
selenium自动爬取-------生产实习
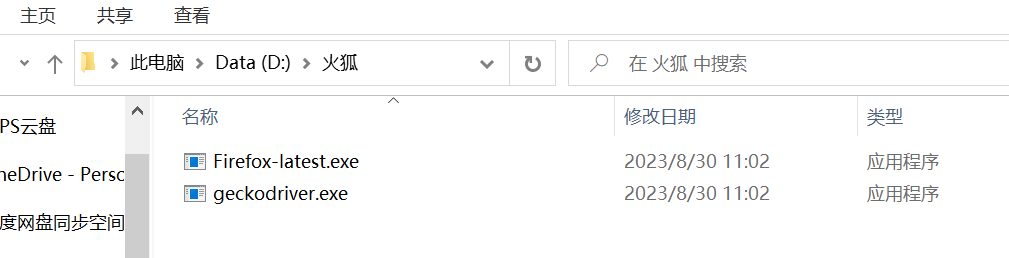
- 前期准备 (安装浏览器及其驱动 :文本使用火狐浏览器爬取 Google浏览器定位)
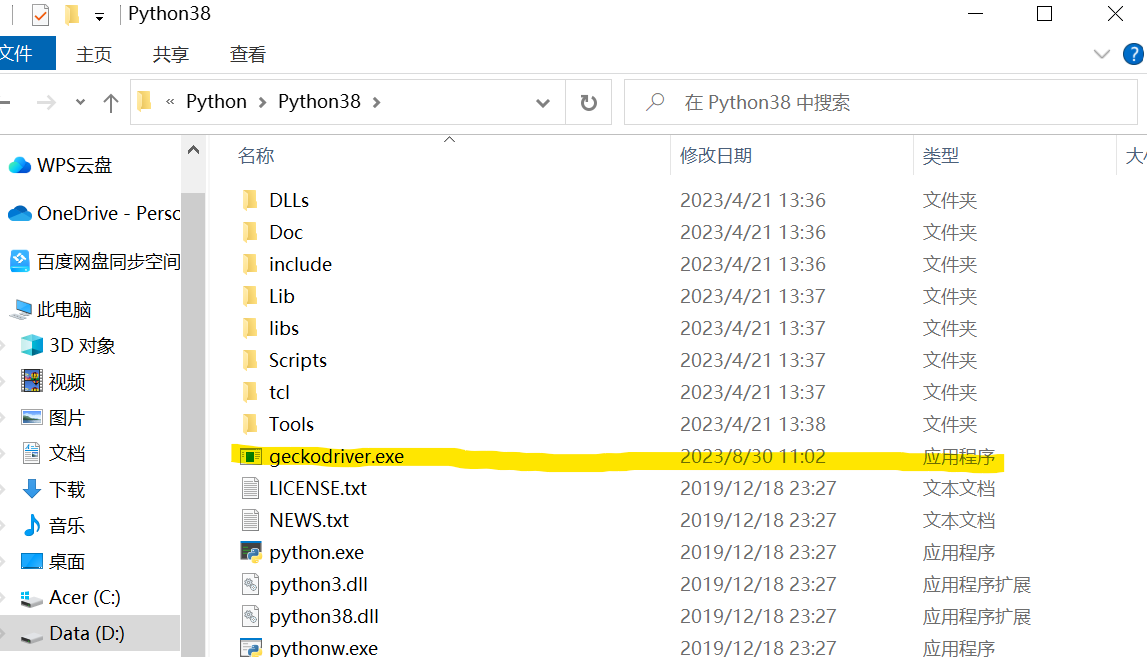
- 在pycharm使用的python、电脑安装的python的不同版本中都装上驱动
![]()
![]()
![]()
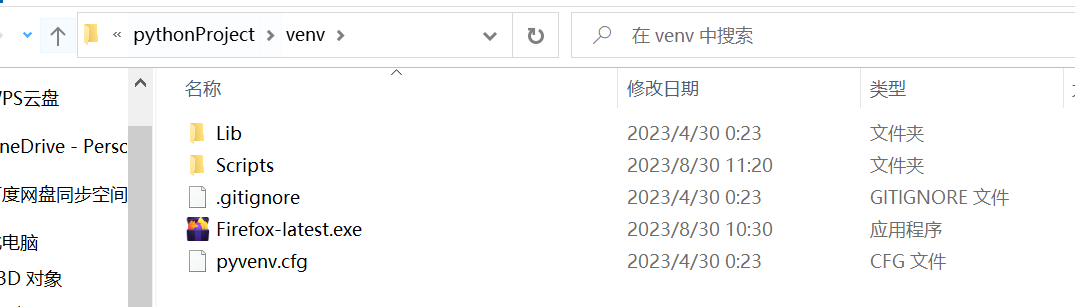
在pycharm的项目venv文件中放置火狐浏览器
- 导入相关的软件包
from selenium import webdriver from bs4 import BeautifulSoup import time
- 设置爬取的url
wd = open('D:\pythonProject\gz.csv','a+',encoding='UTF-8-SIG') #创建csv文档 保存获取的数据 driver=webdriver.Firefox() #自动打开浏览器 time.sleep(10) for i in range(1,3): # 所要爬取的网页 使用Google浏览器定位网页最准确 url=f'https://www.zhipin.com/web/geek/job?query=%E8%AE%A1%E7%AE%97%E6%9C%BA%E5%AE%9E%E4%B9%A0&city=101300100&page={i}' driver.get(url) time.sleep(20) #设置睡眠 模拟 人工等待 html = driver.page_source # #源码解析 等同于 打开F12 time.sleep(5) #设置睡眠 模拟 人工等待 htmlx = BeautifulSoup(html, 'html.parser') ##相对于request不需要转成content selenium只能使用一次
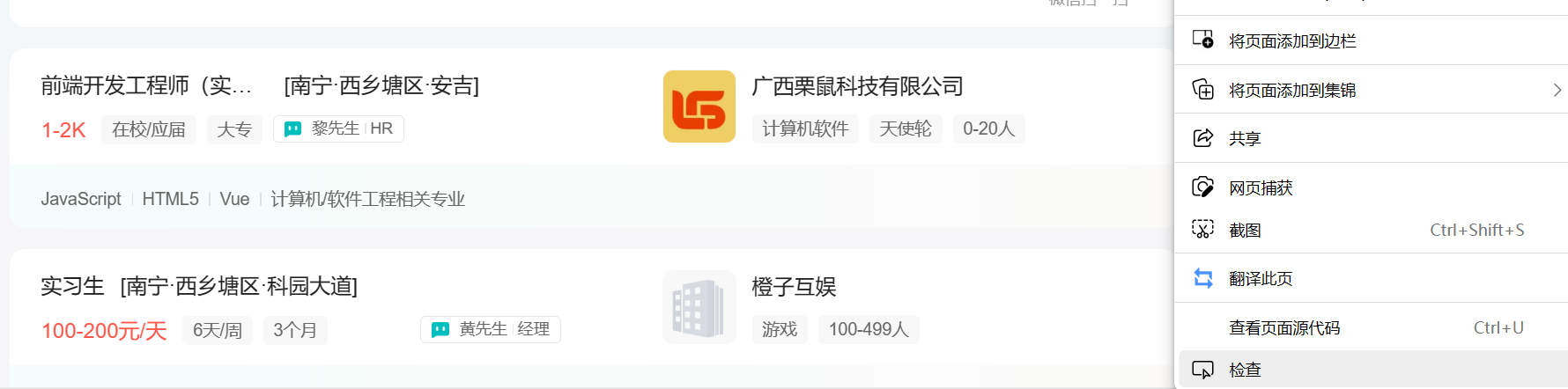
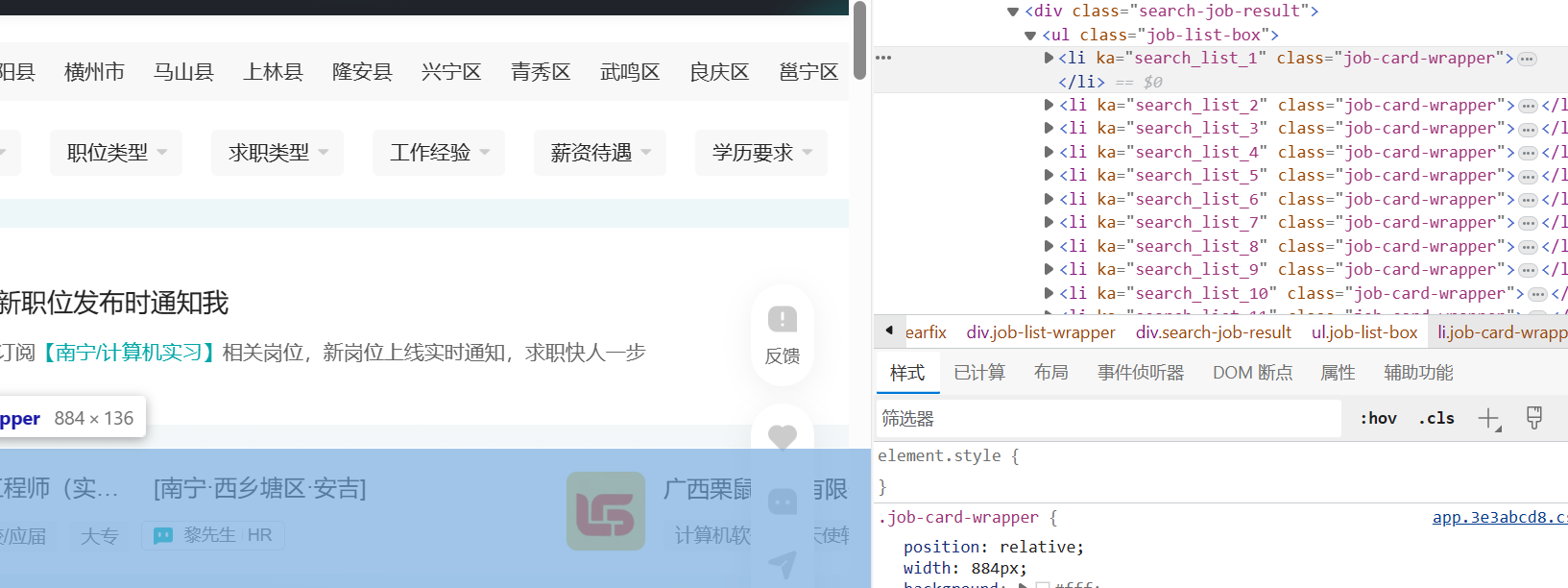
- 通过右键检查 --- 查看 定位selector路径
![]()
一个个li标签内容包含了各个小块求职信息
![]()
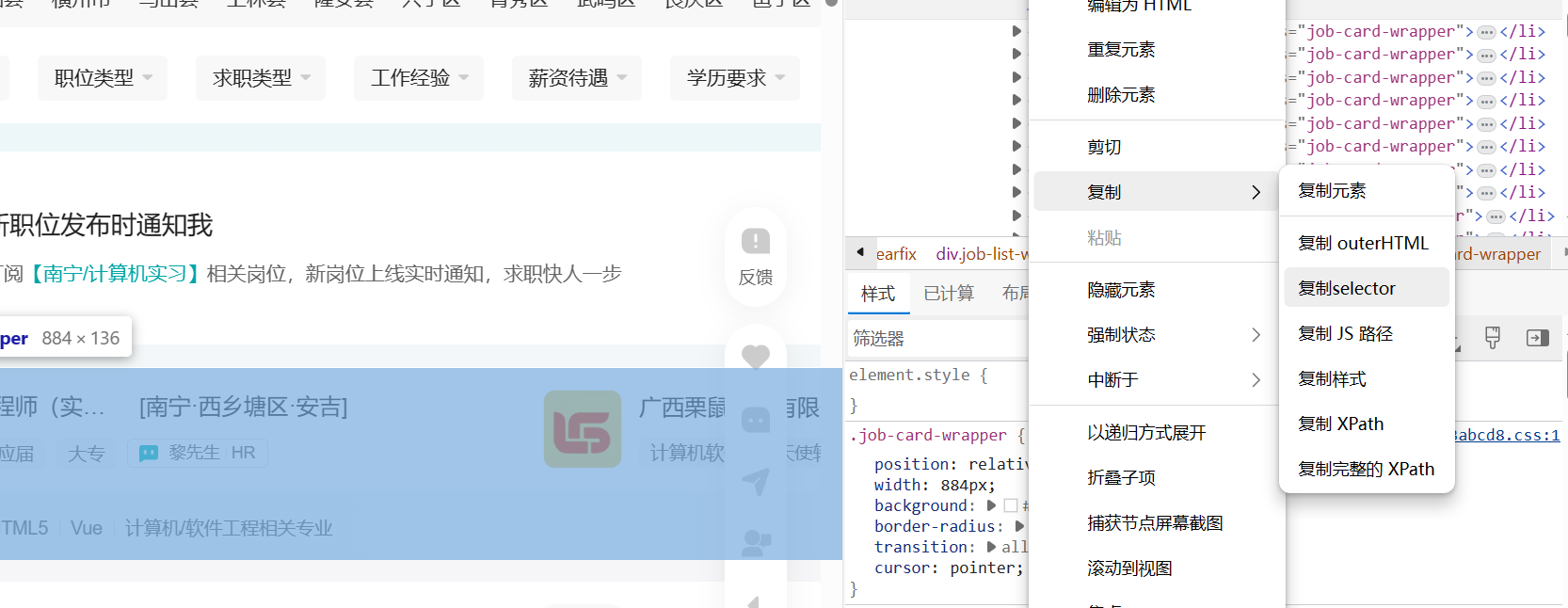
复制右键复制selector路径
![]()
#定位一小块的内容 li Google浏览器 使用selenium时火狐浏览器要打开 datas = htmlx.select('#wrap > div.page-job-wrapper > div.page-job-inner > div > div.job-list-wrapper > div.search-job-result > ul > li')
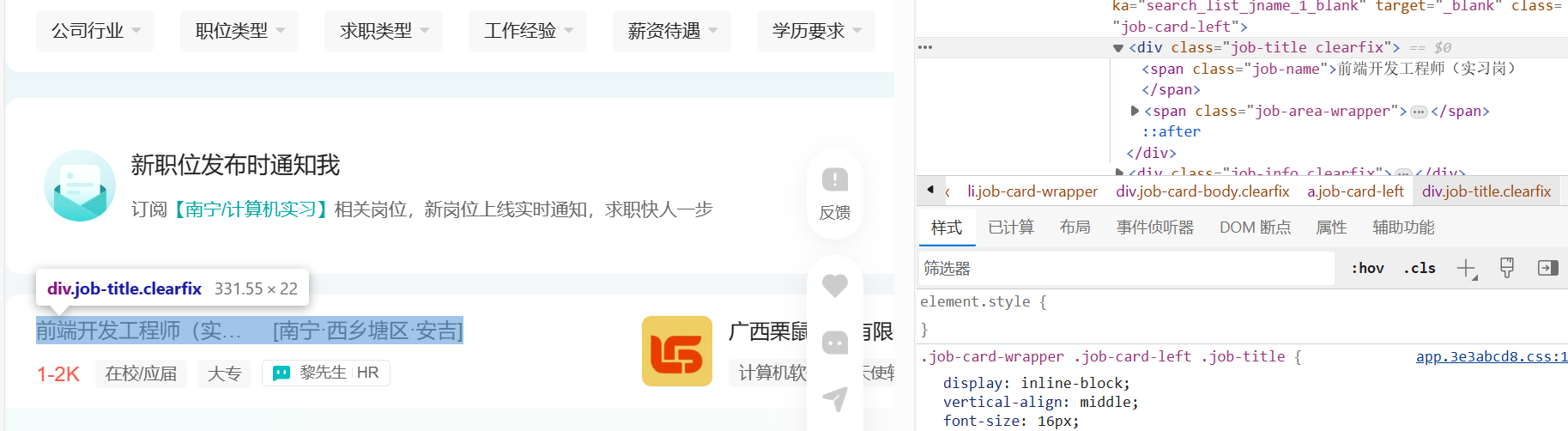
- 通过find函数对所要获取的数据单独爬取
![]()
#查看不同的标签 # 标签 = 小块.find('div',{'class':'tag'}).find_all('span') #获得的span的长度不同 # print('---------') # for t in 标签: # print(t.get_text()) # b=小块.find('div',{'class':'title'}).find('span',{'class':'tagBlock'}).get_text() #报错 空变量 不能使用.get()方法 # b=小块.find('div',{'class':'title'}).find('span',{'class':'tagBlock'}) for data in datas: bt = data.find('div', {'class': 'job-title clearfix'}).find('span', {'class': 'job-name'}).get_text(); dd = data.find('div', {'class': 'job-title clearfix'}).find('span', {'class': 'job-area'}).get_text(); xs = data.find('div', {'class': 'job-info clearfix'}).get_text(); yq = data.find('div', {'class': 'job-card-footer clearfix'}).find('ul').get_text(); gs = data.find('div', {'class': 'company-info'}).get_text(); gm = data.find('div', {'class': 'company-info'}).find('ul', {'class': 'company-tag-list'}).get_text();
- 写入csv文件
title = "标题,工作地点,基本信息,要求,公司,规模" wd.write(title + "\n") wd.write(bt + ',' + str(dd) + ',' + str(xs) + ',' + str(yq) + ',' + str(gs) + ',' + gm + "\n")
- 全部代码
from selenium import webdriver from bs4 import BeautifulSoup import time wd = open('D:\pythonProject\gz.csv','a+',encoding='UTF-8-SIG') #创建csv文档 保存获取的数据 driver=webdriver.Firefox() #自动打开浏览器 time.sleep(10) for i in range(1,3): # 所要爬取的网页 使用Google浏览器定位网页最准确 url=f'https://www.zhipin.com/web/geek/job?query=%E8%AE%A1%E7%AE%97%E6%9C%BA%E5%AE%9E%E4%B9%A0&city=101300100&page={i}' driver.get(url) time.sleep(20) #设置睡眠 模拟 人工等待 html = driver.page_source # #源码解析 等同于 打开F12 time.sleep(5) #设置睡眠 模拟 人工等待 htmlx = BeautifulSoup(html, 'html.parser') ##相对于request不需要转成content selenium只能使用一次 #定位一小块的内容 li Google浏览器 使用selenium时火狐浏览器要打开 datas = htmlx.select('#wrap > div.page-job-wrapper > div.page-job-inner > div > div.job-list-wrapper > div.search-job-result > ul > li') for data in datas: bt = data.find('div', {'class': 'job-title clearfix'}).find('span', {'class': 'job-name'}).get_text(); dd = data.find('div', {'class': 'job-title clearfix'}).find('span', {'class': 'job-area'}).get_text(); xs = data.find('div', {'class': 'job-info clearfix'}).get_text(); yq = data.find('div', {'class': 'job-card-footer clearfix'}).find('ul').get_text(); gs = data.find('div', {'class': 'company-info'}).get_text(); gm = data.find('div', {'class': 'company-info'}).find('ul', {'class': 'company-tag-list'}).get_text(); print(bt + " " + dd) print(xs) print(yq) print(gs + " " + gm) print("~~~~~~~~") title = "标题,工作地点,基本信息,要求,公司,规模" wd.write(title + "\n") wd.write(bt + ',' + str(dd) + ',' + str(xs) + ',' + str(yq) + ',' + str(gs) + ',' + gm + "\n")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号