

Google MapReduce 论文提到的单词计数的例子相当于这一编程实践的"hello world"l ,MapReduce 还可以解决什么问题?又有什么最佳实践和陷阱?
O’Reilly公司近些年出版了不少非常精彩的小册子,在技术类图书的内容质量和时效性上做了一个很好的平衡."MapReduce Design Patterns"就是其中一员.这本书结构相当清晰,基本上思维导图和目录是一一对应的. 书中配图相当不错,甚至只看图就可以回顾该章节的内容.对于这种手册类型的书,想查询某部分的内容按图索骥即可.这里简单记两笔:
MapReduce Design Patterns 和OOP Design Patterns 有类似的产生原因和好处:反复解决问题->发现问题共性-> 模版化描述 -> 方便交流 知识传递.书里面例子全部使用Hadoop实现,即使你不使用Hadoop也太不影响你的理解.
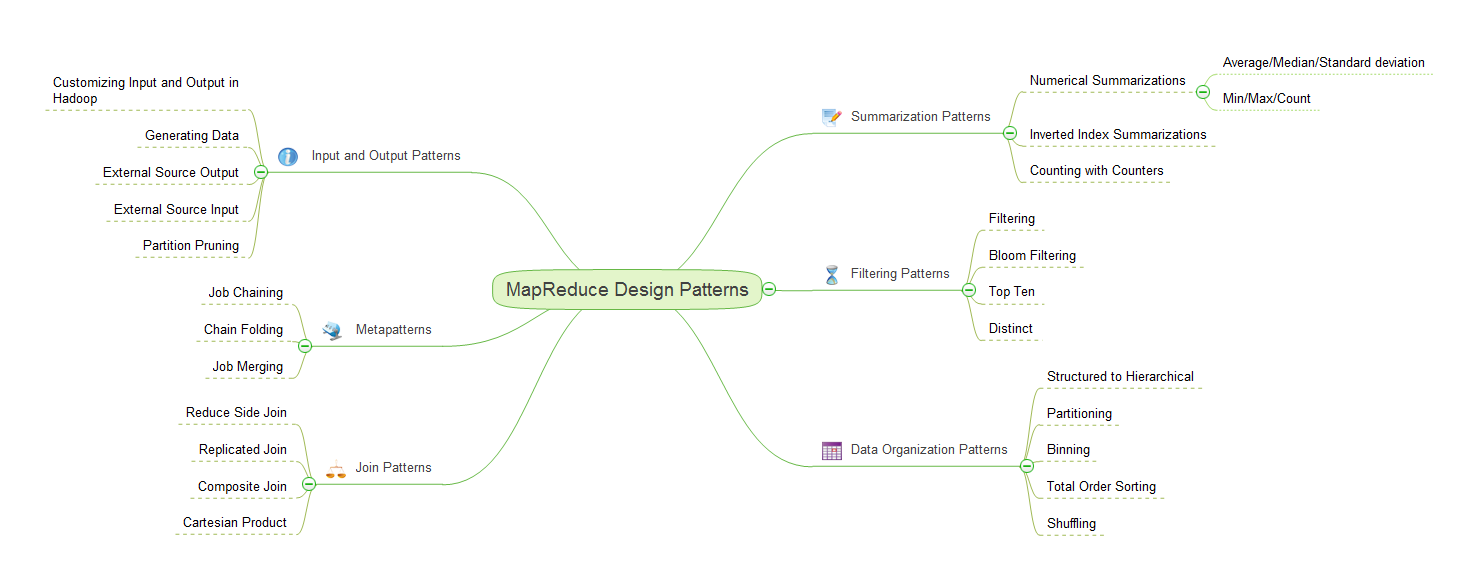
Summarization Patterns
总结归纳模式
相同Key的数据分组汇聚是MapReduce核心,所以总结归纳模式是最容易想到的,书中提到了数值归纳,倒排索引的例子.单词计数就是这类应用的典型,计算过程中高度并行化,Map阶段产出的数据行是信息完备的,后续阶段计算不需要参考其它数据行;这就保证了计算是可以并行实施:不依赖其它数据行,不依赖计算顺序.
中值,均值,标准差,最大值,最小值,倒排索引都可以如法炮制;
Filtering Patterns
过滤模式
这一类模式作用是寻找一个小数据集,这个小数据集合可能是取Top,做Distinct,做filtering 或者Bloom filtering. 直接做Filtering应该是这些模式里面最简单的,每条记录都做一下去留判断,Reduce的过程都没有.但这确有非常经典的应用案例:Distributed grep
Data Organization Patterns
数据重组模式
Structured to Hierarchical 由于只是改变的数据的视图,Combiner帮不了多少忙; 行结构数据外键关联,这样的数据结构构造成类似XML或BSON的结构.
Partitioning 移动数据,并不关心数据的顺序,书中的例子就很典型:3年的日志数据并不是日期排序,取一段时间数据,如果数据按照时间分区,就可以避免全表扫描.如果是按照月分区,该分区内数据顺序并不重要.
Binning 和 Partitioning 的区别在于它是将同一条数据分到一个或多个类别.
Total Order Sorting 整体并行排序,善用Partitioner重定结果,说起来简单实际操作过程中要注意的细节还是非常多的.
Shuffling 除了书中提到的"隐藏用户信息" "随机取样"还有什么使用场景?好奇
Join Patterns
Join模式
Reduce Side Join 将数据映射为外键为Key的形式,在Reduce阶段完成Join. 大量数据发送到Reduce Reduce端join需要大量的网络传输 .如果并不太关注执行时间 就可以用它. 如果要join的数据非常巨大,就只能选这种join.join是在reduce完成,Local优化起不了什么作用
Replicated Join 解决的是Join数据集规模不对称的情况,把小数据集分发出去,消除了Reduce阶段的Shuffle.
谷歌MapReduce论文 MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat
惯例,小图一张



分类:
回头再说-读书


 感受着技术的魅力,生活踏实 充实
感受着技术的魅力,生活踏实 充实 


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义