正则表达式
一、正则表达式的概述
1、概念
正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正则表达式是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串。
2、作用
通常用于判断语句中,用来检查某一字符串是否满足某一格式
• 正则表达式是由普通字符与元字符组成
• 普通字符包括大小写字母、数字、标点符号及一些其他符号
• 元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式
3、可达到的目的
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”)
- 可以通过正则表达式,从字符串中获取我们想要的特定部分
二、基础正则
1、基础正则常见元字符:(支持的 工具: grep、 egrep、 sed、awk)
\ : 转义字符,用于取消特殊符号的含义
^ : 匹配字符串开始的位置
$ : 匹配字符串结束的位置
. : 匹配除\n之外的任意的一个字符
* : 匹配前面子表达式0次或者多次
[list] : 匹配list列表中的一个字符
[^list] : 匹配任意非list列表中的一个字符
{n} : 匹配前面的子表达式n次
{n,} : 匹配前面的子表达式不少于n次
{n,m} : 匹配前面的子表达式n到m次
注: egrep、 awk使用{n}、{n,}、 {n, m}匹配时“{}"前不用加“\”
2、实例操作
2.1 * 匹配前面子表达式0次或者多次
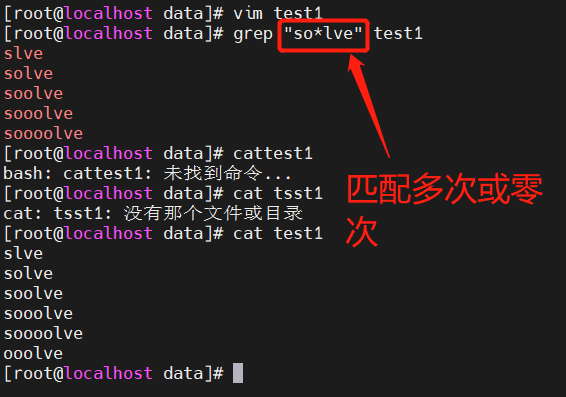
2.2 . 匹配任意单个字符
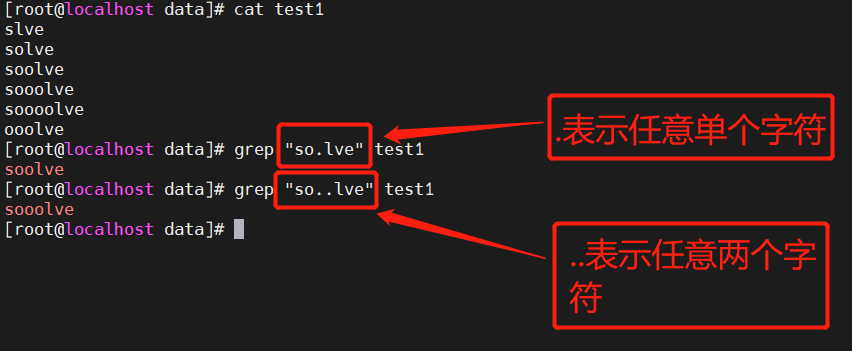
2.3 {n} : 匹配前面的子表达式n次;{n,} : 匹配前面的子表达式不少于n次;{n,m} : 匹配前面的子表达式n到m次
注: egrep、 awk使用{n}、{n,}、 {n, m}匹配时“{}"前不用加“\”
grep -E 相当于 egrep
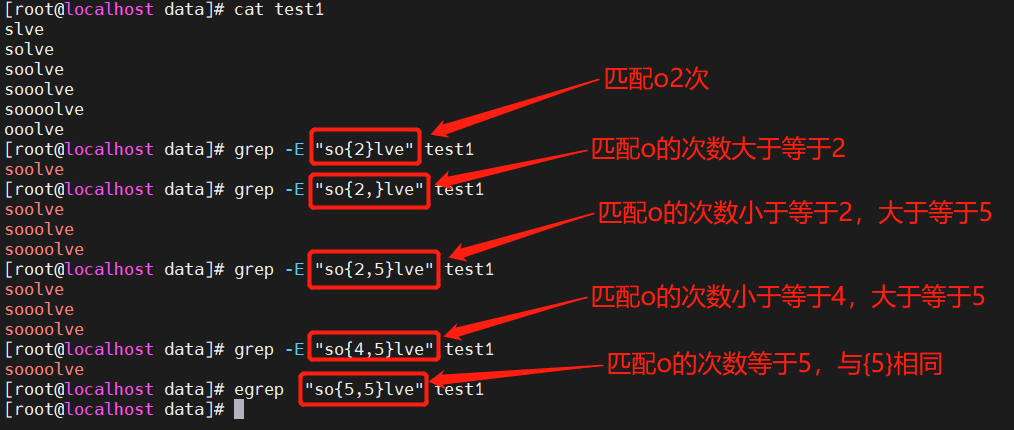
最后结果没显示是因为没有匹配项
2.4 ^ 匹配字符串开始的位置;$ 匹配字符串结束的位置;^$匹配空行
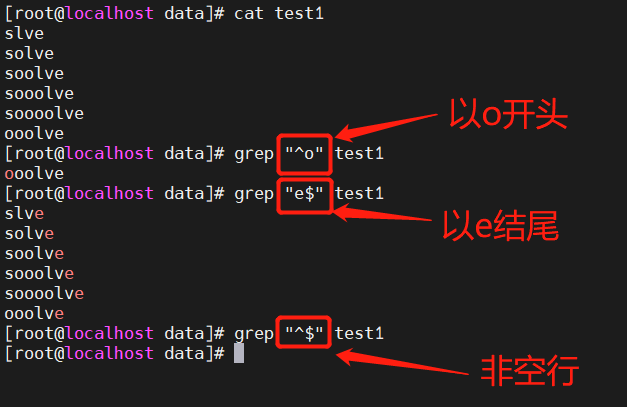
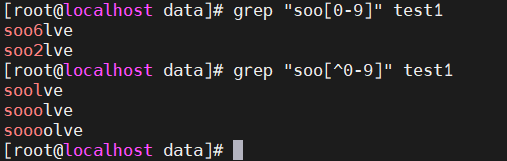
2.5 [list] 匹配list列表中的一个字符;[^list] 匹配任意非list列表中的一个字符
三、扩展正则
1、扩展正则表达式元字符: ( 支持的工具: egrep、 awk,也可用grep -E)
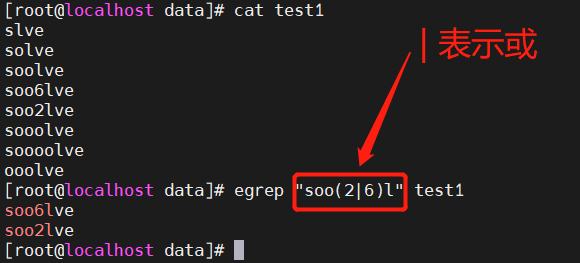
+ : 匹配前面 子表达式1次以上 ? : 匹配前面 子表达式0次或者1次 () : 将括号中的字符串作为一个整体 | : 以或的方式匹配字条串 {} :允许为可重复的正则表达式指定一个上限,这通常称为间隔(interval) {n} 重复n次;{n,} 重复n次或更多次;{n,m} 重复n到m次
2、实例操作
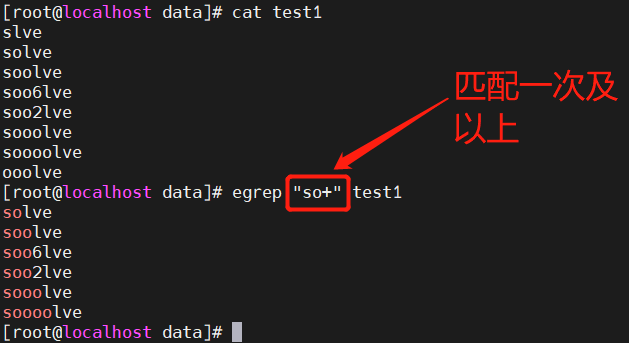
2.1 + 匹配前面 子表达式1次以上
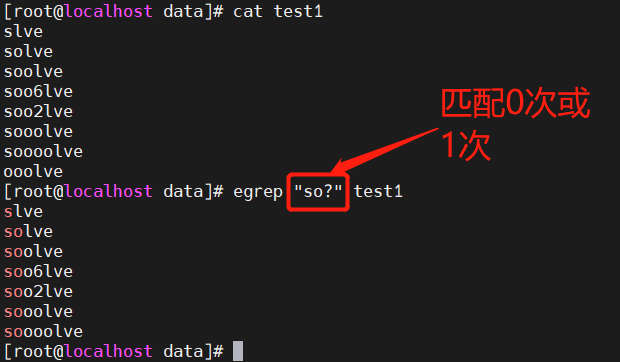
2.2 ? 匹配前面 子表达式0次或者1次
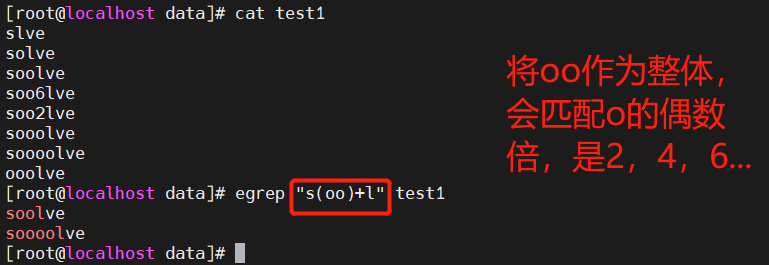
2.3 () 将括号中的字符串作为一个整体
2.4 | 以或的方式匹配字条串

 浙公网安备 33010602011771号
浙公网安备 33010602011771号