python GIL解释器锁
一,介绍
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.
定义:在Cpython中,全局解释器锁(或GIL)是一个可以阻止多个对象的互斥对象,原生线程同时执行Python字节代码,这个锁主要是必要的因为Cpython的
内存管理不是线程安全的,(然而,由于吉尔存在,其他特征已经发展到依赖于它所赋予的保证)
结论:在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势
**GIl不是python的特性, 它是在实现python解释器(Cpython)时所引入 的 一个概念 。python完全可以不依赖GIl
二,GIL介绍
GIL本质就是一把互斥锁,所有互斥锁的本质都一样, 都是将并发运行变成串行 ,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
***保护不同的数据的安全,就应该加不同的锁。
***每次执行python程序,都会产生一个独立的进程, 如:python test.py,python aaa.py,python bbb.py会产生3个不同的python进程


''' #验证python text.py只会产生一个进程 #test.py内容 import os,time print(os.getpid()) tiem.sleep(1000) ''' python3 test.py #在windows下 tasklist |findstr python #在linux下 ps aux |grep python
在一个python进程内,不仅有test.pyde 主线程或者由该主线程开启的其他线程,还有解释器开启的垃圾回收等解释器级别的线程,总之,所有线程都运行在这一个进程内。
#1,所有的数据都是共享的,这其中,代码作为一种数据也是被所有线程共享的(test.py的所有代码以及Cpython解释器的所有代码) # 例如:test.py定义一个函数work(代码内容如下图),在进程内所有线程都能访问到work的代码,于是我们可以开启三个线程然后 # target都指向该代码,能访问到意味这就是可以执行 # 2,所有线程的任务,都需要将任务的代码当做参数传给解释器去执行,即所有的线程要想运行自己的任务,首先需要解决的是 # 能够访问到解释器的代码
综上:
如果多个线程的target=work,那么执行流程是
多个线程先访问到解释器的代码,即拿到执行权限,然后将target的代码交给解释器的代码去执行
解释器的代码是所有线程共享的,所以垃圾回收线程也可能访问到解释器的代码而去执行,这就导致了一个问题:对于同一个数据100,可能线程1执行x=100的同时,而垃圾回收执行的是回收100的操作,解决这种问题没有什么高明的方法,就是加锁处理,如下图的GIL,保证python解释器同一时间只能执行一个任务的代码
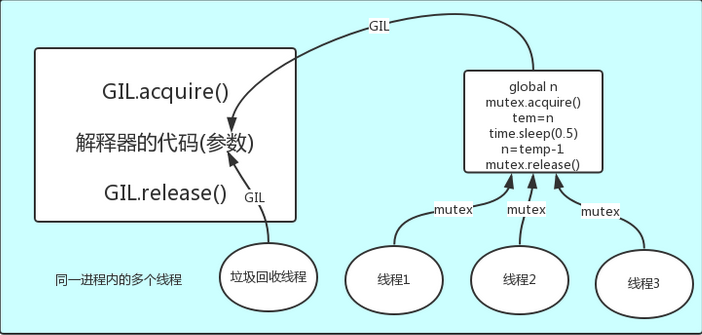
三,GIL与Lock
GIL保护的是解释器级的数据,保护用户自己的数据则需要自己加锁处理,如图
四,GIL与多线程
有了GIL的存在,同一时刻统一进程中只有一个线程被执行
1,cpu到底是用来做计算还是做I/o的
2,多cpu,意味着可以有多个核并行完成计算,所以多核提升的是计算性能
3,每一个cpu一旦遇到I/o阻塞,任然需要等待,所以多核对I/o操作没什么用处
结论:对于计算机来说,cpu越多越好 ,但对于I/o来说,再多的cpu也没用,对于运行程序来说,随着cpu的增多,执行效率就会提高,因为一个程序基本上不会是纯计算或者纯I/O,所以只能相随的看一个程序到底是计算密集型还是I/o密集型,
分析:
有四个人物需要处理,处理方式肯定要并发实现:
一,开启四个进程
二,一个进程下,开启四个线程
#单核情况下,分析结果:
如果四个任务是计算密集型,没有多核来并行计算,方案一徒增了创建进程的开销,方案二胜
如果四个任务是I/o密集型,方案一创建进程的开销大,并且进程的切换速度远不如线程,方案二胜
#多核情况下,分析结果:
如果四个任务是计算密集型,多核意味着并行计算,在python中一个进程中通一时刻只有线程执行核,方案一胜
如果四个任务是I/o密集型,在多的核也解决不了I/o问题,方案二胜
结论:现在的计算机基本上都是多核,python对于计算机密集型的任务开多个线程效率并不能带来多大性能上的提升,甚至不如串行(没有大量切换),但是,对于Io密集型的任务效率还是有提升的
五,多线程性能测试
# 多线程性能测试 from multiprocessing import Process from threading import Thread import os,time def work(): res = 1 for i in range(10000000): res*= i if __name__ == '__main__': l = [] print(os.cpu_count()) #(os.cpu_count())查看本机电脑的核数 start = time.time() for i in range(4): # p = Process(target=work) #耗时 3.479198932647705s p = Thread(target=work) #耗时: 9.911566972732544s l.append(p) p.start() for p in l: p.join() stop = time.time() print('run time is %s'%(stop-start))
from multiprocessing import Process from threading import Thread import threading import os,time def work(): time.sleep(2) print('===>') if __name__ == '__main__': l = [] print(os.cpu_count()) start = time.time() for i in range(400): p = Process(target=work) #耗时: 30.937854290008545s # p = Thread(target=work) #耗时:2.1921255588531494 l.append(p) p.start() for p in l: p.join() stop = time.time() print('run time is %s' %(stop-start))
应用:
多线程用于Io密集型,如socket,爬虫,web
多进程用于计算密集型,金融分析

 浙公网安备 33010602011771号
浙公网安备 33010602011771号