
1. 前文回顾
在字符串算法—字典树(Tries)中,我们实现了在一堆字符串中寻找某个字符串的高效算法。但如果要从一段字符中,寻找某个字符串呢?
我们可以用字符串算法—字符串排序(下篇)中的后缀排序法(suffix arrays)来寻找关键词,但它消耗的内存有点大(毕竟要建一个超大的数组)。
为了解决这个问题,本文将介绍KMP算法(Knuth-Morris-Pratt)和BM算法(Boyer-Moore)。
2. KMP算法(Knuth-Morris-Pratt)
简单介绍一下问题:
现有一段字符:AABACAABABACAA
问:ABABAC是否在这段字符里,如果在,在哪里?
从解决这个问题的过程中了解KMP算法:
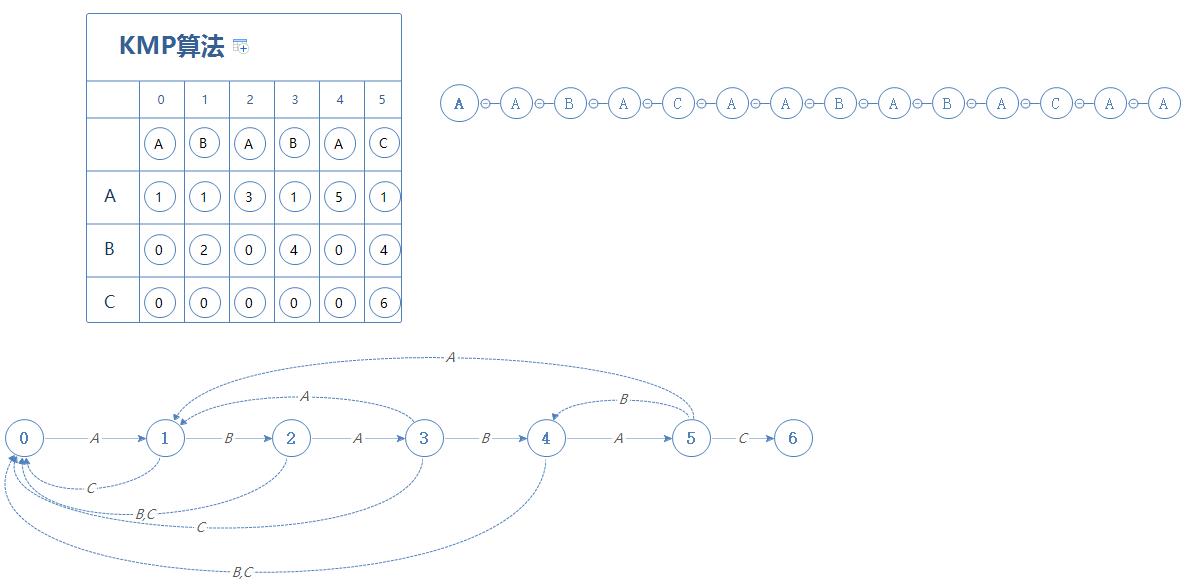
左上角那个表格是KMP算法要用到的辅助表格,最下面的那个图是这个表格的图像化(方便理解用),右上角的图为题目中的那段字符。
辅助表格如何建立,我们等下再介绍,我们先直接用。辅助表格中的字符是题目要我们找的字符串。
为了方便讲解,我们命名题目中的那段字符为字符串S;要寻找的字符为字符串G;即:
字符串S: AABACAABABACAA
字符串G: ABABAC
首先,我们对比S和G的第一个字符,处于辅助表格的第0阶段:
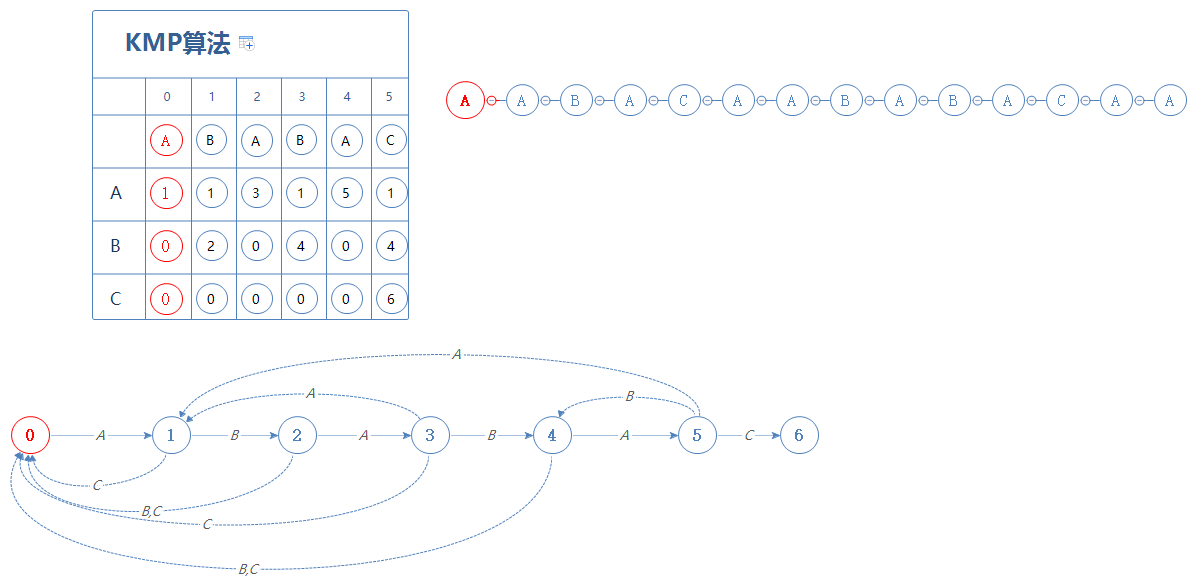
由于字符串S只有A,B,C三种字母,所以辅助表格只考虑了A,B,C三种情况。
处于第0阶段时,如果遇见的是A,则前往第1阶段;如果遇见的是B或者C,则停留在第0阶段;
我们这里遇见的是S的第一个字符A,故前往第1阶段:
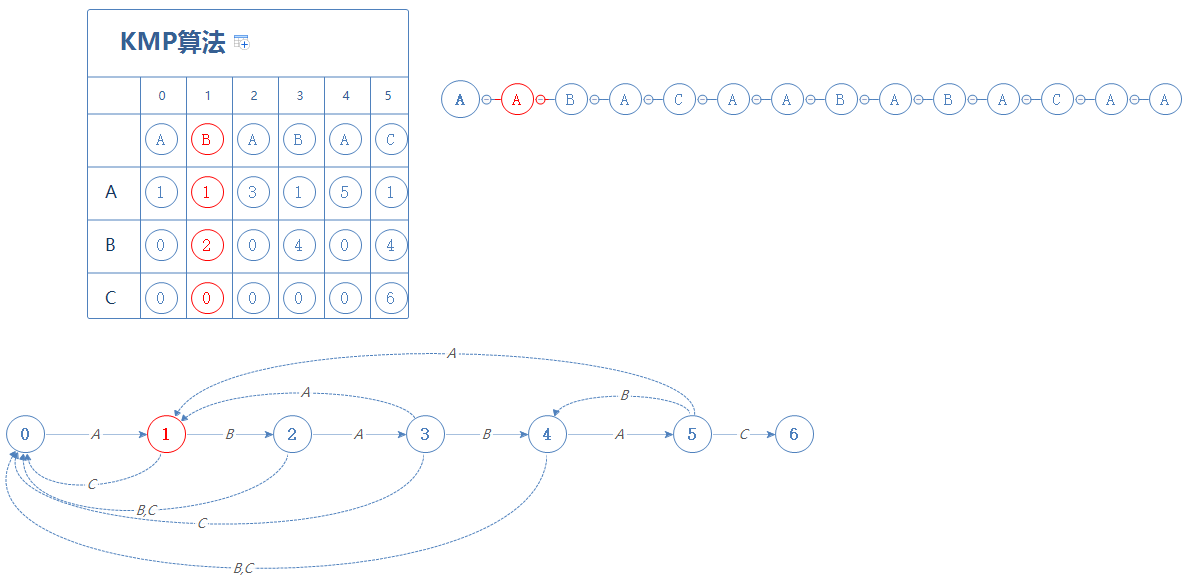
然后我们来看S的下一个字符A,
处于第1阶段时,如果遇见的是A,则停留在第1阶段;如果遇见的是B,则前往第2阶段;如果遇见的是C,则前往第0阶段;
现在,我们遇到的是A,故停留在第1阶段:
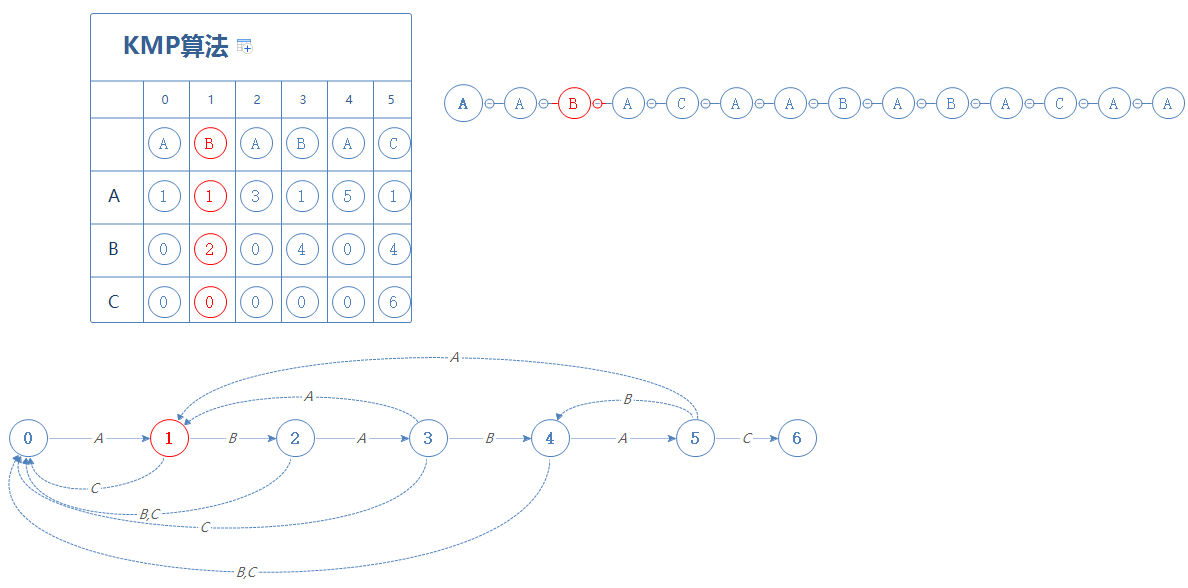
然后我们来看S的下一个字符B,处于第1阶段遇见B,前往第2阶段:(如果有字符已匹配上,则用绿色表示)
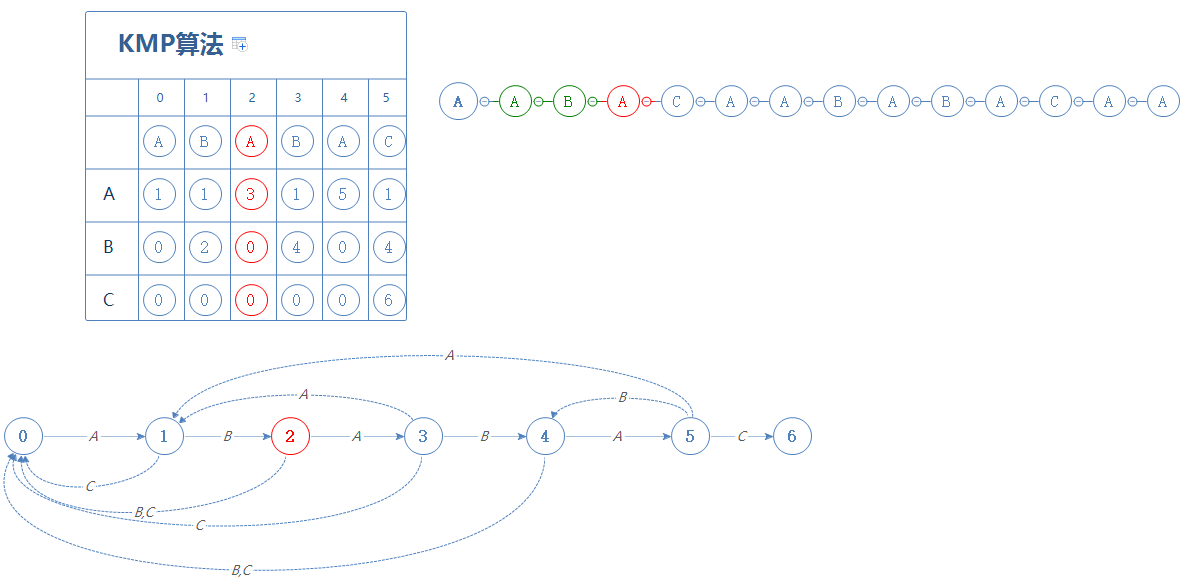
处于第2阶段时,如果遇见的是A,则前往第3阶段;如果遇见的是B或C,则前往第0阶段
我们来看S的下一个字符A,故前往第3阶段:
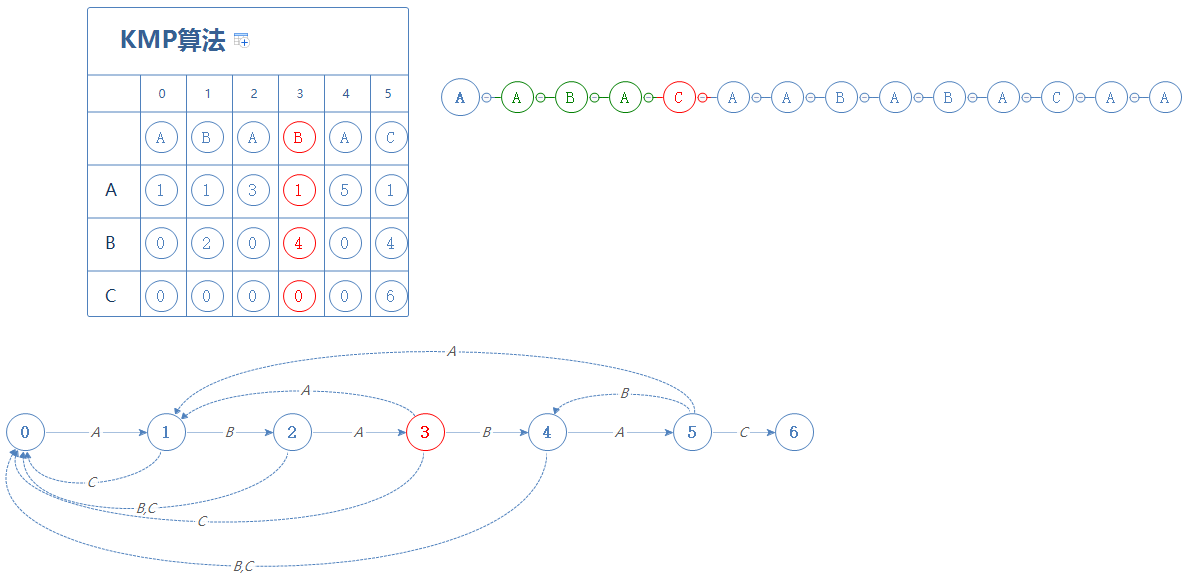
处于第3阶段时,如果遇见的是A,则前往第1阶段;如果遇见的是B,则前往第4阶段;如果遇见的是C,则前往第0阶段;
我们来看S的下一个字符C,故前往第0阶段:
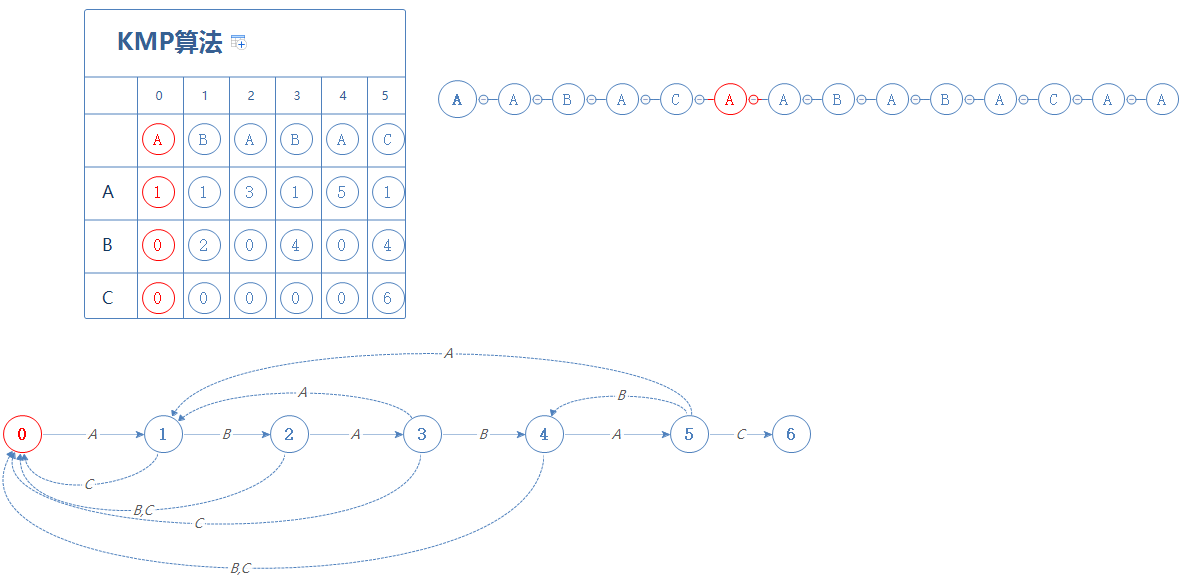
处于第0阶段时,如果遇见的是A,则前往第1阶段;如果遇见的是B或者C,则停留在第0阶段;
我们这里遇见的是S的下一个字符A,故前往第1阶段:
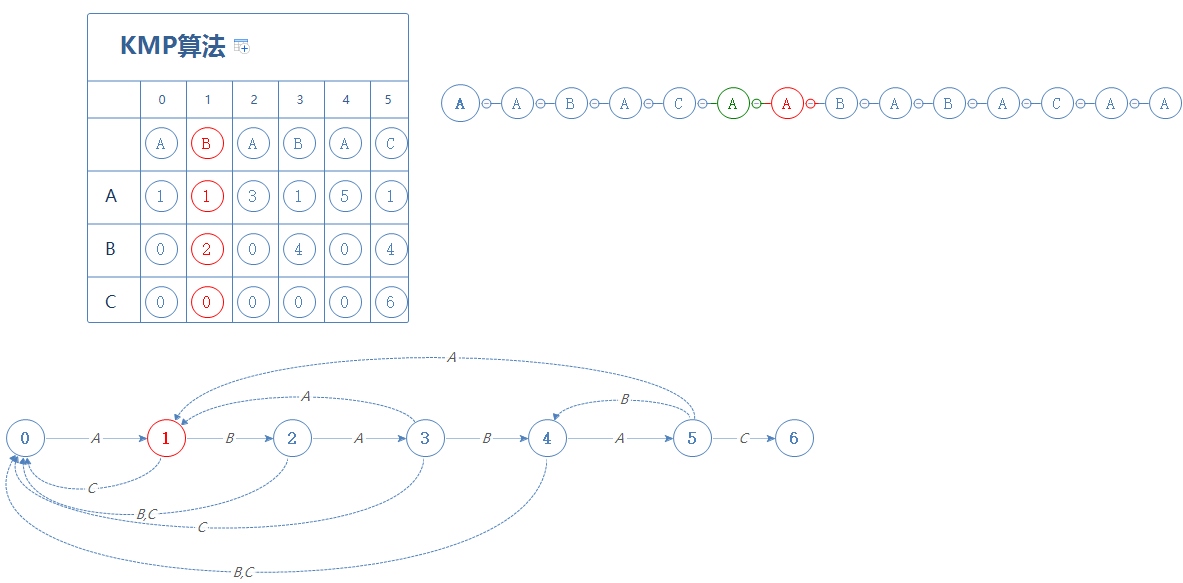
处于第1阶段时,如果遇见的是A,则停留在第1阶段;如果遇见的是B,则前往第2阶段;如果遇见的是C,则前往第0阶段;
现在,我们遇到的是S的下一个字符A,故停留在第1阶段:
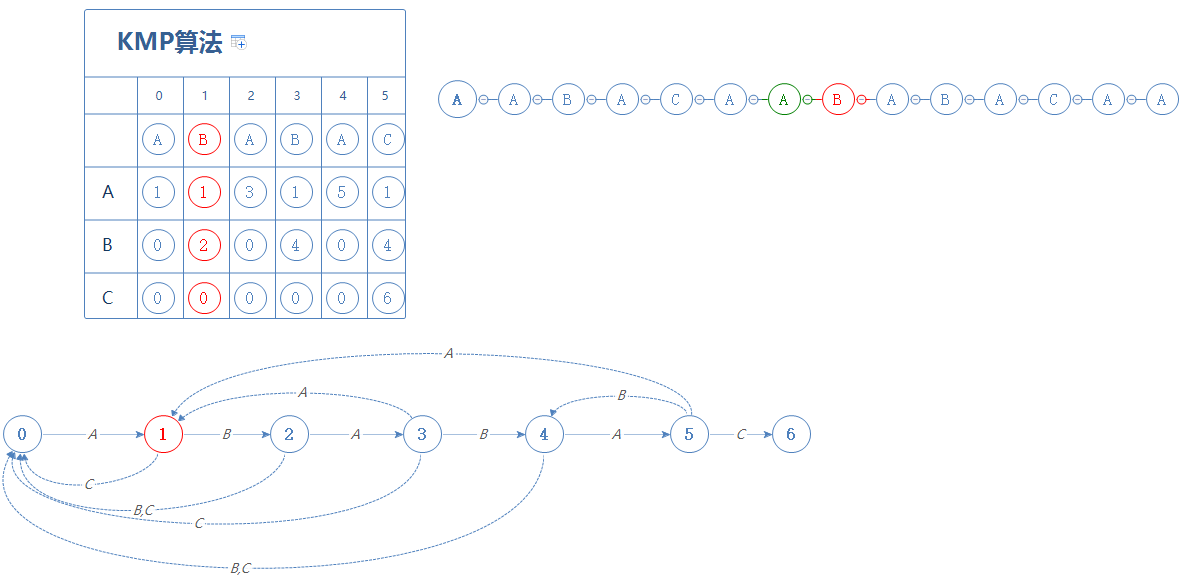
处于第1阶段时,如果遇见的是A,则停留在第1阶段;如果遇见的是B,则前往第2阶段;如果遇见的是C,则前往第0阶段;
我们遇到的是S的下一个字符B,故前往第2阶段:
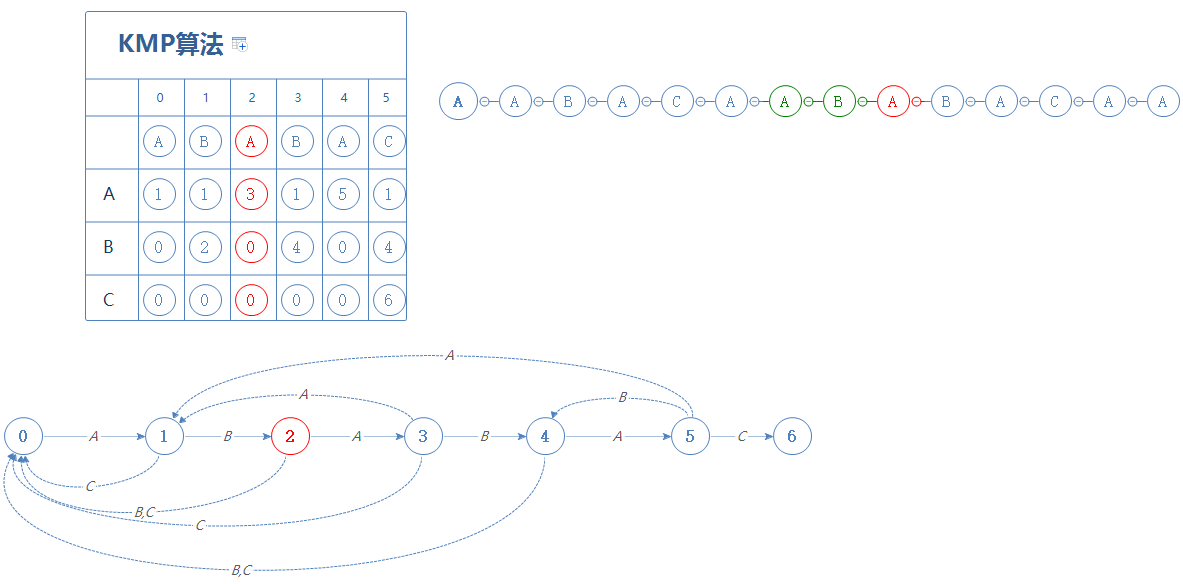
处于第2阶段时,如果遇见的是A,则前往第3阶段;如果遇见的是B或C,则前往第0阶段
我们来看S的下一个字符A,故前往第3阶段:
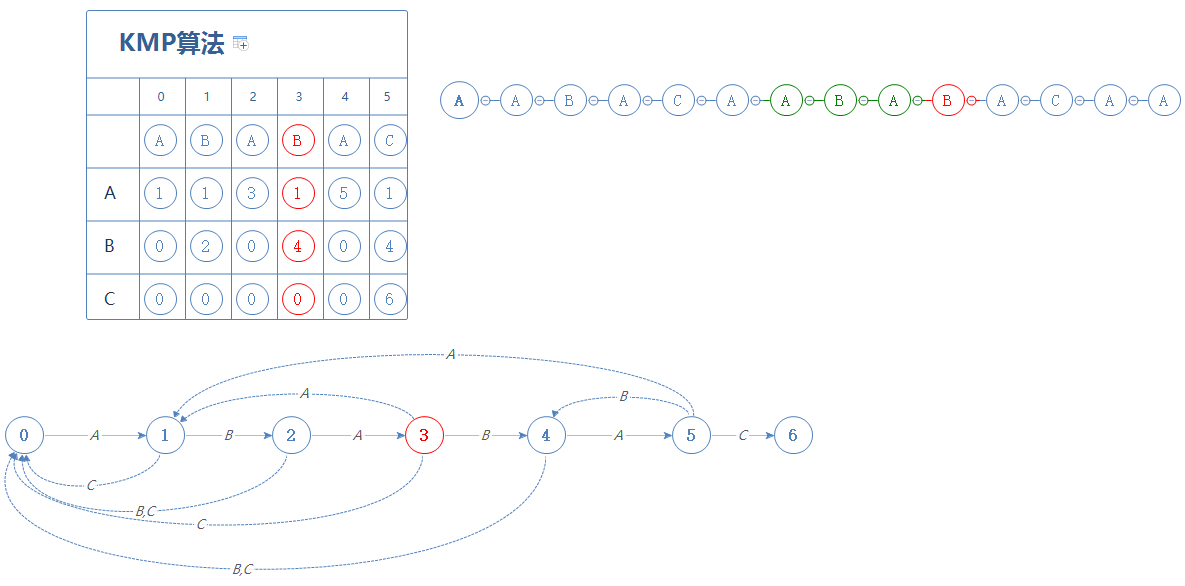
处于第3阶段时,如果遇见的是A,则前往第1阶段;如果遇见的是B,则前往第4阶段;如果遇见的是C,则前往第0阶段;
我们来看S的下一个字符B,故前往第4阶段:

处于第4阶段时,如果遇见的是A,则前往第5阶段;如果遇见的是B或C,则前往第0阶段
我们来看S的下一个字符A,故前往第5阶段:

处于第5阶段时,如果遇见的是A,则前往第1阶段;如果遇见的是B,则前往第4阶段;如果遇见的是C,则前往第6阶段;
我们来看S的下一个字符C,故前往第6阶段:
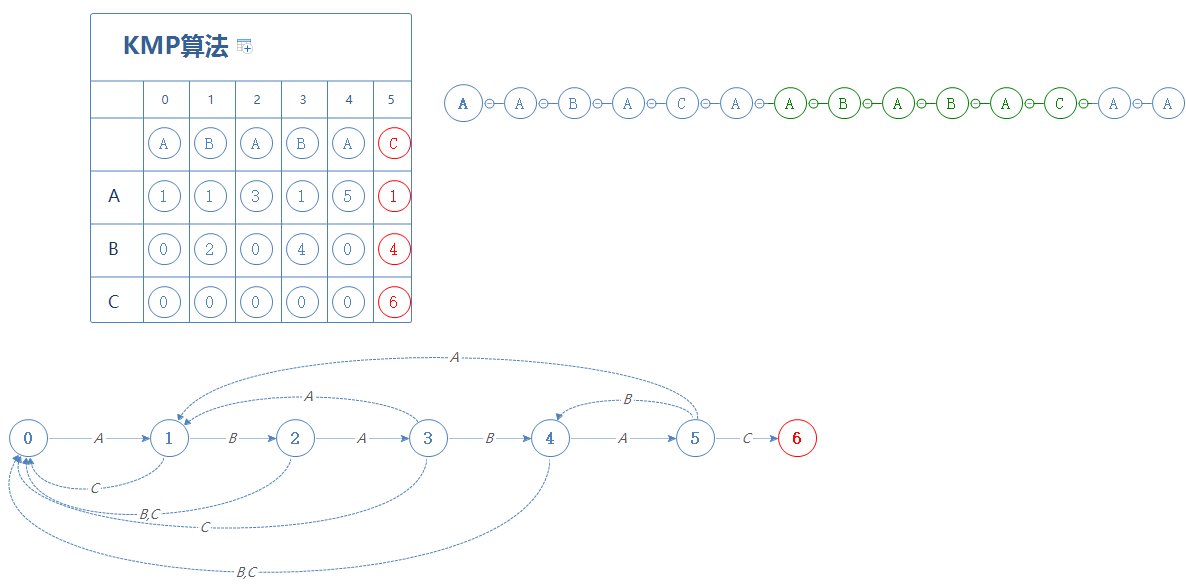
第6阶段就是最终阶段了,来到这个阶段,说明已经找到字符串G了,至于G在字符串S的什么位置,这个容易求:
由于我们是逐个检查字符串S的,(从int i=0开始逐渐递增)所以我们是知道正在检查第几个字符的(i)。
int T= i-字符串G的长度+1; T就是字符串G所处位置,在本例子中,T=6,即字符串G在字符串S的第6个字符处。
如果我们需要知道某个字符串在某段字符中出现过多少次,分别在哪,则可以在每次找到此字符串时,重新回到第0阶段,继续寻找下去。
在本例中,任务完成了,算法结束。
顺带一提:所谓的第几阶段就是有几个字符已经匹配上了。例如处于第三阶段时,字符串G和字符串S已经匹配上了3个字符。
现在开始讨论如何建立辅助表格:
首先最简单的就是每个阶段都遇到了正确的字符,即:
我们要查找的字符串G为ABABAC,第0阶段遇到A;第1阶段遇到B;第2阶段遇到A;第3阶段遇到B;第4阶段遇到A;第5阶段遇到C;那么每个阶段都会前往下一个阶段:
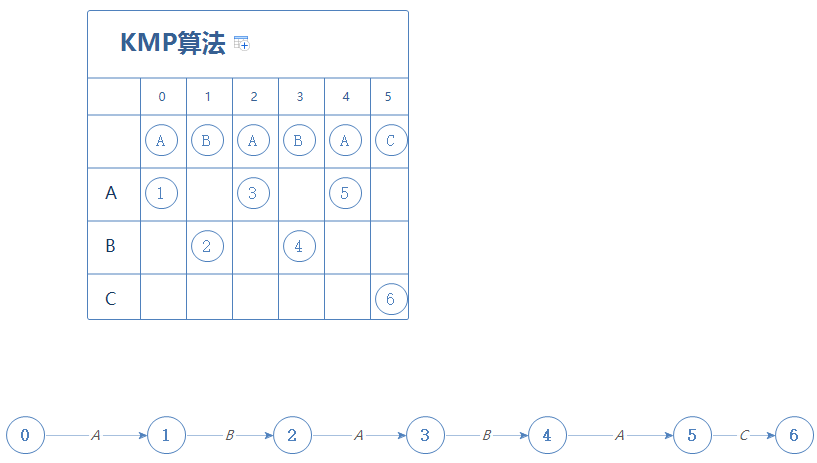
当我们遇到的是不正确的字符,该怎么办呢?这里新增一个整数型变量int X=0;这个X将起辅助作用。
首先第0阶段,只有遇到正确的字符才会前进,否则停留在原地,故:

然后到第1阶段,当我们在第X阶段时(X=0),遇到A会前往第1阶段;遇到C会停留在第0阶段。把这个结果填进第1阶段:(图中标红的是第X阶段)
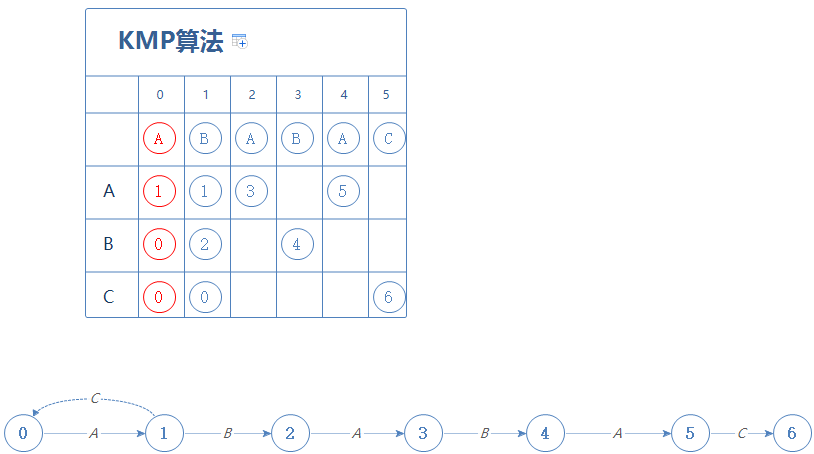
然后更新X:现在在第1阶段,第1阶段的字符为B,在第X阶段(X=0)遇到B会停留在第0阶段,故X=0,X值没改变。
然后到第2阶段,当我们在第X阶段时(X=0),遇到B会停留在第0阶段;遇到C会停留在第0阶段。把这个结果填进第2阶段:
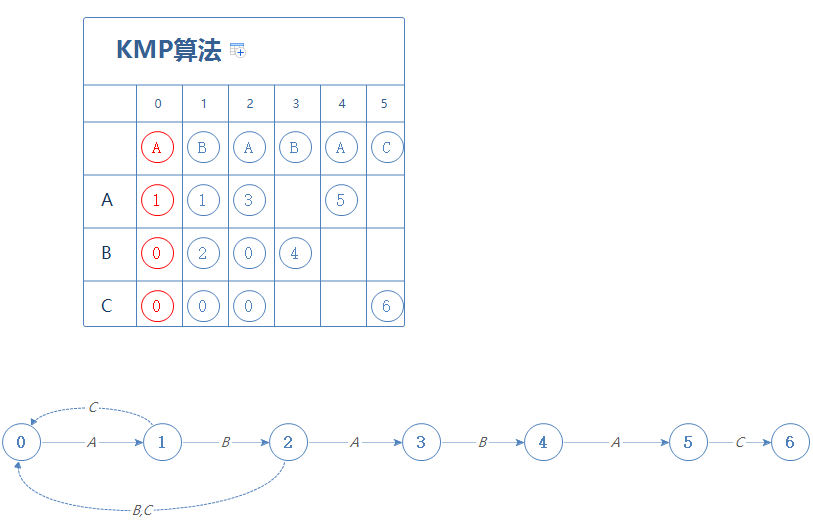
然后更新X:现在在第2阶段,第2阶段的字符为A,在第X阶段(X=0)遇到A会前往第1阶段,故X=1。
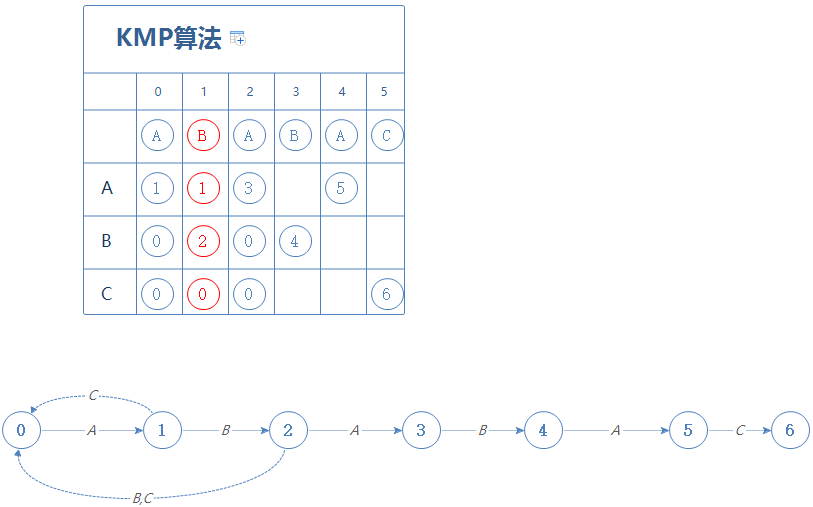
然后到第3阶段,当我们在第X阶段时(X=1),遇到A会前往第1阶段;遇到C会前往第0阶段。把这个结果填进第3阶段:
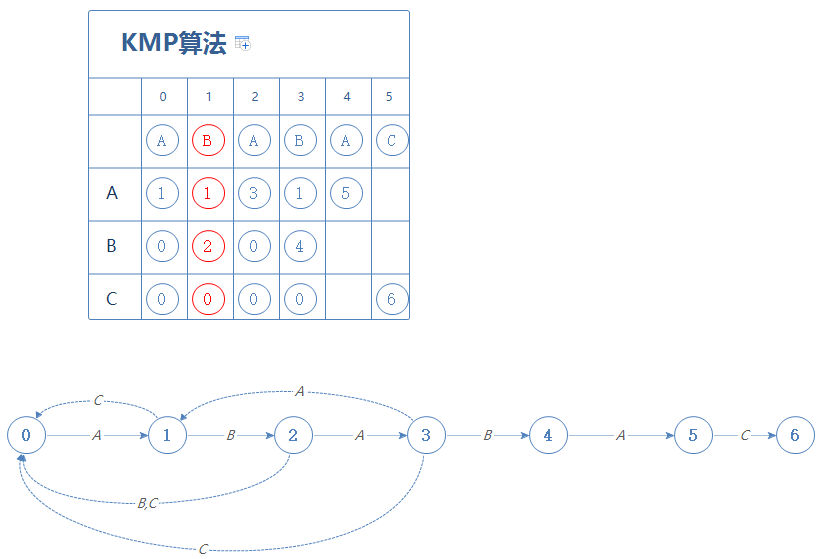
然后更新X:现在在第3阶段,第3阶段的字符为B,在第X阶段(X=1)遇到B会前往第2阶段,故X=2。
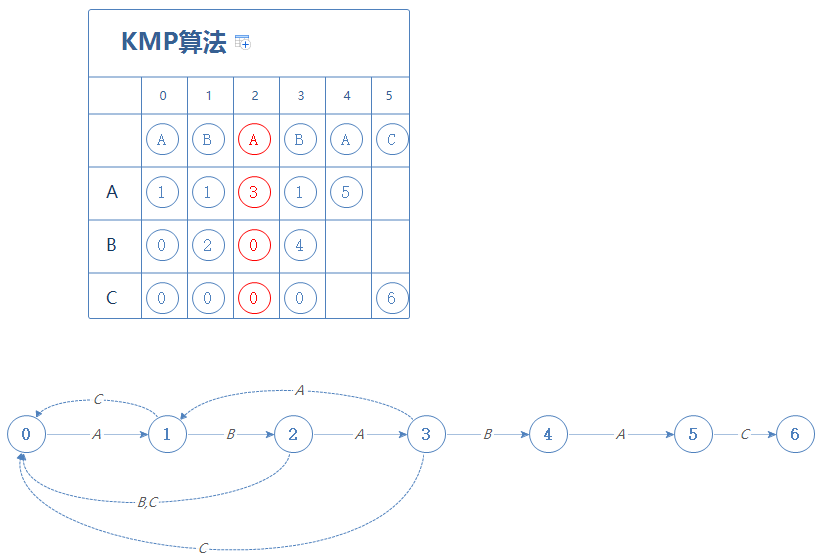
然后到第4阶段,当我们在第X阶段时(X=2),遇到B会前往第0阶段;遇到C会前往第0阶段。把这个结果填进第4阶段:

然后更新X:现在在第4阶段,第4阶段的字符为A,在第X阶段(X=2)遇到A会前往第3阶段,故X=3。
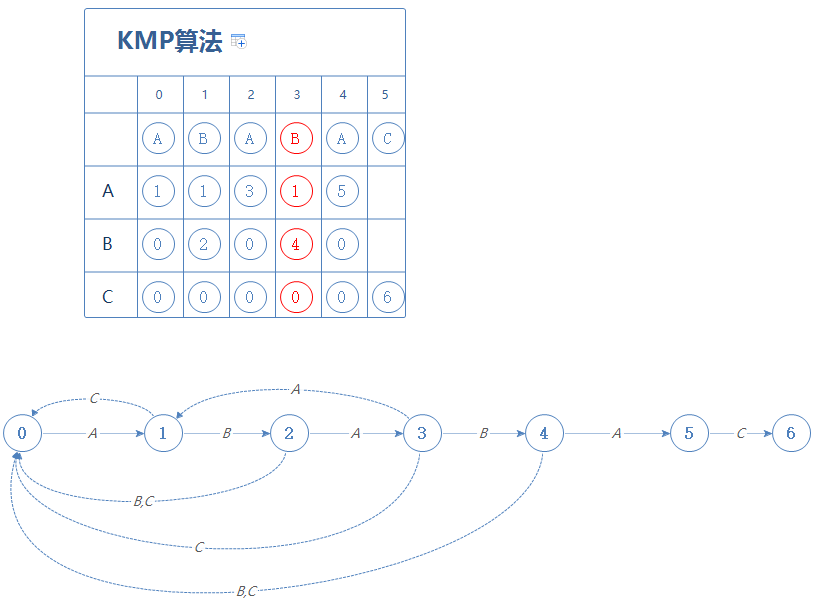
然后到第5阶段,当我们在第X阶段时(X=3),遇到A会前往第1阶段;遇到B会前往第4阶段。把这个结果填进第5阶段:

这样辅助表格就做好了。
辅助表格的制作过程加上一开始介绍的寻找过程就是完整的KMP算法了。
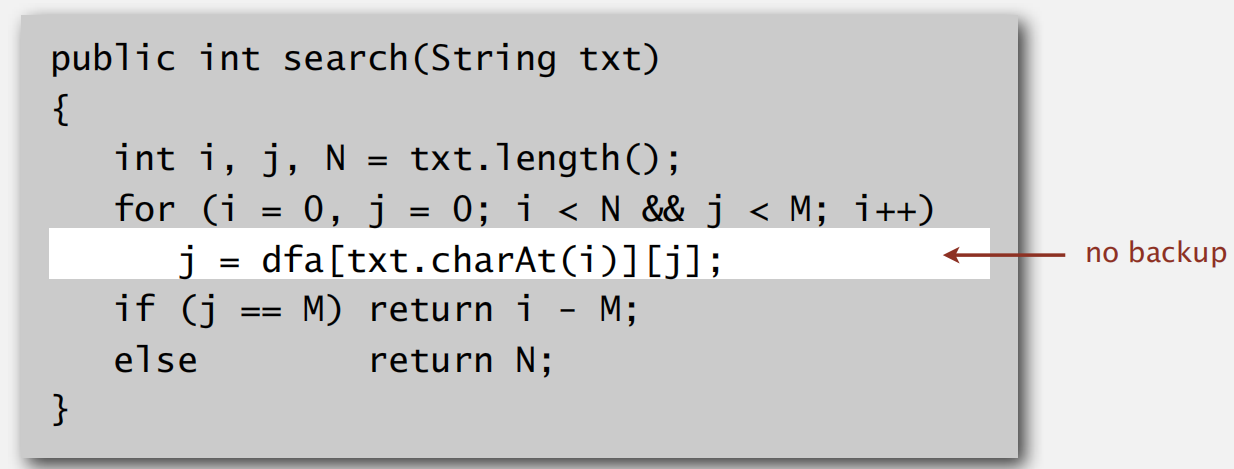
实现代码
建立表格:
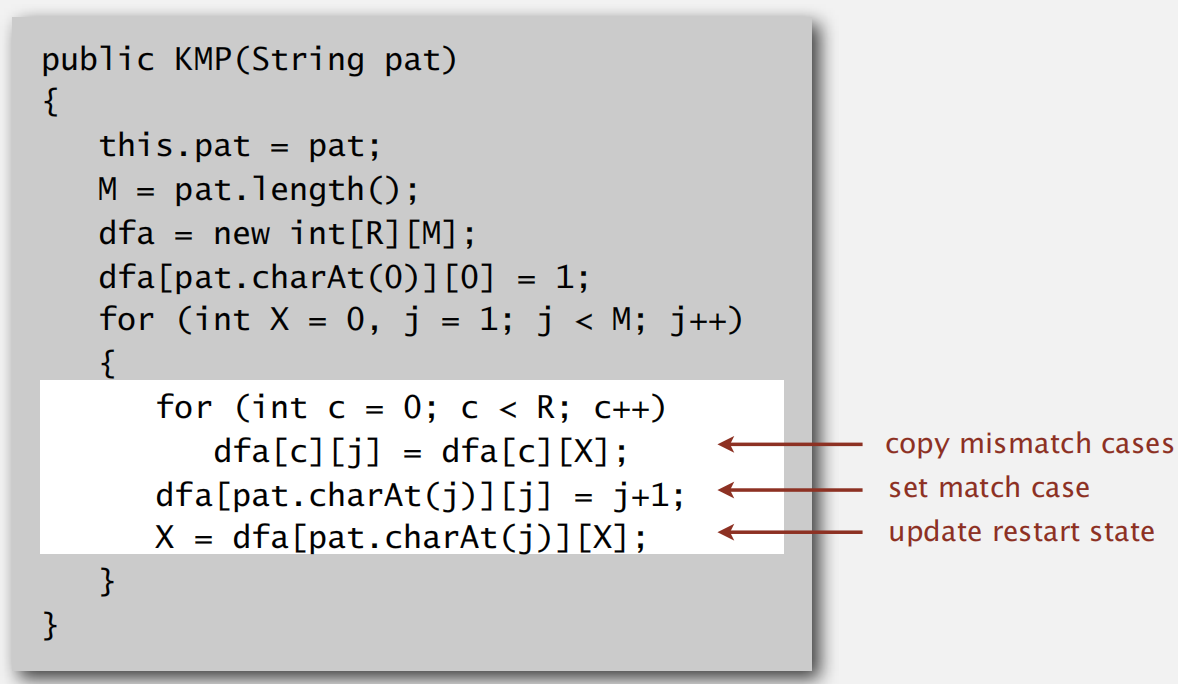
寻找字符:
3. KMP算法效率
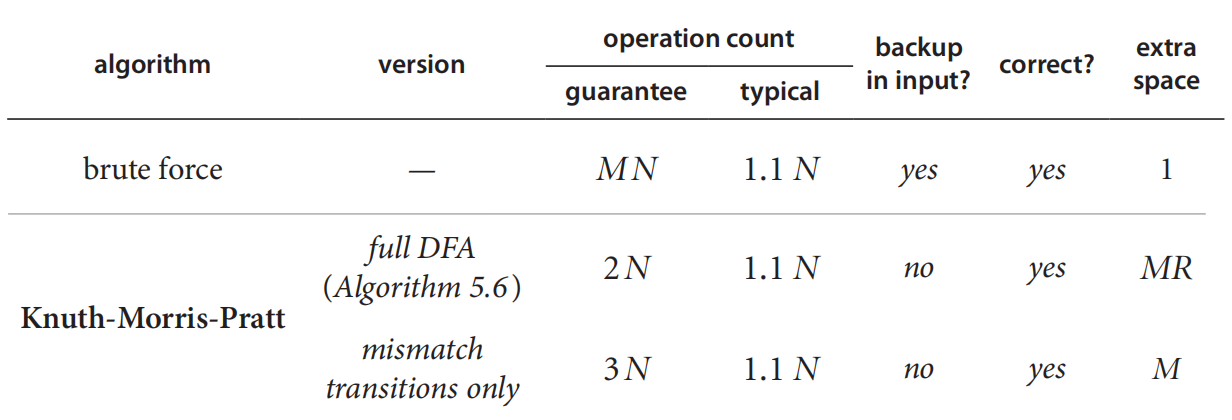
Brute force(暴风算法)是种蛮力算法,它把要查找的字符串与原字符串的第一个字符开始一一对比,如果发现不匹配的字符,则从下一个字符开始一一个对比。如此类推,直到找到了该字符串或原字符串所有字符都对比完(找不到该字符串的情况)为止。
由于此算法效率低下,这里没有细讲。
图中N为原字符串所含字符数量;M为要找的字符串所含字符数量,R为字符串中可能出现的字符种类数量,根据下图选择:

4. BM算法(Boyer-Moore)
百度了一下:在用于查找子字符串的算法当中,BM(Boyer-Moore)算法是目前被认为最高效的字符串搜索算法,它由Bob Boyer和J Strother Moore设计于1977年。 一般情况下,比KMP算法快3-5倍。
这个算法牛的地方在于要查找的字符串越长,搜索效率越高。
从例子入手:


如上图,我们把所有的字符的值定为-1,要查找的字符串needle含有4个不同的字符,我们根据它们所处位置给它们赋值:right[N]=0; right[E]=5; right[D]=3; right[L]=4;其中E出现了3次,我们取其中的最大值。
新增整数变量 int i=0; int j=0; 原字符串长度N=24; 查找的字符串长度M=6;
首先。j=M-1;即j=5;从第j个字符开始比较:

比较结果:不相等。
然后要决定我们可以跳几个字符:原字符串的第5个字符为N,right[N]=0; j-right[N]=5-0=5; 故我们可以跳5个字符:i +=5; i=5;

j+i=5+5=10;比较原字符的第10个字符:

比较结果:不相等。
然后要决定我们可以跳几个字符:原字符串的第10个字符为S,right[S]=-1; j-right[S]=5-(-1)=6; 故我们可以跳6个字符(因为s不在要查找的字符串里,所以可以把这整段跳过去):i +=6; i=11;

j+i=5+11=16;比较原字符的第16个字符:

比较结果:相等。比较前一个字符, j--; j=5-1=4:

计较结果:相等。
然后要决定我们可以跳几个字符:原字符串的第15个字符为N,right[N]=0; j-right[N]=4-0=4; 故我们可以跳4个字符:i +=4; i=15, j=M; j=5;

j+i=5+15=20;比较原字符的第20个字符:

比较结果:相等。比较前一个字符, j--; j=5-1=4:

比较结果:相等。比较前一个字符, j--; j=4-1=3:(由于接下来的结果都是相等,故省略中间过程,直接跳到j=0)

比较结果:相等。由于j=0;再减下去就是负数了,算法也在这里结束。要查找的字符串在原字符的第i个字符处(i=15)。
另外,值得一提的是,请看以下情况:

此时,j=3, 比较结果不相同。
然后要决定我们可以跳几个字符:原字符串的第18个字符为E,right[E]=5; j-right[E]=3-5=-2; 跳的步数为负数,我们总不能往回跳吧!故当跳的步数为负时,我们只往前跳一个字符:

此时如果再跳,就要跳出字符串之外了,故当i>N-M时,我们停止算法,判断结果为没找到该字符。
当我们的要找的字符串越长时,我们可能能跳的字符数也越多,算法越快。(为什么是可能?因为当原字符串的字符都出现在要查找的字符串时,是没办法跳M个字符的。)
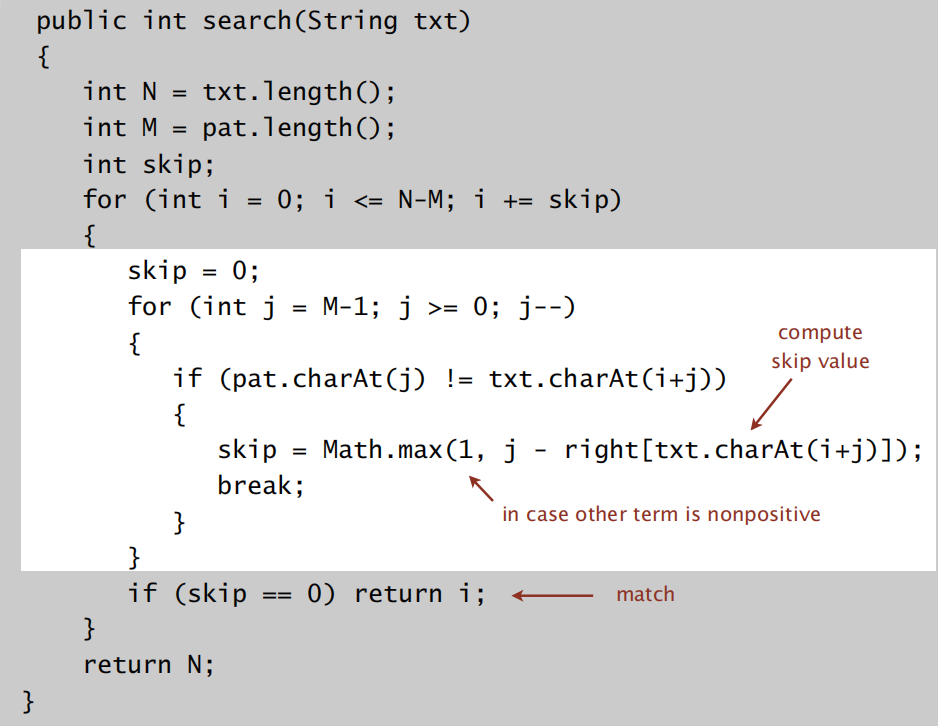
实现代码:

5. BM算法效率
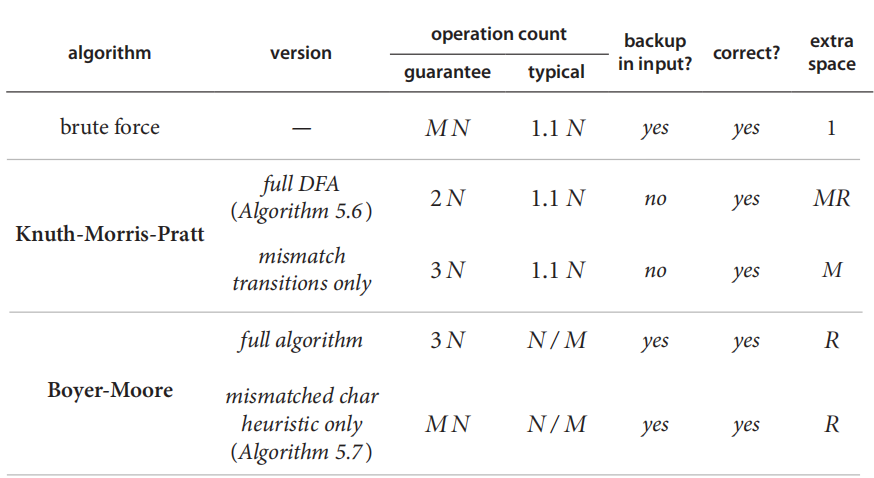
图中N为原字符串所含字符数量;M为要找的字符串所含字符数量,R为字符串中可能出现的字符种类数量。
但是,如果遇到最坏情况:

在这种情况下,BM算法跳不了,只能一步一步往前比较。此时就等于是Brute force(暴风算法)了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号