java JVM技术
java监控工具使用
jconsole
jconsole是一种集成了上面所有命令功能的可视化工具,可以分析jvm的内存使用情况和线程等信息。
启动jconsole
通过JDK/bin目录下的"jconsole.exe"启动Jconsole后,将自动搜索出本机运行的所有虚拟机进程,不需要用户使用jps来查询了,双击其中一个进程即可开始监控。也可以"远程连接服务器,进行远程虚拟机的监控。"
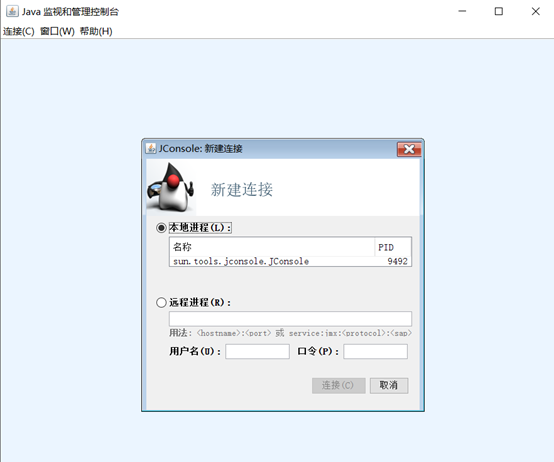
概览页面
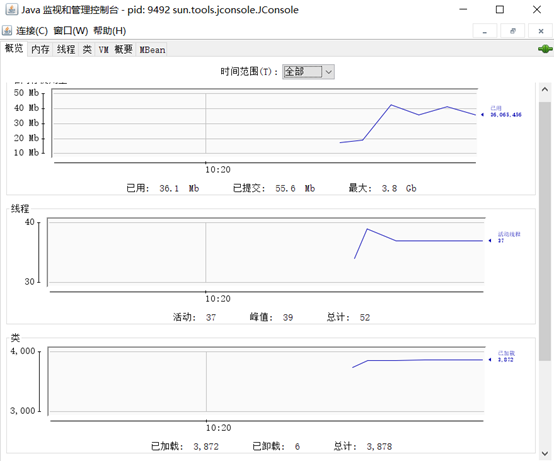
概述页面显示的是整个虚拟机主要运行数据的概览。
jvisualvm
提供了和jconsole的功能类似,提供了一大堆的插件。
插件中,Visual GC(可视化GC)还是比较好用的,可视化GC可以看到内存的具体使用情况。
java内存模型
内存模型图解
Java虚拟机在执行Java程序的过程中,会把它所管理的内存划分为若干个不同的数据区。这些区域有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进程的启动而存在,有的区域则依赖用户线程的启动和结束而建立和销毁,可以将这些区域统称为Java运行时数据区域。
如下图是一个内存模型的关系图:
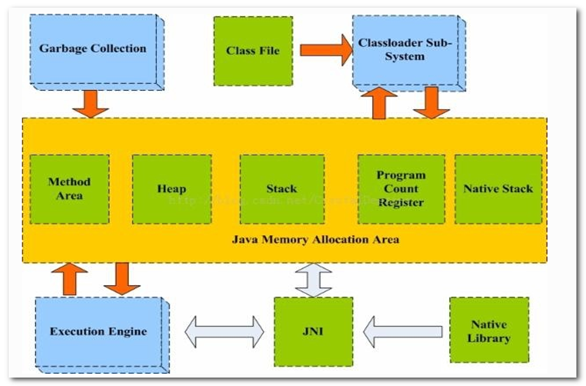
如上图所示,Java虚拟机运行时数据区域被分为五个区域:堆(Heap)、栈(Stack)、本地方法栈(Native Stack)、方法区(Method Area)、程序计数器(Program Count Register)。
堆(Heap)
对于大多数应用来说,Java Heap是Java虚拟机管理的内存的最大一块,这块区域随着虚拟机的启动而创建。在实际的运用中,我们创建的对象和数组就是存放在堆里面。如果你听说线程安全的问题,就会很明确的知道Java Heap是一块共享的区域,操作共享区域的成员就有了锁和同步。
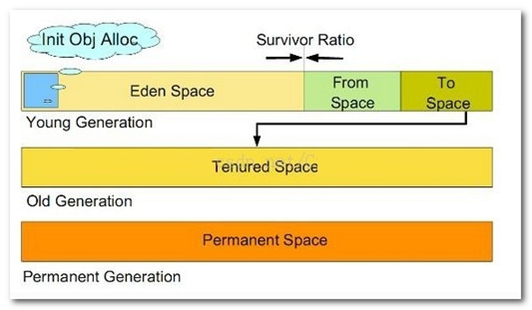
与Java Heap相关的还有Java的垃圾回收机制(GC),Java Heap是垃圾回收器管理的主要区域。程序猿所熟悉的新生代、老生代、永久代的概念就是在堆里面,现在大多数的GC基本都采用了分代收集算法。如果再细致一点,Java Heap还有Eden空间,From Survivor空间,To Survivor空间等。
Java Heap可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可。
栈(Stack)
相对于Java Heap来讲,Java Stack是线程私有的,她的生命周期与线程相同。Java Stack描述的是Java方法执行时的内存模型,每个方法执行时都会创建一个栈帧(Stack Frame)用语存储局部变量表、操作数栈、动态链接、方法出口等信息。从下图从可以看到,每个线程在执行一个方法时,都意味着有一个栈帧在当前线程对应的栈帧中入栈和出栈。
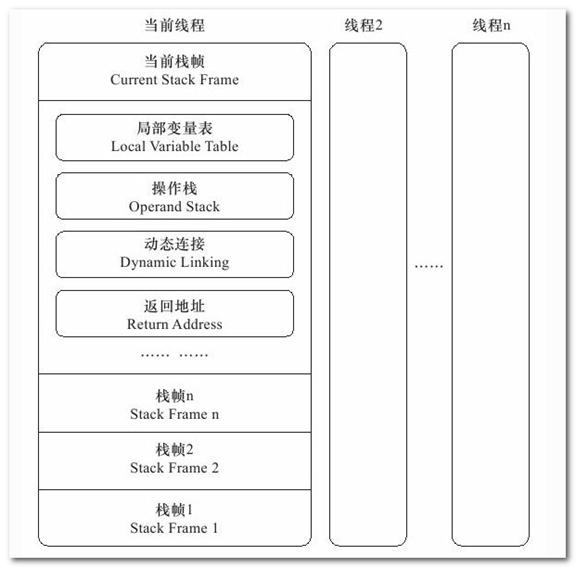
图中可以看到每一个栈帧中都有局部变量表。局部变量表存放了编译期间的各种基本数据类型,对象引用等信息。
本地方法栈(Native Stack)
本地方法栈(Native Stack)与Java虚拟机栈(Java Stack)所发挥的作用非常相似,他们之间的区别在于虚拟机栈为虚拟机栈执行java方法(也就是字节码)服务,而本地方法栈则为使用到Native方法服务。
方法区(Method Area)
方法区(Method Area)与堆(Java Heap)一样,是各个线程共享的内存区域,它用于存储虚拟机加载的类信息,常量,静态变量,即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是她却有一个别名叫做非堆(Non-Heap)。分析下Java虚拟机规范,之所以把方法区描述为堆的一个逻辑部分,应该觉得她们都是存储数据的角度出发的。一个存储对象数据(堆),一个存储静态信息(方法区)。
在上文中,我们看到堆中有新生代、老生代、永久代的描述。为什么我们将新生代、老生代、永久代三个概念一起说,那是因为HotSpot虚拟机的设计团队选择把GC分代收集扩展至方法区,或者说使用永久代来实现方法区而已。这样HotSpot的垃圾收集器就能想管理Java堆一样管理这部分内存。简单点说就是HotSpot虚拟机中内存模型的分代,其中新生代和老生代在堆中,永久代使用方法区实现。根据官方发布的路线图信息,现在也有放弃永久代并逐步采用Native Memory来实现方法区的规划,在JDK1.7的HotSpot中,已经把原本放在永久代的字符串常量池移出。
总结
- 线程私有的数据区域有:
Java虚拟机栈(Java Stack)
本地方法栈(Native Stack)
- 线程共有的数据区域有:
堆(Java Heap)
方法区
JVM参数列表
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxPermSize=16m -XX:MaxTenuringThreshold=0
-Xmx3550m:最大堆内存为3550M。
-Xms3550m:初始堆内存为3550m。
此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。
整个堆大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k:设置每个线程的堆栈大小。
JDK5.0以后每个线程堆栈大小为1M,在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在 3000~5000左右。
-XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
-XX:SurvivorRatio=4:设置年轻代中Eden区与Survivor区的大小比值。
设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6
-XX:MaxPermSize=16m:设置持久代大小为16m。
-XX:MaxTenuringThreshold=0:设置垃圾最大年龄。
如果设置为0的话,则年轻代对象不经过Survivor区,直 接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象 再年轻代的存活时间,增加在年轻代即被回收的概论。
收集器设置
-XX:+UseSerialGC:设置串行收集器
-XX:+UseParallelGC:设置并行收集器
-XX:+UseParalledlOldGC:设置并行年老代收集器
-XX:+UseConcMarkSweepGC:设置并发收集器
垃圾回收统计信息
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-Xloggc:filename
并行收集器设置
-XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。
-XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间
-XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
并发收集器设置
-XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。
-XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。
jvm案例演示
内存:
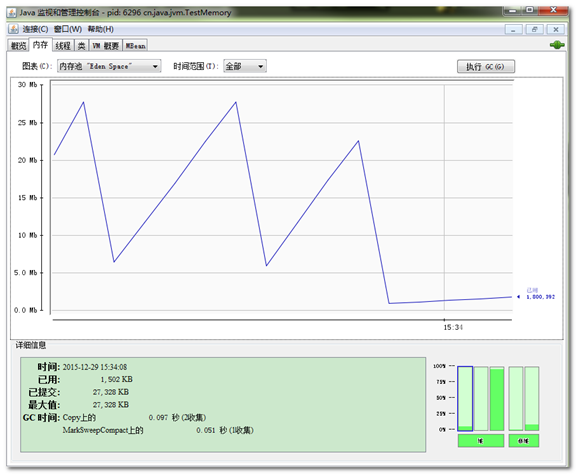
内存标签相当于可视化的jstat命令,用于监视收集器管理的虚拟机内存(java堆和永久代)的变化趋势。
我们通过下面的一段代码体验一下它的监视功能。运行时设置的虚拟机参数为:-Xms100m -Xmx100m -XX:+UseSerialGC,这段代码的作用是以64kb/50毫秒的速度往java堆内存中填充数据。
public class TestMemory { static class OOMObject { public byte[] placeholder = new byte[64 * 1024]; }
public static void fillHeap(int num) throws Exception { ArrayList<OOMObject> list = new ArrayList<OOMObject>(); for (int i = 0; i < num; i++) { Thread.sleep(50); list.add(new OOMObject()); } System.gc(); }
public static void main(String[] args) throws Exception { fillHeap(1000); Thread.sleep(500000); } } |
线程:
线程相当于可视化了jstack命令,遇到线程停顿时,可以使用这个也签进行监控分析。线程长时间停顿的主要原因有:等待外部资源(数据库连接等),死循环、锁等待。下面的代码将演示这几种情况:
package cn.java.jvm;
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader;
public class TestThread { /** * 死循环演示 * * @param args */ public static void createBusyThread() { Thread thread = new Thread(new Runnable() { @Override public void run() { System.out.println("createBusyThread"); while (true) ; } }, "testBusyThread"); thread.start(); }
/** * 线程锁等待 * * @param args */ public static void createLockThread(final Object lock) { Thread thread = new Thread(new Runnable() { @Override public void run() { System.out.println("createLockThread"); synchronized (lock) { try { lock.wait(); } catch (InterruptedException e) { e.printStackTrace(); } }
} }, "testLockThread"); thread.start(); }
public static void main(String[] args) throws Exception { BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); br.readLine(); createBusyThread(); br.readLine(); Object object = new Object(); createLockThread(object); } } |
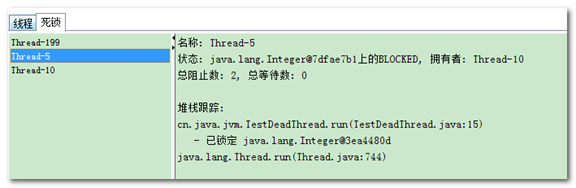
testBusyThread线程:线程阻塞在18行的while(true),直到线程切换,很耗性能
testLockThread线程:出于waitting状态,等待notify
package cn.java.jvm;
public class TestDeadThread implements Runnable { int a, b;
public TestDeadThread(int a, int b) { this.a = a; this.b = b; }
@Override public void run() { System.out.println("createDeadThread"); synchronized (Integer.valueOf(a)) { synchronized (Integer.valueOf(b)) { System.out.println(a + b); } } }
public static void main(String[] args) { for (int i = 0; i < 100; i++) { new Thread(new TestDeadThread(1, 2)).start(); new Thread(new TestDeadThread(2, 1)).start(); } } } |

本文作者:莲藕淹,转载请注明原文链接:https://www.cnblogs.com/meanshift/p/15558232.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号