

基于胎心仪的胎儿心脏诊断神经网络
具体的软硬件实现点击 http://mcu-ai.com/ MCU-AI技术网页_MCU-AI
胎心率(FHR)对于评估胎儿的健康状况具 有重要意义。然而,基于传统的分类标准并不准确。 随着计算机信息技术的飞速发展,计算机技术对于胎 儿电子监护(EFM)中的胎心率分析至关重要。胎心率 分为正常、可疑和异常三类。通过与医院的合作,我 们共获取了4473条记录,其中正常记录 3012条,可疑记录1024条,异常记录437条。为了提 高胎儿状态评估的准确性,将一维FHR记录分为10 个d窗段,然后使用卷积神经网络(CNN)并行处理 数据。最后,我们采用投票的方式来确定胎心率记录 的类别。我们还做了对比实验,采用基于基础统计的 特征提取方法来提取胎心率的特征。然后将这些特征 作为输入支持向量机(SVM)和多层感知器(MLP) 进行分类。实验结果显示,SVM、MLP和CNN的分 类准确率分别为79.66%、85.98%和93.24%。
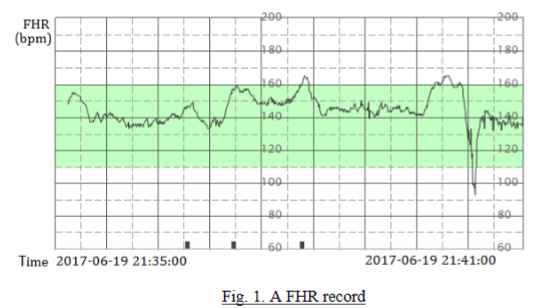
目前,胎心率是临床上应用最广泛的胎心监护方 法。医生通过一些指导标准分析胎心率记录,从 而发现胎儿窘迫的情况。胎儿状况评估可以让医 生及时了解胎儿的健康状况,以便及时发现潜在 的健康问题并做出正确的处理。胎心率已成为监测宫内胎儿健康的主要方法,对于降低分 娩发生率和死亡率也非常重要。图1为胎心率 记录。新生儿神经系统后遗症多由产程诱发因素 引起,包括胎儿缺氧、酸中毒和随后的窒息。 当胎儿缺氧时,可以采取安全有效的方法进行胎儿监测。
因此,不断完善胎儿监护方法无疑具有重要的临 床意义。传统的胎儿监护方法主要包括胎动计 数、胎心听诊计数、羊水形态观察等。这些 方法可以判断胎儿是否处于缺氧状态。由于 FHR所包含信息的复杂性,国际医学组织希望 通过合作提出指南,以避免不同国家有不同的标 准。这种方法可以帮助我们减少观察者之间 的差异。从而可以减少假阳性率和剖宫产率。
随着 人工智能的发展,在医学领域,许多与机器学习 相关的算法可以比医生更准确地识别医学图像。 因此,将机器学习算法应用在胎儿电子监护系统 中,可以帮助胎儿电子监护实现真正的精准分析 自动化。同时孕妇可以在家进行胎儿电子监护, 并及时获得结果。如果有异常数据,EFM系统 可以向孕妇发送消息并通知医生。该系统为用户 提供了极大的便利,节省了医疗资源。因 此,人工智能算法极大地促进了胎儿电子监护的 发展。通过数据分析技术和一些算法来分析胎心 率变得越来越重要。
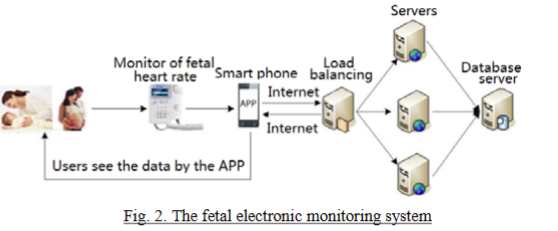
数据收集通过与医院合作,我们开发了胎儿电子监护 系统,如图2所示。该系统包括Web、Android和IOS APP。服务器程序语言为Java,数据库为MySQL。系 统硬件包括三台CentOS服务器、八核MySQL数据库, 主要系统架构如图2所示。在医院,孕妇志愿者使用多 普勒设备检测胎儿状态以及胎儿电子监护,我们收集了4473名胎儿胎儿心率记录
预处理数据处理的目的是为了获得更准确的数据进 行分析和训练。首先,由于一些孕妇的操作不准确, 我们需要删除明显错误的数据。例如,孕妇将胎心放 置在不准确的位置,导致大量数据为0。胎心率也存在 一些噪声,这些噪声会导致信号不稳定和错误,因此 需要清除这些噪声。另外,胎动、母体胎动以及 测量设备都会对胎心率数据产生影响。孕妇完成胎儿 监测后,医生会对数据进行标记。所以标签是由医生 给出的。
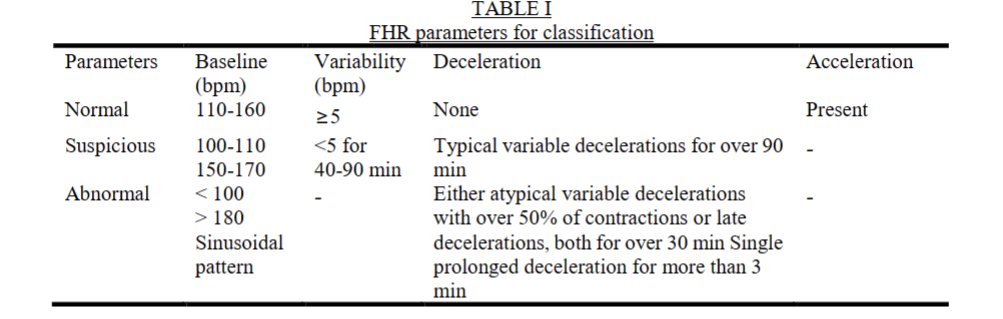
利用基本统计方法进行特征提取胎心率有二十多个 相关特征。但重要的特征是基线胎心率、加速 度、减速度、变异性和胎动。主要特征如表1所示 。我们可以使用基本的统计方法来提取这些特 征。基本统计方法的特征提取是提取数据波形的均 值、方差、极值、频带、功率谱、过零等统计数据来 表示原始序列数据作为特征向量。时间序列数据 有平均值、方差、极值、过零、边界点、带峰长度等 。频域的基本统计方法包括功率谱、功率密度 比、中频、平均功率频率等。我们 通过国家标准生产的医院胎儿监护系统提取了7个特 征,包括加速度、减速度、基线、基线变异性、周期 变异性、胎动和子宫收缩。医生主要通过这7个特征来 判断胎心率是否正常。所以这7个特征就是最终的特征 向量。
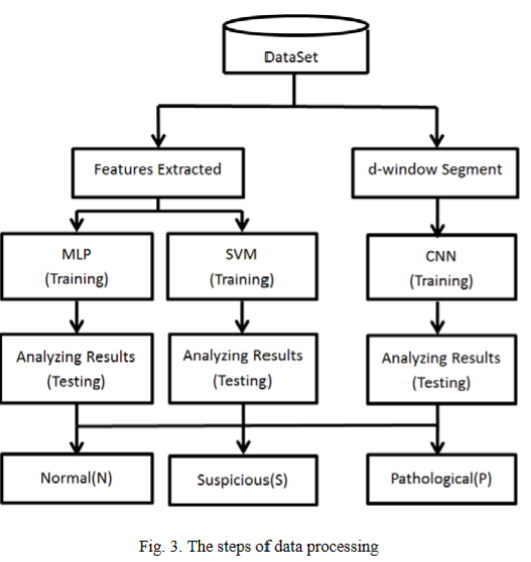
分类器本文使用了三种分类算法。第一个和第二个是 基于基本统计方法的特征提取,然后通过多层感知器 (MLP)和支持向量机(SVM)进行分类。 MLP具有 学习非线性模型的能力,并通过应用Softmax作为输出 函数支持多类分类。SVM在高维空间中有效,实现了多 类分类的方法。 SVM中的决策函数可以指定不同的核 函数。第三种是使用CNN对d窗段进行分类,然后通过 投票的方法计算分类的频率。图3所示。
神经网络的主要优点是它们可以处理复杂的非线性函 数,并且可以找到不同输入之间的依赖关系。胎心 率数据的分类标准是固定的,而医生在评估胎心率时会 考虑特征和比例的组合。因此,为了准确判断胎心 率数据的分类,需要神经网络训练相关的权重关系。在 神经网络中,可以输入任意数字,网络可以产生数字输 出。该功能也特别适合胎儿心率数据。神经网络还 可以增量训练,并且通常不需要大量空间来保存训练模 型,因为它们只需要保存一组代表突触权重的数字,并 且不需要保存训练后的原始数据,这意味着神经网络可 以用于有连续训练数据的应用中。因此,随着我们 不断获得更多的胎心率数据,我们就可以不断地进行训 练以获得更好的模型。神经网络的缺点是需要花费大量 的时间和精力来调整模型,并且优化模型需要经验 。SVC(支持向量分类)是一个非线性核,称为径向基函数(RBF)。内核生成的划分器试图将数据 集的数据点划分为沿径向分布的不同区域。实验中,将 获取的多个特征放入SVC和MLP中,分类精度计算如 下:
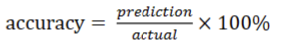
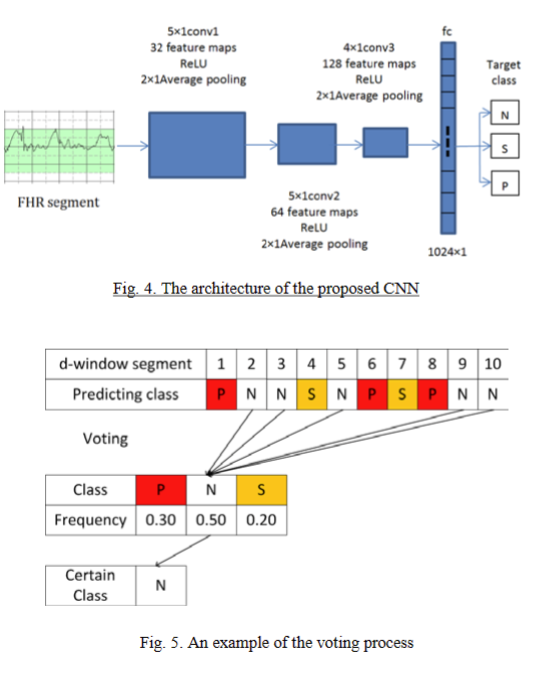
卷积神经网络是人工神经网络之一。 卷积神经网络算法已成功应用于图像识别领域。 CNN 的主要目的是基于权重共享和子采样来识别图 像。其网络结构对于平移、缩放、倾斜或其他形式的变 形具有高度不失真性。由于卷积神经网络的这些特 点,它可以很好地处理受设备或母亲心跳影响的高一维 数据。在临床实践中,医生一般会分析20分钟的胎心率 数据。心率记录为20分钟胎儿心率(共4473个数据),是一个 1×4800的一维信号,然后分为多个d窗段。最后,我们通 过投票并计算相关频率来确定胎心率数据的类别。本文尝 试了多种经典的CNN模型,然后结合胎心率数据的特点提 出了我们自己的胎心数据处理架构。通常CNN是用来处理 二维数据的。然而,我们的CNN架构设计处理一维胎 儿心率数据。该架构如图 4 所示。我们提出的架构包含三 个卷积层和一个全连接层。 ReLU 是我们模型中的激活函 数。而fc就是全连接层。本文使用85%的数据进行训练, 5%进行验证,10%进行测试。在该架构中,使用最小二乘 误差来评估模型的性能。在CNN的每次训练中,由于初始 化权重和偏差值的不同,会产生不同的结果。因此,CNN 必须反复训练才能获得稳定的精度。速率记录被分为1到16 段,以减少对记录长度的依赖。使用卷积神经网络对每 个片段进行分类,然后计算每个记录的相关标签的频率。 最后,我们选择每条记录出现频率最大的类别。我们的步 骤如图 5 所示。
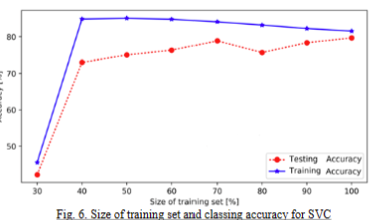
首先,我们使用SVC(支持向量分类)分类算法对胎心率数 据进行分类。在SVC中,C用于设置正则化参数。 C越 大意味着实验对松弛变量进行惩罚,期望松弛变量接近 0。换句话说,对错误分类的惩罚增加,这往往会获得 正确的分类结果。这样,训练集的准确率较高,但泛化能 力较弱。C值越小,误分类的惩罚就越小,可以容错,将其 视为噪声点,获得更好的泛化能力。实验中,经过多次调 整C值,当C值为1时,实验结果最好。实验中使用的SVC核 是径向基函数(RBF)。我们对数据进行随机划分,90% 的数据使用训练,10%的数据用于测试。实验结果如图6所 示。
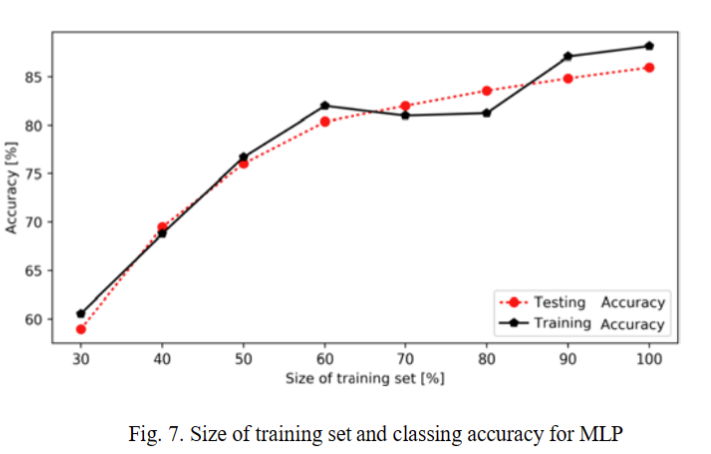
我们使用MLP算法。隐藏层从1层增加到200层,分 类精度明显提高,但训练时间和测试时间也明显增加。另 外,隐藏层超过200层,分类精度没有明显提升。考虑到训 练时间和测试时间,我们将隐藏层设置为150层,以获得更 高的效率并保证准确性。每个实验过程的重复称为"迭 代"。实验训练的迭代次数设置为200,那么提高迭代 次数对于分类的准确率并没有太大的影响。考虑到实验数据 集较大,本文采用的权重优化算法是Kingma Diederik提 出的基于随机梯度的优化器,它比拟牛顿法族中的优化器 获得了更好的准确率。初始学习率设置为0.0001。实验结 果如图7所示
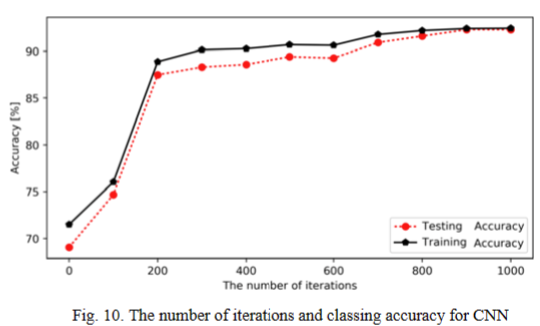
CNN 分类结果,根据胎心率数据的特点,我们设置 步长的大小为1。我们需要给予权重来制造一些随机 噪声来打破完全对称的,例如截断正态分布。标准差 设置为0.1。因为我们使用 ReLU,所以我们还在偏差 中添加了一些小的正值 (0.1) 以避免死节点。在训练 过程中,我们随机丢弃部分节点的数据以减少过拟 合,并保留整个数据在预测中以追求最终的预测性 能,因此dropout率等于1。最后,我们将 Dropout层的输出连接到Softmax层以获得最终的频 率输出。我们选择AdamOptimizer,它可以获得更 好的结果。并且学习率设置为0.00015,这也获得了 最好的结果。首先,我们将每个胎心记录分为多个分 段以提高准确性。实验结果如图10所示。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具