
1. 有向图(Directed Graphs)
有向图与无向图是很像的,如果对无向图不熟悉,建议先看一下无向图。
在讨论有向图的算法前,先讨论如何构建有向图。
构建有向图的方法基本与无向图的方法一模一样。
首先,有向图是长这样的:
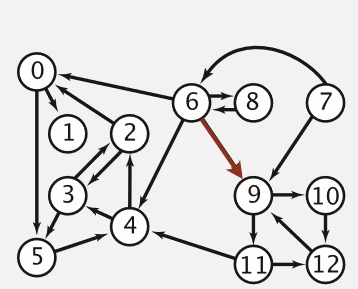
也是有两个关键点:
a. 这个有向图有哪些点
b. 哪些点可以通往哪些点(箭头代表可通往的方向,如此例子中,0可以去1,但1不可以去0。)
构建有向图也是用邻接矩阵(Adjacency-matrix)或邻接列表(Adjacency-list)。
这个矩阵和列表也和无向图的基本一样,唯一的区别在于,有向图的矩阵不是关于对角线对称的。
有向图的邻接列表显示:(0可以去的点有5,1,即adj[0]=5,1)
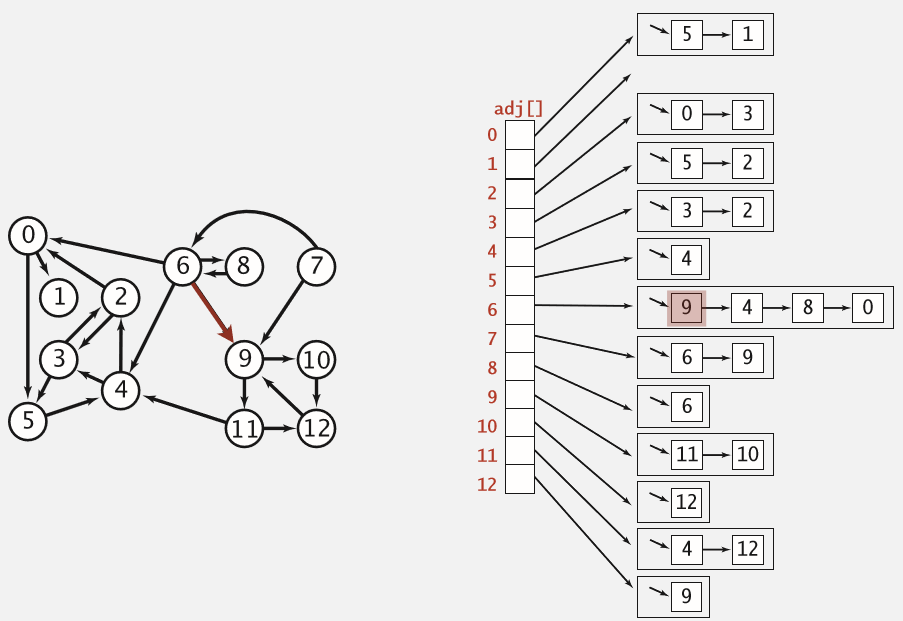
下面开始讨论有向图的算法:深度优先搜索(depth-first search)和广度优先搜索(breadth-first search)。
无向图的Group在有向图中不适用,因为有些路是单方向的。稍后我们将引入强联系(Strong Components)的概念来解决Group的问题。
2. 深度优先搜索(depth-first search)
有向图的深度优先搜索与无向图的深度优先搜索很像,像到什么程度呢?甚至可以直接把无向图的深度优先搜索代码直接复制过来用。
看例子:
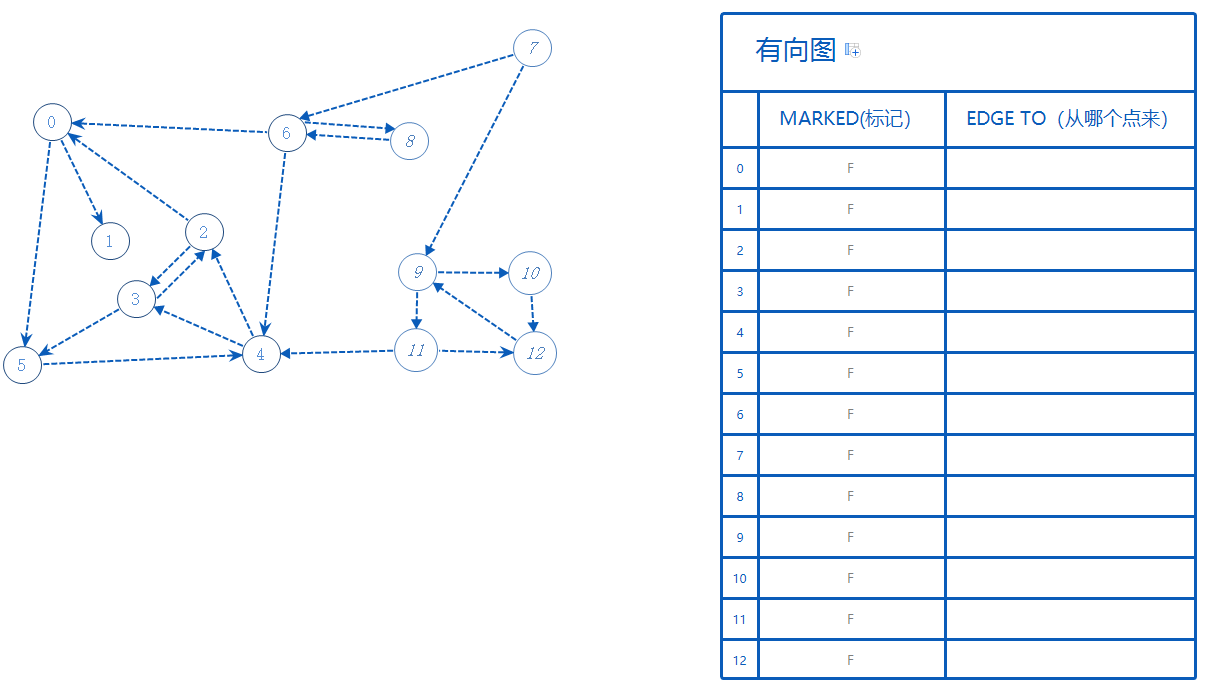
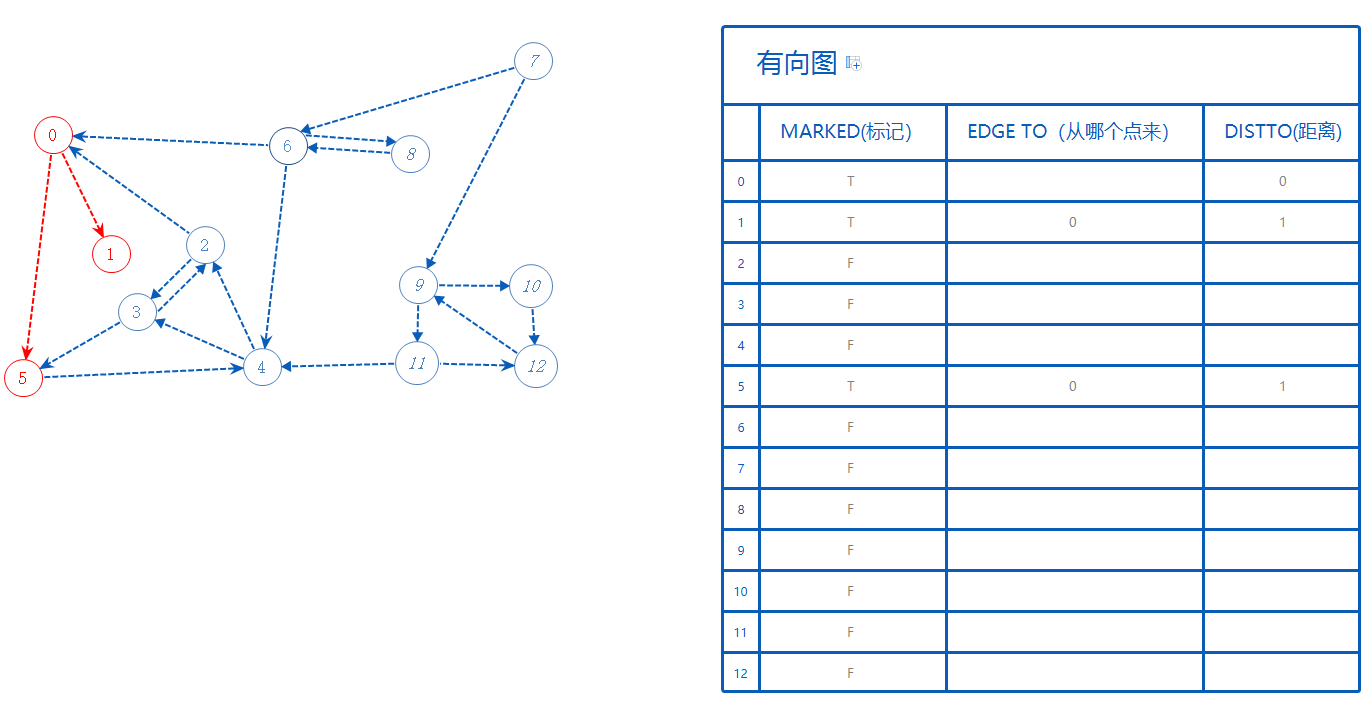
0~12代表着图中的所有点。
一开始所有点标记为False(F),当我们走到某个点后,此点标记为True(T)。标记过的点不需要再走一次。
EdgeTo记录了部分路线,所有部分路线可以整合成一个完整的路线。例如从E点抵达A点,则记为EdgeTo[A]=E;
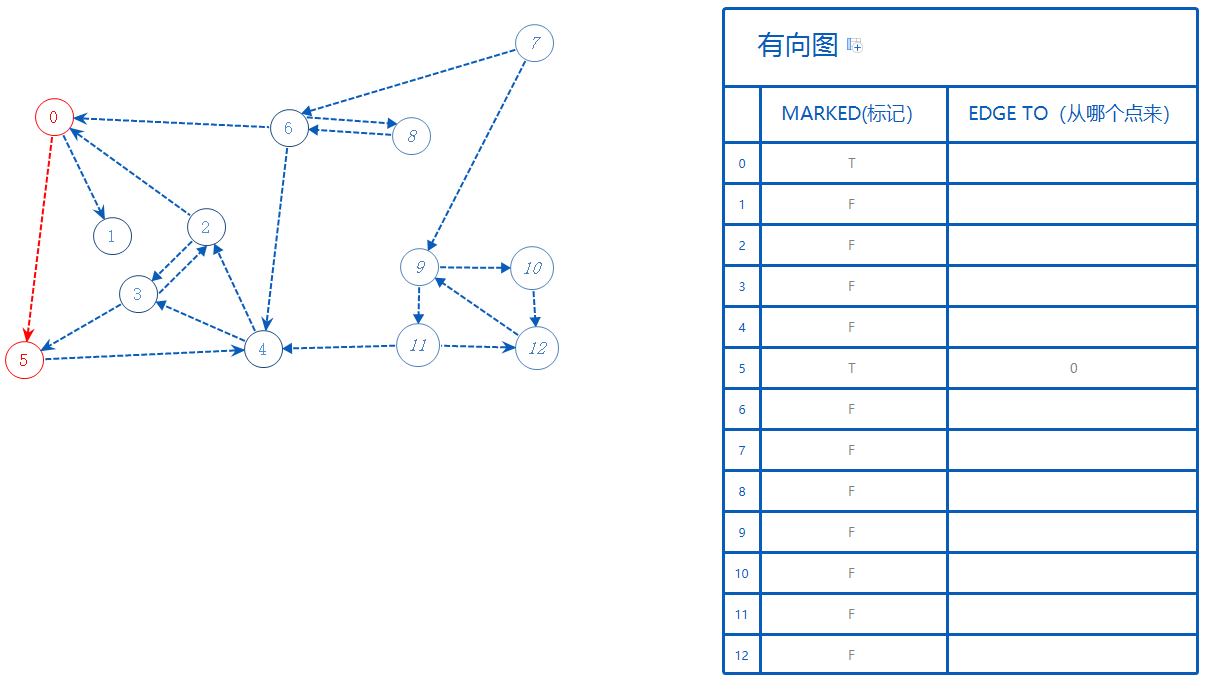
从0开始,先把0标记为True(变红)。
然后0可以去的点有5,1,这些点都还没标记为True,随便选一个:5。
5标记为True。5从0来,故EdgeTo[5]=0;
5只有一个点可以去:4。4还没标记为True,去4。
4标记为True。4从5来,故EdgeTo[4]=5。
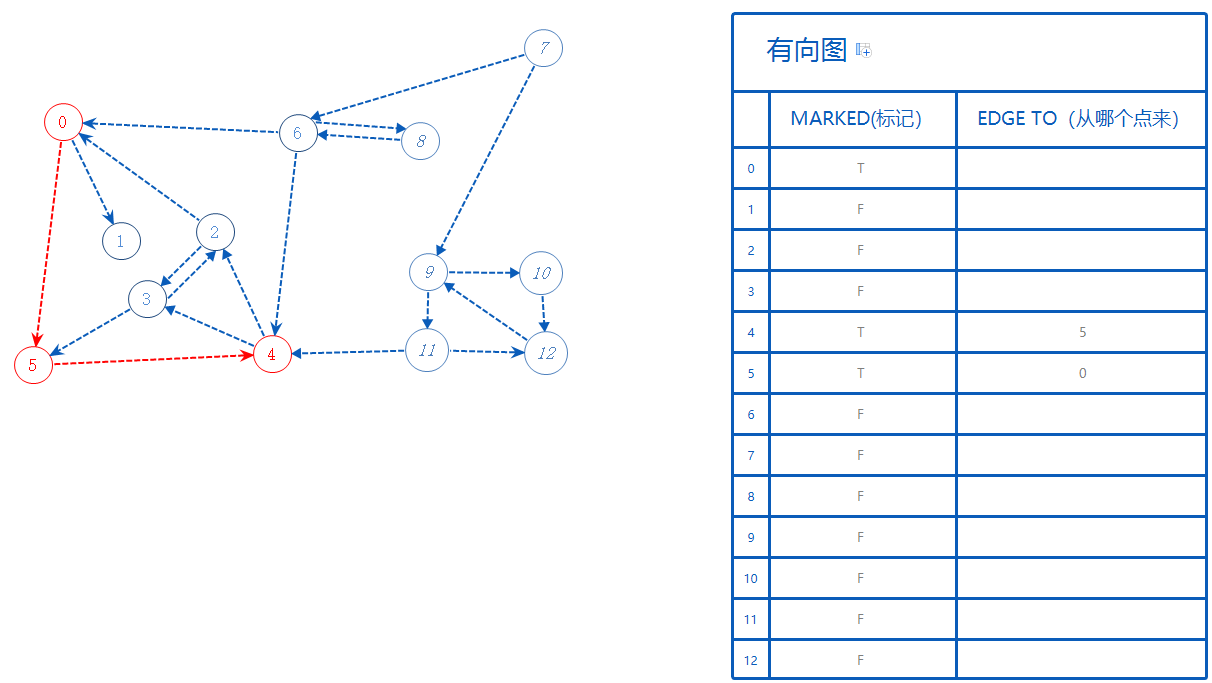
4可以去的点有3,2,这些点都还没标记为True,随便选一个:3。
3标记为True。3从4来,故EdgeTo[3]=4。
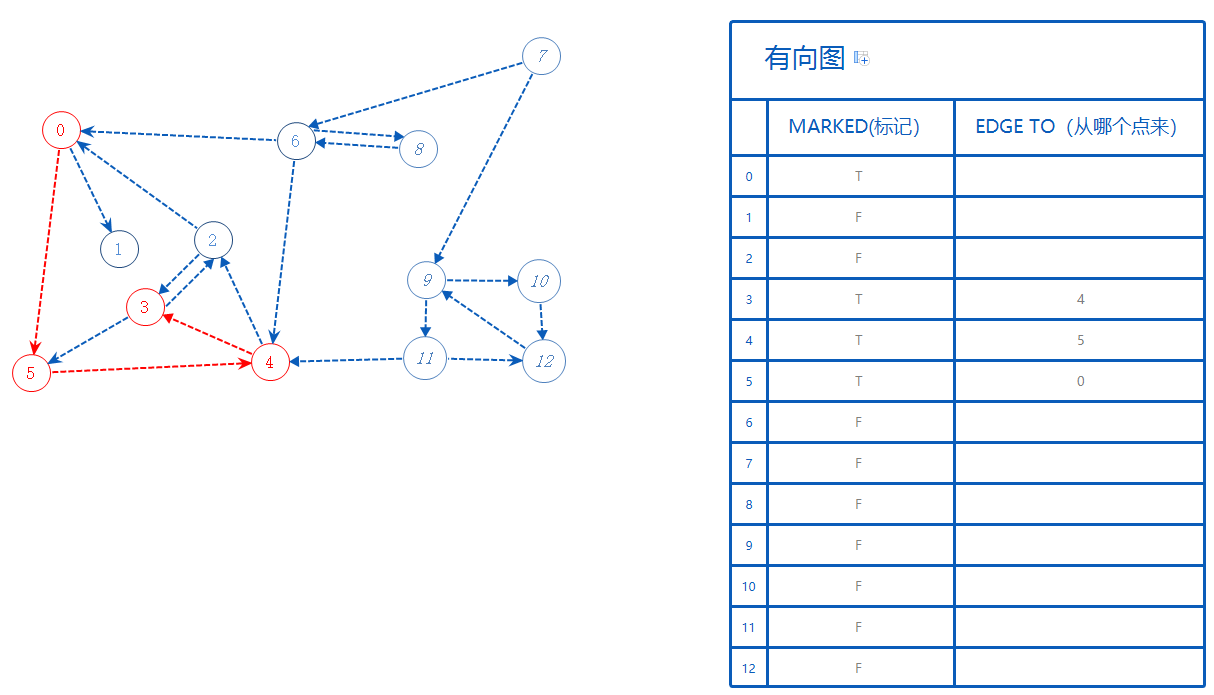
3可以去的点有5,2,5已标记,不管。2没标记,只能去2。
2标记为True。2从3来,故EdgeTo[2]=3。
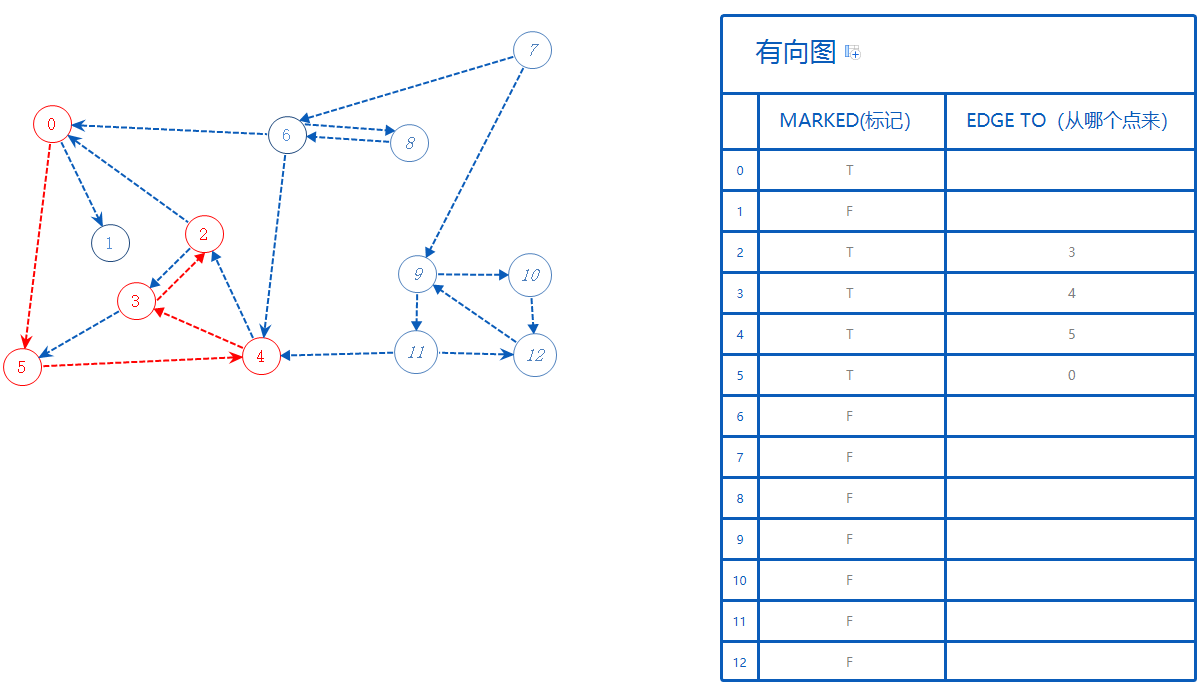
2可以去的点有0,0已标记,不管。2无路可走,返回上一个分支3。
3无路可走,返回上一个分支4。
4无路可走,返回上一个分支5。
5无路可走,返回上一个分支0。
0还有一个点可以去:1。
1标记为True。1从0来,故EdgeTo[1]=0。
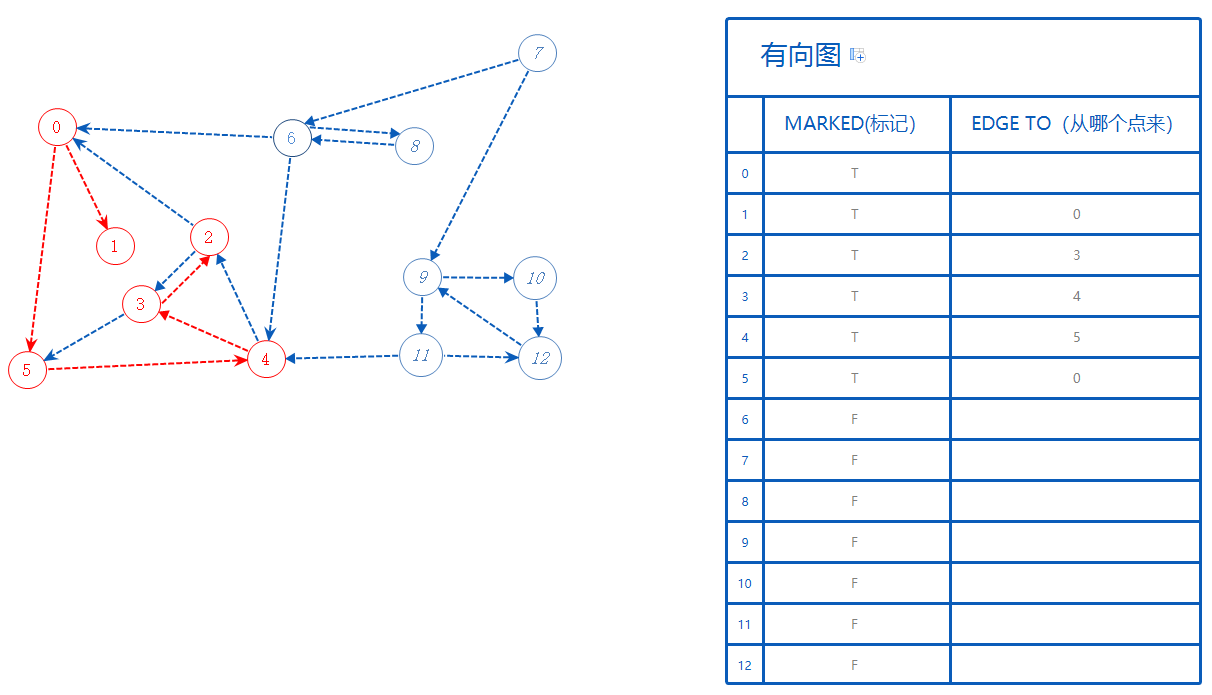
1无路可走,返回上一个分支0。
0无路可走,且无上一个分支,此部分结束。
查找标记为F的其它点,随便选一个来走,如7。
重复上述过程,直到所有点标记为T为止。
通用思路也呼之欲出了,见代码:

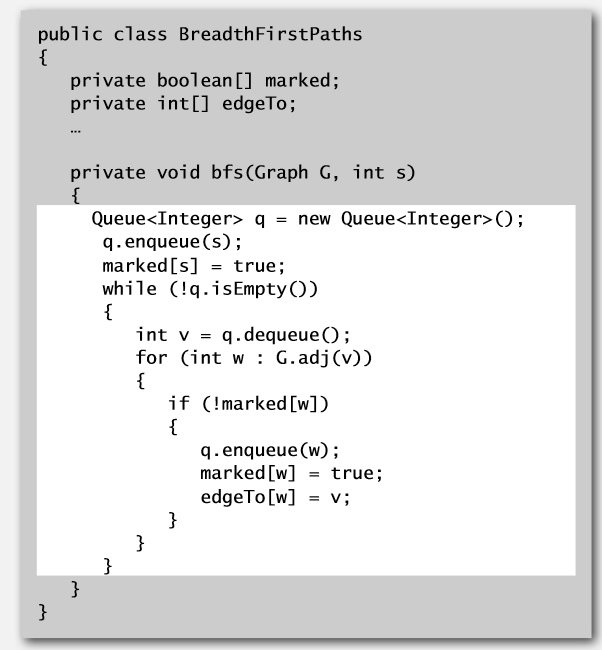
3. 广度优先搜索(breadth-first search)
有向图的深度优先搜索与无向图的深度优先搜索基本一样。具体详细内容可以去无向图那里去看,这里讲的会比较快。
新建队列A。
从0出发(从哪个点开始可以根据需求来决定。),0先标红。0进队列A。
队列A输出一个值:0。
0可以去的点有1,5。1,5全部标红,1,5输进队列A。
队列A输出一个值:1。1没有可以去的点,不管。
队列A输出一个值:5。5可以去的点有4,4标红,4进队列A。
队列A输出一个值:4。4可以去的点有2,3;2,3标红,2,3进队列A。

队列A输出一个值:2。2可以去0,3,但它们都是已标记的,不管。
队列A输出一个值:3。3可以去2,5,但它们都是已标记的,不管。
队列A为空,此部分处理完成。
其它部分也是相同处理方法,DistTo要小心处理,一般要遍历全部的时候,DistTo是不需要的。DistTo一般用于寻找两个点之间的最短距离与路线。
代码与无向图的一样:
4. 拓扑排序(Topological Sort)
一、什么是拓扑排序?
先从一个例子中直观地感受一下:左图是有向图,右图是这个有向图拓扑排序后形成的拓扑序列。(当然,这个拓扑序列是竖着的还是横着的都没所谓,怎么好看怎么来。)
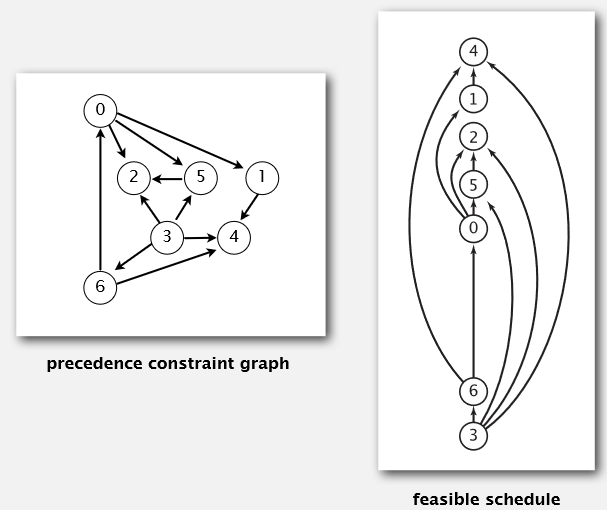
在现实生活中,很多任务是有先决条件的,例如冲一杯咖啡,我们需要先做4个前提任务:
a.水烧开
b.把开水倒入杯子中
c.把咖啡冲剂倒入杯子中
d.把杯子里面的东西搅匀
b和c的顺序没所谓,a要在b之前完成,d要在a,b,c之后才能进行。如果把这些任务拓扑排序:
图中e是喝咖啡。

由上图可知,要完成e需先完成d;要完成d需先完成b和c;要完成b需先完成a。
像这样,拓扑序列可以把一个大任务分成若干小任务,这是做大型项目所需要的,并且任务流程十分清晰。
拓扑序列也可以在许多地方有所作为,这里不一一列出,有兴趣的可自行搜索。
下面将介绍如何对一个有向图进行拓扑排序。
二、如何进行拓扑排序?
一般来说,我们只会对有向无环图(DAG, Directed Acyclic Graph)进行拓扑排序,这里的无环是指无内部循环。
我们举一个有内部循环的例子:
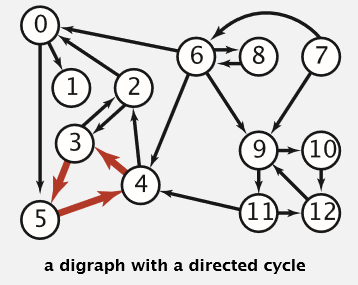
此例子中,要完成5需要先完成3;要完成3需要先完成4;要完成4需要先完成5。
试想下,如果现实生活中有个任务是3,4,5这种结构的,那么这个任务如何完成?
但是,如果对这个有向有环图进行拓扑排序,会有什么效果?答案就是会把这个循环的部分(强联系体)看成一个点,然后这个点与其它没循环的点形成拓扑序列。这个将在下面介绍强联系体的时候讲到。
接下来,我们来看一下如何对有向无环图进行拓扑排序,需要用到栈(Stack),不熟悉的,建议先去看一下栈。
记住,栈是后进先出的。拓扑排序就是进行一次深度优先搜索。
从例子入手:创建栈A
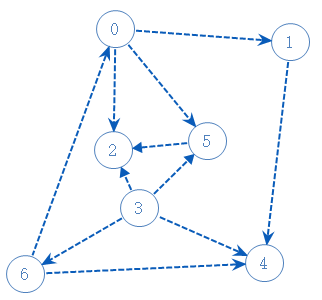
从0出发,0有3个可以去的点:2,5,1;随便选一个:2:
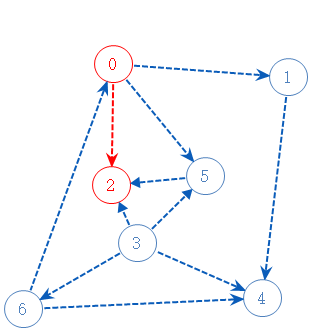
2没有可以去的点,把2加进栈A,返回上一个分支0;
0还有两个可以去的点,随便选一个:5;
5可以去2,但2已标记,不管;把5加进栈A,返回上一个分支0;
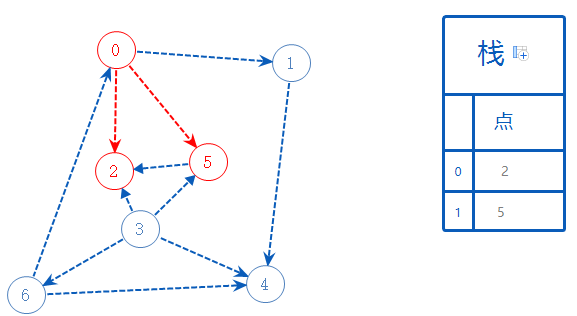
0还有一个可以去的点:1;去1;
1可以去4;去4;
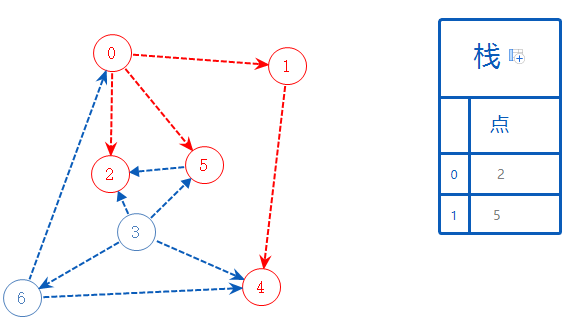
4无路可去,加进加进栈A,返回上一个分支1;
1无路可去,加进加进栈A,返回上一个分支0;
0无路可去,加进栈A,无上一个分支,去找其它未被标记的值,随便选一个:6;
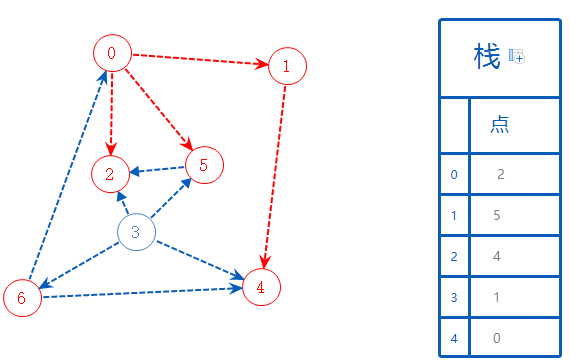
6可以去的点都标记了,无路可去且无上一个分支,加进栈A,去找其它未被标记的值:3
3可以去的点都标记了,无路可去且无上一个分支,加进栈A,没其它未被标记的值,搜索结束。
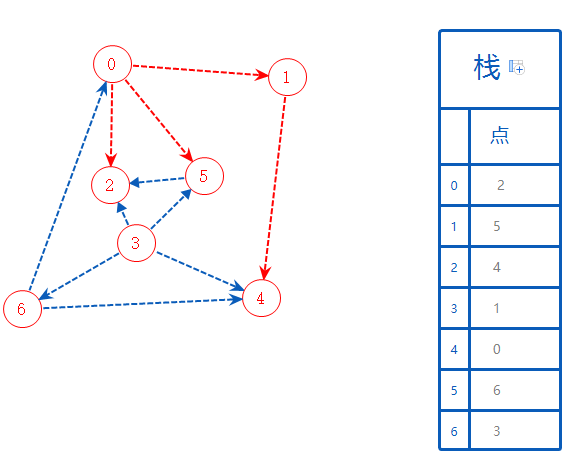
把栈的值逐一输出(后进先出!),得到拓扑序列:3,6,0,1,4,5,2。你或许会发现这个图与一开始给的不一样。其实这个区别就是先把开水倒入杯子中还是先把咖啡冲剂倒入杯子中的区别。本质上是一样的。
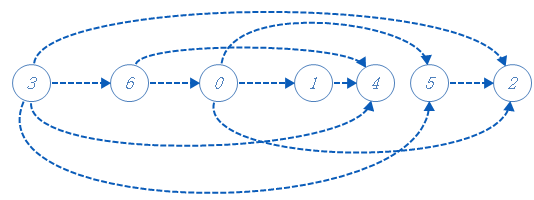
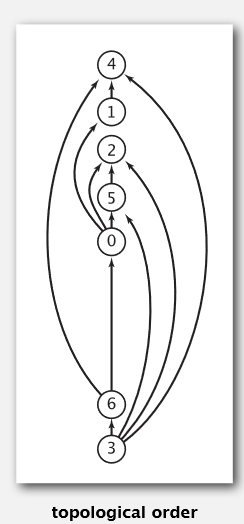
总结一下通用思路就是:对一个有向无环图进行一次深度优先搜索。把无路可去的点依次加入到栈中,搜索结束后,把栈的点逐一输出,得到拓扑序列。
可以想到,代码只是在深度优先搜索的代码中加入少量代码:
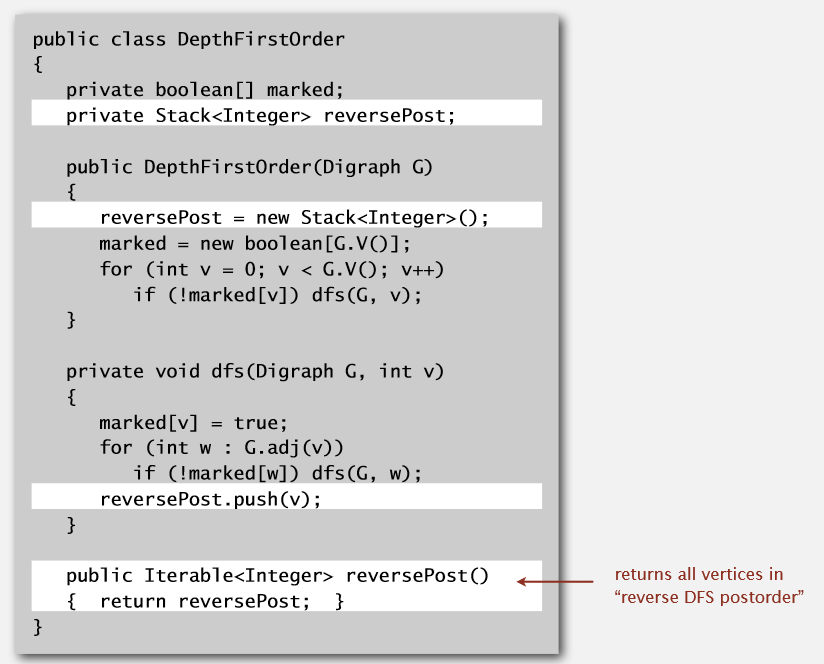
5. 强联系(Strong Components)
一、什么是强联系?
上文提及,有向图的强联系是与无向图的组别(Group)相对应的。
如果一堆点中,点A可以去点B(间接或直接),且点B可以去点A(间接或直接),则点A与点B是强联系。
例如:
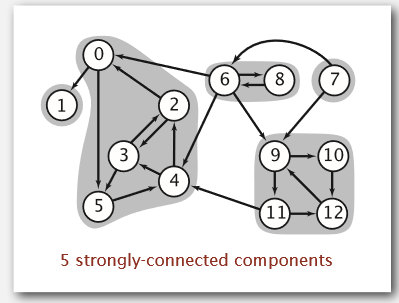
这个图中,0,2,3,4,5互为强联系,这些强联系形成了一个强联系体。要想快速知道给定的两个点是否是强联系,只需检查它们是否同属一个强联系体即可。
二、如何把一个有向图划分成数个强联系体?
这个问题困扰了众多算法研究者多年,这里将介绍一种相对简单的算法:Kosaraju-Sharir算法(也称Kosaraju算法)
此算法由S. Rao Kosaraju在19世纪80年代提出。
我们将进行两次深度优先搜索,第一次是把有向图的所有方向反过来,然后进行拓扑排序,得到一个拓扑序列。
然后根据这个拓扑序列,按原来的有向图的方向进行深度优先搜索,并得出强联系体。
从例子入手:
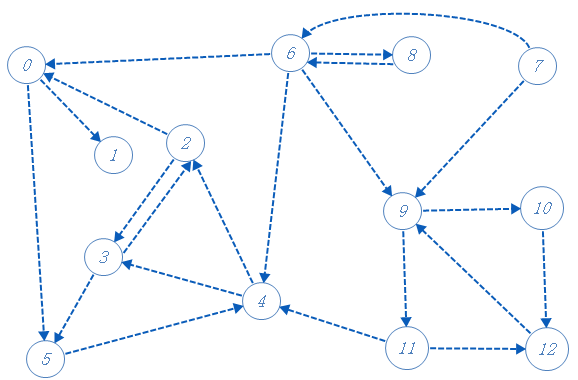
先把有向图反过来:
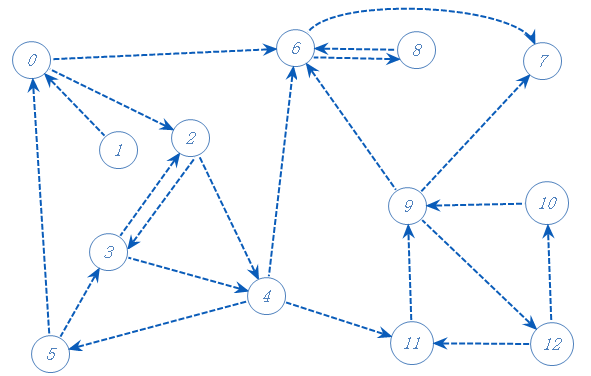
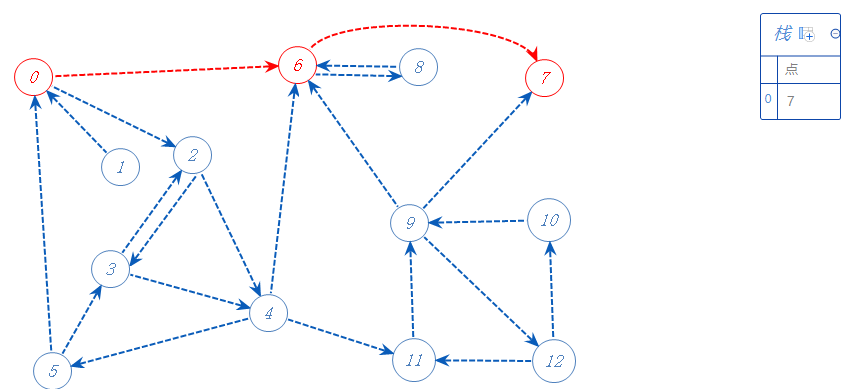
从0开始,0有两个可以去点2,6;随便选一个:6
6有两个可以去的点8,7;随便选一个:7
7无路可走,加入栈A中,返回上一个分支点6。
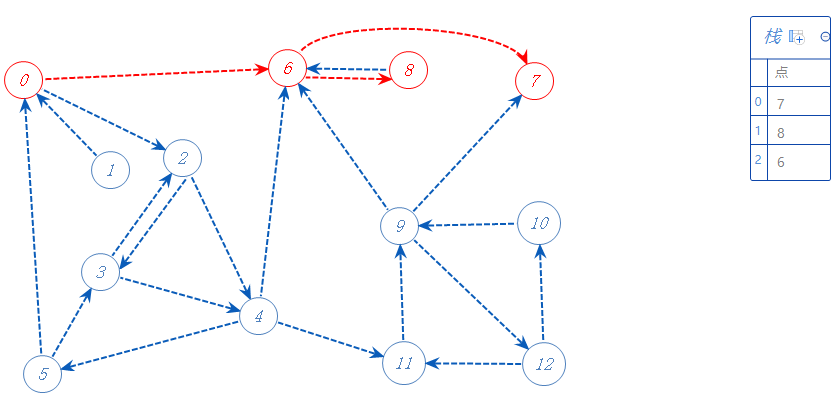
6还可以去8;
8可以去6,但6已经标记,不管;8无路可走,加入栈A,返回上一个分支点6。
6无路可走,加入栈A,返回上一个分支点0。
0还可以去2;
2两个可以去的点3,4;随便选一个:3;
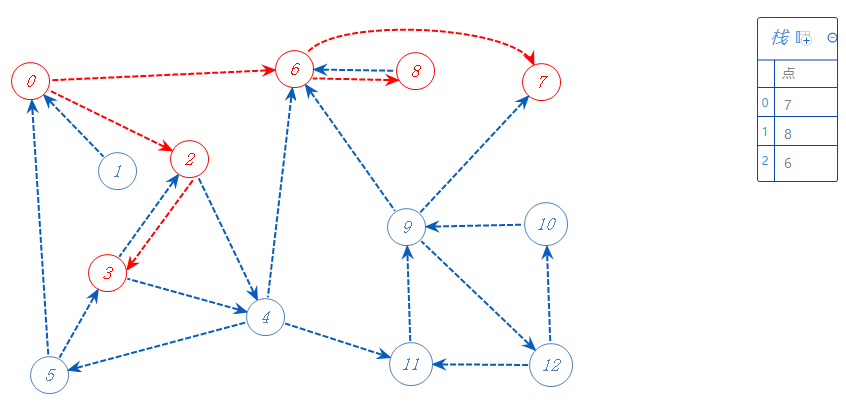
3可以去2,4,但2以标记,不去;去4;
4有三个可以去的点5,6,11;6已标记,不去;剩下的随便选一个:5;
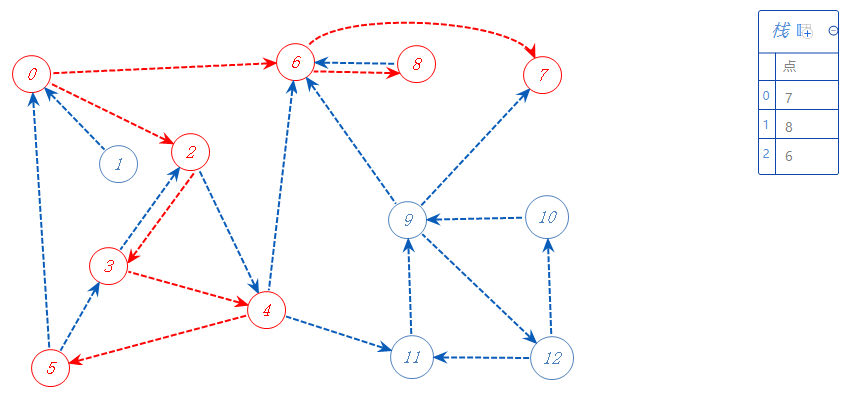
5可以去的点都标记了,无路可走,加入栈A,返回上一个分支点4。
4还可去11,去11;
11可以去9,去9;
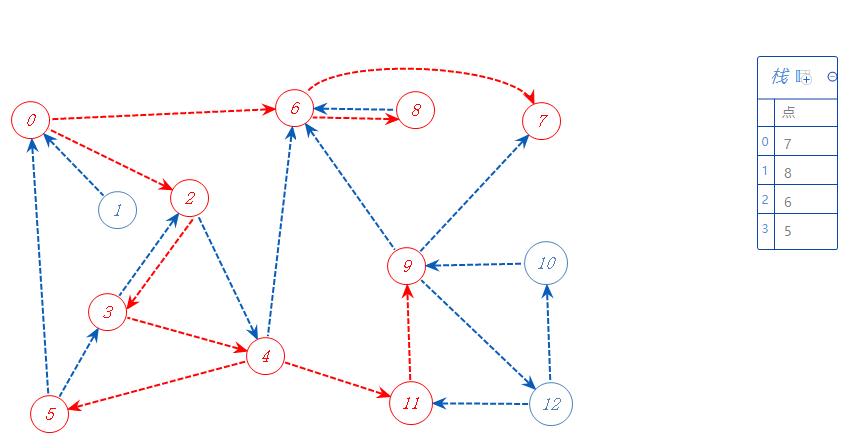
9可以去12,去12;
12可以去11,10,但11已标记,不去,故去10;
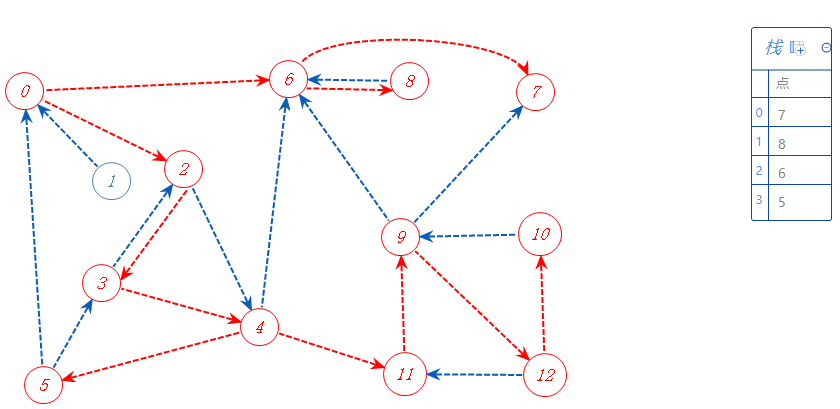
10可以去的点都标记了,无路可走,加入栈A,返回上一个分支点12。
12可以去的点都标记了,无路可走,加入栈A,返回上一个分支点9。
9可以去的点都标记了,无路可走,加入栈A,返回上一个分支点11。
11可以去的点都标记了,无路可走,加入栈A,返回上一个分支点4。
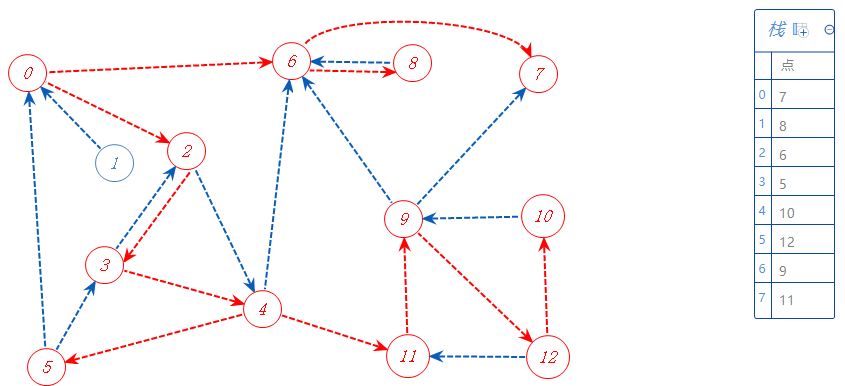
4可以去的点都标记了,无路可走,加入栈A,返回上一个分支点3;
3可以去的点都标记了,无路可走,加入栈A,返回上一个分支点2。
2可以去的点都标记了,无路可走,加入栈A,返回上一个分支点0。
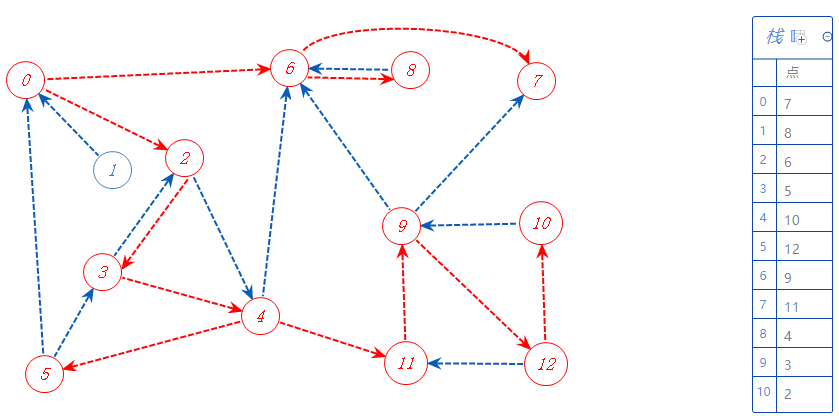
0可以去的点都标记了,无路可走,加入栈A,无上一个分支点,找还没标记的点1,去1。
1可以去的点都标记了,无路可走,加入栈A,无上一个分支点,无还没标记的点,搜索结束。
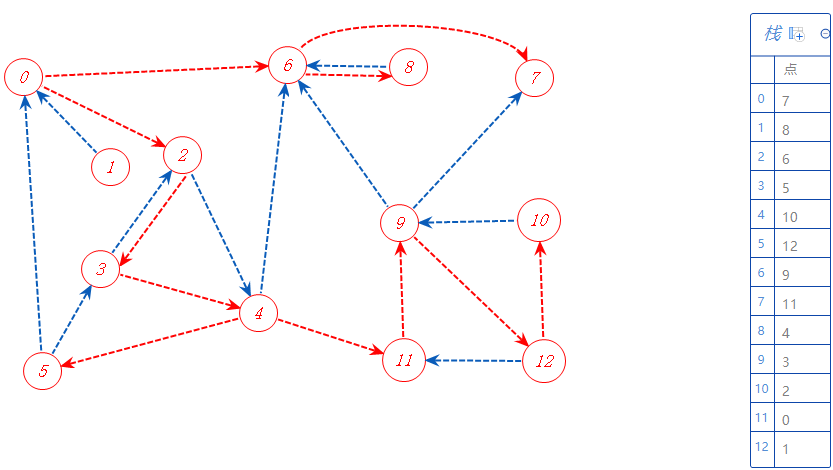
栈逐一输出数值,得到反拓扑序列(因为是反的有向图):1,0,2,3,4,11,9,12,10,5,6,8,7
当有向图有内部循环(即强联系体)时,这个拓扑序列怎么理解?见下图
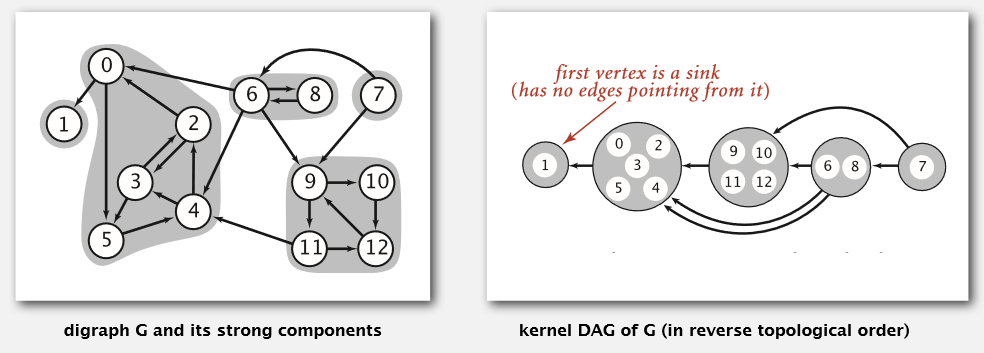
每个强联系体可以看作是一个整体,然后所有整体形成拓扑序列。
然后我们将根据这个拓扑序列,按原来的有向图的方向进行深度优先搜索:
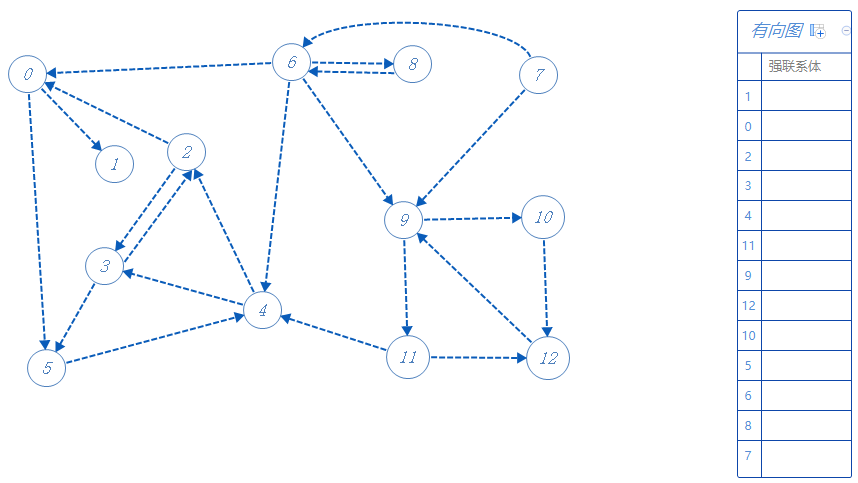
根据反拓扑序列,从1开始;
1无路可去,属于强联系体0;
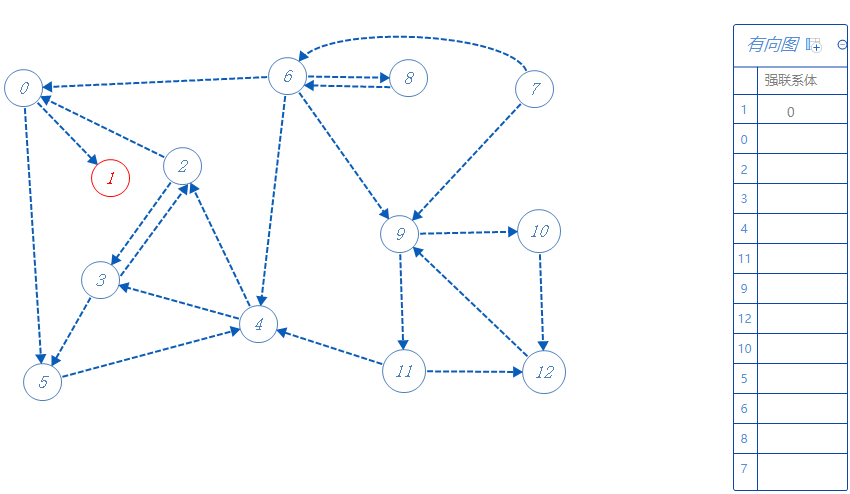
根据反拓扑序列顺序寻找未被标记的点,下一个去0,0属于强联系体1,0可以去1,5,但1已标记,不去,故去5;
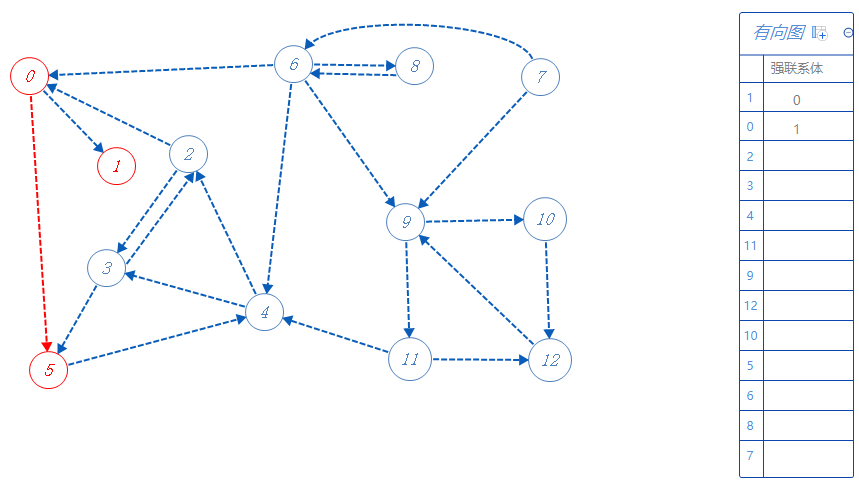
5属于强联系体1,可以去4,去4;
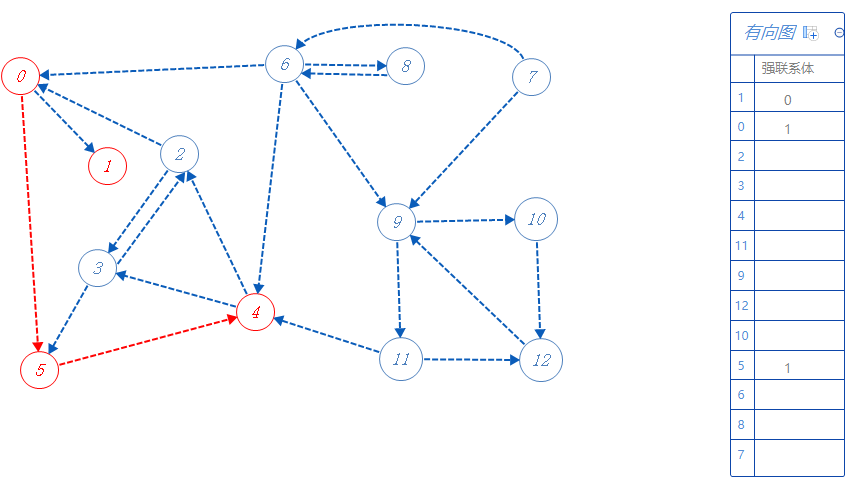
4属于强联系体1,可以去2,3,随便选一个:2;
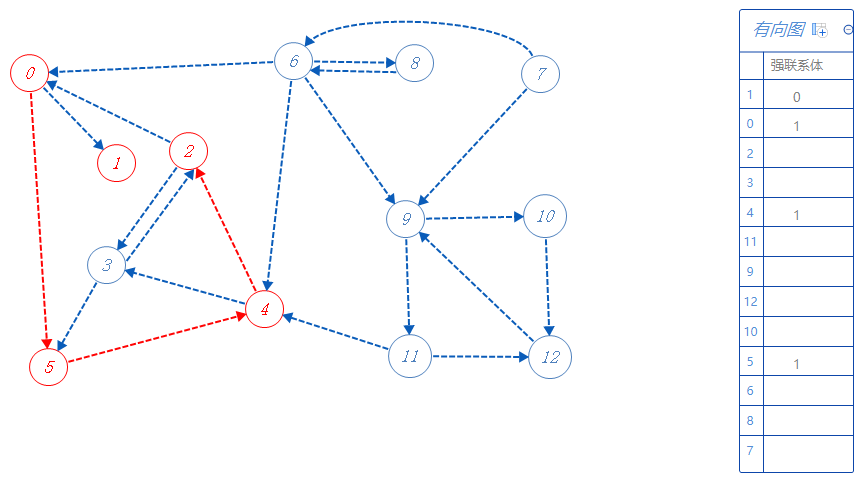
2属于强联系体1,可以去0,3,但0已标记,不去,故去3;
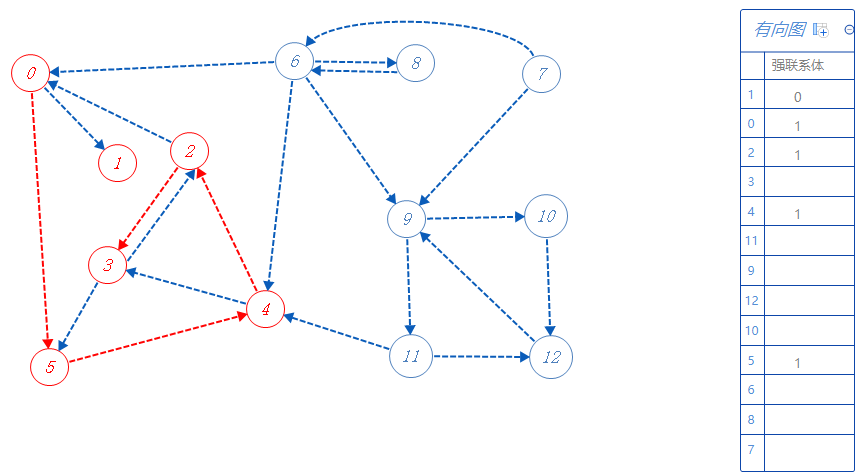
3属于强联系体1,可以去的点都标记了,无路可走,返回上一个分支点2。
2可以去的点都标记了,无路可走,返回上一个分支点4。
4可以去的点都标记了,无路可走,返回上一个分支点5。
5可以去的点都标记了,无路可走,返回上一个分支点0。
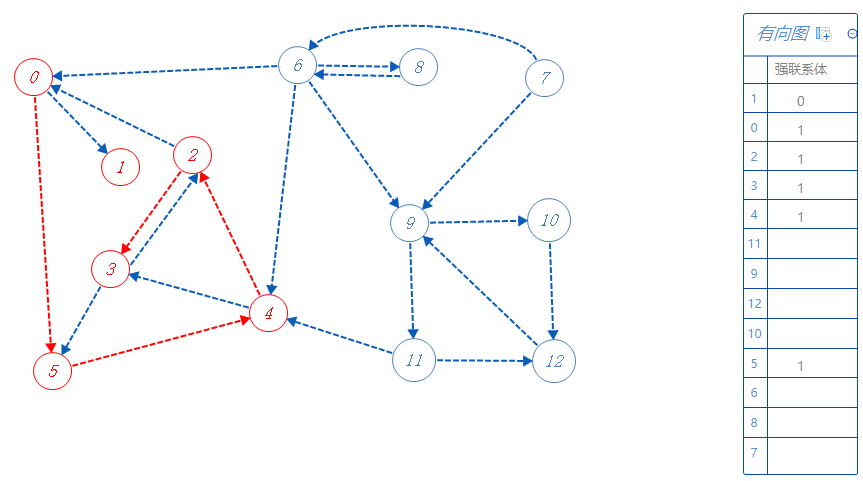
0可以去的点都标记了,无路可走,无上一个分支点,根据反拓扑序列顺序寻找未被标记的点,下一个去11;
11属于强联系体2,可以去12,4,但4已标记,不去,故去12;
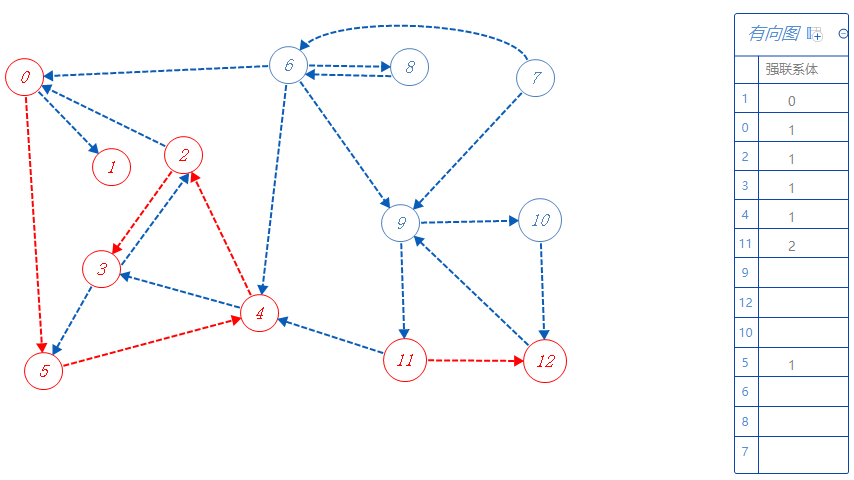
12属于强联系体2,可以去9,去9;
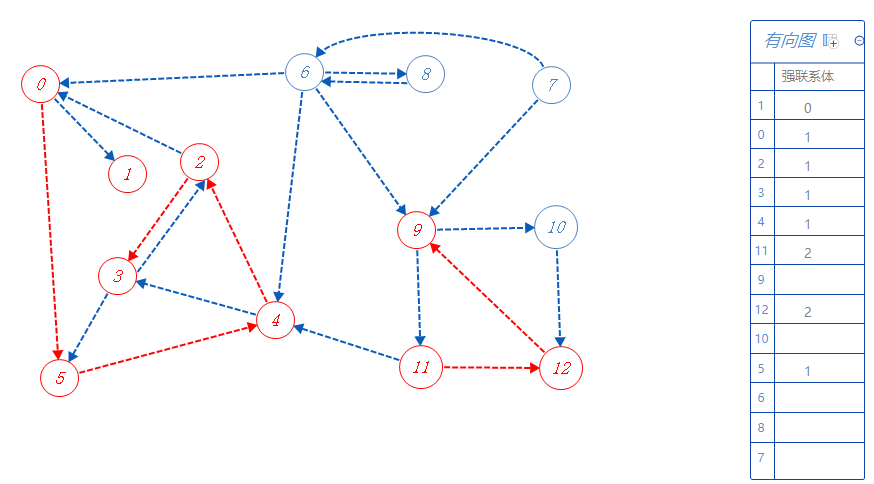
9属于强联系体2,可以去10,11,但11已标记,不去,故去10;
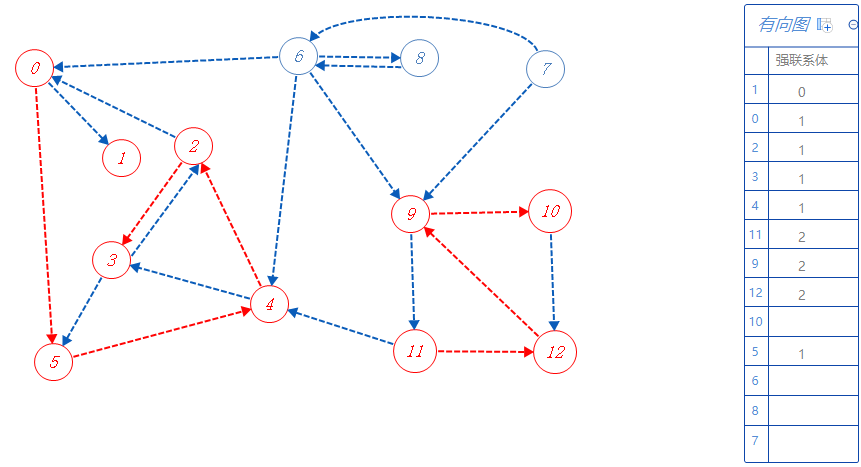
10属于强联系体2,可以去的点都标记了,无路可走,返回上一个分支点9。
9可以去的点都标记了,无路可走,返回上一个分支点12。
12可以去的点都标记了,无路可走,返回上一个分支点11。
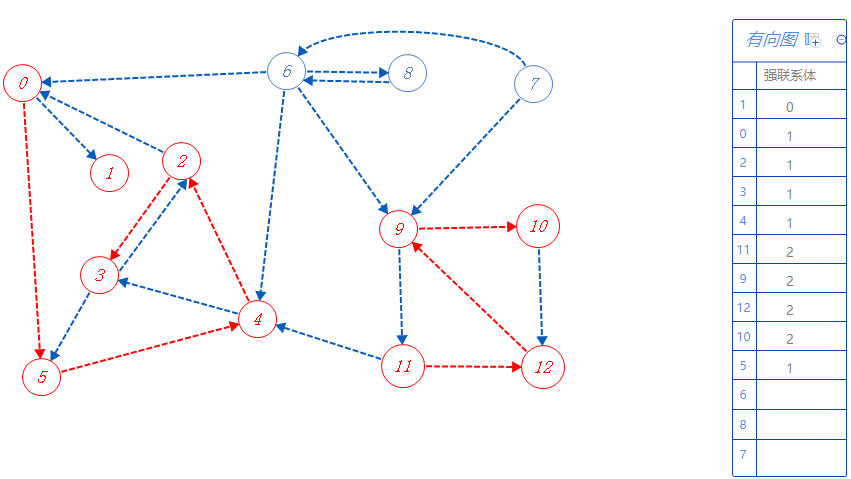
11可以去的点都标记了,无路可走,无上一个分支点,根据反拓扑序列顺序寻找未被标记的点,下一个去6;
6属于强联系体3,可以去8,7,随便选一个:8;
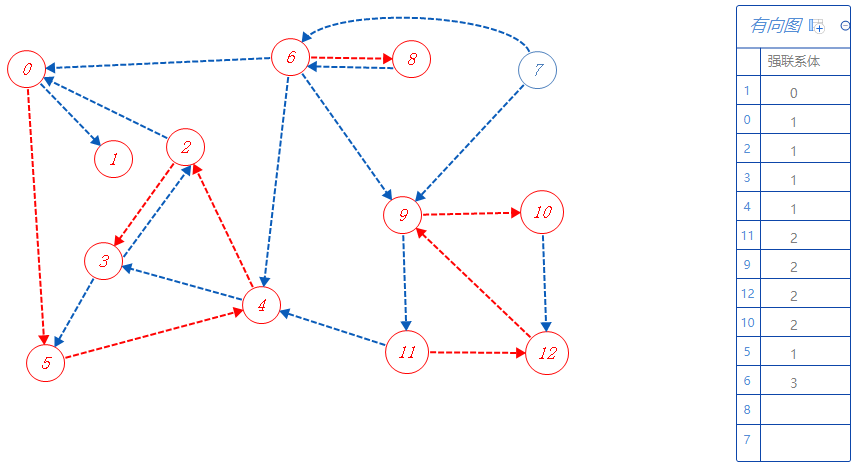
8属于强联系体3,无路可走,返回上一个分支点6。
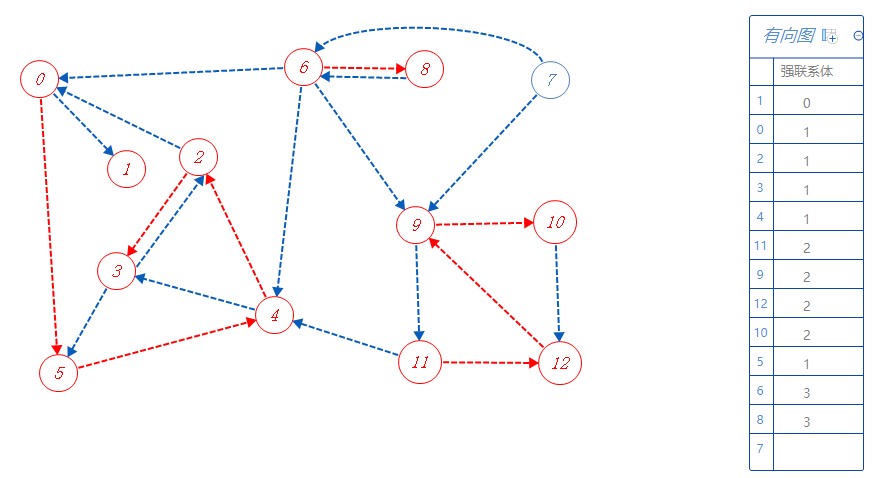
6可以去的点都标记了,无路可走,无上一个分支点,根据反拓扑序列顺序寻找未被标记的点,下一个去7;
7属于强联系体4,无路可走,无上一个分支点,没有其它未被标记的点,结束搜索。
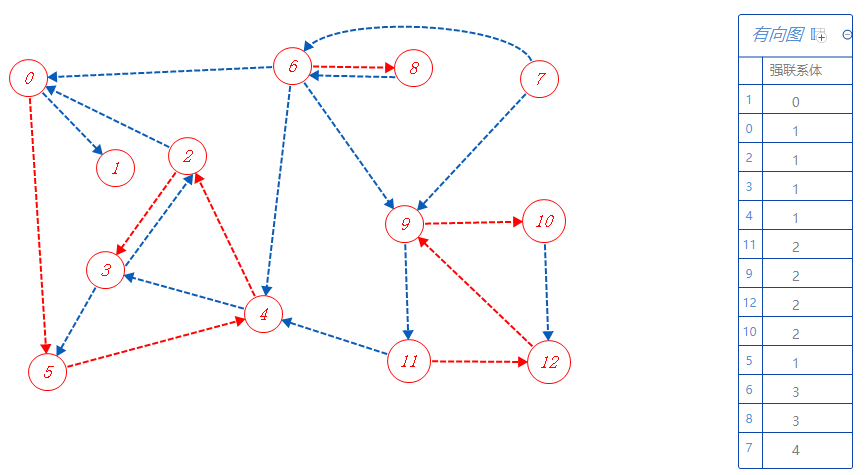
就这样,划分完毕。
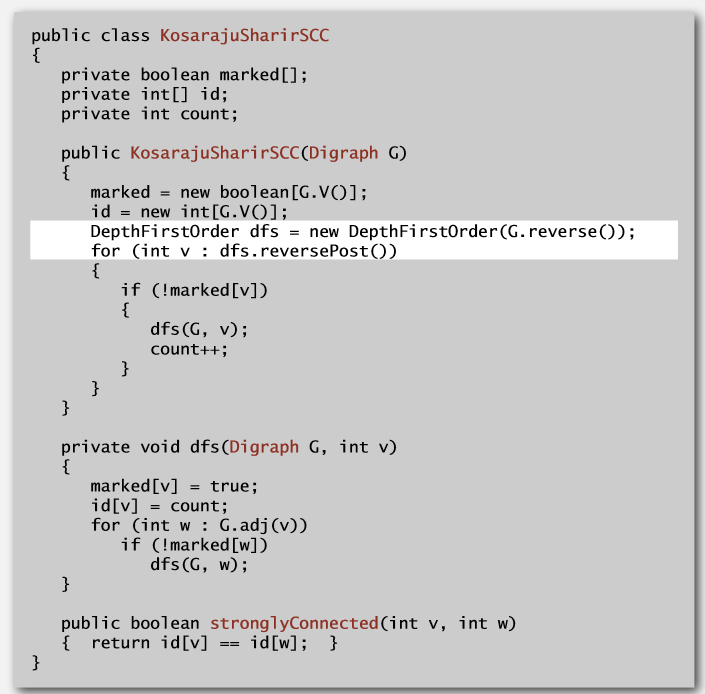
看懂了思路,代码实现应该不难,下面有一份现成的可供参考。
实现代码:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号