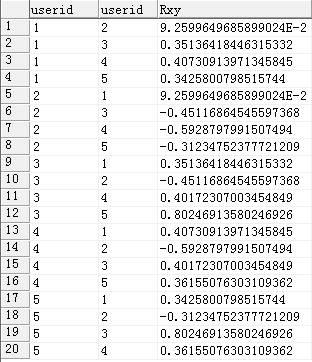
加权平均 --计算Rxy相似度之和 DECLARE@SRxyfloat; select@SRxy=Sum(Rxy) From( select m1.userid userA,m2.userid userB, (sum(m1.level*m2.level)-sum(m1.level)*sum(m2.level)/10) /sqrt((sum(power(m1.level,2))-power(sum(m1.level),2)/10)*(sum(power(m2.level,2))-power(sum(m2.level),2)/10)) Rxy From moive_level m1,moive_level m2 where m1.userid<> m2.userid and m1.userid=1and m1.moiveid=m2.moiveid groupby m1.userid,m2.userid ) Temp select@Srxy --计算一部新的电影所有他人评价值的加权平均 selectsum(t.sim)/@Srxy from ( --下面计算的是用户Zen(userid=1)与其他用户的相似度系数,我们使用的是皮尔逊相似度算法 select moive_level.*,per.Rxy,Rxy*moive_level.Level Sim From (select m1.userid userA,m2.userid userB, (sum(m1.level*m2.level)-sum(m1.level)*sum(m2.level)/10) /sqrt((sum(power(m1.level,2))-power(sum(m1.level),2)/10)*(sum(power(m2.level,2))-power(sum(m2.level),2)/10)) Rxy From moive_level m1,moive_level m2 where m1.userid<> m2.userid and m1.userid=1and m1.moiveid=m2.moiveid groupby m1.userid,m2.userid ) Per,moive_level where per.userB=moive_level.userid and moive_level.moiveid=469 )T
将上面的运算抽取成为存储过程:
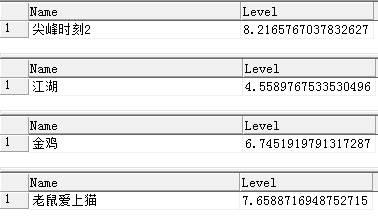
Code SET QUOTED_IDENTIFIER OFF GO SET ANSI_NULLS OFF GO ALTERPROCEDURE[dbo].[RecommendMoiveForZen] ( @midint ) AS --计算Rxy相似度之和 DECLARE@SRxyfloat; select@SRxy=Sum(Rxy) From( select m1.userid userA,m2.userid userB, (sum(m1.level*m2.level)-sum(m1.level)*sum(m2.level)/10) /sqrt((sum(power(m1.level,2))-power(sum(m1.level),2)/10)*(sum(power(m2.level,2))-power(sum(m2.level),2)/10)) Rxy From moive_level m1,moive_level m2 where m1.userid<> m2.userid and m1.userid=1and m1.moiveid=m2.moiveid groupby m1.userid,m2.userid ) Temp --select @Srxy --计算对一部新的电影,所有他人评价值的加权平均 select moive.Name,sum(t.sim)/@Srxy[Level] from ( --下面计算的是用户Zen(userid=1)与其他用户的相似度系数,我们使用的是皮尔逊相似度算法 select moive_level.moiveid,Rxy*moive_level.Level Sim From (select m1.userid userA,m2.userid userB, (sum(m1.level*m2.level)-sum(m1.level)*sum(m2.level)/10) /sqrt((sum(power(m1.level,2))-power(sum(m1.level),2)/10)*(sum(power(m2.level,2))-power(sum(m2.level),2)/10)) Rxy From moive_level m1,moive_level m2 where m1.userid<> m2.userid and m1.userid=1and m1.moiveid=m2.moiveid groupby m1.userid,m2.userid ) Per,moive_level where per.userB=moive_level.userid and moive_level.moiveid=@mid )T,moive where T.moiveid=moive.id groupby moive.name GO SET QUOTED_IDENTIFIER OFF GO SET ANSI_NULLS ON GO
SET QUOTED_IDENTIFIER OFF GO SET ANSI_NULLS OFF GO ALTERPROCEDURE[dbo].[EuclideanDistanceForMoive] @moiveidAint, @moiveidBint AS
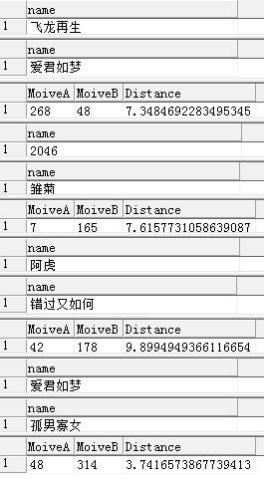
select*From moive where id=@moiveidA; select*From moive where id=@moiveidB; select@moiveidA MoiveA,@moiveidB MoiveB,sqrt(sum(result)) Distance From ( select m1.*,power(m1.level-m2.level,2) result From moive_level m1,moive_level m2 where m1.moiveid=@moiveidAand m2.moiveid=@moiveidBand m1.userid=m2.userid )T GO SET QUOTED_IDENTIFIER OFF GO SET ANSI_NULLS ON GO










 感受着技术的魅力,生活踏实 充实
感受着技术的魅力,生活踏实 充实 


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异