Spark详解(05-1) - SparkCore实战案例
Spark详解(05-1) - SparkCore实战案例
数据准备
本项目的数据是采集电商网站的用户行为数据,主要包含用户的4种行为:搜索、点击、下单和支付。
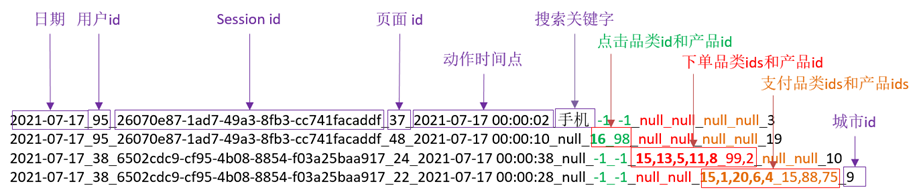
(2)每一行表示用户的一个行为,所以每一行只能是四种行为中的一种。
(4)针对下单行为,一次可以下单多个产品,所以品类id和产品id都是多个,id之间使用逗号分割。
编号 | 字段名称 | 字段类型 | 字段含义 |
1 | date | String | 用户点击行为的日期 |
2 | user_id | Long | 用户的ID |
3 | session_id | String | Session的ID |
4 | page_id | Long | 某个页面的ID |
5 | action_time | String | 动作的时间点 |
6 | search_keyword | String | 用户搜索的关键词 |
7 | click_category_id | Long | 点击某一个商品品类的ID |
8 | click_product_id | Long | 某一个商品的ID |
9 | order_category_ids | String | 一次订单中所有品类的ID集合 |
10 | order_product_ids | String | 一次订单中所有商品的ID集合 |
11 | pay_category_ids | String | 一次支付中所有品类的ID集合 |
12 | pay_product_ids | String | 一次支付中所有商品的ID集合 |
13 | city_id | Long | 城市 id |
需求1:Top10热门品类
需求说明:品类是指产品的分类,大型电商网站品类分多级,本项目中品类只有一级,不同的公司可能对热门的定义不一样。按照每个品类的点击、下单、支付的量来统计热门品类。
例如,综合排名 = 点击数*20% + 下单数*30% + 支付数*50%
本项目需求优化为:先按照点击数排名,靠前的就排名高;如果点击数相同,再比较下单数;下单数再相同,就比较支付数。
需求分析(方案一)分步计算
缺点:统计3次,需要启动3个job,每个job都有对原始数据遍历一次,效率低。
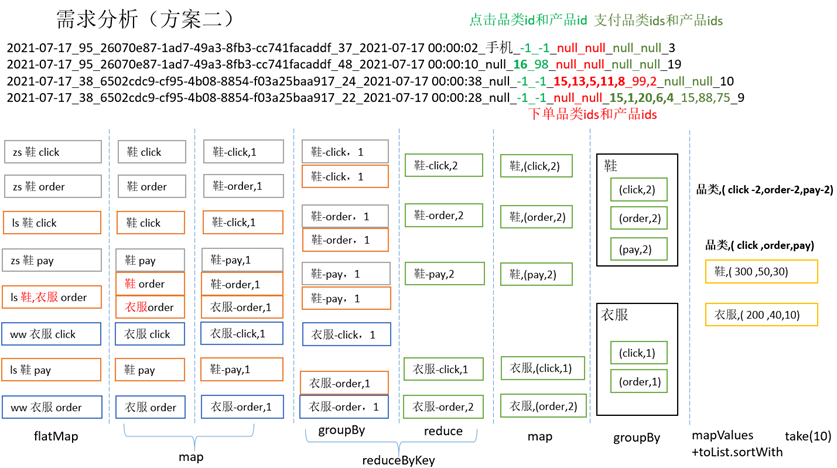
需求分析(方案二)常规算子
需求分析(方案三)样例类

需求实现(方案三)
注意:样例类的属性默认是val修饰,不能修改;需要修改属性,需要采用var修饰。
需求分析(方案四)样例类+算子优化
针对方案三中的groupBy,没有提前聚合的功能,替换成reduceByKey

需求实现(方案四)
需求分析(方案五)累加器

需求实现(方案五)
需求2:Top10热门品类中每个品类的Top10活跃Session统计
需求分析

需求实现
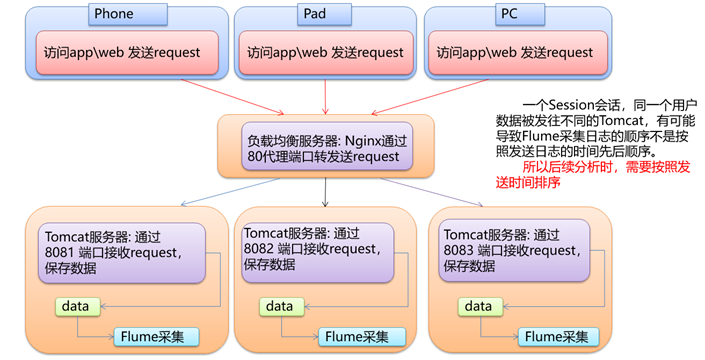
需求3:页面单跳转化率统计
需求分析

产品经理和运营总监,可以根据这个指标,去尝试分析,整个网站,产品,各个页面的表现怎么样,是不是需要去优化产品的布局;吸引用户最终可以进入最后的支付页面。
企业管理层,可以看到整个公司的网站,各个页面的之间的跳转的表现如何,可以适当调整公司的经营战略或策略。
1-2/ 1 2-3/2 3-4/3 4-5/4 5-6/5 6-7/6
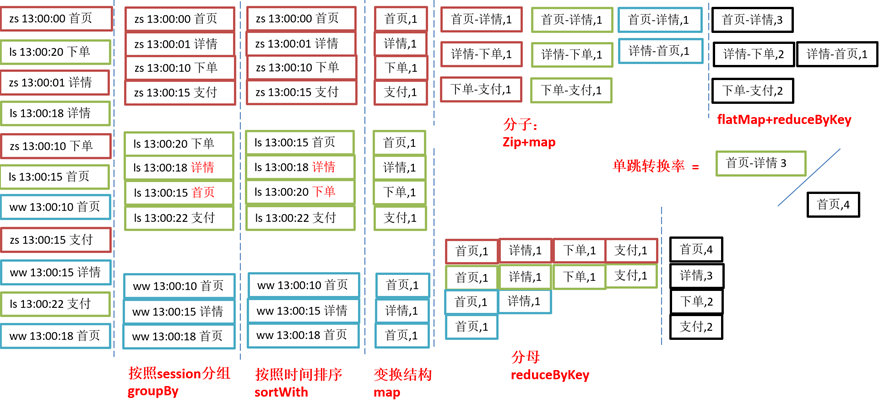


需求实现
本文作者:莲藕淹,转载请注明原文链接:https://www.cnblogs.com/meanshift/p/16063761.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号