K8S中HPA详解
一、 HPA解决的问题
HPA全称是 Horizontal Pod Autoscaler,也就是对k8s的workload的副本数进行自动水平扩缩容(scale)机制,也是k8s里使用需求最广泛的一种Autoscaler机制,在开始详细介绍HPA之前,先简单梳理下k8s autoscale的整个大背景。
k8s被誉为新一代数据中心操作系统(DCOS),说到操作系统我们自然想到其定义:管理计算机的软硬件资源的系统,k8s也一样其核心工作也是管理整个集群的计算资源,并按需合理分配给系统里的程序(以Pod为基础的各种workload)。
其本质是解决资源与业务负载之间供需平衡的问题,随着业务需求和部署规模的增大,k8s集群就要相应扩容计算资源,集群扩容的最直接的办法是新增资源,一般单机器很难垂直扩展(k8s node也不支持),所以一般都是直接增加节点。但是随着机器的不断增加成本也不断加大,而实际上大量服务大部分时间负载很低导致机器的整体使用率很低,一方面业务为了应对每日随机流量高峰会把副本数尽量扩得很高,另一方面业务方并不能准确评估服务实际需要的CPU等资源,也出现大量浪费。
为了解决业务服务负载时刻存在的巨大波动和资源实际使用与预估之间差距,就有了针对业务本身的“扩缩容”解决方案: Horizontal Pod Autoscaler(HPA)和 Vertical Pod Autoscaler(VPA)。
为了充分利用集群现有资源优化成本,当一个资源占用已经很大的业务需要扩容时,其实可以先尝试优化业务负载自身的资源需求配置(request与实际的差距),只有当集群的资源池确实已经无法满足负载的实际的资源需求时,再调整资源池的总量保证资源的可用性,这样可以将资源用到极致。
所以总的来说弹性伸缩应该包括:
- Cluster-Autoscale: 集群容量(node数量)自动伸缩,跟自动化部署相关的,依赖iaas的弹性伸缩,主要用于虚拟机容器集群
- Vertical Pod Autoscaler: 工作负载Pod垂直(资源配置)自动伸缩,如自动计算或调整deployment的Pod模板limit/request,依赖业务历史负载指标
- Horizontal-Pod-Autoscaler: 工作负载Pod水平自动伸缩,如自动scale deployment的replicas,依赖业务实时负载指标
其中VPA和HPA都是从业务负载角度从发的优化,VPA是解决资源配额(Pod的CPU、内存的limit/request)评估不准的问题,HPA则要解决的是业务负载压力波动很大,需要人工根据监控报警来不断调整副本数的问题,有了HPA后,被关联上HPA的deployment,后续副本数修改就不用人工管理,HPA controller将会根据业务忙闲情况自动帮你动态调整。当然还有一种固定策略的特殊HPA: cronHPA,也就是直接按照cron的格式设定扩容和缩容时间及对应副本数,这种不需要动态识别业务繁忙度属于静态HPA,适用于业务流量变化有固定时间周期规律的情况,这种比较简单可以算做HPA的一种简单特例。
二、原理架构
既然是自动根据业务忙闲来调整业务工作负载的副本数,其实HPA的实现思路很容易想到:通过监控业务繁忙情况,在业务忙时,就要对workload扩容副本数;等到业务闲下来时,自然又要把副本数再缩下去。所以实现水平扩缩容的关键就在于:
- 如何识别业务的忙闲程度
- 使用什么样的副本调整策略
kubernetes提供了一种标准metrics接口(整个HPA及metrics架构如下图所示),HPA controller通过这个统一metrics接口可以查询到任意一个HPA对象关联的deployment业务的繁忙指标metrics数据,不同的业务的繁忙指标均可以自定义,只需要在对应的HPA里定义关联deployment对应的metrics即可。
标准的metrics查询接口有了,还需要实现metrics API的服务端,并提供各种metrics数据,我们知道k8s的所有核心组件之间都是通过apiserver进行通信,所以作为k8s API的扩展,metrics APIserver自然选择了基于API Aggregation聚合层,这样HPA controller的metrics查询请求就自动通过apiserver的聚合层转发到后端真实的metrics API的服务端(对应下图的Promesheus adapter和Metrics server)。
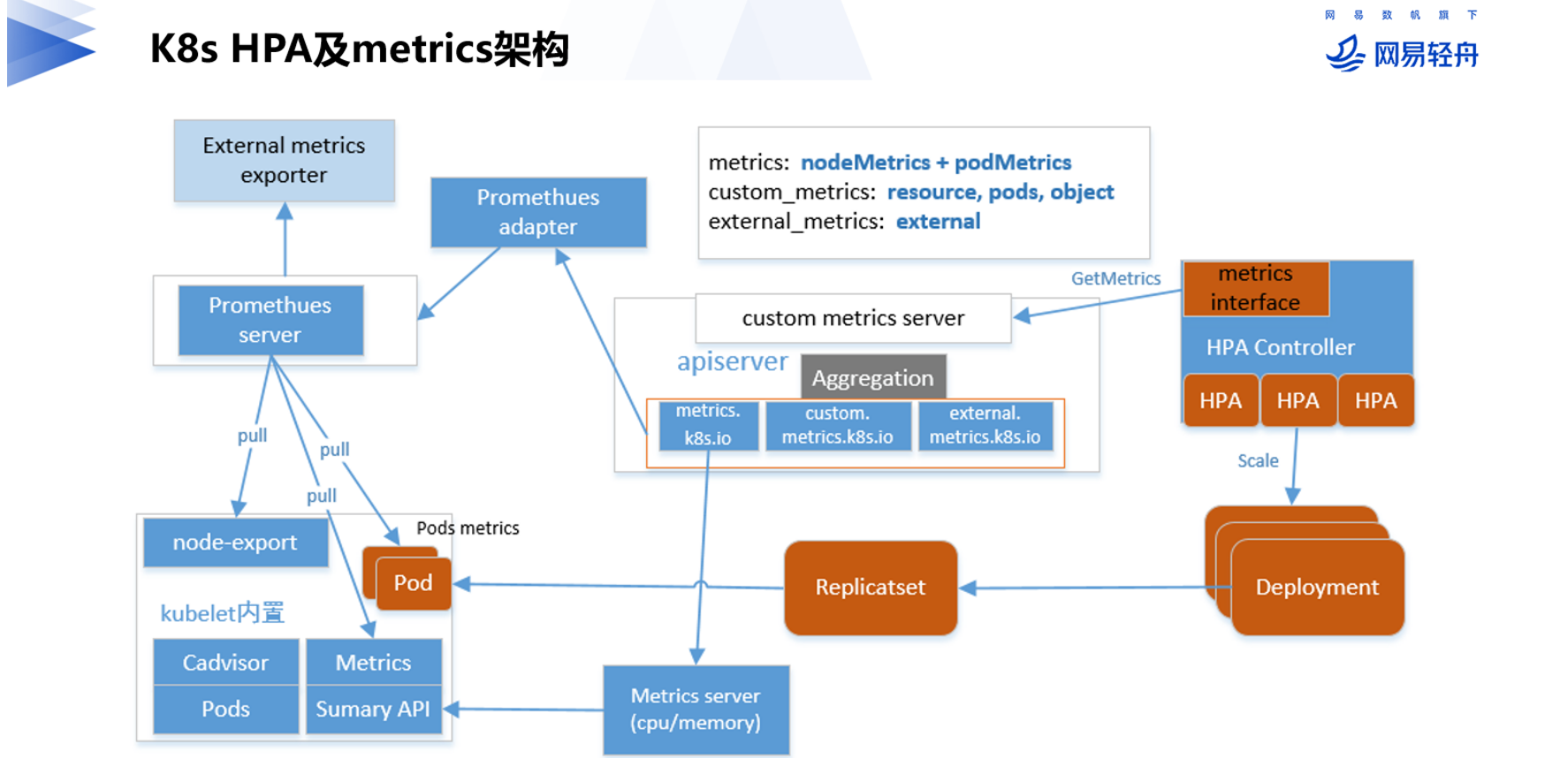
最早的metrics数据是由metrics-server提供的,只支持CPU和内存的使用指标,metrics-serve通过将各node端kubelet提供的metrics接口采集到的数据汇总到本地,因为metrics-server是没有持久模块的,数据全在内存中所以也没有保留历史数据,只提供当前最新采集的数据查询,这个版本的metrics对应HPA的版本是autoscaling/v1(HPA v1只支持CPU指标)。
后来为了适应更灵活的需求,metrics API开始扩展支持用户自定义metrics指标(custom metrics),自定义数据则需要用户自行开发custom metrics server,社区有提供专门的custom adpater框架 custom-metrics-apiserver ,该框架定义了Custom和External的MetricsProvider接口(如下所示),需要自行实现对应的接口。

type MetricsProvider interface {
CustomMetricsProvider
ExternalMetricsProvider
}
type CustomMetricsProvider interface {
// GetMetricByName fetches a particular metric for a particular object.
// The namespace will be empty if the metric is root-scoped.
GetMetricByName(name types.NamespacedName, info CustomMetricInfo, metricSelector labels.Selector) (*custom_metrics.MetricValue, error)
// GetMetricBySelector fetches a particular metric for a set of objects matching
// the given label selector. The namespace will be empty if the metric is root-scoped.
GetMetricBySelector(namespace string, selector labels.Selector, info CustomMetricInfo, metricSelector labels.Selector) (*custom_metrics.MetricValueList, error)
// ListAllMetrics provides a list of all available metrics at
// the current time. Note that this is not allowed to return
// an error, so it is reccomended that implementors cache and
// periodically update this list, instead of querying every time.
ListAllMetrics() []CustomMetricInfo
}
type ExternalMetricsProvider interface {
GetExternalMetric(namespace string, metricSelector labels.Selector, info ExternalMetricInfo) (*external_metrics.ExternalMetricValueList, error)
ListAllExternalMetrics() []ExternalMetricInfo
}
目前社区已经有人基于promethus server的监控数据源,实现看一个promethus adapter来提供 custom metrics server服务,如果需要的自定义指标数据已经在promesheus里有了,可以直接对接使用,否则要先把自定义的指标数据注入到promesheus server里才行。因为HPA的负载一般来源于监控数据,而promesheus又是CNCF标准的监控服务,所以这个promesheus adapter基本也可以满足我们所有自定义metrics的HPA的扩展需求。
讲清楚了metrics,也就解决了识别业务的忙闲程度的问题,那么HPA Controller是怎么利用metrics数据进行扩缩容控制的呢,也就是使用什么样的副本调整机制呢?
如上图右边所示,用户需要在HPA里设置的metrics类型和期望的目标metrics数值,HPA Controller会定期(horizontal-pod-autoscaler-sync-period配置,默认15s)reconcile每个HPA对像,reconcile里面又通过metrics的API获取该HPA的metrics实时最新数值(在当前副本数服务情况下),并将它与目标期望值比较,首先根据比较的大小结果确定是要扩缩容方向:扩容、缩容还是不变,若不需要要进行扩缩容调整就直接返回当前副本数,否则才使用HPA metrics 目标类型对应的算法来计算出deployment的目标副本数,最后调用deployment的scale接口调整当前副本数,最终实现尽可能将deployment下的每个pod的最终metrics指标(平均值)基本维持到用户期望的水平。注意HPA的目标metrics是一个确定值,而不是一个范围。
三、HPA的metrics的分类
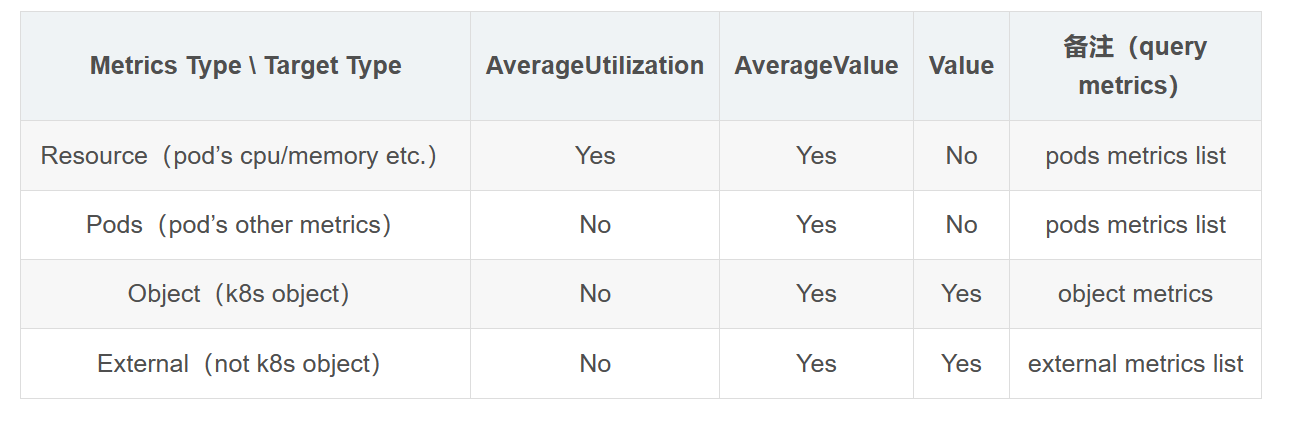
要支持最新的custom(包括external)的metrics,也需要使用新版本的HPA:autoscaling/v2beta1,里面增加四种类型的Metrics:Resource、Pods、Object、External,每种资源对应不同的场景,下面分别说明:
- Resource支持k8s里Pod的所有系统资源(包括cpu、memory等),但是一般只会用cpu,memory因为不太敏感而且跟语言相关:大多数语言都有内存池及内置GC机制导致进程内存监控不准确。
- Pods类型的metrics表示cpu,memory等系统资源之外且是由Pod自身提供的自定义metrics数据,比如用户可以在web服务的pod里提供一个promesheus metrics的自定义接口,里面暴露了本pod的实时QPS监控指标,这种情况下就应该在HPA里直接使用Pods类型的metrics。
- Object类型的metrics表示监控指标不是由Pod本身的服务提供,但是可以通过k8s的其他资源Object提供metrics查询,比如ingress等,一般Object是需要汇聚关联的Deployment下的所有的pods总的指标。
- External类型的metrics也属于自定义指标,与Pods和Object不同的是,其监控指标的来源跟k8s本身无关,metrics的数据完全取自外部的系统。
在HPA最新的版本 autoscaling/v2beta2 中又对metrics的配置和HPA扩缩容的策略做了完善,特别是对 metrics 数据的目标指标值的类型定义更通用灵活:包括AverageUtilization、AverageValue和Value,但是不是所有的类型的Metrics都支持三种目标值的,具体对应关系如下表。
HPA里的各种类型的Metrics和Metrics Target Type的对应支持关系表
四、 HPA的使用说明
先看个最简单的HPA的定义的例子
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
从上面的例子可以看出,HPA的spec定义由三个必填部分组成:
- HPA控制的目标workload,即scaleTargetRef,理论上HPA可以对任意支持scale子接口( sub-resource )的workload做弹性伸缩,不过statefulset一般代表有状态服务,副本不可随便修改,而Job一般代表短生命周期的,所以基本可以认为HPA目前是专门控制deployment的扩缩容的(不建议直接控制RS,否则将无法滚动升级)。
- 弹性扩缩容的上下边界,minReplicas和maxReplicas,也就是说HPA的扩缩容也不能是漫无边际,如果计算出的副本数超过max则统一取maxReplicas,maxReplicas是为了保护k8s集群的资源被耗尽,minReplicas则相反,而且minReplicas必须不大于maxReplicas,但是也要大于0(k8s v1.16之后才放开允许Objetct和External类型的metrics的minReplicas为0,需要apiserver开启–feature-gates mapStringBool HPAScaleToZero=true),两者相等就相当于关闭了自动伸缩功能了,总的来说minReplicas和maxReplicas边界机制避免metrics数据异常导致的副本数不受控,特别是HPA在k8s最新的v1.18版本也依然是alpha特性,强烈建议大家谨慎设置这两个边界。
- metrics指标类型和目标值,在autoscaling/v1里只有targetCPUUtilizationPercentage,autoscaling/v2beta1开始就扩展为metrics数组了,也就是说一个HPA可以同时设置多个类型维度的metrics目标指标,如果有多个HPA 将会依次考量各个指标,然后最终HPA Controller选择一个会选择扩缩幅度最大的那个为最终扩容副本数。在最新的autoscaling/v2beta2版本的HPA中,metrics type共有4种类型:Resource、Pods、Object、External,target里则定义了metrics的目标期望值,这里target的type也有三种类型Utilization,AverageValue和 Value,不同的metrics type都只能支持部分target type(详见上面表格)
- 此外,在autoscaling/v2beta2的HPA的spec里还新增了一个Behavior可选结构,它是用来精确控制HPA的扩容和缩容的速度。
完整的HPA的定义可参考k8s的官方API文档。
默认HPA spec里不配置任何metrics的话k8s会默认设置cpu的Resouce,且目标类型是AverageUtilization value为80%。
五、HPA扩缩容算法具体实现
5.1 算法模型
在HPA控制器里,针对不同类型的metrics和不同metrics下的target 类型,都有独立的计算算法,虽然有很多细节差异,但是总的来说,计算公式可以抽象为:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
例如如果配置 target value 是100m,当前从metrics接口读取到的 metrics value 是 200m,说明最新的副本数应该是当前的 200m/100m=2.0倍, 如果当前副本数为 2,则HPA计算后的期望副本数是2*2.0=4;
而如果当前从metrics接口读取到的 metrics value是 50m,说明最新的副本数应该是 当前的 50m/100m=0.5倍,也就是最终scale的副本数将为1。
当然实际上当前的metrics value并不一定就只有一个值,如果是 Resource或者Pods类型的metrics,实际上 GetMetrics 会返回一批关联的Pods对应的metrics数据,一般需要做一个平均后再与target的metrics的做比较。
此外,为了保证结果尽量精确,metrics的计算都是浮点数计算,但是最终的副本数肯定要是整数,为了统一HPA控制器在最后,都会对计算出的浮点数副本数向上取整,也就是上面公式里最外层的ceil函数。
5.2 扩缩容threshold控制
当然上面的公式也只是纯数学模型,实际工程实现还要考虑很多现实细节问题:比如监控数据可能会有一定的误差,如果GetMetrics里读到数据不稳定就会造成算出的期望副本数不稳定,导致deployment一会扩缩1个副本,一会又扩容1副本。所以为了避免这种问题kube-controller-manager里有个HPA的专属参数 horizontal-pod-autoscaler-tolerance 表示HPA可容忍的最小副本数变化比例,默认是0.1,如果期望变化的副本倍数在[0.9, 1.1] 之间就直接停止计算返回。那么如果相反,某个时间点开始metrics数据大幅增长,导致最后计算的副本数变化倍数很大,是否HPA控制器会一步扩容到位呢? 事实上HPA控制器为了避免副本倍增过快还加了个约束:单次倍增的倍数不能超过2倍,而如果原副本数小于2,则可以一次性扩容到4副本,注意这里的速率是代码写死不可用配置的。(这个也是HPA controller默认的扩缩容速率控制,autoscaling/v2beta2的HPA Behavior属性可以覆盖这里的全局默认速率)
5.3 缩容冷却机制(cooldown delay)
虽然HPA同时支持扩容和缩容,但是在生产环境上扩容一般来说重要性更高,特别是流量突增的时候,能否快速扩容决定了系统的稳定性,所以HPA的算法里对扩容的时机是没有额外限制的,只要达到扩容条件就会在reconcile里执行扩容(当前一次至少扩容到原来的1.1倍)。但是为了避免过早缩导致来回波动(thrashing ),而容影响服务稳定性甚,HPA的算法对缩容的要求比较严格,通过设置一个默认5min(可配置horizontal-pod-autoscaler-downscale-stabilization)的滑动窗口,来记录过去5分钟的期望副本数,只有连续5分钟计算出的期望副本数都比当前副本数小,才执行scale缩容操作,缩容的目标副本数取5分钟窗口的最大值。
总的来说k8s HPA算法的默认扩缩容原则是:快速扩容,谨慎缩容。
5.4 Pod的metrics数据过滤检查机制
一般情况下HPA的数据指标都来自k8s的Pod里,但是实际上每次创建deployment、对deployment做扩缩容,Pod的副本数和状态都会不断变化,这就导致HPA controller在reconcile里获取到的metrics的指标肯定会有一定的异常,比如Pod还没有Running、Pod刚刚启动还在预热期、或者Pod中间临时OOM恰逢采集时刻、或者Pod正处在删除中,这些都可能导致metrics指标缺失。如果有任何 pod 的指标缺失,HPA控制器会采取最保守的方式重新计算平均值, 在需要缩小时假设这些 pod 消耗了目标值的 100%, 在需要放大时假设这些 pod 消耗了0%目标值, 这可以在一定程度上抑制伸缩的幅度。
具体来说,HPA算法里把deployment下的所有Pod的metrics的指标数据分为三类:
ready pods list, deployment下处于Running状态的Pod且HPA controller成功通过GetMetrics获取的pod metrics的列表 ignore pods list, deployment下处于pending状态的Pods或者(仅对Resouce类似的cpu metrics有效)虽然pod running了但controller成功通过GetMetrics获取的pod metrics,但是pod的启动时间在配置的initial-readiness-delay和cpu-initialization-period 保护期内。 missing pods list,deployment下处于running状态的pod(非pending、非failed、非deleted状态)但是HPA controller通过GetMetrics无法获取的pod metrics的列表
在计算pod的平均metrics值的时候,统一把 ignore pods的metrics设置为最小值0,如果HPA扩缩容的方向是扩容,把missing pods的metrics也设置为最小值0,如果是缩容方向则把missing pods的metrics也设置为最大值(如果是Resouce类型,最大值是Pod的request值,否则最大值就是target value)。
六、HPA的scale速度控制
讲解完HPA的原理及具体算法后,最后再重点介绍HPA在扩缩容的速率控制机制。在前面讲过HPA controller里默认扩缩容总原则是:快速扩容,谨慎缩容,扩容上虽然强调快,但是速度却是固定的最大于当前副本数的2倍速度,对于想设置其他倍数或者说想精确控制副本数增量的方式的需求都是不行的;缩容上则仅仅只是靠设置一个集群全局的窗口时间,窗口期过后也就失去控制能力。
为了能更精准灵活地控制HPA的autoscale速度,从k8s v1.18(依赖HPA autoscaling/v2beta2)开始HPA的spec里新增了behavior结构(如下定义)扩展了HPA的scale速度控制策略,该结构支持每个HPA实例独立配置扩缩容的速度,而且还可以单独配置扩容scaleUp和缩容scaleDown使用不同的策略。
在扩容策略ScalingRules里,有个StabilizationWindowSeconds用来记录最近计算的期望副本数,效果跟上面缩容的cooldown delay机制一样,每次都会选择窗口里所有推荐值的最大值,保证结果的稳定性。
Policies是一个HPAScalingPolicy数组,每个HPAScalingPolicy才是真正控制速度的部分:扩缩容计算周期和周期内扩缩容变化的最大幅度,PeriodSeconds周期单位是秒,Percent是设置副本数每次变化的百分比,扩容后副本数是:(1+PercentValue%)* currentReplicas,缩容后副本数是:(1-PercentValue%)* currentReplicas; Pods则是设置每次副本数变化的绝对值。
次外,每个方向还可以设置多个策略,多个策略会同时计算最终副本数,最后结果则是通过SelectPolicy:Max/Min/Disabled做聚合,注意在缩容时Max会选择计算副本数最小的那个,Min会选择计算的副本数最大的那个,Disabled表示禁止这个方向的扩缩容。
type HorizontalPodAutoscalerBehavior struct {
// scaleUp is scaling policy for scaling Up.
// If not set, the default value is the higher of:
// * increase no more than 4 pods per 60 seconds
// * double the number of pods per 60 seconds
ScaleUp *HPAScalingRules
// scaleDown is scaling policy for scaling Down.
// If not set, the default value is to allow to scale down to minReplicas pods, with a
// 300 second stabilization window (i.e., the highest recommendation for
// the last 300sec is used).
ScaleDown *HPAScalingRules
}
type HPAScalingRules struct {
// StabilizationWindowSeconds is the number of seconds for which past recommendations should be
// considered while scaling up or scaling down.
StabilizationWindowSeconds *int32
// selectPolicy is used to specify which policy should be used.
// If not set, the default value MaxPolicySelect is used.
SelectPolicy *ScalingPolicySelect
// policies is a list of potential scaling polices which can used during scaling.
// At least one policy must be specified, otherwise the HPAScalingRules will be discarded as invalid
Policies []HPAScalingPolicy
}
// HPAScalingPolicyType is the type of the policy which could be used while making scaling decisions.
type HPAScalingPolicyType string
const (
// PodsScalingPolicy is a policy used to specify a change in absolute number of pods.
PodsScalingPolicy HPAScalingPolicyType = "Pods"
// PercentScalingPolicy is a policy used to specify a relative amount of change with respect to
// the current number of pods.
PercentScalingPolicy HPAScalingPolicyType = "Percent"
)
// HPAScalingPolicy is a single policy which must hold true for a specified past interval.
type HPAScalingPolicy struct {
// Type is used to specify the scaling policy.
Type HPAScalingPolicyType
// Value contains the amount of change which is permitted by the policy.
Value int32
// PeriodSeconds specifies the window of time for which the policy should hold true.
// PeriodSeconds must be greater than zero and less than or equal to 1800 (30 min).
PeriodSeconds int32
}
HPA的Behavior如果不设置,k8s会自动设置扩缩容的默认配置, 具体内容如下:
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
- type: Pods
value: 4
periodSeconds: 15
selectPolicy: Max
默认配置里分别定义了扩容和缩容的速率策略,缩容按照百分比,每15秒最多减少currentReplicas*100%个副本(但最终不可小于minReplicas),且缩容后的最终副本不得低于过去300s内计算的历史副本数的最大值;扩容则采用快速扩容,不考虑历史计算值(窗口时间为0),每15秒副本翻倍或者每15秒新增4个副本(取最大值),即:max(2*currentReplicas,4)。这个默认Behavior的默认配置是否有点似曾相似的感觉,没错它跟HPA没有Behavior时的默认快速扩容,缩容的策略是完全一致的。
6.1不同扩缩容速率需求场景下的behavior用法举例
场景1:扩容越快越好
如果业务希望能尽快的扩容,可以配置大的 percent值,可以按照如下配置:
behavior:
scaleUp:
policies:
- type: Percent
value: 900
periodSeconds: 60
假如 deployment的副本数最开始是1,那么每隔60s的的极限扩容副本数的变化如下:
1 -> 10 -> 100 -> 1000
也就是每个扩容period都是(1+900%)=10倍的速度,不过最大副本数依然不可用超过HPA 的 maxReplicas上界,缩容则使用默认行为。当然Percent类型可能对资源消耗波动特别大,如果希望资源消耗可控,可以按绝对副本数来Pods类型来配置。
场景 2: 扩容越快越好但要逐步缩容
当业务希望能尽快的扩容,但是缩容需要缓慢一些时,可以使用如下配置:
behavior:
scaleUp:
policies:
- type: Percent
value: 900
periodSeconds: 60
scaleDown:
policies:
- type: Pods
value: 1
periodSeconds: 600
假如 pod 最开始数量为 1,那么扩容路径如下:
1 -> 10 -> 100 -> 1000
同时,缩容路径如下 (每 10 分钟缩容一次,每次减少一个 pod):
1000 -> 1000 -> 1000 -> … (another 7 min) -> 999 (最小不低于minReplicas)
场景 3: 逐步扩容、正常的缩容
当希望缓慢的扩容、正常的缩容,可以使用如下配置
behavior:
scaleUp:
policies:
- type: Pods
value: 1
periodSeconds: 600
把缩容的百分比或者pod 都置为 0,那么就永远不会缩容。
或者直接设置 selectPolicy: Disabled。
behavior:
scaleDown:
selectPolicy: Disabled
场景 4: 正常扩容、不要缩容
如果希望能正常的扩容,但是不要自动缩容,可以使用如下配置:
behavior:
scaleDown:
policies:
- type: Percent 或 Pods
value: 0
periodSeconds: 600
把缩容的百分比或者pod 都置为 0,那么就永远不会缩容。
或者直接设置 selectPolicy: Disabled。
behavior:
scaleDown:
selectPolicy: Disabled
场景 5: 延后缩容
一般在流量激增时,都希望快速扩容应对,那么发现流量降低是否应该立马缩容呢,加入只是临时的流量降低呢,这样就可能导致短时间反复的扩缩容,为了避免这种情况,缩容时应该更谨慎些,可以使用延迟缩容机制:delaySeconds(这个跟 kube-controller-manager 的 horizontal-pod-autoscaler-downscale-stabilization 非常类似,但是这个参数是全局的,如果HPA有配置优先使用delaySeconds),配置如下:
behavior:
scaleDown:
policies:
- type: Pods
value: 5
periodSeconds: 600
那么,每次缩容最多减少 5 个 pod,同时每次缩容,至少要往前看 600s 窗口期的所有推荐值,每次都从窗口期中选择最大的值。这样,除非连续600s的推荐值都比之前的最大副本数小,才开始缩容。
七、总结
总的来说,从k8s v1.18开始HPA的机制已经算比较灵活了,在扩缩容识别指标上可以使用Pod的系统cpu、内存指标,也可以Pods自身暴露的自定义metrics指标,还可以支持外部的业务指标;在具体自定义实现上也提供了标准的扩展框架,还有社区其他人贡献的promesheus adapter。在扩缩容速度上也通过相对百分比和绝对 Pods数变化,可以独立控制单位时间内最大的扩容和缩容,此外还通过自定义窗口时间机制保证副本变化的稳定性。
需要说明下,HPA特性还依然处于非正式GA版本,社区相关的issue有些没有解决,包括HPA缩容的最小副本不允许为0(Resouce和Pods类型的metrics如果在pod副本为0时,将采集不到metrics,需要依赖额外的流量激活机制,Knative集成了service mesh有对流量的劫持所以可以直接实现0副本),参数控制粒度还不够灵活,而且HPA controller的reconcile循环不支持多线程并发,所以也一定程度上影响了一个k8s集群内HPA的对象数过多的时效性,随着k8s HPA关注和使用人数的增多,相信这些问题也都会逐步优化掉。
网易轻舟之前就已经集成了基于业务容器的CPU、内存指标的HPA,网易传媒业务很早就开始在生产环境使用这个特性,不过随着离线业务的容器化迁移和离在线混部的广泛使用,传媒业务团队也提出了希望根据任务队列的大小这样的外部指标来进行弹性伸缩,所以轻舟也开始支持自定义metrics的HPA的功能,目前相关配套已经开发完毕,正逐步应用在网易内部业务中,未来也将会跟随轻舟新版本对外发布。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」