Stream流操作
1.说明
stream流操作是java8引入的一个新概念,是一种对Java集合运算和表达的高阶抽象。主要是java8用来处理集合的,使我们的代码更简洁高效。
特点:
- 大大提高编码效率和降低代码的复杂度
- 不是数据结构,不会保存数据
- 要有终端操作流才会进行处理,也就是开始流动,如果没有终端操作的话,则流的处理操作不会执行
- 有串行和并行两种,但是并行的时候处理的数组是无序的,所以一般对排序没有要求的时候才会使用并行
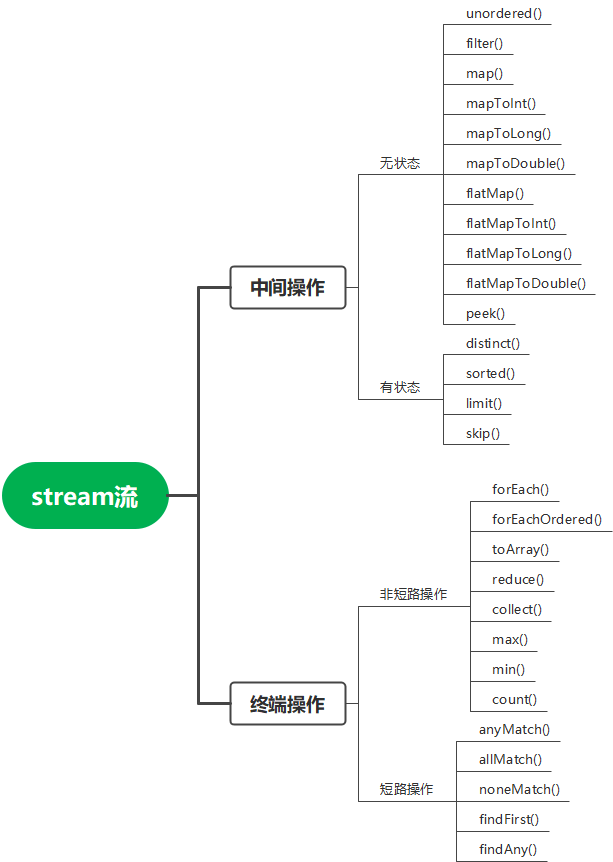
2.分类
流操作主要分为中间操作和终端操作两大类,其中中间操作又分为无状态和有状态两小类,终端操作又分为非短路操作和短路操作。
- 无状态:指元素的处理不受之前元素的影响
- 有状态:指该操作只有拿到之前的元素之后才能继续下去
- 非短路操作:指必须处理所有的元素才能得到结果
- 短路操作:指遇到一些符合/不符合条件的元素就可以获取结果,不一定非要处理完所有的元素
分类树状图:
3.使用
3.1 流的创建
stream流的创建大致有五种创建方法:
(1).使用Collection下的 stream() 和 parallelStream() 方法
其中stream()就是创建一个普通的流,而parallelStream()则是一个并行的流,另外也可以通过Stream的parallel()方法将普通的流改变为并行的流。
List<Person> people = Person.initPerson();
Stream<Person> stream = people.stream();
Stream<Person> parallelStream = people.parallelStream();
(2).使用Arrays 中的 stream() 方法,将数组转成流
Integer[] age = {12, 13, 14, 15, 16, 17, 18};
Stream<Integer> ageStream = Arrays.stream(age);
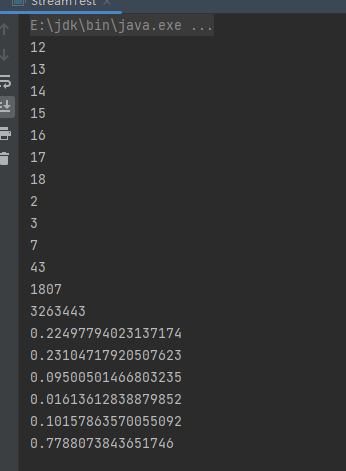
(3).使用Stream中的静态方法:of()、iterate()、generate()
Stream<Integer> ofStream = Stream.of(12, 13, 14, 15, 16, 17, 18);
ofStream.forEach(System.out::println);
Stream<Integer> iterateStream = Stream.iterate(2, s -> s * (s - 1) + 1).limit(6);
iterateStream.forEach(System.out::println);
Stream<Double> generateStream = Stream.generate(Math::random).limit(6);
generateStream.forEach(System.out::println);
运行结果:
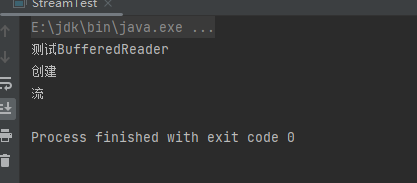
(4).使用 BufferedReader.lines() 方法,将每行内容转成流
BufferedReader reader = new BufferedReader(new FileReader("C:\\Users\\admin\\Desktop\\123.sql"));
// 这里直接将流通过collect()转化为了List
List<String> collect = reader.lines().collect(Collectors.toList());
collect.forEach(System.out::println);
运行结果:
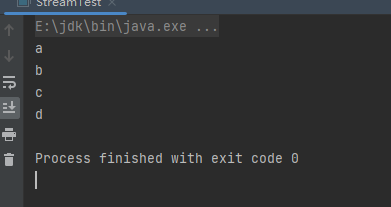
(5).使用 Pattern.splitAsStream() 方法,将字符串分隔成流
Pattern pattern = Pattern.compile(",");
List<String> collect = pattern.splitAsStream("a,b,c,d").collect(Collectors.toList());
collect.forEach(System.out::println);
运行结果:
3.2 中间操作的使用
例子中用到的Person类为:
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Arrays;
import java.util.List;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Person {
private String name;
private Integer age;
private Double score;
public static List<Person> initPerson() {
return Arrays.asList(new Person("张三", 14, 80.0),
new Person("李四", 15, 70.0),
new Person("王二", 16, 80.0),
new Person("麻子", 15, 80.0),
new Person("张三", 14, 80.0));
}
@Override
public String toString() {
return "name:" + name + ",age:" + age + ",score:" + score;
}
@Override
public boolean equals(Object a) {
return hashCode() == a.hashCode();
}
@Override
public int hashCode() {
return toString().hashCode();
}
}
(1)filter中间操作
filter中间操作是过滤操作,筛选出一些符合条件的数据。样例:
List<Person> people = Person.initPerson();
long count = people.stream().filter(person -> person.getAge().equals(14)).count();
System.out.println(count);
运行结果:
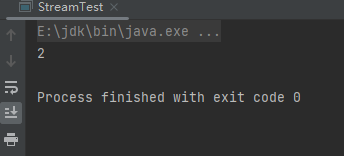
从上面的结果可以看出,其筛选出了两个age为14的数据。
(2)map中间操作
map中间操作是对数据进行映射,处理,相关的扩展还有mapToInt,mapToLong,mapToDouble这三个操作会降数据分别转化为int,long,double。样例:
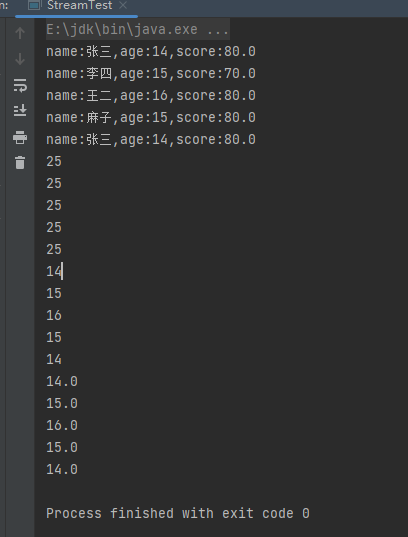
List<Person> people = Person.initPerson();
List<String> collect = people.stream().map(Person::toString).collect(Collectors.toList());
collect.forEach(System.out::println);
people.stream().mapToInt(u -> u.toString().length()).forEach(System.out::println);
people.stream().mapToLong(Person::getAge).forEach(System.out::println);
people.stream().mapToDouble(Person::getAge).forEach(System.out::println);
运行结果:
(3)flatMap中间操作
flatMap中间操作和map中间操作一样,不过区别是flatMap操作的返回类型只能为Stream流,也就是从一个流转化为另一个流。
(4)peek中间操作
peek中间操作是传递一个消费性函数接口作为参数对数据及逆行消费。样例:
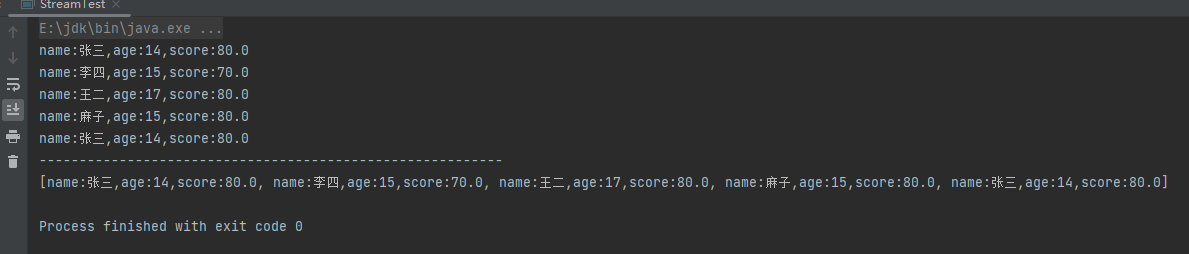
List<Person> people = Person.initPerson();
people.stream().peek(s -> {
if (s.getAge() > 15)
s.setAge(17);
}).forEach(System.out::println);
System.out.println("----------------------------------------------------------");
System.out.println(people);
运行结果:
(5)unorder中间操作
unorder中间操作,消除相遇顺序,主要用于并行流,提高并行流的性能,因为并行流在处理有序数据结构时,对性能会有很大的影响。
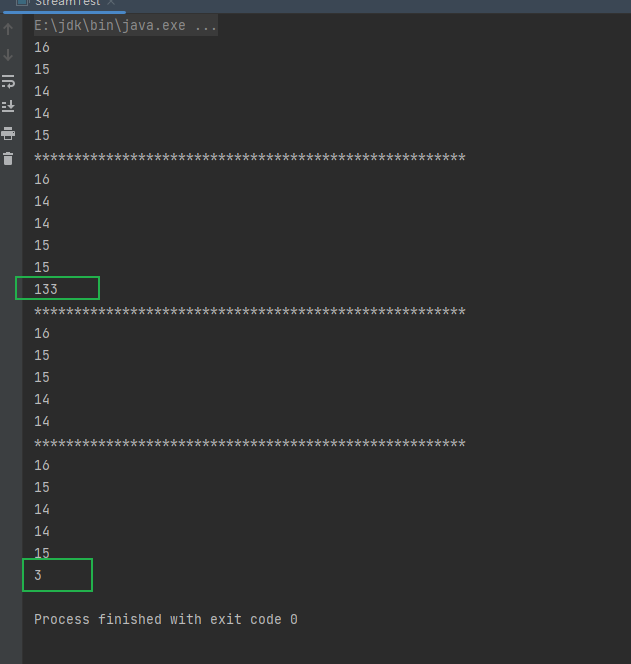
PS:不过这边进行样例的时候发现好像加了unorder的比没加unorder的用时还要旧,不确定是不是因为数据太少。增加数据之后进行测试,发现增加unorder的用时变化不大,而没加unorder的用时增加了些。
List<Person> people = Person.initPerson();
long time = new Date().getTime();
people.stream().parallel().unordered().map(Person::getAge).forEach(System.out::println);
System.out.println("******************************************************");
people.stream().parallel().unordered().map(Person::getAge).forEach(System.out::println);
long time1 = new Date().getTime();
System.out.println(time1 - time);
System.out.println("******************************************************");
long time2 = new Date().getTime();
people.stream().parallel().map(Person::getAge).forEach(System.out::println);
System.out.println("******************************************************");
people.stream().parallel().map(Person::getAge).forEach(System.out::println);
long time3 = new Date().getTime();
System.out.println(time3 - time2);
运行结果:
(6)distinct中间操作
distinct中间操作通过流中元素的 hashCode() 和 equals() 去除重复元素,样例:
List<Person> people = Person.initPerson();
people.forEach(System.out::println);
System.out.println("------------------------------------------------------");
// distinct中间操作,进行去重操作
people.stream().distinct().forEach(System.out::println);
运行结果:
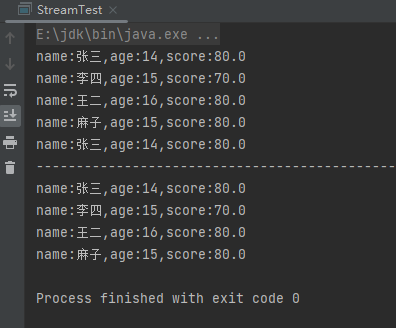
(7)sorted中间操作
sorted中间操作是一个排序操作,能够进行定制排序和自然排序,定制排序就是传一个比较器参数。样例:
List<Person> people = Person.initPerson();
people.stream().sorted(Comparator.comparing(s1 -> s1.getAge(), (a1,a2) -> a2 - a1)).forEach(System.out::println);
System.out.println("------------------------------------------------------");
people.stream().sorted(Comparator.comparing(Person::getAge).thenComparing(Person::getScore).reversed()).forEach(System.out::println);
运行结果:
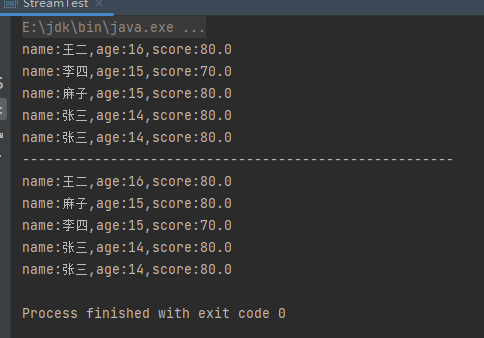
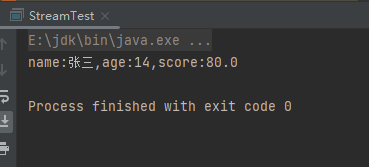
(8)limit中间操作
limit中间操作就是获取n个元素,就像是sql中的limit。样例:
List<Person> people = Person.initPerson();
people.stream().limit(1).forEach(System.out::println);
运行结果:
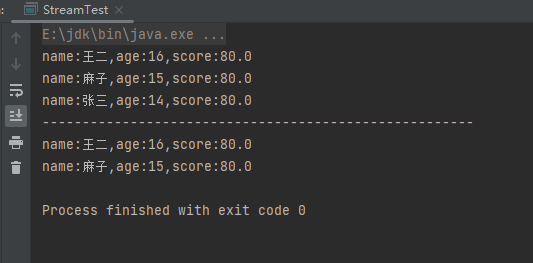
(9)skip中间操作
skip中间操作是跳过n个元素,与limit相互配合时可以实现分页功能。样例:
List<Person> people = Person.initPerson();
people.stream().skip(2).forEach(System.out::println);
System.out.println("------------------------------------------------------");
people.stream().skip(2).limit(2).forEach(System.out::println);
运行结果:
3.3 终端操作
(1)anyMatch终端操作
anyMatch终端操作是进行判断是否有数据满足条件,只要有一条数据满足条件就会返回true。样例:
List<Person> people = Person.initPerson();
System.out.println(people.stream().map(Person::getAge).anyMatch(s1 -> s1 > 15));
System.out.println(people.stream().map(Person::getAge).anyMatch(s1 -> s1 > 17));
运行结果:
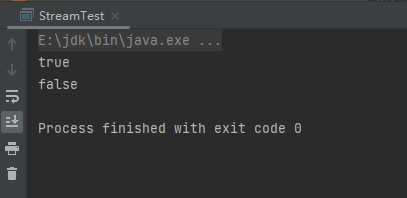
(2)allMatch终端操作
allMatch终端操作是判断数据是否满足条件,必须全部的数据满足条件才会返回true,只要有一个不满足条件就会返回false。样例:
List<Person> people = Person.initPerson();
System.out.println(people.stream().map(Person::getAge).allMatch(s1 -> s1 > 15));
System.out.println(people.stream().map(Person::getAge).allMatch(s1 -> s1 > 13));
运行结果:
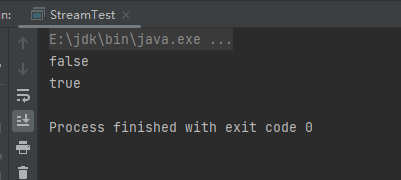
(3)noneMatch终端操作
noneMatch终端操作时判断数据是否全部不满足条件,只有全部不满足条件才会返回true,否则返回false。样例:
List<Person> people = Person.initPerson();
System.out.println(people.stream().map(Person::getAge).noneMatch(s1 -> s1 > 16));
System.out.println(people.stream().map(Person::getAge).noneMatch(s1 -> s1 > 15));
运行结果:
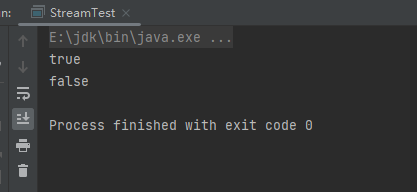
(4)findFirst终端操作
findFirst终端操作是返回第一个满足条件的数据。样例:
List<Person> people = Person.initPerson();
System.out.println(people.stream().parallel().filter(s1 -> s1.getAge() > 14).findFirst());
运行结果:
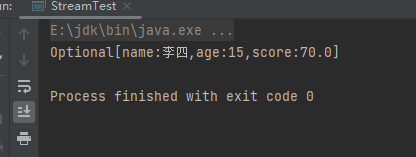
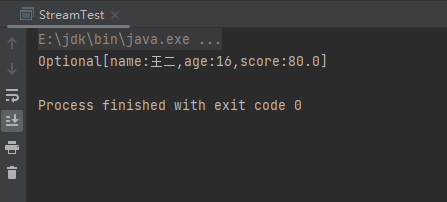
(5)findAny终端操作
findAny终端操作时返回任意一个满足条件的数据,不一定是第一个。样例:
List<Person> people = Person.initPerson();
System.out.println(people.stream().parallel().filter(s1 -> s1.getAge() > 14).findAny());
运行结果:
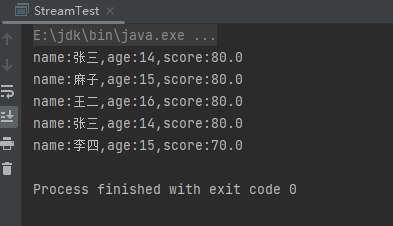
(6)forEach终端操作
foreach终端操作时对数据进行遍历消费,说白了就是一个循环操作。样例:
List<Person> people = Person.initPerson();
people.stream().parallel().forEach(System.out::println);
运行结果:
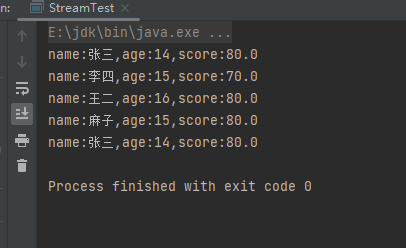
(7)forEachOrdered终端操作
forEachOrdered终端操作也是一个循环,不过与forEach终端操作不同的是forEachOrdered能保证循环是按照顺序进行循环的。样例:
List<Person> people = Person.initPerson();
people.stream().parallel().forEachOrdered(System.out::println);
运行结果:
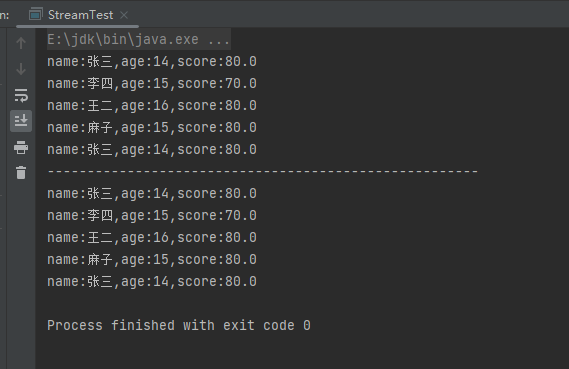
(8)toArray终端操作
toArray终端操作是将流转化为数组的操作,如果不写参数则转化为object数组,写参数则转为当前所写参数的数组。样例:
List<Person> people = Person.initPerson();
Object[] objects = people.stream().toArray();
for (Object object : objects) {
System.out.println(object);
}
System.out.println("------------------------------------------------------");
Person[] persons = people.stream().toArray(Person[]::new);
for (Person person : persons) {
System.out.println(person);
}
运行结果:
(9)min终端操作
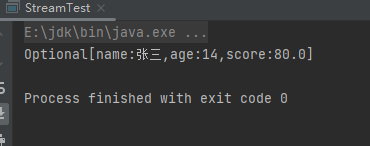
min终端操作是获取数据中的最小值,返回值是Optional。样例:
List<Person> people = Person.initPerson();
Optional<Person> min = people.stream().min(Comparator.comparing(Person::getAge));
System.out.println(min);
运行结果:
(10)max终端操作
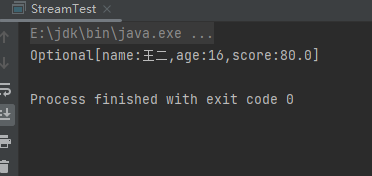
max终端操作是获取数据中的最大值,返回值也是Optional。样例:
List<Person> people = Person.initPerson();
Optional<Person> max = people.stream().max(Comparator.comparing(Person::getAge));
System.out.println(max);
运行结果:
(11)count终端操作
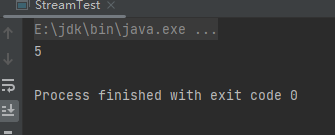
count终端操作是获取流中的数据量。样例:
List<Person> people = Person.initPerson();
System.out.println(people.stream().count());
运行结果:
(12)reduce终端操作
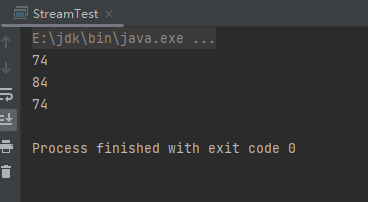
reduct终端操作是根据指定的计算模型将Stream中的值计算得到一个最终结果,其分为一个参数,两个参数和三个参数的方法。一个参数:就是进行计算的逻辑,两个参数:一个初始值,一个计算逻辑,三个参数:也是一个初始值,一个计算逻辑,一个合并逻辑,合并逻辑只会针对并发时冲突的情况。样例:
List<Person> people = Person.initPerson();
// 获取所有数据年龄的和
Integer sum = people.stream().map(Person::getAge).reduce((s1, s2) -> s1 + s2).get();
System.out.println(sum);
// 获取所有数据的年龄的和,并其初始值为10
Integer sum1 = people.stream().map(Person::getAge).reduce(10, (s1, s2) -> s1 + s2);
System.out.println(sum1);
// 计算所有年龄的和,初始值为0,如果冲突的话则取其中最大的,当发生冲突时求的就不是和了
Integer sum2 = people.stream().map(Person::getAge).reduce(0, (s1, s2) -> s1 + s2, (s1, s2) -> s1 > s2 ? s1 : s2);
System.out.println(sum2);
运行结果:
(13)collect终端操作
collect终端操作是收集操作,可以说是对处理过后的流进行一些归纳处理。其收集器有多种,具体如下:
| 收集器 | 功能描述 |
|---|---|
| toList | 转化为list集合 |
| toSet | 转化为set集合 |
| toColection | 转化为collection集合 |
| toMap | 转化为map |
| counting | 计算数量 |
| summingInt | 计算和,根据值得类型有不同的派生,比如summingLong等 |
| averagingInt | 计算平均值,根据值的类型不同也会有不同的派生,比如averagingLong等 |
| joining | 根据字符串进行拼接流中的元素 |
| maxBy | 根据比较器选择出值最大的元素 |
| minBy | 根据比较器选择出值最小的元素 |
| groupingBy | 按照给定的分组函数进行分组,返回值类型为map |
| partitioningBy | 根据给定的分区函数的值进行分区,会将key分为true和false的map |
| collectingAndThen | 对流的结果进行二次加工转换 |
| reducing | 从给定的初始值逐一处理,知道最后只剩一个结果为止,和reduce终端操作类似 |
各种收集器的样例:
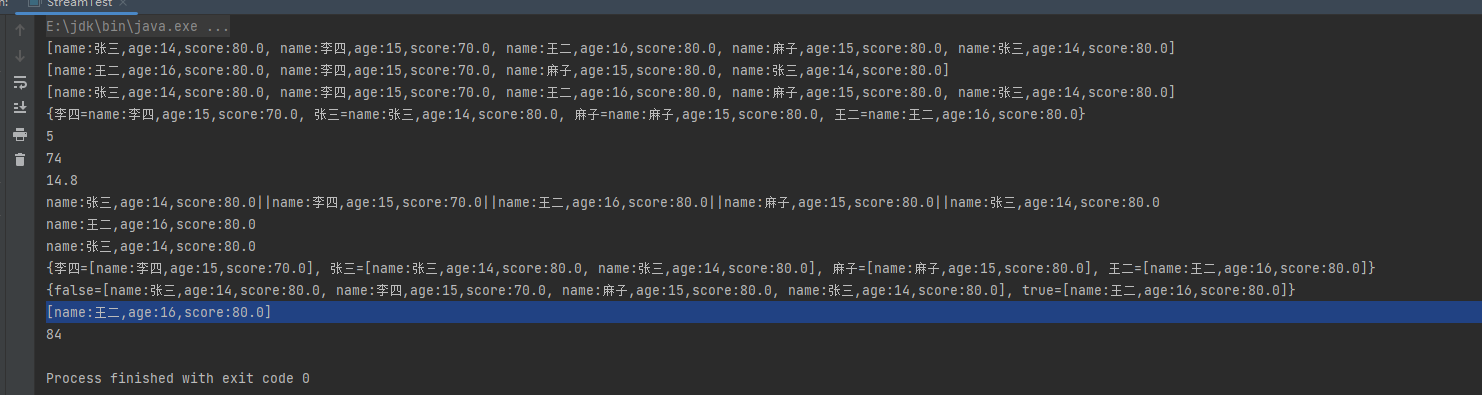
List<Person> people = Person.initPerson();
// toList收集器,转为list数组
List<Person> collect = people.stream().collect(Collectors.toList());
System.out.println(collect);
// toSet收集器,转为set集合
Set<Person> collect1 = people.stream().collect(Collectors.toSet());
System.out.println(collect1);
// toCollection收集器,转为collection集合
List<Person> collect2 = people.stream().collect(Collectors.toCollection(ArrayList<Person>::new));
System.out.println(collect2);
// toMap收集器,转为map
Map<String, Person> collect3 = people.stream().collect(Collectors.toMap(Person::getName, Function.identity(), (s1, s2) -> s2));
System.out.println(collect3);
// counting收集器,计算数量
Long collect4 = people.stream().collect(Collectors.counting());
System.out.println(collect4);
// summingInt收集器,计算和,根据值的类型不同有不同的派生,比如summingLong等
Integer collect5 = people.stream().collect(Collectors.summingInt(Person::getAge));
System.out.println(collect5);
// averagingInt收集器,计算平均值,根据值的类型不同也会有不同的派生,比如averagingLong
Double collect6 = people.stream().collect(Collectors.averagingInt(Person::getAge));
System.out.println(collect6);
// joining收集器,进行拼接流中的元素
String collect7 = people.stream().map(Person::toString).collect(Collectors.joining("||"));
System.out.println(collect7);
// maxBy收集器,根据比较器选择出值最大的元素
Person person = people.stream().collect(Collectors.maxBy((s1, s2) -> s1.getAge() - s2.getAge())).get();
System.out.println(person);
// minBy收集器,根据比较器选择出值最小的元素
Person person1 = people.stream().collect(Collectors.minBy((s1, s2) -> s1.getAge() - s2.getAge())).get();
System.out.println(person1);
// groupingBy收集器,按照给定的分组函数进行分组
Map<String, List<Person>> collect8 = people.stream().collect(Collectors.groupingBy(Person::getName));
System.out.println(collect8);
// partitioningBy收集器,根据给定的分区函数的值进行分区,会将key分为true和false两个map
Map<Boolean, List<Person>> collect9 = people.stream().collect(Collectors.partitioningBy(s -> s.getAge() > 15));
System.out.println(collect9);
// collectingAndThen收集器,对其结果进行二次加工转换
List<Person> collect10 = people.stream().collect(Collectors.collectingAndThen(Collectors.partitioningBy(s -> s.getAge() > 15), sm -> sm.get(true)));
System.out.println(collect10);
// reducing收集器,从给定的初始值逐一处理,直到最后只剩一个结果位置,和reduce终端操作类似
Integer collect11 = people.stream().map(Person::getAge).collect(Collectors.reducing(10, (s1, s2) -> s1 + s2));
System.out.println(collect11);
运行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号