python并发编程之线程
一,什么是线程
如把进程比作一个运行的生产车间,那么线程就是这个车间的一条流水线。进程只是用来把资源集中到一起(进程只是一个资源单位或资源吧集合),而线程才是CPU上的执行单位
1,多线程(即多个控制线程)的概念,在一个进程中存在多个控制线程,多个控制线程共享该进程的地址空间,相当于一个车间内有多条流水线,都共用一个车间的资源。
2,进程与线程之间的关系
创建进程的开销远大于线程 进程之间是竞争关系,线程之间是协作关系
二,线程与进程之间的区别
1,线程共享创建它的进程的地址空间;进程有自己的地址空间。
2,线程可以直接访问其进程的数据段;进程有自己的父进程数据段的副本。
3, 线程可以与进程的其他线程直接通信;进程必须使用进程间通信来与同级进程通信
4,新线程很容易创建;新进程需要父进程的重复。
5,线程可以对同一进程的线程进行相当大的控制;进程只能对子进程执行控制。
6,主线程(取消、优先级变更等)的anges可能会影响进程中其他线程的行为;对父进程的更改不会影响子进程。
三,多线程的应用
1,多线程共享一个进程的地址空间
2,线程比进程更容易创建与撤销,线程比进程更轻量级
3,存在大量的计算机和大量的I/O处理,在重叠的情况下程序执行速度加快
4,在CPU系统中,为了最大限度的利用多核,可开启多个线程,比开进程开销要小得多
四,多线程的应用
threading模块------完全模仿了threading模块的接口
五,开启线程的两种方式
#方法一 from threading import Thread #在threading包下导入Thread(线程)模块 import time #在导入时间模块 def sayhi(name): #定义函数sayhi并传参 time.sleep(2) #设置停顿时间为2秒 print('%s say hello' %name) #打印传入的参数 if __name__ == '__main__': #判断是否为主函数,是main,否name文件 t=Thread(target=sayhi,args=('egon',)) #生成一个线程 t.start() #开始生成 print('主线程') #打印主线程
#方法二 from threading import Thread import time class Sayhi(Thread): #创建Sayhi类 继承线程 #动态属性 def __init__(self,name): super().__init__() self.name=name def run(self): #定义run函数 time.sleep(2) #停顿两秒 print('%s say hello' %self.name) if __name__ == '__main__': t=Sayhi('egon') #实例化Sayhi类 t.start() print('主线程')
六,守护线程与守护进程
----相同点:两者都是守护***会等待主***完毕后被销毁
----不同点:1,守护线程: 主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。
2,守护进程:主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收)。
1,守护进程
from multiprocessing import Process #在multiprocessing包下导入Process(主进程)模块 import time #导入时间模块 import random #导入随机模块 class Piao(Process): #创建Piao类,继承Process #动态属性 def __init__(self,name): #init方法 self.name=name super().__init__() def run(self): #定run函数 print('%s is piaoing' %self.name) time.sleep(random.randint(1,3)) print('%s is piao end' %self.name) p=Piao('egon') p.daemon=True #一定要在p.start()前设置,设置p为守护进程,禁止p创建子进程,并且父进程代码执行结束,p即终止运行 p.start() print('主')
from multiprocessing import Process from threading import Thread import time def foo(): print(123) time.sleep(2) print('end123') def bar(): print(456) time.sleep(4) print('end456') p1=Process(target=foo) p2=Process(target=bar) p1.daemon=True p1.start() p2.start() print('main------') #打印该行则主进程代码结束,则守护进程p1应该被终止,可能会有p1任务执行打印的信息123,因为主进程打印main----时, #p1也执行了,但是随即被终止
2,守护线程
from threading import Thread import time def sayhi(name): time.sleep(2) print('%s say hello' %name) if __name__ == '__main__': t=Thread(target=sayhi,args=('egon')) t.setDaemon(True) #必须在t.start()之前设置 t.start() print('主线程') print(t.is_alive())
from threading import Thread import time def foo(): print(123) time.sleep(1) print('end123') def bar(): print(456) time.sleep(3) print('end456') t1=Thread(target=foo) t2=Thread(target=bar) t1.daemon=True t1.start() t2.start() print('main-----')
七,python GIL
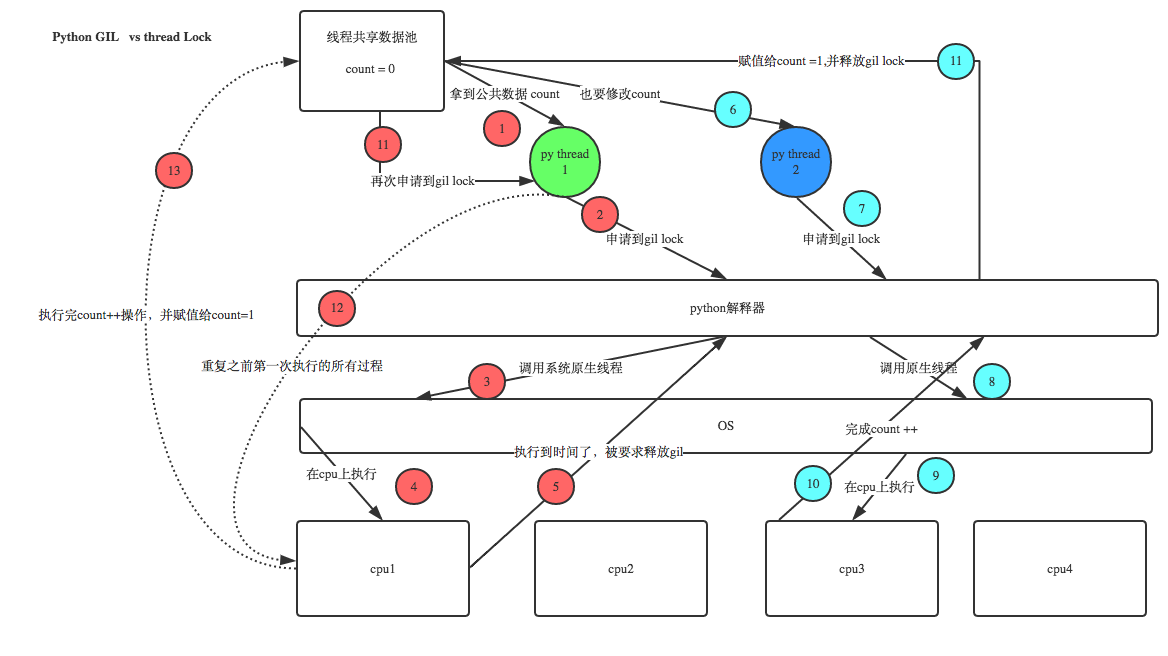
1, GIL------本质就是一把胡吃锁,互斥锁本质都一样,都是并发运行编程串行,在控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全
保护不同的数据安全就要加不同的锁
每次执行python程序,都会产生一个独立的进程 (所有的线程都行在一个进程内)
**所有数据都是共享的,代码做为一种数据也是被所有线程共享的(test.py的所有代码以及Cpython解释器的所有代码)
**所有线程的任务,都需要将任务的代码当做参数传给解释器的代码去执行,即所有的线程运行自己的任务,首先需要解决的是能访问到解释器的代码。
2,GIL与Lock
****GIL保护的是解释器的数据,保护自己的数据要自己加锁处理
3,GIL与多线程
有了GIL 的存在,同一时刻同一进程中只有一个线程被执行
对计算机来说,当然是CPU越多越好,但对于I/O来说,再多的CPU也没用
对于一个运行程序来说,CPU增多执行效率也会提高。
4,多线程性能测试
#计算机密集型开启多进程 from threading import Thread import time def work(): res=0 for i in range(10000000): res+=i if __name__ == '__main__': l=[] start=time.time() for i in range(4): p=Thread(target=work) l.append(p) p.start() for p in l: p.join() stop=time.time() print('%s' %(stop-start)) #I/o密集型要开启线程 from multiprocessing import Process from threading import Thread import time def work(): time.sleep(2) if __name__ == '__main__': l=[] start=time.time() for i in range(40): p=Process(target=work) #p=Thread(target=work) l.append(p) p.start() for p in l: p.join() stop=time.time() print('%s' %(stop-start))
5,应用:多线程用于IO密集型(socket,爬虫,web),多进程用于计算机密集型(金融分析)
八,同步锁
三个需要注意的点:
#1.线程抢的是GIL锁,GIL锁相当于执行权限,拿到执行权限后才能拿到互斥锁Lock,其他线程也可以抢到GIL,但如果发现Lock仍然没有被释放则阻塞,即便是拿到执行权限GIL也要立刻交出来
#2.join是等待所有,即整体串行,而锁只是锁住修改共享数据的部分,即部分串行,要想保证数据安全的根本原理在于让并发变成串行,join与互斥锁都可以实现,毫无疑问,互斥锁的部分串行效率要更高
#3. 一定要看本小节最后的GIL与互斥锁的经典分析
from threading import Thread,Lock
import os,time
def work():
global n
lock.acquire()
temp=n
time.sleep(0.1)
n=temp-1
lock.release()
if __name__ == '__main__':
lock=Lock()
n=100
l=[]
for i in range(100):
p=Thread(target=work)
l.append(p)
p.start()
for p in l:
p.join()
print(n) #结果肯定为0,由原来的并发执行变成串行,牺牲了执行效率保证了数据安全
# from threading import Thread,Lock #导入模块 # import time #导入模块 # n=100 #全局变量 # def work(): #定义函数 # mutex.acquire() #拿到锁,枷锁 # global n #定义全局 # temp=n #获取全局变量 # time.sleep(0.5) #停顿0.5秒 # n=temp-1 #运行 # mutex.release() #释放锁 # if __name__ == '__main__': #判断函数是否主函数,是main 否name文件名 # mutex=Lock() #互斥锁 # t_l=[] #定义空 # s=time.time() #计算开始时间 # for i in range(10): #循环遍历 # t=Thread(target=work) #开线程 # t_l.append(t) #添加 # t.start() #初始化 # for t in t_l: # # t.join() #等待 # print('%s:%s' %(time.time()-s,n))
互斥锁与join的区别
#不加锁:并发执行,速度快,数据不安全 from threading import current_thread,Thread,Lock import os,time def task(): global n print('%s is running' %current_thread().getName()) temp=n time.sleep(0.5) n=temp-1 if __name__ == '__main__': n=100 lock=Lock() threads=[] start_time=time.time() for i in range(100): t=Thread(target=task) threads.append(t) t.start() for t in threads: t.join() stop_time=time.time() print('主:%s n:%s' %(stop_time-start_time,n)) ''' Thread-1 is running Thread-2 is running ...... Thread-100 is running 主:0.5216062068939209 n:99 ''' #不加锁:未加锁部分并发执行,加锁部分串行执行,速度慢,数据安全 from threading import current_thread,Thread,Lock import os,time def task(): #未加锁的代码并发运行 time.sleep(3) print('%s start to run' %current_thread().getName()) global n #加锁的代码串行运行 lock.acquire() temp=n time.sleep(0.5) n=temp-1 lock.release() if __name__ == '__main__': n=100 lock=Lock() threads=[] start_time=time.time() for i in range(100): t=Thread(target=task) threads.append(t) t.start() for t in threads: t.join() stop_time=time.time() print('主:%s n:%s' %(stop_time-start_time,n)) ''' Thread-1 is running Thread-2 is running ...... Thread-100 is running 主:53.294203758239746 n:0 ''' #有的同学可能有疑问:既然加锁会让运行变成串行,那么我在start之后立即使用join,就不用加锁了啊,也是串行的效果啊 #没错:在start之后立刻使用jion,肯定会将100个任务的执行变成串行,毫无疑问,最终n的结果也肯定是0,是安全的,但问题是 #start后立即join:任务内的所有代码都是串行执行的,而加锁,只是加锁的部分即修改共享数据的部分是串行的 #单从保证数据安全方面,二者都可以实现,但很明显是加锁的效率更高. from threading import current_thread,Thread,Lock import os,time def task(): time.sleep(3) print('%s start to run' %current_thread().getName()) global n temp=n time.sleep(0.5) n=temp-1 if __name__ == '__main__': n=100 lock=Lock() start_time=time.time() for i in range(100): t=Thread(target=task) t.start() t.join() stop_time=time.time() print('主:%s n:%s' %(stop_time-start_time,n)) ''' Thread-1 start to run Thread-2 start to run ...... Thread-100 start to run 主:350.6937336921692 n:0 #耗时是多么的恐怖
九,死锁现象与递归锁
死锁-----指的是两个以上的进程或线程在执行过程中,因共享竞争而制造的的一种相互等待的现象,程序不能正常执行。
递归锁------在线程中多次加锁与释放锁,解决了死锁问题
from threading import Lock,Thread,RLock #导模块 import time #导入时间模块 # mutexA=Lock() # mutexB=Lock() mutexB=mutexA=RLock() #重入多个锁(链式赋值) class MyThread(Thread): #定义一个MyThread(线程)对象 #动态属性 def run(self): #定义run函数 self.f1() # self调用f1()方法 self.f2() # self调用f2()方法 def f1(self): #定义f1()方法 mutexA.acquire() #拿A锁,加锁 print('\033[32m%s 拿到A锁'%self.name) mutexB.acquire() #拿到B锁,加锁 print('\033[45m%s 拿到B锁' %self.name) mutexB.release() #释放B锁 mutexA.release() #释放A锁 def f2(self): #定义f2()方法 mutexB.acquire() #拿到锁B锁,加锁 print('\033[32m%s 拿到B锁' %self.name) time.sleep(2) #停顿2秒 mutexA.acquire() #拿到A锁,加锁 print('033[45m%s 拿到A锁' %self.name) mutexA.release() #释放锁A mutexB.release() #释放锁B if __name__ == '__main__': #判断 for i in range(10): #判断 t=MyThread() #线程 t.start() #开线程
十,信号量Semaphore
同进程一样,Semapphore管理一个内置的计数器,每当古调用acquire()时内置计数器-1;调用release()时内置计数器+1;计数器不能小于0,当计数器为0时,acquire()将阻塞线程直到其他线程调用release().
from threading import Thread,Semaphore #导模块 import threading #导入模块 import time #导入模块 def func(): if sm.acquire(): print(threading.currentThread().getName()) time.sleep(2) sm.release() # def func(): #定义函数 # sm.acquire() #加锁 # print('%s get sm' %threading.current_thread().getName()) #打印当前获得的线程 # time.sleep(3) #睡3秒 # sm.release() #释放锁 if __name__ == '__main__': #判断 sm=Semaphore(5) #定义信号量 for i in range(23): #循环二十三个量 #开线程 t=Thread(target=func) t.start()
**信号量是产生一堆线程,进程
十一,事件Event
event.isSet(): 返回event的状态
event.wait():如果event.isSet()==False将阻塞线程
event.set():设置event的状态值为True,所有阻塞池的线程激活进入就绪状态,等待操作系统调度
event.clear():恢复event的状态值为False
1,模拟过马路,车遇红灯停,绿灯跑
from threading import Thread, Event, currentThread import time e = Event() def traffic_lights(): time.sleep(5) e.set() def car(): print('\033[46m%s 等绿灯' % currentThread().getName()) e.wait() print('\033[46m%s 跑' % currentThread().getName()) if __name__ == '__main__': for i in range(10): t = Thread(target=car) t.start() traffic_thread = Thread(target=traffic_lights) traffic_thread.start()
2,模拟mysql连接服务端
from threading import Thread,Event,currentThread import time e=Event() #定义一个事件 def conn_mysql(): count=1 while not e.is_set(): if count > 3: raise ConnectionError('尝试连接的次数过多') print('\033[45m%s 第%s尝试' % (currentThread().getName(), count)) e.wait(timeout=1) count+=1 print('\033[45m%s 开始连接' %currentThread().getName()) def check_mysql(): print('\033[45m%s 检测mysql...' %currentThread().getName()) time.sleep(5) e.set() if __name__ == '__main__': for i in range(5): t = Thread(target=conn_mysql) t.start() t=Thread(target=check_mysql) t.start()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号