kafka详解(5)-KAFKA重复消费和消息丢失
Kafka重复消费
重复消费
消息重复消费的根本原因都在于:已经消费了数据,但是offset没有成功提交。
其中很大一部分原因在于发生了再均衡。
1)消费者宕机、重启等。导致消息已经消费但是没有提交offset。
2)消费者使用自动提交offset,但当还没有提交的时候,有新的消费者加入或者移除,发生了rebalance(再平衡)。再次消费的时候,消费者会根据提交的偏移量来,于是重复消费了数据。
3)消息处理耗时,或者消费者拉取的消息量太多,处理耗时,超过了max.poll.interval.ms的配置时间,导致认为当前消费者已经死掉,触发再均衡。
重复消费的解决方案
由于网络问题,重复消费不可避免,因此,消费者需要实现消费幂等。方案:
- 消息表
- 数据库唯一索引
- 缓存消费过的消息id
- 手动提交office
幂等性保证消息的一致性
kafka新版本(比如2.4版本)已经在broker中保证了接收消息的幂等性,只需在生产者加上参数 props.put(“enable.idempotence”, true) 即可,默认是false不开启。
新版kafka的broker幂等性具体实现原理:
kafka每次发送消息会生成PID和Sequence Number,并将这两个属性一起发送给broker,broker会将PID和Sequence Number跟消息绑定一起存起来,下次如果生产者重发相同消息,broker会检查PID和Sequence Number,如果相同不会再接收。
PID:每个新的 Producer 在初始化的时候会被分配一个唯一的 PID,这个PID对用户完全是透明的。生产者如果重启则会生成新的PID。
Sequence Number:对于每个 PID,该 Producer 发送到每个 Partition 的数据都有对应的序列号,这些序列号是从0开始单调递增的。
ACK可靠性保证
为保证producer发送的数据,能可靠的发送到指定的topic,topic的每个partition收到producer发送的数据后,都需要向producer发送ack(acknowledgement确认收到),如果producer收到ack,就会进行下一轮的发送,否则重新发送数据。
ack应答级别
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,没必要等ISR中的follower全部接收成功。所以Kafka为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,选择以下的配置。
acks参数配置:
0:这一操作提供了一个最低的延迟,partition的leader接收到消息还没有写入磁盘就已经返回ack,当leader故障时有可能丢失数据;
1: partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,那么将会丢失数据;
-1(all): partition的leader和follower全部落盘成功后才返回ack。但是如果在follower同步完成后,broker发送ack之前,leader发生故障,那么会造成数据重复。
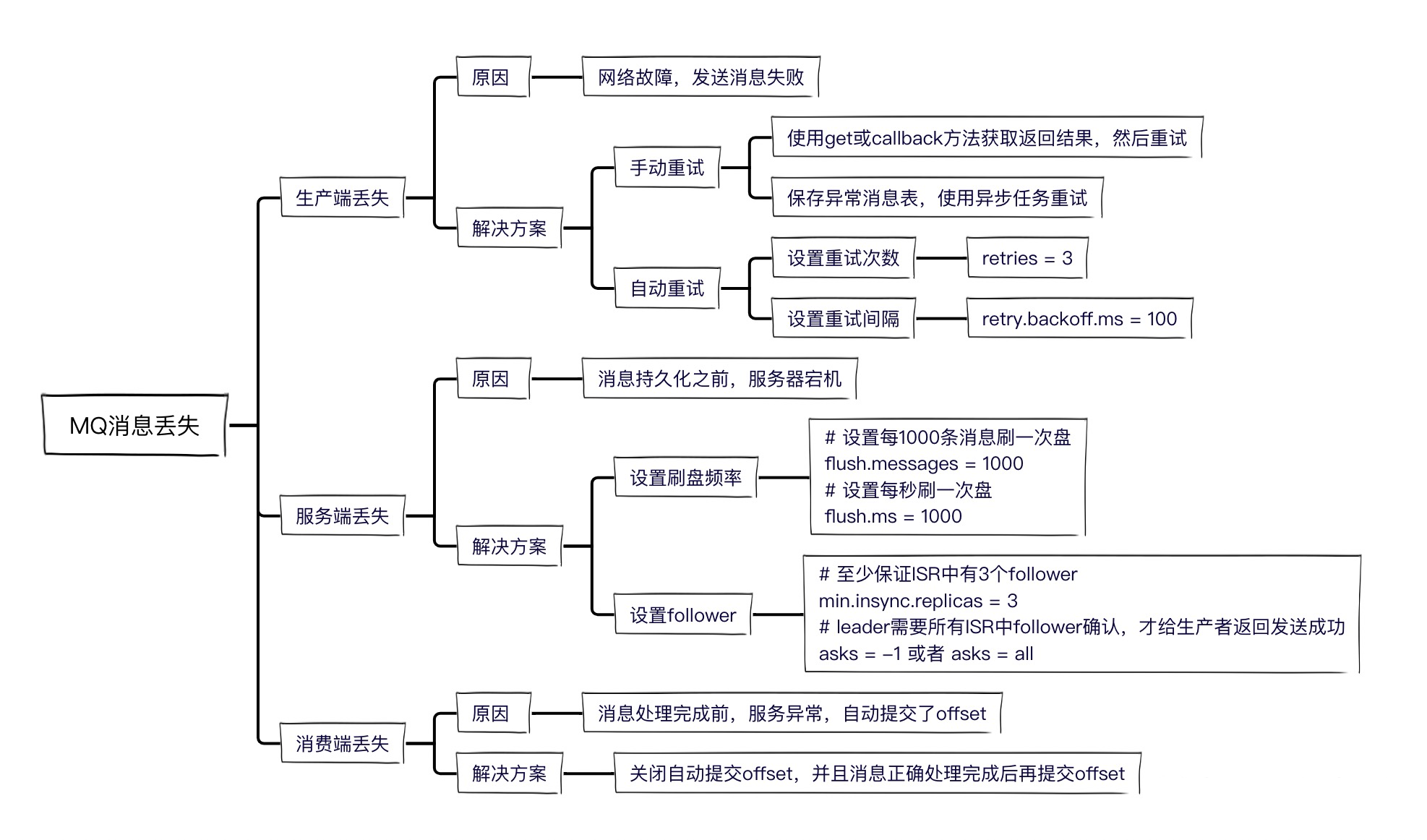
Kafka消息丢失
消息队列发送消息和消费消息的过程,共分为三段,生产过程、服务端持久化过程、消费过程,如下图所示。这三个过程都有可能弄丢消息。
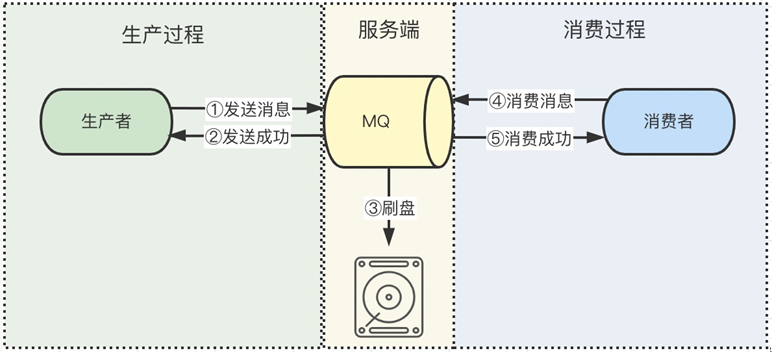
一、生产过程丢失消息
丢失原因:一般可能是网络故障,导致消息没有发送出去。
解决方案:重新发送
由于kafka为了提高性能,采用了异步发送消息。只有获取到发送结果,才能确保消息发送成功。 有两个方案可以获取发送结果。
- kafka把发送结果封装在Future对象中,可以使用Future的get方法同步阻塞获取结果。
- 使用kafka的callback函数获取返回结果。
如果发送失败了,有两种重试方案:
- 手动重试 在catch逻辑或else逻辑中,再调用一次send方法。如果还不成功,可以在数据库中建一张异常消息表,把失败消息存入表中,然后搞个异步任务重试,便于控制重试次数和间隔时间。
- 自动重试 kafka支持自动重试,当集群Leader选举中或者Follower数量不足等原因返回失败时,就可以自动重试。
一般不会用kafka自动重试,因为超过重试次数,还是会返回失败,还需要手动重试。
、服务端持久化过程丢失消息
为了保证性能,kafka采用的是异步刷盘,当发送消息成功后,Broker节点在刷盘之前宕机了,就会导致消息丢失。当然也可以设置刷盘频率减少数据丢失的概率。
kafka集群的架构模型(了解):
kafka集群由多个broker组成,一个broker就是一个节点(机器)。 一个topic有多个partition(分区),每个partition分布在不同的broker上面,可以充分利用分布式机器性能,扩容时只需要加机器、加partition就行了。
一个partition又有多个replica(副本),有一个leader replica(主副本)和多个follower replica(从副本),这样设计是为了保证数据的安全性。
发送消息和消费消息都在leader上面,follower负责定时从leader上面拉取消息,只有follower从leader上面把这条消息拉取回来,才算生产者发送消息成功。
kafka为了加快持久化消息的性能,把性能较好的follower组成一个ISR列表(in-sync replica),把性能较差的follower组成一个OSR列表(out-of-sync replica),ISR+OSR=AR(assigned repllicas)。 如果某个follower一段时间没有向leader拉取消息,落后leader太多,就把它移出ISR,放到OSR之中。 如果某个follower追上了leader,又会把它重新放到ISR之中。 如果leader挂掉,就会从ISR之中选一个follower做leader。
消费过程丢失消息
kafka中有个offset的概念,consumer从partition中拉取消息,consumer本地处理完成后需要commit一下offset,表示消费完成,下次就不会再拉取到这条消息。所以需要关闭自动commit offset的配置,防止consumer拉到消息后,服务宕机,导致消息丢失。
总结:
本文作者:莲藕淹,转载请注明原文链接:https://www.cnblogs.com/meanshift/p/17025786.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号