Linux下Hadoop3.2.0集群环境的搭建
Linux下Hadoop3.2.0集群环境的搭建
张京坤
20190704
本文旨在提供最基本的,可以用于在生产环境进行Hadoop、HDFS分布式环境的搭建
一 准备工作
1.1 服务器
本案例使用Contos 7.6 64bit 在3台机器上部署集群 一台管理节点master,2台数据节点slave
1.2 Host配置
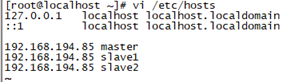
由于搭建Hadoop集群包含三台机器,所以需要修改调整各台机器的hosts文件配置,进入/etc/hosts,配置主机名和ip的映射,命令如下:
vi /etc/hosts
1.3 jdk环境安装
Hadoop是用Java开发的,Hadoop的编译及MapReduce的运行都需要使用JDK。
具体安装流程请参考jdk安装文档
本文采用jdk版本:1.8.0_191
1.4 添加HADOOP用户并分配sudoer权限
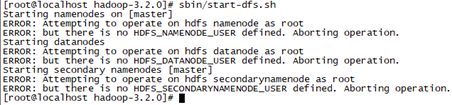
如果直接用root用户部署hadoop服务,则在启动时会报下面错误,需要修改/hadoop/sbin路径下的start-dfs.sh,stop-dfs.sh等文件,可百度搜索解决办法,所以推荐新建hadoop用户,然后用hadoop用户部署,
创建用户:useradd hadoop
给已创建的用户设置密码:passwd hadoop

分别给3台机器的hadoop用户分配sudoer权限
- root 账户键入visudo即可进入sudo配置
- 键入visudo后,在编辑器下键入 /root 寻找root,找到第三个root的那一行
root ALL=(ALL) ALL
- 按yyp键复制并在粘贴在下一行,将root替换为你所需要添加用户的账户名,
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
如果你希望之后执行sudo命令时不需要输入密码,那么可以形如
root ALL=(ALL) ALL
hadoop ALL=(ALL) NOPASSWD:ALL

- 输入:wq保存即可。
- 之后执行sudo命令时直接在命令前端键入sudo 空格即可,比如sudo shutdown -h now执行立即关机命令.
如果需要输入口令,则输入用户密码即可,而不是root密码.
- 注:如果用户不在sudoers列表中,将会得到以下提示.
Blinux is not in the sudoers file. This incident will be reported.
1.5 配置ssh免密登陆
切换到hadoop用户,下面的所有操作都用hadoop用户进行
Hadoop需要通过SSH来启动salve列表中各台主机的守护进程,因此SSH也是必须安装的,即使是安装伪分布式版本(因为Hadoop并没有区分集群式和伪分布式)。对于伪分布式,Hadoop会采用与集群相同的处理方式,即依次序启动文件conf/slaves中记载的主机上的进程,只不过伪分布式中salve为localhost(即为自身),所以对于伪分布式Hadoop,SSH一样是必须的。
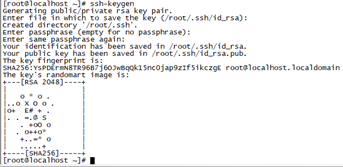
- 在管理节点上生成密文:ssh-keygen
![]()
- 将密文拷贝到所有机器,包括自己,hadoop在自动启动时,即使启动本地的服务也是通过ssh方式启动的,所以,生成的ssh密文对本机也需要配置一份
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2

- 测试ssh是否配置成功:ssh master date; ssh slave1 date; ssh slave2 date
![]()
1.6 其他
- 同步时间,所有服务器的时间要同步
- 防火墙关闭,若生产环境需要开放防火墙则需要开放相应端口,可以先关闭,安装完成在打开开放相应端口

二 Hadoop安装部署
2.1 下载
登陆apacher Hadoop官网下载:http://hadoop.apache.org/
或直接访问地址:https://www.apache.org/dist/hadoop/common/ ,可以选择相应版本下载,本文选用hadoop-3.2.0版本,
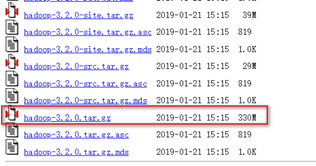
2.2 上传解压
1、将下载好的压缩包上传
2、规划安装目录,本文将安装到/home/hadoop/apps/hadoop目录下,创建目录:/home/hadoop/apps/hadoop
创建文件目录,建议所有文件和文件夹统一放到一个单独的文件夹下面,方便scp拷贝到其他节点上
创建Master的hdfs的NameNode、DataNode及临时文件目录,在后面的配置文件中会用到
mkdir /home/hadoop/apps/hadoop/name
mkdir /home/hadoop/apps/hadoop/data
mkdir //home/hadoop/apps/hadoop/tmp
- 解压:tar -zxvf hadoop-3.2.0.tar.gz -C /home/hadoop/apps/hadoop/
删除doc:
cd /home/hadoop/apps/hadoop/hadoop-3.2.0/share/
rm -rf doc/
doc目录下是说明文档,不删除后面再scp到其他服务器时会很费时
4、配置环境变量(3台机器都要配置为防止遗漏另外两台的也先配上)
vi /etc/profile

立刻让hadoop环境变量生效:source /etc/profile (这个命令不需要sudo权限)
使用hadoop命令有如下提示则表示环境变量生效,也可以使用 hadoop version查看Hadoop版本
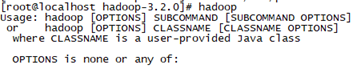
2.3 修改配置文件
进入hadoop-2.7.1的配置目录:cd /usr/local/hadoop/hadoop-3.2.0/etc/Hadoop
依次修改core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml以及workers文件
Hadoop3.0版本配置主机名的文件是slaves,3.0之后以后slaves更名为workers。
1、修改core-site.xml:
vi core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/apps/hadoop/tmp</value>
</property>
</configuration>
注意:hadoop.tmp.dir的value填写对应前面创建的目录,其他值根据实际情况填写
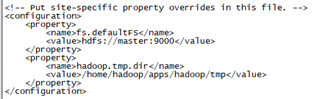
配置说明:
fs.defaultFS 配置哪个节点来启动hdfs
hadoop.tmp.dir 配置hadoop存储数据的路径,需要手动创建这个目录,上面的步骤已经说明了
2、修改hdfs-site.xml
vi hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/apps/hadoop/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/apps/hadoop/data</value>
<final>true</final>
</property>
</configuration>
注意:dfs.namenode.name.dir和dfs.datanode.data.dir的value填写对应前面创建的目录
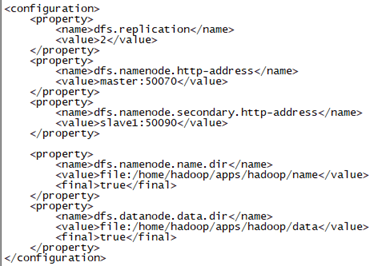
配置说明
dfs.replication 设置文件的备份数量
dfs.namenode.http-address 设置哪台虚拟机作为namenode节点
dfs.namenode.secondary.http-address 设置哪台虚拟机作为冷备份namenode节点,用于辅助namenode即ResourceManager进程,本文中使用的时slave1节点,也可以在master节点。
注意:dfs.namenode.name.dir和dfs.datanode.data.dir的value填写对应前面创建的目录
3、修改mapred-site.xml文件
vi mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

配置说明:
mapreduce.framework.name 配置yarn来进行任务调度
4、修改yarn-site.xml
vi yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/home/hadoop/apps/hadoop/hadoop-3.2.0/etc/hadoop:/home/hadoop/apps/hadoop/hadoop-3.2.0/share/hadoop/common/lib/*:/home/hadoop/apps/hadoop/hadoop-3.2.0/share/hadoop/common/*:/home/hadoop/apps/hadoop/hadoop-3.2.0/share/hadoop/hdfs:/home/hadoop/apps/hadoop/hadoop-3.2.0/share/hadoop/hdfs/lib/*:/home/hadoop/apps/hadoop/hadoop-3.2.0/share/hadoop/hdfs/*:/home/hadoop/apps/hadoop/hadoop-3.2.0/share/hadoop/mapreduce/lib/*:/home/hadoop/apps/hadoop/hadoop-3.2.0/share/hadoop/mapreduce/*:/home/hadoop/apps/hadoop/hadoop-3.2.0/share/hadoop/yarn:/home/hadoop/apps/hadoop/hadoop-3.2.0/share/hadoop/yarn/lib/*:/home/hadoop/apps/hadoop/hadoop-3.2.0/share/hadoop/yarn/*</value>
</property>
</configuration>

配置说明
yarn.resourcemanager.hostname 配置yarn启动的主机名,也就是说配置在哪台虚拟机上就在那台虚拟机上进行启动
yarn.application.classpath 配置yarn执行任务调度的类路径,如果不配置,yarn虽然可以启动,但执行不了mapreduce。执行hadoop classpath命令,将出现的类路径放在<value>标签里(注:其他机器启动是没有效果的)
5、修改workers文件
vi workers
将原来的localhost删除,该成如下内容

slave1、slave2表示dateNode的域名,有几个写几个,若master节点也作为数据节点时则也可以写上,这里仅有两个数据节点,master不作为储存节点
6、 修改hadoop-env.sh文件
vi Hadoop-env.sh
找到已经注释了"export JAVA_HOME"的代码行,按照下面写入对应的变量
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/local/jdk1.8.0_191
export HADOOP_PID_DIR=/home/hadoop/apps/hadoop/tmp/pids

配置注意项
JAVA_HOME的路径一定要填写绝对路径!
HADOOP_PID_DIR的值可以先填上去,后面再去创建,创建的时候最好放在hadoop安装目录下,而且只需要创建到tmp文件夹就行,pids会自动生成,方便拷贝到其他节点(虚拟机)上
如果使用的是root用户,则还需要再添加以下变量,本文使用的是hadoop用户,不需要添加
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
2.4 复制
1、将hadoop安装文件夹使用scp复制到slave1和slave2相同的目录中(NameNode、DataNode及临时文件目录也要一起复制)。
2、同时确认在slave1和slave2上配置hadoop的环境变量
scp -r /home/hadoop/apps/ slave1:/home/hadoop/
三 运行hadoop集群
3.1 运行hdfs
- 格式化HDFS:hdfs namenode -format
第一次启动集群时需要格式化hdfs,之后就不再需要
如果严格按照上述配置执行,那格式化namenode是不会失败的,如果失败,请到各个节点的tmp路径进行删除操作,然后重新格式化namenode,若已经储存了数据可以将各个节点下的tmp,name,data都删除重新格式化。
- 启动HDFS
进到hadoop安装目录,由于环境变量之配置了bin目录下,启动hdfs在sbin下,所以需要用绝对目录
cd /home/hadoop/apps/hadoop/hadoop-3.2.0
sbin/start-dfs.sh
![]()
jps命令查看进程是否运行
master显示:SecondaryNameNode和NameNode进程
slave显示:DataNode进程
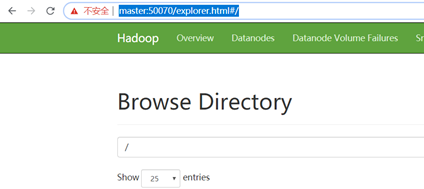
启动成功后,web控制台查看HDFS集群信息 浏览器输入http://master:50070
![]()
- 其他启动命令
单独启动nameNode:sbin/hadoop-daemon.sh start namenode
单独启动dataNode: sbin/hadoop-daemons.sh start datanode
同时启动hdfs和yarn :sbin/start-all.sh

3.2 运行yarn
- 启动命令:sbin/start-yarn.sh
yarn 也有分开的启动命令,一般使用上面的即可,如果有单个机器挂掉可以使用单个启动
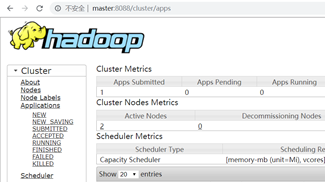
- 启动完成后浏览器输入http://master:8088查看yarn状态
![]()
3.3 测试
- 测试hdfs
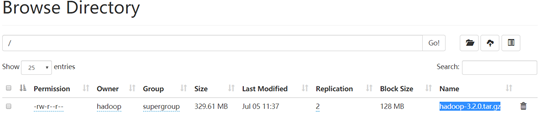
上传文件:hadoop fs -put ./ hadoop-3.2.0.tar.gz to /
![]()
- 测试yarn
Hadoop安装包里提供了例子,在Hadoop的share/hadoop/mapreduce目录下。可以直接运行测试运行。
cd share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-3.2.0.jar pi 5 10
![]()
可以在yarn的web页面看到运行状态等信息

至此,hadoop3.2搭建完成
本文作者:莲藕淹,转载请注明原文链接:https://www.cnblogs.com/meanshift/p/15585703.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号