【转载】笔记:新手的Hive指南
转载自:https://blog.csdn.net/mrlevo520/article/details/74906302
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/MrLevo520/article/details/74906302 </div>
<div id="content_views" class="markdown_views">
<!-- flowchart 箭头图标 勿删 -->
<svg xmlns="http://www.w3.org/2000/svg" style="display: none;"><path stroke-linecap="round" d="M5,0 0,2.5 5,5z" id="raphael-marker-block" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></path></svg>
<h1 id="前言"><a name="t0"></a>前言</h1>
算是对在滴滴实习的这段时间Hive的笔记吧,回学校也有段时间了,应该整理整理了,肯定不会巨细无遗,作为一种学习记录或者入门指南吧
基础
- SQL基本语法
- Python基础语法(HiveStreaming会用到)
- Java基础语法(写UDF会用到)
- Hadoop基础(毕竟mapred过程)
什么是Hive?
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
建议阅读:
Hive的基本操作
Hive建库建表
第一步:建数据库
CREATE DATABASE IF NOT EXISTS test
COMMENT '添加对表的描述'- 1
- 2
第二步:建table表
- 首先看下数据存储以及形式
# 把本地数据put到集群
$hadoop fs -put /Users/mrlevo/Desktop/project/163music/music_data /test/music/
# 其中hdfs上的数据是这样的,它会location到该路径下的所有文件
$hadoop fs -ls /test/music/
-rw-r--r-- 1 mac supergroup 2827582 2017-07-07 15:03 /test/music/music_data
# music_data里面的文件是这样的,这里把个人信息抹掉了
$ hadoop fs -cat /test/music/music_data | more
xxx|9|让音乐串起你我|云南省|文山壮族苗族自治州|75后|新浪微博|482|2002|326|http://music.163.com/#/user/fans?id=xx
xx|8|None|云南省|曲靖市|75后|None|0|12|4|http://music.163.com/user/fans?id=xx
xx|8|百年云烟只过眼,不为繁华易素心|贵州省|贵阳市|85后|None|1|22|1|http://music.163.com/user/fans?id=xx- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 然后再直接建hive表并关联数据
# 已进入hive的环境了,我为了方便解释,就直接备注上去了
hive> create external table test.163music( //建立外表,选择的数据库是test,表是163music
> nickname string,
> stage string,
> introduce string,
> province string,
> city string,
> age string,
> social string,
> trends string,
> follow string,
> fans string,
> homepage string) //这里是列名
> ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' //这里是关联进表里面的数据的分隔符
> LOCATION '/test/music/'; //这里location 选择的是hdfs的路径,比如我把我文件放在hdfs路径是/test/music/
OK
Time taken: 0.035 seconds- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 看下数据情况
hive> select * from test.163music limit 1;
OK
xxxxx 9 让音乐串起你我 云南省 文山壮族苗族自治州 75后 新浪微博 482 2002 326http://music.163.com/#/user/fans?id=xxxx
Time taken: 0.065 seconds, Fetched: 1 row(s)- 1
- 2
- 3
- 4
- 查看下表结构
# 查看表结构. 操作表之前,都应该先操作查看表字段类型,不然进行join的时候可能会产生很大的错误
hive> desc test.163music;
OK
nickname string
stage string
introduce string
province string
city string
age string
social string
trends string
follow string
fans string
homepage string
Time taken: 0.063 seconds, Fetched: 11 row(s)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 查看表存储
# Hive的数据都是存储在HDFS上的,默认有一个根目录,在hive-site.xml中,由参数hive.metastore.warehouse.dir指定。默认值为/user/hive/warehouse.
hive> show create table test.163music;
OK
CREATE EXTERNAL TABLE `test.163music`(
`nickname` string,
`stage` string,
`introduce` string,
`province` string,
`city` string,
`age` string,
`social` string,
`trends` string,
`follow` string,
`fans` string,
`homepage` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://localhost/test/music'
TBLPROPERTIES (
'COLUMN_STATS_ACCURATE'='false',
'numFiles'='0',
'numRows'='-1',
'rawDataSize'='-1',
'totalSize'='0',
'transient_lastDdlTime'='1499411018')
Time taken: 0.119 seconds, Fetched: 27 row(s)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
注意:除了location 还有另一种方法把数据挂到hive表里面,就是put方法,建表的时候,和上面的唯一区别就是没有location
首先,查看下自己建的外部表的路径在哪
# 这里我用另一张表,test2
hive> show create table test.test2;
OK
createtab_stmt
CREATE EXTERNAL TABLE `test2`(
`name` string,
`age` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs: xxxxx/warehouse/test.db/test2'
TBLPROPERTIES (
'transient_lastDdlTime'='1481853187')
Time taken: 0.132 seconds, Fetched: 13 row(s)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
然后将自己的内容put到表中
hadoop fs -put LOCALFILE hdfs:xxxxxx/warehouse/DATABASE/TABLENAME
# LOCALFILE 需要推送的文件
# DATABASE 数据库名
# TABLENAME 表名- 1
- 2
- 3
- 4
几个关键字
语法关键字太多了,我只写了我以前做过笔记的那几个,其余的应该查一下就能用,可参考的文章:Hive高级查询(group by、 order by、 join等)
join
这应该是用到最多的语句了,多个表的联结操作
SELECT
a.id,a.dept,b.age # 选择需要连接的东西
FROM
a join b
ON
(a.id = b.id);- 1
- 2
- 3
- 4
- 5
- 6
实际集群栗子
- 首先查看下表中内容
# 这里我测试了另两张表
hive> select * from owntest;
OK
owntest.name owntest.age
shangsan 20
lisi 22
zhouwu 21
Time taken: 0.042 seconds, Fetched: 3 row(s)
hive> select * from owntest2;
OK
owntest2.workplace owntest2.name
didi shangsan
baidu lisi
wangyi zhouwu
Time taken: 0.349 seconds, Fetched: 3 row(s)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 然后开辟队列 (如果是公司的hive,肯定会设置队列的,自己部门有自己的队列,有资源分配)
hive> set mapred.job.queue.name=xxxxxxxx;- 1
- 然后实现join的操作
hive> select * from owntest join owntest2 on owntest.name=owntest2.name;- 1
回车之后会显示进度情况,之后查看表即可,这里我先建了张表来存放结果数据,名字是query_result,使用insert overwrite进行数据复写到新建表中
hive> insert overwrite table query_result
> select * from owntest join owntest2 on owntest.name=owntest2.name;
Query ID = map_da_20161216130626_40fda9ef-386f-4ef3-9e13-7b08ad69118c
Total jobs = 3
Launching Job 1 out of 3
...
OK
owntest.name owntest.age owntest2.workplace owntest2.name # 这里join出来为空值,所以只返回了列名
Time taken: 96.932 seconds- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
后续操作
也可以将结果写入hdfs上的文件中
hive> insert overwrite directory "/user/xx/xukai/result.txt"
> row format delimited fields terminated by ","
> select owntest.name,owntest.age,owntest2.workplace from owntest join owntest2 on owntest.name=owntest2.name;
###########
$ hadoop fs -cat /user/xx/xukai/result.txt/000000_0
lisi,22,baidu
shangsan,20,didi
zhouwu,21,wangyi
#值得注意的是,文件只是制定了输出的路径,如果没有文件在,那么会直接输出000000_0的文件- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
当然还有最常用的方法,更适合工程项目,使用hive -e “sql语句” > 服务器本地输出路径
$ hive -e "
set mapred.job.queue.name=root.xxxxx;
use test;
select owntest.name,owntest.age,owntest2.workplace from owntest join owntest2 on owntest.name=owntest2.name
" > /data/xx/xukai/result_hive_e4.txt
# 上面的话意思是,直接在终端输入,不用进入hive环境,将其结果输出到/data/xx/xukai/result_hive_e4.txt路径下- 1
- 2
- 3
- 4
- 5
- 6
- 7
然后可以直接下载到本地查看
如果是公司的集群,肯定是挂服务器上跑的,那如果我要线下也就是下载到自己的本机上处理,可以通过简单的python语句,即可开启传输服务
# 在本地文件夹直接输入即可
python -m SimpleHTTPServer 8042
# 在本地通过浏览器浏览http://线上服务器地址:8042- 1
- 2
- 3
- 4
- 5
其他类似操作,请看Hive join用法,这里没有存入新表的话,只是显示结果
-- 展示数据
hive> select * from zz0;
111111
222222
888888
hive> select * from zz1;
111111
333333
444444
888888
-- 内关联,只匹配有的
hive> select * from zz0 join zz1 on zz0.uid = zz1.uid;
111111 111111
888888 888888
-- 左外关联:以LEFT [OUTER] JOIN关键字前面的表作为主表,和其他表进行关联,返回记录和主表的记录数一致,关联不上的字段置为NULL。右外关联一个道理
hive> select * from zz0 left outer join zz1 on zz0.uid = zz1.uid;
111111 111111
222222 NULL
888888 888888 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
注意:Hive中Join的关联键必须在ON ()中指定,不能在Where中指定,否则就会先做笛卡尔积,再过滤。join发生在where字句前,所以,如果要限制join的输出,需要写在where字句,否则写在join字句
补充笛卡尔积:假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}。
如果出现一对多的情况,假设left join,左表中对应多个右表的值,则相应的表行会变多,而在右表中没有对应则输出为Null
一个例子,左边为table1,右边为table2

select * from table1 left outer join table2 on (table1.student_no=table2.student_no);- 1
1 name1 1 11
1 name1 1 12
1 name1 1 13
2 name2 2 11
2 name2 2 14
3 name3 3 15
3 name3 3 12
4 name4 4 13
4 name4 4 12
5 name5 5 14
5 name5 5 16
6 name6 NULL NULL- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
可以看到left outer join左边表的数据都列出来了,如果右边表没有对应的列,则写成了NULL值。
同时注意到,如果左边的主键在右边找到了N条,那么结果也是会叉乘得到N条的,比如这里主键为1的显示了右边的3条。
更多案例:
http://www.cnblogs.com/xd502djj/archive/2013/01/21/2869366.html
- http://lxw1234.com/archives/2015/06/313.htm
- http://lxw1234.com/archives/2015/06/315.htm
case when
语法: case when a then b [when c then d]* [else e] end
如果a为TRUE,则返回b;如果c为TRUE,则返回d;否则返回e,很多时候在于对数据的改写操作
hive> select case when 1=2 then 'tom' when 2=2 then 'mary' else'tim' end from lxw_dual;
mary- 1
- 2
- 3
-- 查看一下原数据
hive> select * from owntest;
OK
owntest.name owntest.age
shangsan 20
lisi 22
zhouwu 21
-- 执行when case 操作,记得end
hive> create table test_case as select name, case when age=21 then 'twenty one ' when age=22 then 'twenty two' else 'twenty' end age_case from owntest;
-- 实现效果
hive> select * from test_case;
OK
test_case.name test_case.age_case
shangsan twenty
lisi twenty two
zhouwu twenty one- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
sum
用于统计的啦,多和group by一块使用进行分组的一些统计操作
-- 原始表
hive> select * from owntest;
OK
owntest.name owntest.age
lisi 22
zhangsan 21
zhouwu 21
zhangsan 21
lisi 22
zhouwu 20
xiaoming 10
xiao 10
--经过sum操作
hive> create table test_sum as select name,sum(age) from owntest group by name;
hive> select * from test_sum;
OK
test_sum.name test_sum._c1
lisi 44.0
xiao 10.0
xiaoming 10.0
zhangsan 42.0
zhouwu 41.0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
collect_set
简单来说,类似python 的set,将一个属性中的所有值放在一个array里面然后返回去重后的结果,如果不需要去重,可以使用collect_list
hive> select * from owntest;
OK
owntest.name owntest.age
lisi 22
zhangsan 21
zhouwu 21
zhangsan 21
lisi 22
zhouwu 20
xiaoming 10
xiao 10
hive> create table test_collect as select name,collect_set(age) age_collect from owntest where age>20 group by name;
hive> select * from test_collect;
OK
test_collect.name test_collect.age_collect
lisi ["22"]
zhangsan ["21"]
zhouwu ["21"]
# 注意返回了值,应为限制了条件age>20- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
综合一点的例子
hive> select * from owntest;
OK
owntest.name owntest.age owntest.money
lisi 22 1000
zhangsan 22 1000
zhouwu 21 2999
zhangsan 21 3999
lisi 22 2828
zhouwu 20 2992
xiaoming 10 2999
xiao 10 1919
hive> create table test_sum as select name,collect_set(age) age_collect,sum(money) sum_money from owntest group by name;
hive> select * from test_sum ;
OK
test_sum.name test_sum.age_collect test_sum.sum_money
lisi [22] 3828
xiao [10] 1919
xiaoming [10] 2999
zhangsan [22,21] 4999
zhouwu [21,20] 5991- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
concat_ws
contact_ws(seperator, string s1, string s2…)
功能:制定分隔符将多个字符串连接起来
例子:常常结合 group by 与 collect_set 使用
| col1 | col2 | col3 |
|---|---|---|
| a | b | 1 |
| a | b | 2 |
| a | b | 3 |
| c | d | 4 |
| c | d | 5 |
| c | d | 6 |
变成如下
| c | d | 4,5,6 |
|---|---|---|
| a | b | 1,2,3 |
select
col1,
col2,
concat_ws(',',collect_set(col3))
from xxxtable
group by col1,col2;- 1
- 2
- 3
- 4
- 5
- 6
需要注意的是 ,col3必须是string类型的,如果不是,则需要使用cast(col3 as string)强制转化
order by & sort by & cluster by
order by后面可以有多列进行排序,默认按字典排序
order by为全局排序
- order by需要reduce操作,且只有一个reduce ,与配置无关。 数据量很大时,慎用
select * from baidu_click order by click desc;- 1
使用distribute和sort进行分组排序
select * from baidu_click distribute by product_line sort by click desc;- 1
distribute by + sort by就是该替代方案,被distribute by设定的字段为KEY,数据会被HASH分发到不同的reducer机器上,然后sort by会对同一个reducer机器上的每组数据进行局部排序。
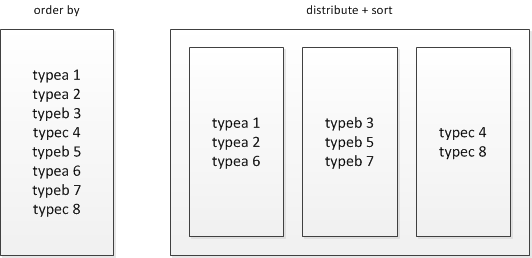
- sort by,那么在每个reducer端都会做排序,也就是说保证了局部有序,好处是:执行了局部排序之后可以为接下去的全局排序提高不少的效率
- distribute by:按照指定的字段将数据划分到不同的输出reduce中,可以保证每个Reduce处理的数据范围不重叠,每个分区内的数据是没有排序的。控制着在map端如何分区,按照什么字段进行分区,要注意均衡。参考Hive:解决Hive创建文件数过多的问题
由于每组数据是按KEY进行HASH后的存储并且组内有序,其还可以有两种用途:
1) 直接作为HBASE的输入源,导入到HBASE;
2) 在distribute+sort后再进行order by阶段,实现间接的全局排序;
- cluster by,可看做是distribute by和 sort by的组合,以下两种等价,但是,cluster by指定的列只能是升序,不能指定asc和desc
# 栗子
hive> select * from (select stage ,count(*) as count_num from test.163music group by stage)a sort by a.count_num desc;
Query ID = root_20170707154144_04b4e0fa-b63f-4fb3-a836-8c1e48e59aed
Total jobs = 2
Launching Job 1 out of 2
...
OK
6 5211
7 5137
5 3923
8 2437
4 1855
3 1402
2 710
1 686
9 566
0 451
10 36- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
row_number() over()
From hive如何去掉重复数据,显示第一条
语法:row_number() over(partition by column order by column)
row_number() over(partition by col1 order by col2) 表示根据col1分组,在分组内部根据 col2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)
实例:
步骤一:初始化数据
create table employee (empid int ,deptid int ,salary decimal(10,2))
insert into employee values(1,10,5500.00)
insert into employee values(2,10,4500.00)
insert into employee values(3,20,1900.00)
insert into employee values(4,20,4800.00)
insert into employee values(5,40,6500.00)
insert into employee values(6,40,14500.00)
insert into employee values(7,40,44500.00)
insert into employee values(8,50,6500.00)
insert into employee values(9,50,7500.00)
数据显示为
empid deptid salary
1 10 5500.00
2 10 4500.00
3 20 1900.00
4 20 4800.00
5 40 6500.00
6 40 14500.00
7 40 44500.00
8 50 6500.00
9 50 7500.00
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
需求:根据部门分组,显示每个部门的工资等级
预期结果:
empid deptid salary rank
1 10 5500.00 1
2 10 4500.00 2
4 20 4800.00 1
3 20 1900.00 2
7 40 44500.00 1
6 40 14500.00 2
5 40 6500.00 3
9 50 7500.00 1
8 50 6500.00 2 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
步骤二:实现方式
SELECT
*,
row_number() over(partition by deptid ORDER BY salary desc) rank
FROM employee
- 1
- 2
- 3
- 4
- 5
根据deptid进行分组,然后在组内对salary进行降序排序,对此序列,标记等级。
Hive 中级用法及概念
Hive分区表的使用
为什么有分区表?
如果把一年或者一个月的日志文件存放在一个表下,那么数据量会非常的大,当查询这个表中某一天的日志文件的时候,查询速度还非常的慢,这时候可以采用分区表的方式,把这个表根据时间点再划分为小表。这样划分后,查询某一个时间点的日志文件就会快很多,因为这是不需要进行全表扫描。
注意的是!!建表,新手一定要建外部表!!因为涉及到数据元的删除问题,如果瞎操作,可能你drop table的时候把数据也清空了,特别是内表删除,hdfs上的数据也会没的!切记!什么是hive的内部表和外部表?
建立分区表
CREATE EXTERNAL TABLE IF NOT EXISTS `test.zzzztp` (
`business_id` bigint,
`order_id` bigint,)
PARTITIONED BY (
year string
,month string
,day string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LOCATION
'hdfs://mycluster-tj/xxxx/newesid/';
# 最后制定的location是会新建立一个文件夹,里面会存放这个表所指向的数据,分区就在这个文件夹下开始进行
# 注意如果使用hive streaming来解决问题的时候,那种'`'不要出现在字符串中- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
插入新分区和数据
注意:创建分区后,里面是没有分区的,需要插入分区的操作,而插入分区的操作需要根据hdfs上的目录进行对应的改变,不然插入的分区无法获取数据
alter table test.zzzztp add if not exists partition (year='2016', month='08', day='31')
location 'hdfs://mycluster-tj/xxxx/newesid/20160831';- 1
- 2
注意:使用python自动化脚本插入方法会更快,注意写好逻辑
例子:hive表运行结果插入结果表的对应分区
#insert data into middle table
set mapred.job.queue.name=xxxxxx;
USE xxx_table;
ALTER TABLE tablexxx ADD IF NOT EXISTS PARTITION (YEAR = '2016',MONTH = '10',DAY = '15') LOCATION '/user/xxxx/2016/10/15';
insert overwrite table tablexxx partition(YEAR = '2016',MONTH = '10',DAY = '15')
# 新添加新分区,然后插入数据到相应的分区
select distinct
a.business_id,
a.order_id,
a.origin_id,
b.category as category1 ,
a.destination_id,
c.category as category2
from
(select * from test.zzzztp where concat(year,month,day)='20161015') a
join poi_data_base.poi_category b
on a.origin_id = b.poi_id
join poi_data_base.poi_category c
on a.destination_id = c.poi_id ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
Hive桶的使用
本段引自:大数据时代的技术hive:hive的数据类型和数据模型
partition是目录级别的拆分数据,bucket则是对数据源数据文件本身来拆分数据。使用桶的表会将源数据文件按一定规律拆分成多个文件,要使用bucket,我们首先要打开hive对桶的控制,命令如下:
set hive.enforce.bucketing = true
- 1
- 2
下面这段文字是我引用博客园里风生水起的博文
# 示例:
# 建临时表student_tmp,并导入数据:
hive> desc student_tmp;
OK
id int
age int
name string
stat_date string
Time taken: 0.106 seconds
hive> select * from student_tmp;
OK
1 20 zxm 20120801
2 21 ljz 20120801
3 19 cds 20120801
4 18 mac 20120801
5 22 android 20120801
6 23 symbian 20120801
7 25 wp 20120801
Time taken: 0.123 seconds
# 建student表:
hive>create table student(id INT, age INT, name STRING)
>partitioned by(stat_date STRING)
>clustered by(id) sorted by(age) into 2 bucket
>row format delimited fields terminated by ',';
# 设置环境变量:
>set hive.enforce.bucketing = true;
# 插入数据:
>from student_tmp
>insert overwrite table student partition(stat_date="20120802")
>select id,age,name where stat_date="20120801" sort by age;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
查看文件目录
$ hadoop fs -ls /user/hive/warehouse/studentstat_date=20120802/
Found 2 items
-rw-r--r-- 1 work supergroup 31 2012-07-31 19:52 /user/hive/warehouse/student/stat_date=20120802/000000_0
-rw-r--r-- 1 work supergroup 39 2012-07-31 19:52 /user/hive/warehouse/student/stat_date=20120802/000001_0- 1
- 2
- 3
- 4
物理上,每个桶就是表(或分区)目录里的一个文件,桶文件是按指定字段值进行hash,然后除以桶的个数例如上面例子2,最后去结果余数,因为整数的hash值就是整数本身,上面例子里,字段hash后的值还是字段本身,所以2的余数只有两个0和1,所以我们看到产生文件的后缀是0_0和1_0,文件里存储对应计算出来的元数据。
Hive的桶,我个人认为没有特别的场景或者是特别的查询,我们可以没有必要使用,也就是不用开启hive的桶的配置。因为桶运用的场景有限,一个是做map连接的运算,我在后面的文章里会讲到,一个就是取样操作了,下面还是引用风生水起博文里的例子:
查看sampling数据:
hive> select * from student tablesample(bucket 1 out of 2 on id);
Total MapReduce jobs = 1
Launching Job 1 out of 1
.......
OK
4 18 mac 20120802
2 21 ljz 20120802
6 23 symbian 20120802
Time taken: 20.608 seconds
# tablesample是抽样语句,语法:TABLESAMPLE(BUCKET x OUT OF y)
y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。例如,table总共分了64份,当y=32时,抽取 (64/32=)2个bucket的数据,当y=128时,抽取(64/128=)1/2个bucket的数据。x表示从哪个bucket开始抽取。例 如,table总bucket数为32,tablesample(bucket 3 out of 16),表示总共抽取(32/16=)2个bucket的数据,分别为第3个bucket和第(3+16=)19个bucket的数据。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
Hive 数据倾斜的问题
倾斜的原因
可参考:hive大数据倾斜总结
使map的输出数据更均匀的分布到reduce中去,是我们的最终目标。由于Hash算法的局限性,按key Hash会或多或少的造成数据倾斜。大量经验表明数据倾斜的原因是人为的建表疏忽或业务逻辑可以规避的。
解决方案
驱动表:使用大表做驱动表,以防止内存溢出;Join最右边的表是驱动表;Mapjoin无视join顺序,用大表做驱动表;StreamTable。也就是大表放join右边,小表放左边
- 设置自动处理倾斜队列:set hive.groupby.skewindata = true;
- 生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
- 对于group by或distinct,设置此项
- 设置顶层的聚合操作(top-levelaggregation operation),是指在group by语句之前执行的聚合操作:SET hive.map.aggr=true
- Map 端部分聚合,相当于Combiner
Hive UDF
当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。至于如何写UDF,我没试过,直接用的公司库里面写好的,你可以参考Hive内置运算函数,自定义函数(UDF)和Transform
1.add jar hdfs:/xxxx/aaa.jar; -- 添加已上传到hdfs上的jar包
2.create temporary function aaa as 'xxxx'; --创建临时函数与开发好的java class关联
3.select aaa(oid) oid from database.table -- 就像函数一样使用就可以了- 1
- 2
- 3
Hive Streaming
Hive提供了另一种数据处理方式——Streaming,这样就可以不需要编写Java代码了,其实Streaming处理方式可以支持很多语言。但是,Streaming的执行效率通常比对应编写的UDF或改写InputFormat对象的方式要低。管道中序列化然后反序列化数据通常时低效的。而且以通常的方式很难调试整个程序。
简单说就是,使用脚本来处理数据
Hive中提供了多种语法来使用Streaming
- map()
- reduce()
- transform()
但是,注意map()实际上并非在Mapper阶段执行Streaming,正如reduce()实际上并非在reducer阶段执行Streaming。因此,相同的功能,通常建议使用transform()语句,这样可以避免产生疑惑。
Hive Streaming实际操作
hive streamming 方式 将python程序分发到每个reducer,对每个reducer中的数据应用该程序。
使用自带的cat,来试试,USING什么脚本都可以
hive> select transform(owntest.name,owntest.age)
> using '/bin/cat' as name,age
> from owntest;- 1
- 2
- 3
Total MapReduce CPU Time Spent: 1 seconds 980 msec
OK
name age
shangsan 20
lisi 22
zhouwu 21
Time taken: 22.042 seconds, Fetched: 3 row(s)- 1
- 2
- 3
- 4
- 5
- 6
- 7
使用Python脚本进行的Streaming操作
很好的文章值得实验:hive组合python: Transform的使用
select transform(salary)
using 'python /root/experiment/hive/sum.py' as total // 调用外部python程序
from employee; - 1
- 2
- 3
使用using来加载需要执行的python脚本
#python脚本书写
import sys
for lines in sys.stdin: # 当做streaming流输入
newline=lines.split(',')[0]
newlinestr="\t".join(newline)
print >> sys.stdout, newlinestr # streaming流输出- 1
- 2
- 3
- 4
- 5
- 6
注意!加载的python注释里面也不能出现中文字符!除非添加# -*- coding:utf-8 -*-,py脚本的存储位置,最好写绝对路径
# 栗子,将数据流以hive streaming的方式传递进去,解析的时候按照文本流的方式进行解析,善用python字符处理
hive -e "
set mapred.job.queue.name=xxxxxx; # 设置队列
add file findnavitype.py; # 将程序加载到分布式缓存中
drop table xx.xxxx;
create table xx.xxxx as
select
TRANSFORM(h.order_id,h.navitype_list,h.city_list)
USING 'python findnavitype.py'
as (order_id,navitype,cityname)
from
table h
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
hive streaming实际使用中的一些技巧
- 因为加载python文件然后输出流实际上遵循的select xx from xxtabl的原则,而xx就是经过python处理得到,所以复杂的运算直接抛给python即可,然后输出的字段只要看as(这里)就可以了。
- 不要往python里面抛无用的字段,如果计算量x 小还不影响,但是对于计算量非常大,影响效果很大,特别是字段是字符串形式的。
- 加载python文件,若使用hive -e “sql”来使用,则需要在python文件存在的路径下使用
执行Hive方式
在终端执行Hive
-- 直接使用hive -e "sql " 方法
hive -e "
set mapred.job.queue.name = xxxxxxx;
use test;
select
a.name,
a.age,
b.workplace
from owntest a
join owntest2 b
on a.name = b.name and a.age > 20
-- where a.age > 20
-- can use where but only behand the join
" > /data/xxxx/xukai/result_hive_e6.txt- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
注意点
- 两种方式来挑选数据,where或者在join中直接过滤
- 在hive -e中的sql语句注释只能为
--,其余的如#和//不能用
Python自动化实现Hive相关脚本
最核心的还是可以在终端实现hive -e “sql” 语句,直接再封装上一层python,然后python file.py 即可。然后调用保存为.q的写好的hive操作语句,可以使用替换符来实现更多的自定义操作,使用raw_input来获取输入数据,捕捉后再当做变量。
# python脚本
import os
if __name__ == '__main__':
day = raw_input("please enter the day you want to join(like 20161014)")
m_table = raw_input("please enter the hive table store datasource(like database.table):")
result_table = raw_input("please enter the hive table store result(like database.table):")
ql_createtable = open("createtables.q","r").read()
ql_join = open("jointables.q","r").read()
ql_createtable_target = ql_createtable.replace("{DAY}",day).replace("{DATABASE_TABLENAME}",m_table)
ql_join_target = ql_join.replace("{source_table}",m_table).replace("{result_table}",result_table)
os.system('hive -e "%s"'% ql_createtable_target)
os.system('hive -e "%s"'% ql_join_target)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
More
- 注意括号的中文和英文方式是不同的!!!!看起来却是一样的!!!,表别名的时候建议贴边
)table1,这样写就容易观察是不是中文括号导致的问题。 count(*)所有值不全为NULL时,加1操作,count(1)不管有没有值,只要有这条记录,值就+1,count(col)中col列里面的值为NULL,值不会+1,这个列里面的值不为NULL,才+1,union与union all前者会把两个记录集中相同的记录合并,而后者不会,性能上前者优
更新
- 2017.07.09 更新,整理的片段信息
- 2017.07.26 更新,增加桶的片段
- 2017.08.04 更新,增加UDF操作
- 2018.04.22 更新,优化结构补充内容,review学习
致谢
@上述所有超链接


 浙公网安备 33010602011771号
浙公网安备 33010602011771号