心组件拆分为独立的微服务,每个微服务都有自己的数据库和API接口。
-
微服务之间通过轻量级通信协议(如HTTP/REST、gRPC)进行通信。
负载均衡与容错
-
使用负载均衡器(如Nginx、HAProxy)将请求分发到多个微服务实例上,以实现高可用性和负载均衡。
-
采用熔断器(如Hystrix)和重试机制来处理微服务之间的调用失败,提高系统的容错能力。
数据持久化
- 使用MongoDB存储用户数据和翻译记录,确保数据的一致性和完整性。
安全性
-
使用HTTPS协议来加密用户数据在传输过程中的内容,确保数据的安全性。
-
实施身份验证和授权机制,确保只有授权用户才能访问特定功能。
5 功能拓展
API服务
-
提供完善的API文档和SDK,方便其他应用程序或平台集成云译网的翻译功能。
-
支持多种编程语言和开发框架的接入。
语音翻译和图片文字翻译
-
引入语音识别和图像识别技术,实现语音翻译和图片文字翻译功能。
-
优化后端系统以支持这些新功能的实时处理和高效存储。
智能推荐与个性化服务(*)
-
利用用户数据和翻译记录进行智能推荐,提高用户的满意度和忠诚度。
-
引入机器学习算法来优化个性化翻译服务,提高翻译质量。
三、概要设计
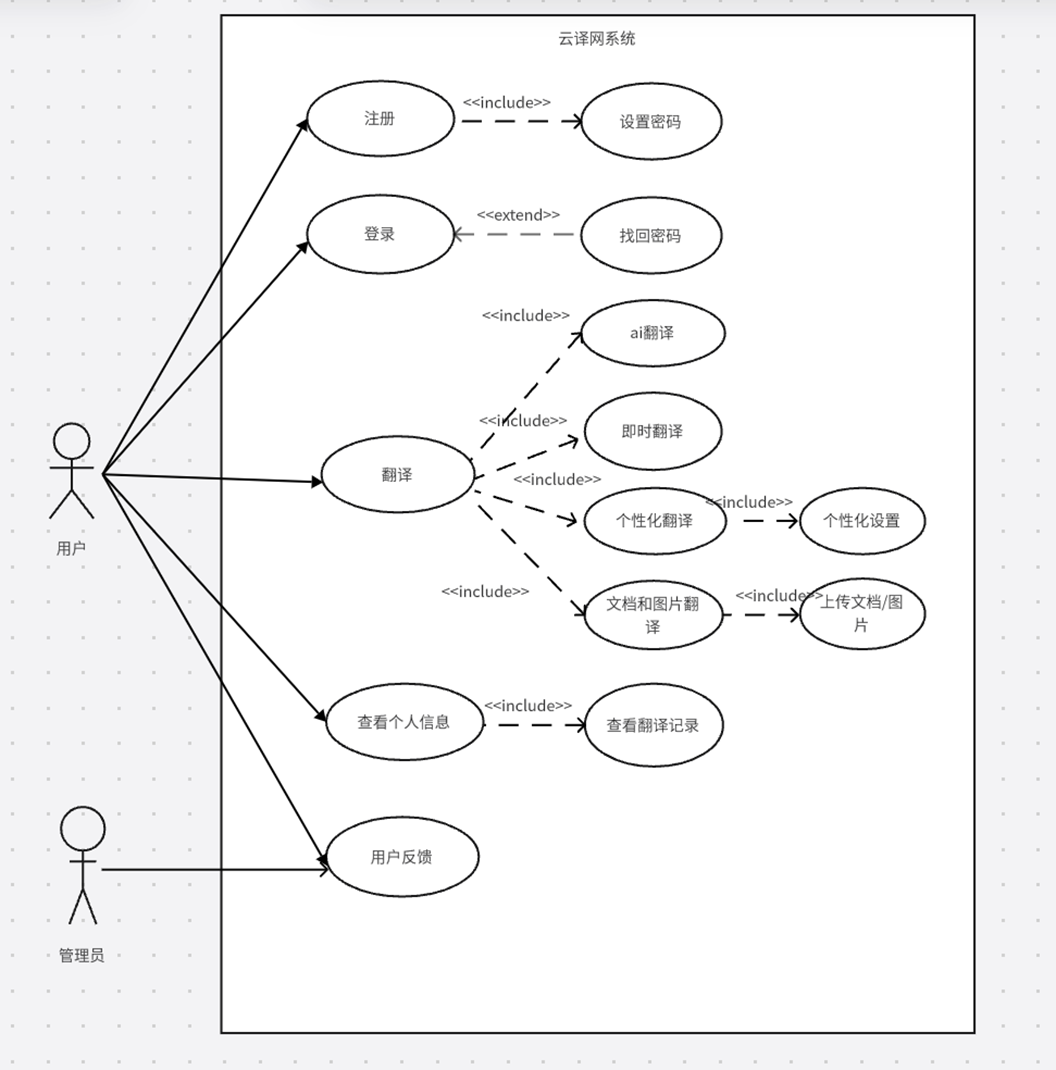
1 用例图
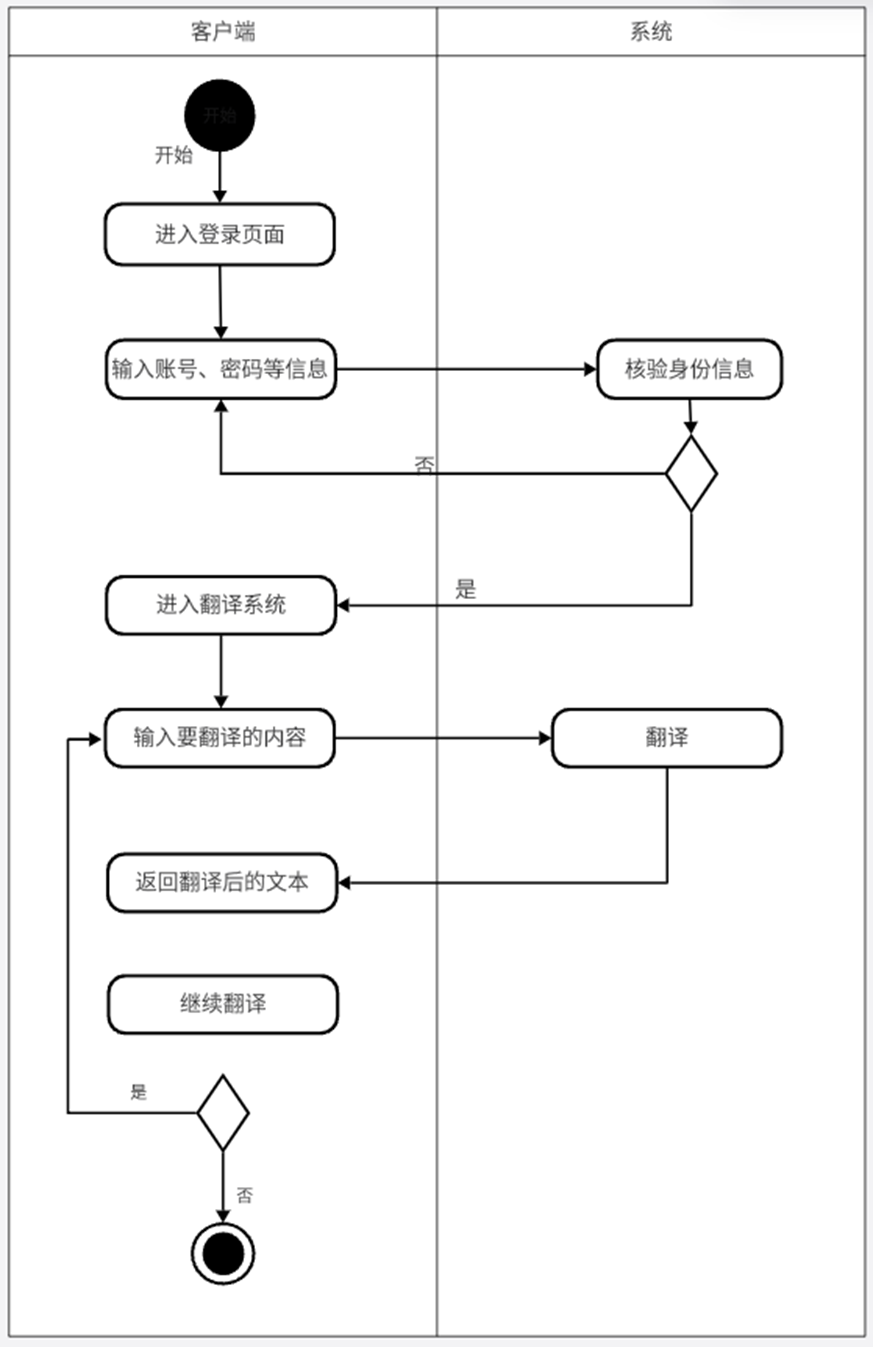
2 活动图
3 类图
4 时序图
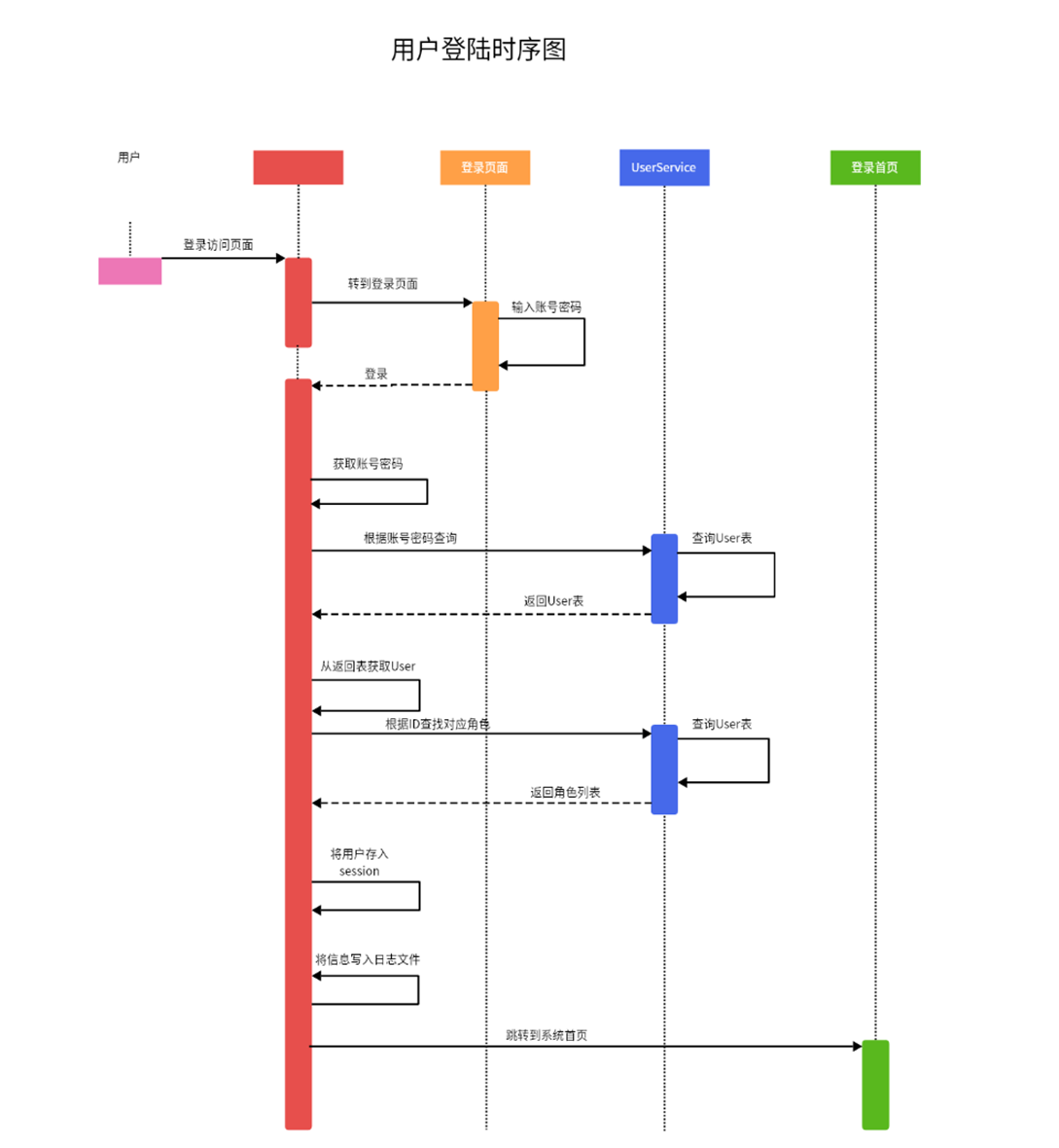
登录模块:
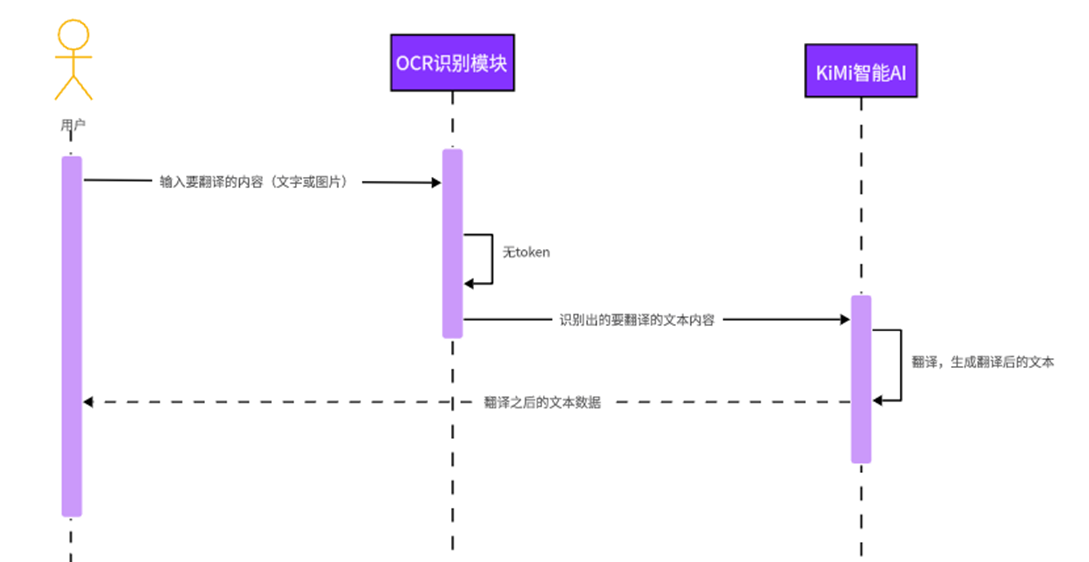
翻译模块:
5 协作图
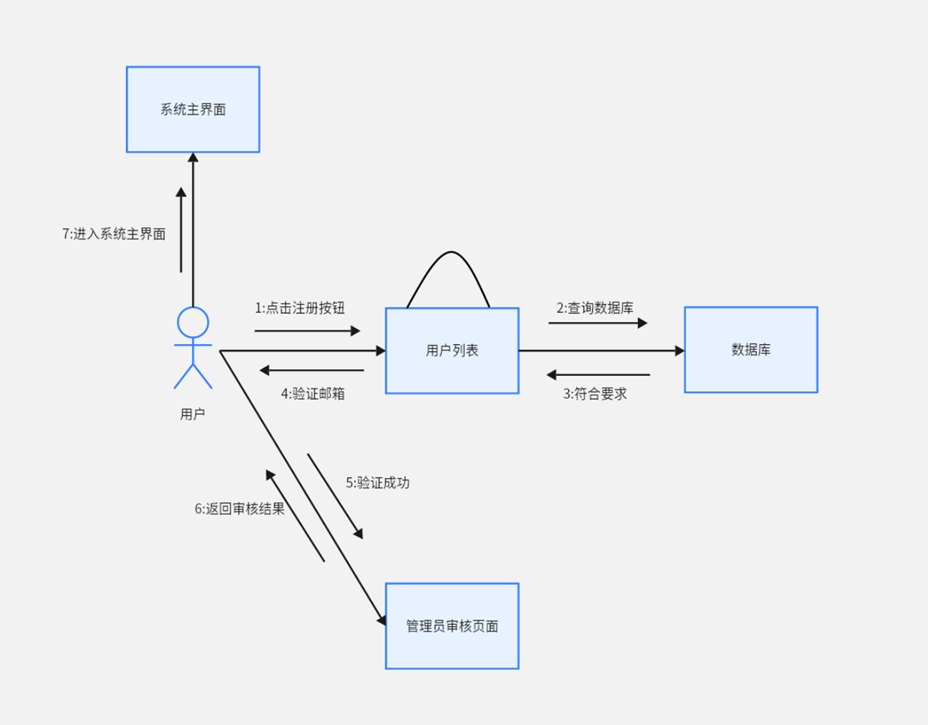
用户注册:
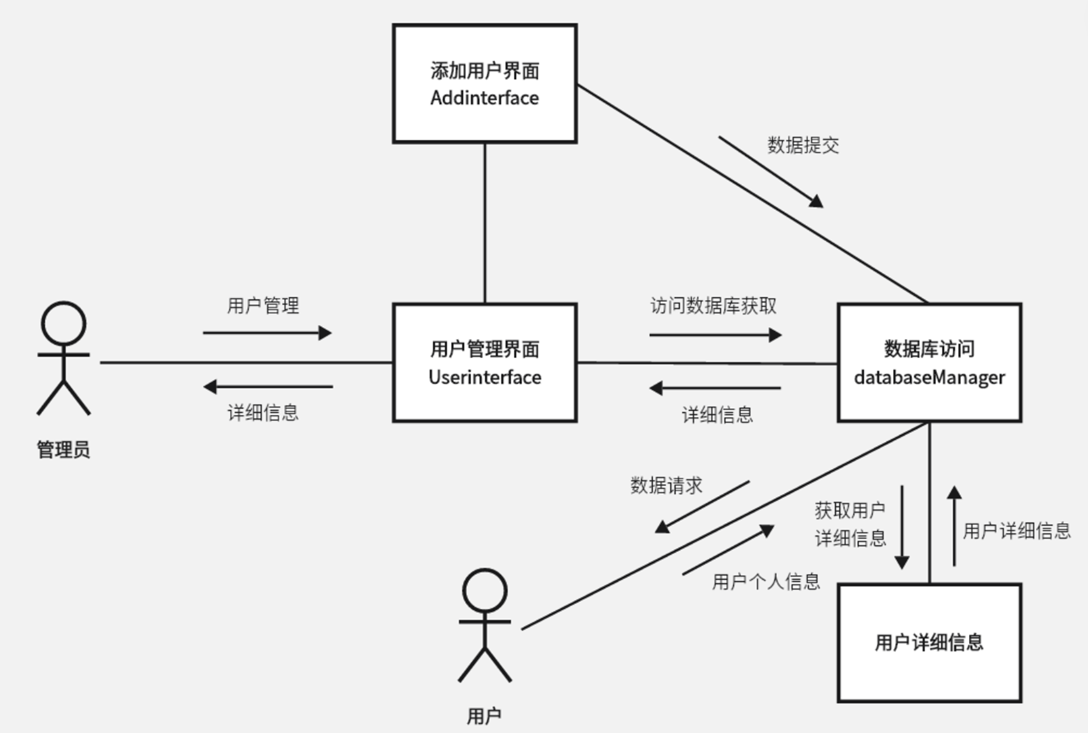
用户管理:
团队协作
一、预计计划安排表
| 周次 | 时间 | 产出 |
|---|---|---|
| 第1周 | 11月2日 - 11月8日 | 前端页面设计、后端基础功能实现进度达到60%以上 |
| 第2周 | 11月9日 - 11月15日 | 完成前后端设计,撰写相关文档 |
| 第3周 | 11月16日 - 11月22日 | 前后端集成,系统功能初步演示,完成测试报告 |
| 第4周 | 11月23日 - 11月29日 | 审查代码,修复bug并优化性能,交予用户使用,收集反馈再度优化 |
二、预计开发计划分工
| 姓名 | 角色 | 负责的开发部分 |
|---|---|---|
| 侯丽珂 | 组长 | 项目整体规划与管理,协作沟通,进度跟踪 |
| 肖晗涵、陈鹭 | 前端开发人员 | 前端界面设计,用户交互功能实现 |
| 戴康怡 | 前端总负责人 | 辅助前端开发,了解各部分功能编写相关文档 |
| 赵弈茗 | 后端总负责人 | 后端功能实现,编写相关文档 |
| 魏儀阳、谢李东 | 后端开发人员 | API设计与实现,数据库管理 |
| 郑嘉祺 | 前端开发员兼测试助理 | 前端页面设计,兼辅助测试的实现 |
| 郑冰智 | 测试负责人 | 负责测试计划的制订与实现,后续运行的反馈与改进,编写测试相关文档 |
| 朱胤帆 | 运维及对接员 | 负责运行维护及前后端对接 |
三、团队协作记录
1 任务初分工
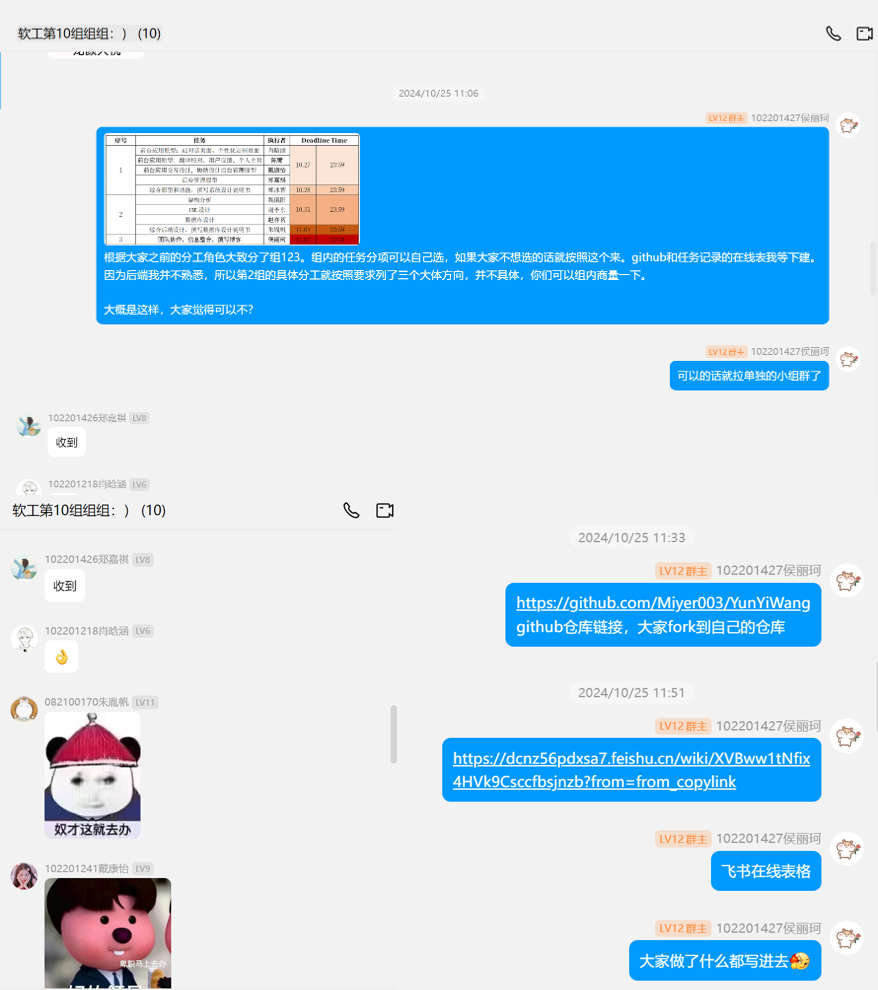
2 分任务跟进与实现
3 项目管理平台协作
- 使用摹客RP多人实时协作进行原型设计
- 使用飞书在线表格实时记录/查看任务进度
- 使用飞书在线文档协作编写架构文档
4 GitHub贡献记录
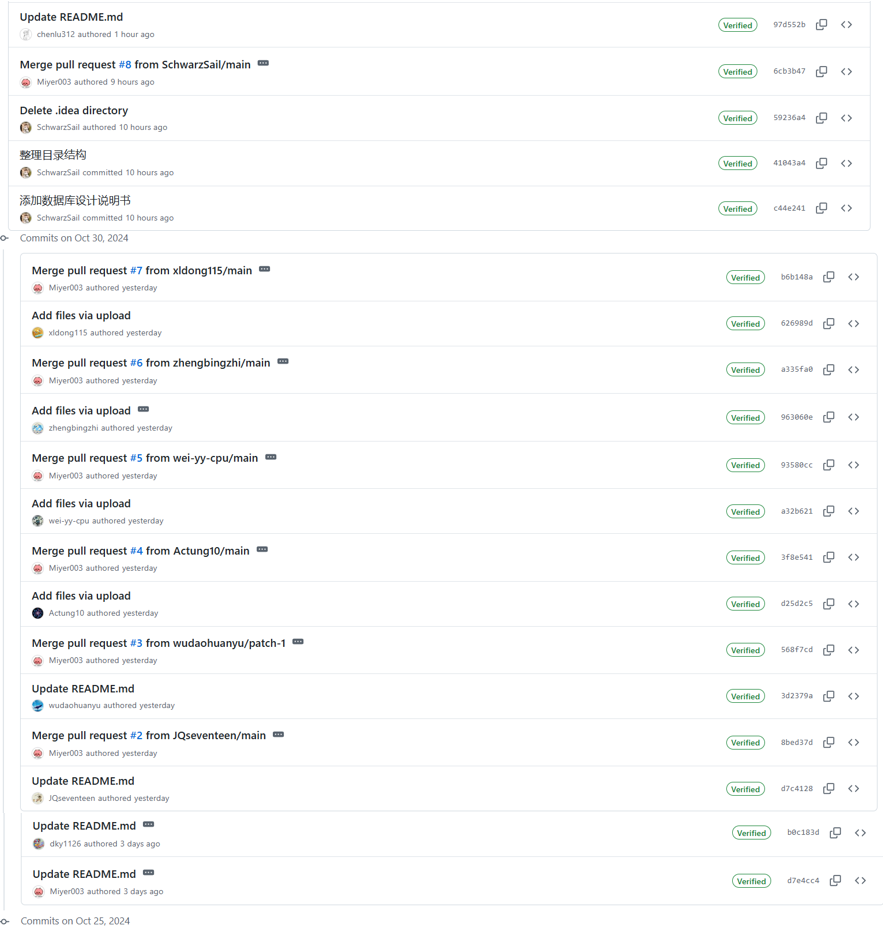
1.GitHub团队仓库链接:https://github.com/Miyer003/YunYiWang
2.当然不是草台班子_系统设计说明书:https://1drv.ms/b/c/1378ce4530586b37/EbHrFIU7jZhPp6OCbOOw9kUBXIV0YAiSge6rhV_rTsofQQ?e=YxcxxL
3.当然不是草台班子_数据库设计说明书:https://1drv.ms/b/c/1378ce4530586b37/EWMRUXszWcVKnL1paqNgcToBRwa8yX2ZVFbm4UJ-W2E2jg?e=i3DynT
4.当然不是草台班子_原型设计+概要设计答辩PPT:https://1drv.ms/b/c/1378ce4530586b37/EfzoHKIpcglPm2FSiaKxneIBTnJfEMeoX5UW5grQLLxK1A?e=91VR7Y


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY