

春招MySQL知识点总结(个人向)
InnoDB Buffer Pool
数据页
InnoDB中,数据管理的最小单位为页,默认是16KB,页中除了存储用户数据,还可以存储控制信息的数据。InnoDB IO子系统的读写最小单位也是页。如果对表进行了压缩,则对应的数据页称为压缩页,如果需要从压缩页中读取数据,则压缩页需要先解压,形成解压页,解压页为16KB。压缩页的大小是在建表的时候指定,目前支持16K,8K,4K,2K,1K。假设指定的压缩页大小为4K,如果有个数据页无法被压缩到4K以下,则需要做B-tree分裂操作,这是一个比较耗时的操作。正常情况下,Buffer Pool中会把压缩和解压页都缓存起来,当Free List不够时,按照系统当前的实际负载来决定淘汰策略。如果系统瓶颈在IO上,则只驱逐解压页,压缩页依然在Buffer Pool中,否则解压页和压缩页都被驱逐。数据页里面不一定都存的是用户数据,开始是控制信息,比如行锁,自适应哈希等。对于一张表,在InnoDB中主键按page有序,但是page内不一定有序。
Buffer Chunks
Buffer Chunks包括数据页和数据页对应的控制体,它在数据库启动时分配,直到数据库关闭时才回收。通过遍历chunks可以访问几乎所有的数据页,有两种状态的数据页除外:没有被解压的压缩页(BUF_BLOCK_ZIP_PAGE)以及被修改过且解压页已经被驱逐的压缩页(BUF_BLOCK_ZIP_DIRTY)。
List
Free List
其上的节点都是未被使用的节点,如果需要从数据库中分配新的数据页,直接从上获取即可。InnoDB需要保证Free List有足够的节点,提供给用户线程用,否则需要从FLU List或者LRU List淘汰一定的节点。InnoDB初始化后,Buffer Chunks中的所有数据页都被加入到Free List,表示所有节点都可用。
Flu List
这个链表中的所有节点都是脏页,也就是说这些数据页都被修改过,但是还没来得及被刷新到磁盘上。一个数据页可能会在不同的时刻被修改多次,在数据页上记录了最老(也就是第一次)的一次修改的lsn,Flu List中的节点按照oldest_modification排序,链表尾是最小的,也就是最早被修改的数据页,当需要从Flu List中淘汰页面时候,从链表尾部开始淘汰。
LRU List
所有新读取进来的数据页都被放在上面。最近最少使用的节点被放在链表末尾,如果Free List里面没有节点了,就会从中淘汰末尾的节点。LRU List还包含没有被解压的压缩页,这些压缩页刚从磁盘读取出来,还没来的及被解压。LRU List被分为两部分,默认前为young list,存储经常被使用的热点page,后为old list。新读入的page默认被加在old list头,新加入的page如果在过了一段时间之后仍有访问,才被移到young list上,主要是为了预读的数据页和全表扫描污染buffer pool。如果LRU List小于512,则没有young list,同时,只有young list的前4分之一页面才会在访问后移动到young list头。除此之外,还有专门管理解压页的Unzip LRU List。
核心数据结构
一个Buffer Pool实例中的数据结构有buf_pool_t,buf_block_t,buf_page_t从大到小,其中pool管理着包含block的数据页控制体。block的第一个元素是page方便指针转换,第二个元素Frame指针指向数据页。block上还存储着Unzip LRU List的头指针,压缩页解压后放在Frame指向的数据页上。block还有页面级别的锁block_mutex_t。page也是数据页控制体,存储着和block上不一样的信息,如buf_state_t表示页面状态,有以下几种情况。
BUF_BLOCK_POOL_WATCH:
这种类型的page是提供给purge线程用的。InnoDB为了实现多版本,需要把之前的数据记录在undo log中,如果没有读请求再需要它,就可以通过purge线程删除。换句话说,purge线程需要知道某些数据页是否被读取,现在解法就是首先查看page hash,看看这个数据页是否已经被读入,如果没有读入,则获取一个BUF_BLOCK_POOL_WATCH类型的哨兵数据页控制体,同时加入page_hash,但是没有真正的数据,并把其类型置为BUF_BLOCK_ZIP_PAGE(表示已经被使用了,其他purge线程就不会用到这个控制体了),如果查看page hash后发现有这个数据页,只需要判断控制体在内存中的地址是否属于Buffer Chunks即可,如果是表示对应数据页已经被其他线程读入了。另一方面,如果用户线程需要这个数据页,先查看page hash看看是否是BUF_BLOCK_POOL_WATCH类型的数据页,如果是则回收这个BUF_BLOCK_POOL_WATCH类型的数据页,从Free List中(即在Buffer Chunks中)分配一个空闲的控制体,填入数据。这里的核心思想就是通过控制体在内存中的地址来确定数据页是否还在被使用。
BUF_BLOCK_ZIP_PAGE:
当压缩页从磁盘读取出来的时候,先通过malloc分配一个临时的buf_page_t,然后从伙伴系统中分配出压缩页存储的空间,把磁盘中读取的压缩数据存入,然后把这个临时的buf_page_t标记为BUF_BLOCK_ZIP_PAGE状态,只有当这个压缩页被解压了,state字段才会被修改为BUF_BLOCK_FILE_PAGE,并加入LRU List和Unzip LRU List(buf_page_get_gen)。如果一个压缩页对应的解压页被驱逐了,但是需要保留这个压缩页且压缩页不是脏页,则这个压缩页被标记为BUF_BLOCK_ZIP_PAGE。另外一个用法是,从BUF_BLOCK_POOL_WATCH类型节点中,如果被某个purge线程使用了,也会被标记为BUF_BLOCK_ZIP_PAGE。
BUF_BLOCK_ZIP_DIRTY:
如果一个压缩页对应的解压页被驱逐了,但是需要保留这个压缩页且压缩页是脏页,则被标记为BUF_BLOCK_ZIP_DIRTY,如果该压缩页又被解压了,则状态会变为BUF_BLOCK_FILE_PAGE。因此BUF_BLOCK_ZIP_DIRTY也是一个比较短暂的状态,这种类型的数据页都在Flush List中。
BUF_BLOCK_NOT_USED:
当链表处于Free List中,状态就为此状态。
BUF_BLOCK_READY_FOR_USE:
当从Free List中,获取一个空闲的数据页时,状态会从BUF_BLOCK_NOT_USED变为BUF_BLOCK_READY_FOR_USE,也是一个比较短暂的状态。处于这个状态的数据页不处于任何逻辑链表中。
BUF_BLOCK_FILE_PAGE:
正常被使用的数据页都是这种状态。LRU List中,大部分数据页都是这种状态。压缩页被解压后,状态也会变成BUF_BLOCK_FILE_PAGE。
BUF_BLOCK_MEMORY:
Buffer Pool中的数据页不仅可以存储用户数据,也可以存储一些系统信息,例如InnoDB行锁,自适应哈希索引以及压缩页的数据等,这些数据页被标记为BUF_BLOCK_MEMORY。处于这个状态的数据页不处于任何逻辑链表中
BUF_BLOCK_REMOVE_HASH:
当加入Free List之前,需要先把page hash移除。因此这种状态就表示此页面page hash已经被移除,但是还没被加入到Free List中,是一个比较短暂的状态。
buf_page_t中buf_fix_count和io_fix两个变量主要用来做并发控制,减少mutex加锁的范围。当从buffer pool读取一个数据页时候,会其加读锁,然后递增buf_fix_count,同时设置io_fix为BUF_IO_READ,然后即可以释放读锁。后续如果其他线程在驱逐数据页(或者刷脏)的时候,需要先检查一下这两个变量,如果buf_fix_count不为零且io_fix不为BUF_IO_NONE,则不允许驱逐。这里的技巧主要是为了减少数据页控制体上mutex的争抢,而对数据页的内容,读取的时候依然要加读锁,修改时加写锁。
读取流程
首先通过buf_pool_get函数依据space_id和page_no查找指定的数据页在那个Buffer Pool Instance里面。,也就是说先通过space_id和page_no算出一个fold value然后按照instance的个数取余数即可。这里有个小细节,page_no的六位被砍掉,这是为了保证一个extent(一个extent是连续的64个页,大小1M)的数据能被缓存到同一个Buffer Pool Instance中,便于后面的预读操作。
在page hash中查找这个数据页是否已经被加载到对应的Buffer Pool Instance中,如果没有找到这个数据页且mode为BUF_GET_IF_IN_POOL_OR_WATCH则设置watch数据页,接下来,如果没有找到数据页且mode为BUF_GET_IF_IN_POOL、BUF_PEEK_IF_IN_POOL或者BUF_GET_IF_IN_POOL_OR_WATCH函数直接返回空,表示没有找到数据页。
如果mode是其他模式,就读取磁盘,在读取磁盘数据之前,我们如果发现需要读取的是非压缩页,则先从Free List中获取空闲的数据页,如果Free List中已经没有了,则需要通过刷脏来释放数据页,这里的一些细节我们后续在LRU模块再分析,获取到空闲的数据页后,加入到LRU List中。如果发现需要读取的是压缩页,则临时分配一个buf_page_t用来做控制体,通过伙伴系统分配到压缩页存数据的空间,最后同样加入到LRU List中。最后读取数据,重试100次,然后判断是否需要随机预读。
读取数据成功后,我们需要判断读取的数据页是不是压缩页,如果是的话,因为从磁盘中读取的压缩页的控制体是临时分配的,所以需要重新分配block,把临时分配的buf_page_t给释放掉,接着进行解压,解压成功后,设置state为BUF_BLOCK_FILE_PAGE,最后加入Unzip LRU List中。我们判断这个页是否是第一次访问,如果是则设置access_time。
如果mode不为BUF_PEEK_IF_IN_POOL,我们需要判断是否把这个数据页移到young list中,具体细节在后面LRU模块中分析。
如果mode不为BUF_GET_NO_LATCH,我们给数据页加上读写锁。
如果mode不为BUF_PEEK_IF_IN_POOL且这个数据页是第一次访问,则判断是否需要线性预读。
获取空闲压缩页
统计Free List和LRU List的长度,如果发现他们再Buffer Chunks占用太少的空间,则表示太多的空间被行锁,自使用哈希等内部结构给占用了,一般这些都是大事务导致的。这时候会给出报警。
查看Free List中是否还有空闲的数据页,如果有则直接返回,否则进入下一步。大多数情况下,这一步都能找到空闲的数据页。
如果Free List中已经没有空闲的数据页了,则会尝试驱逐LRU List末尾的数据页。如果系统有压缩页,InnoDB会调用buf_LRU_evict_from_unzip_LRU来决定是否驱逐压缩页,如果Unzip LRU List大于LRU List的十分之一或者当前InnoDB IO压力比较大,则会优先从Unzip LRU List中把解压页给驱逐,否则会从LRU List中把解压页和压缩页同时驱逐。
如果在上一步中没有找到空闲的数据页,则需要刷脏,由于buf_LRU_get_free_block这个函数是在用户线程中调用的,所以即使要刷脏,这里也是刷一个脏页,防止刷过多的脏页阻塞用户线程。
如果上一步的刷脏因为数据页被其他线程读取而不能刷脏,则重新跳转到上述第二步。进行第二轮迭代,与第一轮迭代的区别是,第一轮迭代在扫描LRU List时,最多只扫描innodb_lru_scan_depth个,而在第二轮迭代开始,扫描整个LRU List。如果很不幸,这一轮还是没有找到空闲的数据页,从三轮迭代开始,在刷脏前等待。
最终找到一个空闲页后,page的state为BUF_BLOCK_READY_FOR_USE。
刷脏优化
在InnoDB里面,一个线程可以随时访问Hazard Pointer,但是在访问后,他需要调整指针到一个有效的值。InnoDB中可能有多个线程同时作用在Flush List上进行刷脏,例如LRU_Manager_Thread和Page_Cleaner_Thread。同时,为了减少锁占用的时间,InnoDB在进行写盘的时候都会把之前占用的锁给释放掉。这两个因素叠加在一起导致同一个刷脏线程刷完一个数据页A,就需要回到Flush List末尾(因为A之前的脏页可能被其他线程给刷走了,之前的脏页可能已经不在Flush list中了),重新扫描新的可刷盘的脏页。最本质的方法就是当刷完一个脏页的时候不要每次都从队尾重新扫描。我们可以使用Hazard Pointer来解决,方法如下:遍历找到一个可刷盘的数据页,在锁释放之前,调整Hazard Pointer使之指向Flush List中下一个节点,注意一定要在持有锁的情况下修改。然后释放锁,进行刷盘,刷完盘后,重新获取锁,读取Hazard Pointer并设置下一个节点,然后释放锁,进行刷盘,如此重复。当这个线程在刷盘的时候,另外一个线程需要刷盘,也是通过Hazard Pointer来获取可靠的节点,并重置下一个有效的节点。
预读模块
随机预读
当一个extent的数据页有13个以上在Buffer pool中时,会把这个extent的页使用异步IO和IO合并的策略都读进Buffer pool。
线性预读
这中预读只发生在一个边界的数据页(Extend中第一个数据页或者最后一个数据页)上。在一个Extend范围内,如果大于一定数量的数据页是被顺序访问(通过判断数据页access time是否为升序或者逆序来确定)的,则把下一个Extend的所有数据页都读入Buffer Pool。读取的时候依然采用异步IO和IO合并策略。
Double Write Buffer
https://cloud.tencent.com/developer/article/1663304
MVCC与恢复
redo log
为了取得更好的读写性能,InnoDB会将数据缓存在内存中(InnoDB Buffer Pool),对磁盘数据的修改也会落后于内存,这时如果进程或机器崩溃,会导致内存数据丢失,为了保证数据库本身的一致性和持久性,InnoDB维护了Redo Log。修改Page之前需要先将修改的内容记录到REDO中,并保证REDO LOG早于对应的Page落盘,也就是常说的WAL,Write Ahead Log。当故障发生导致内存数据丢失后,InnoDB会在重启时,通过重放REDO,将Page恢复到崩溃前的状态。
Redo Log的重放需要保证页标志的对应,这是基于dblwr实现的。同时需要保证幂等,即多次Redo的结果是一样的,这一实现可以基于LSN(Log Sequence Number)InnoDB中维护了redo的LSN,只有在LSN后的Redo Log才进行恢复。
Redo Log主要针对page,文件操作变更和原子操作的记录。
Redo Log文件的组织
逻辑Redo层
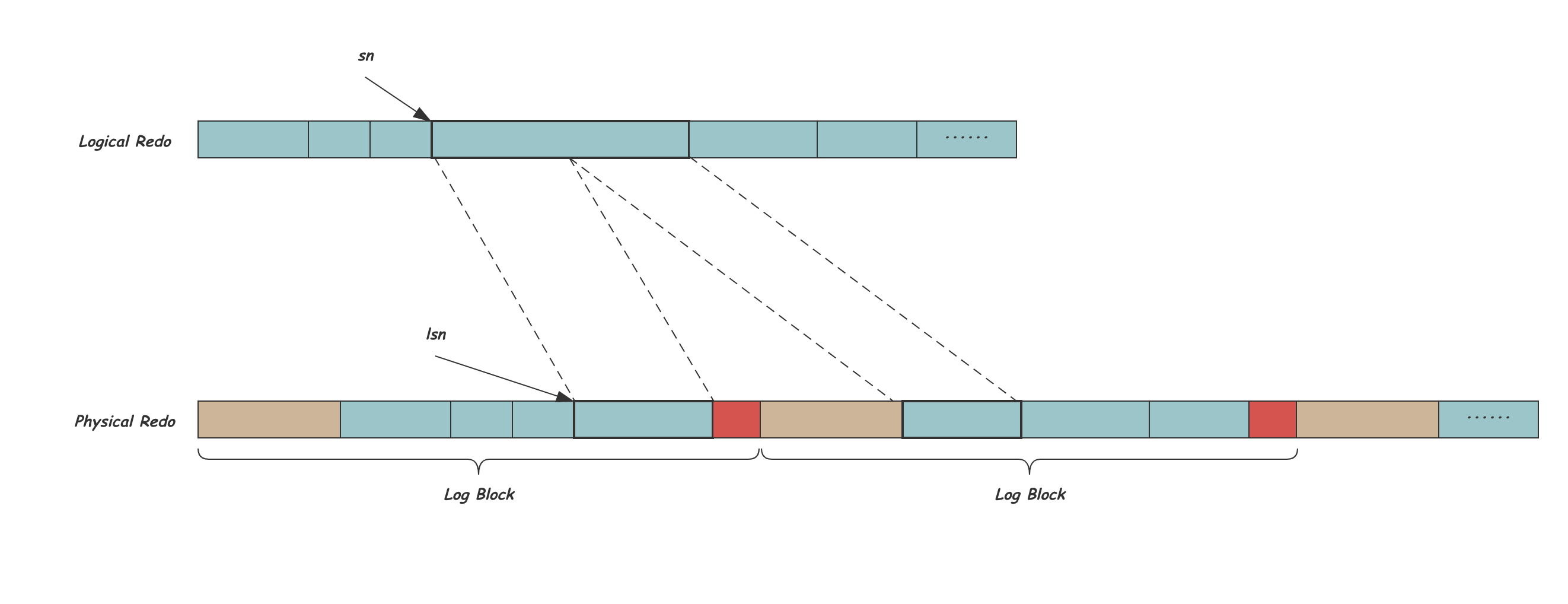
这一层是真正的Redo内容,Redo由多个不同Type的多个Redo记录收尾相连组成,有全局唯一的递增的偏移sn,InnoDB会在全局log_sys中维护当前sn的最大值,并在每次写入数据时将sn增加Redo内容长度。如下图所示:

物理Redo层
磁盘是块设备,InnoDB中也用Block的概念来读写数据,一个Block的长度OS_FILE_LOG_BLOCK_SIZE等于磁盘扇区的大小512B,每次IO读写的最小单位都是一个Block。除了REDO数据以外,Block中还需要一些额外的信息,下图所示一个Log Block的的组成,包括12字节的Block Header:前4字节中Flush Flag占用最高位bit,标识一次IO的第一个Block,剩下的31个个bit是Block编号;之后是2字节的数据长度,取值在[12,508];紧接着2字节的First Record Offset用来指向Block中第一个Redo组的开始,这个值的存在使得我们对任何一个Block都可以找到一个合法的的Redo开始位置;最后的4字节Checkpoint Number记录写Block时的next_checkpoint_number,用来发现文件的循环使用,这个会在文件层详细讲解。Block末尾是4字节的Block Tailer,记录当前Block的Checksum,通过这个值,读取Log时可以明确Block数据有没有被完整写盘。

Block中剩余的中间498个字节就是Redo真正内容的存放位置,也就是我们上面说的逻辑Redo。我们现在将逻辑Redo放到物理Redo空间中,由于Block内的空间固定,而Redo长度不定,因此可能一个Block中有多个Redo,也可能一个Redo被拆分到多个Block中。
产生和清除
事务在写入数据的时候会产生Redo,一次原子的操作可能会包含多条Redo记录,这些Redo可能是访问同一Page的不同位置,也可能是访问不同的Page(如Btree节点分裂)。InnoDB有一套完整的机制来保证涉及一次原子操作的多条Redo记录原子,即恢复的时候要么全部重放,要不全部不重放。
为了尽量减少恢复时需要重放的Redo,InnoDB引入log_checkpointer线程周期性的打Checkpoint。重启恢复的时候,只需要从最新的Checkpoint开始回放后边的Redo,因此Checkpoint之前的Redo就可以删除或被复用。我们知道REDO的作用是避免只写了内存的数据由于故障丢失,那么打Checkpiont的位置就必须保证之前所有Redo所产生的内存脏页都已经刷盘。最直接的,可以从Buffer Pool中获得当前所有脏页对应的最小Redo LSN:lwm_lsn。 但光有这个还不够,因为有一部分REDO对应的Page还没有来的及加入到Buffer Pool的脏页中去,如果checkpoint打到这些REDO的后边,一旦这时发生故障恢复,这部分数据将丢失,因此还需要知道当前已经加入到Buffer Pool的Redo lsn位置:dpa_lsn。取二者的较小值作为最终checkpoint的位置。
undo log
Undo Log是InnoDB十分重要的组成部分,它的作用横贯InnoDB中两个最主要的部分,并发控制(Concurrency Control)和故障恢复(Crash Recovery),InnoDB中Undo Log的实现亦日志亦数据。InnoDB中的Undo Log采用了基于事务的Logical Logging的方式。InnoDB中其实是把Undo当做一种数据来维护和使用的,也就是说,Undo Log日志本身也像其他的数据库数据一样,会写自己对应的Redo Log,通过Redo Log来保证自己的原子性。
Undo Log内容
每当InnoDB中需要修改某个Record时,都会将其历史版本写入一个Undo Log中,对应的Undo Record是Update类型。当插入新的Record时,还没有一个历史版本,但为了方便事务回滚时做逆向(Delete)操作,这里还是会写入一个Insert类型的Undo Record。
-
Insert类型的Undo Record
这种Undo Record在代码中对应的是TRX_UNDO_INSERT_REC类型。不同于Update类型的Undo Record,Insert Undo Record仅仅是为了可能的事务回滚准备的,并不在MVCC功能中承担作用。因此只需要记录对应Record的Key,供回滚时查找Record位置即可。
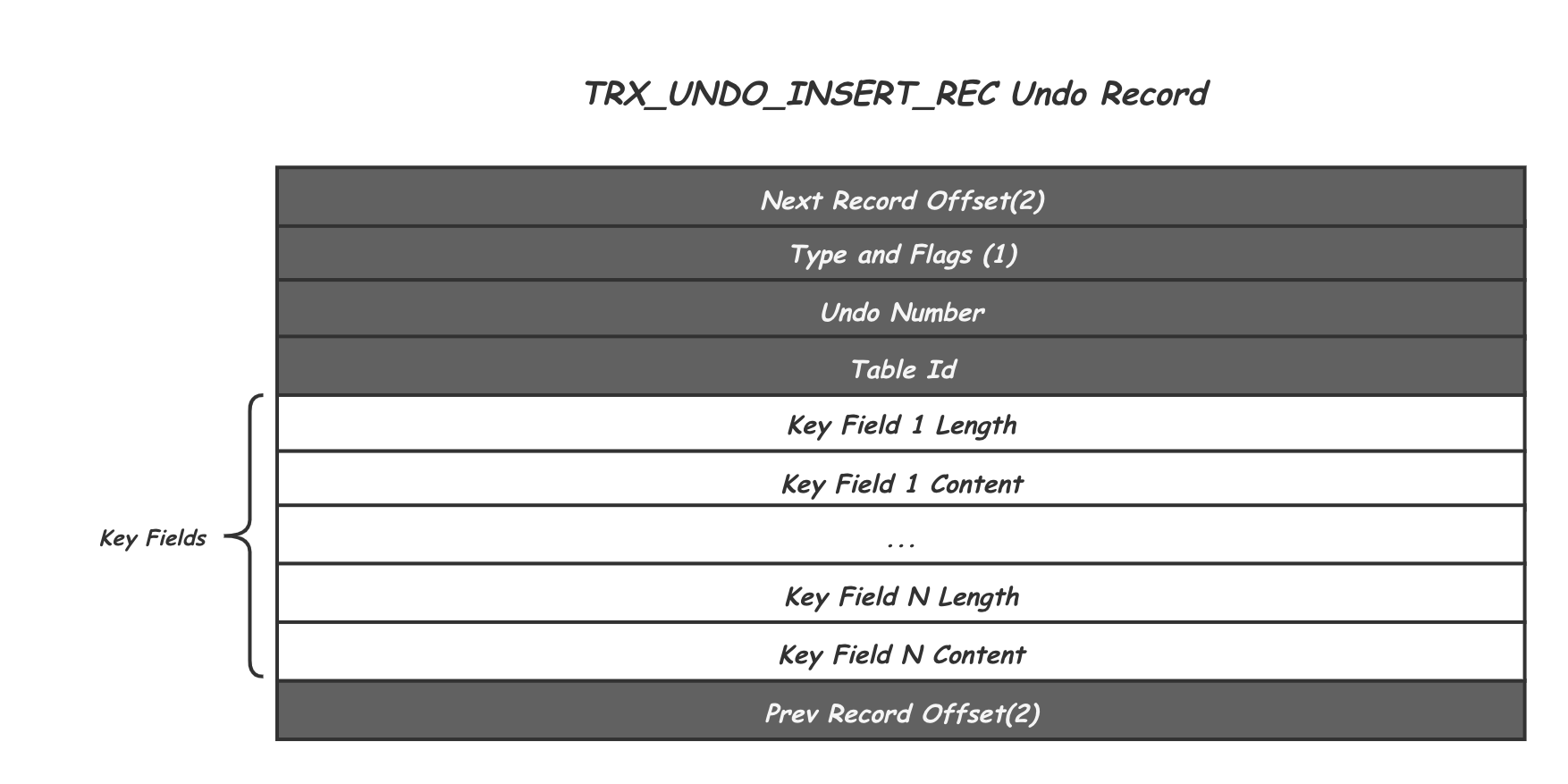
其中Undo Number是Undo的一个递增编号,Table ID用来表示是哪张表的修改。下面一组Key Fields的长度不定,因为对应表的主键可能由多个field组成,这里需要记录Record完整的主键信息,回滚的时候可以通过这个信息在索引中定位到对应的Record。除此之外,在Undo Record的头尾还各留了两个字节用户记录其前序和后继Undo Record的位置。 -
Update类型的Undo Record
由于MVCC需要保留Record的多个历史版本,当某个Record的历史版本还在被使用时,这个Record是不能被真正的删除的。因此,当需要删除时,其实只是修改对应Record的Delete Mark标记。对应的,如果这时这个Record又重新插入,其实也只是修改一下Delete Mark标记,也就是将这两种情况的delete和insert转变成了update操作。再加上常规的Record修改,因此这里的Update Undo Record会对应三种Type:TRX_UNDO_UPD_EXIST_REC、TRX_UNDO_DEL_MARK_REC和TRX_UNDO_UPD_DEL_REC。他们的存储内容也类似:
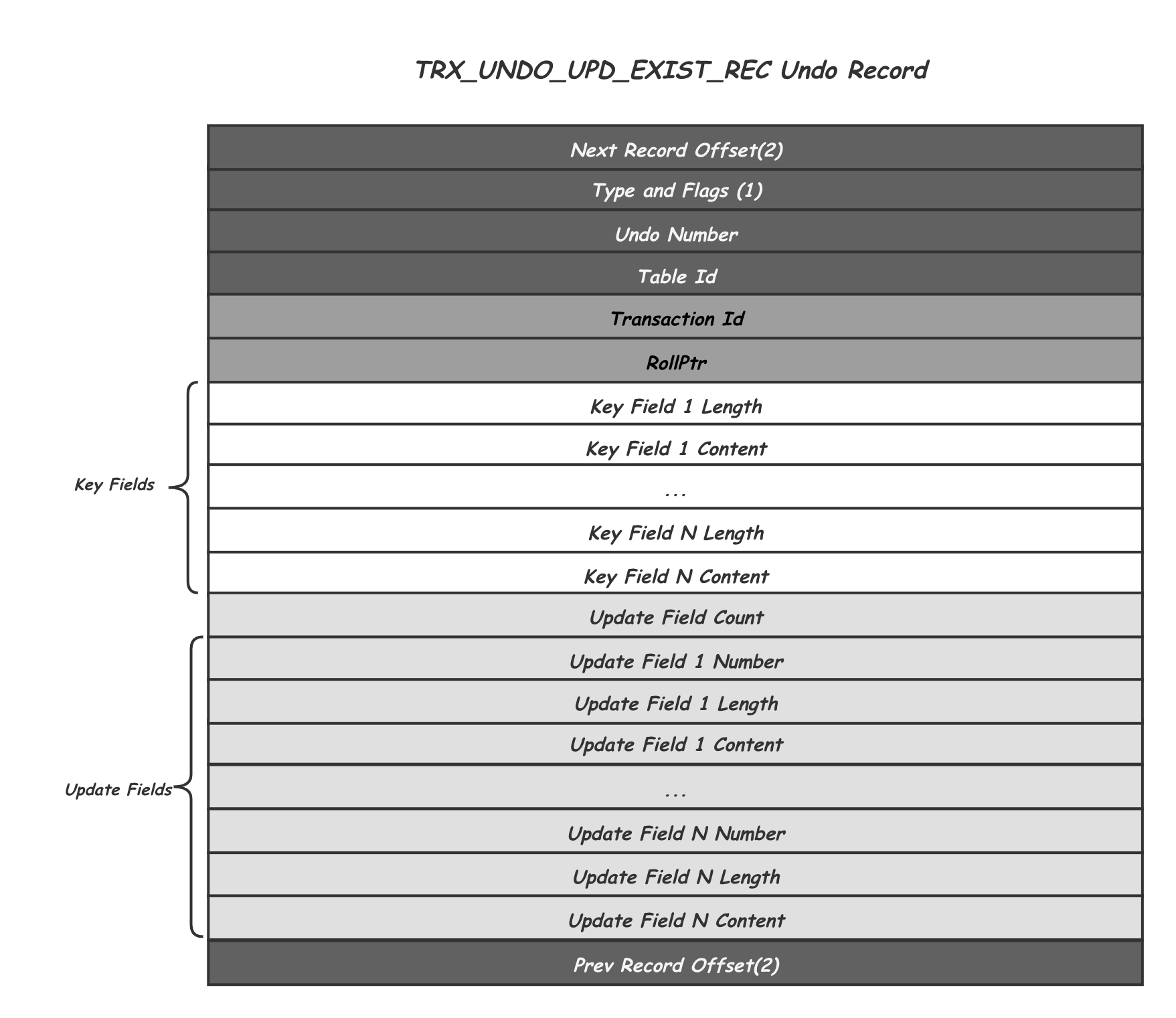
除了跟Insert Undo Record相同的头尾信息,以及主键Key Fileds之外,Update Undo Record增加了: -
Transaction Id记录了产生这个历史版本事务Id,用作后续MVCC中的版本可见性判断
-
Rollptr指向的是该记录的上一个版本的位置,包括space number,page number和page内的offset。沿着Rollptr可以找到一个Record的所有历史版本。
-
Update Fields中记录的就是当前这个Record版本相对于其之后的一次修改的Delta信息,包括所有被修改的Field的编号,长度和历史值。
每个事务其实会修改一组的Record,对应的也就会产生一组Undo Record,这些Undo Record收尾相连就组成了这个事务的Undo Log。除了一个个的Undo Record之外,还在开头增加了一个Undo Log Header来记录一些必要的控制信息。
Undo Log Header中记录了产生这个Undo Log的事务的Trx ID;Trx No是事务的提交顺序,也会用这个来判断是否能Purge;Delete Mark标明该Undo Log中有没有TRX_UNDO_DEL_MARK_REC类型的Undo Record,避免Purge时不必要的扫描;Log Start Offset中记录Undo Log Header的结束位置,方便之后Header中增加内容时的兼容;之后是一些Flag信息;Next Undo Log及Prev Undo Log标记前后两个Undo Log;最后通过History List Node将自己挂载到为Purge准备的History List中。
索引中的同一个Record被不同事务修改,会产生不同的历史版本,这些历史版本又通过Rollptr穿成一个链表,供MVCC使用。
Undo Log的文件存储
一个事务会产生多大的Undo Log本身是不可控的,而最终写入磁盘却是按照固定的块大小为单位的,InnoDB中默认是16KB,那么如何用固定的块大小承载不定长的Undo Log,以实现高效的空间分配、复用,避免空间浪费。InnoDB的基本思路是让多个较小的Undo Log紧凑存在一个Undo Page中,而对较大的Undo Log则随着不断的写入,按需分配足够多的Undo Page分散承载。下面我们就看看这部分的物理存储方式:
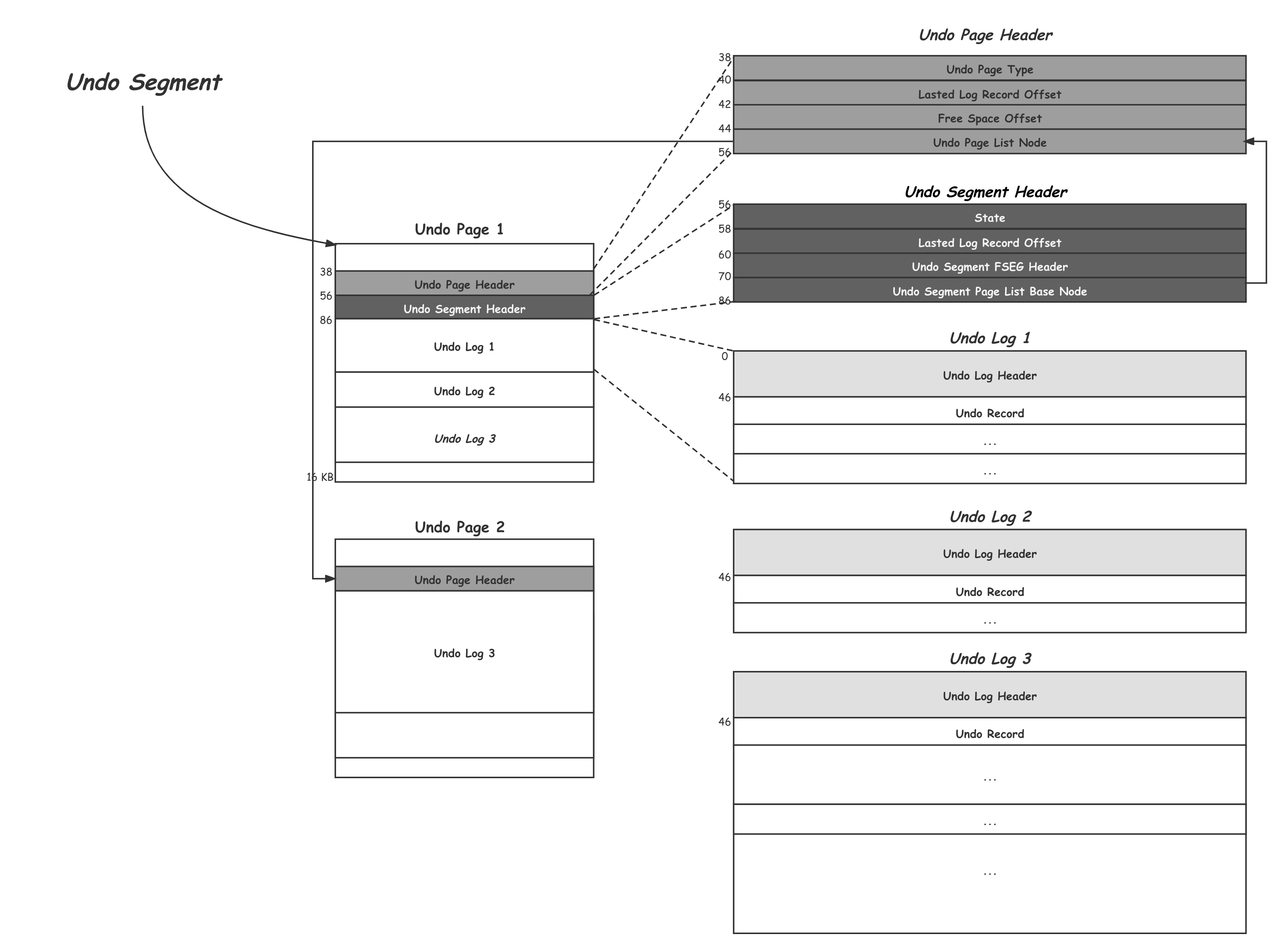
如上所示,是一个Undo Segment的示意图,每个写事务开始写操作之前都需要持有一个Undo Segment,一个Undo Segment中的所有磁盘空间的分配和释放。
Undo Log的内存存储
上面介绍的都是Undo数据在磁盘上的组织结构,除此之外,在内存中也会维护对应的数据结构来管理Undo Log,如下图所示:
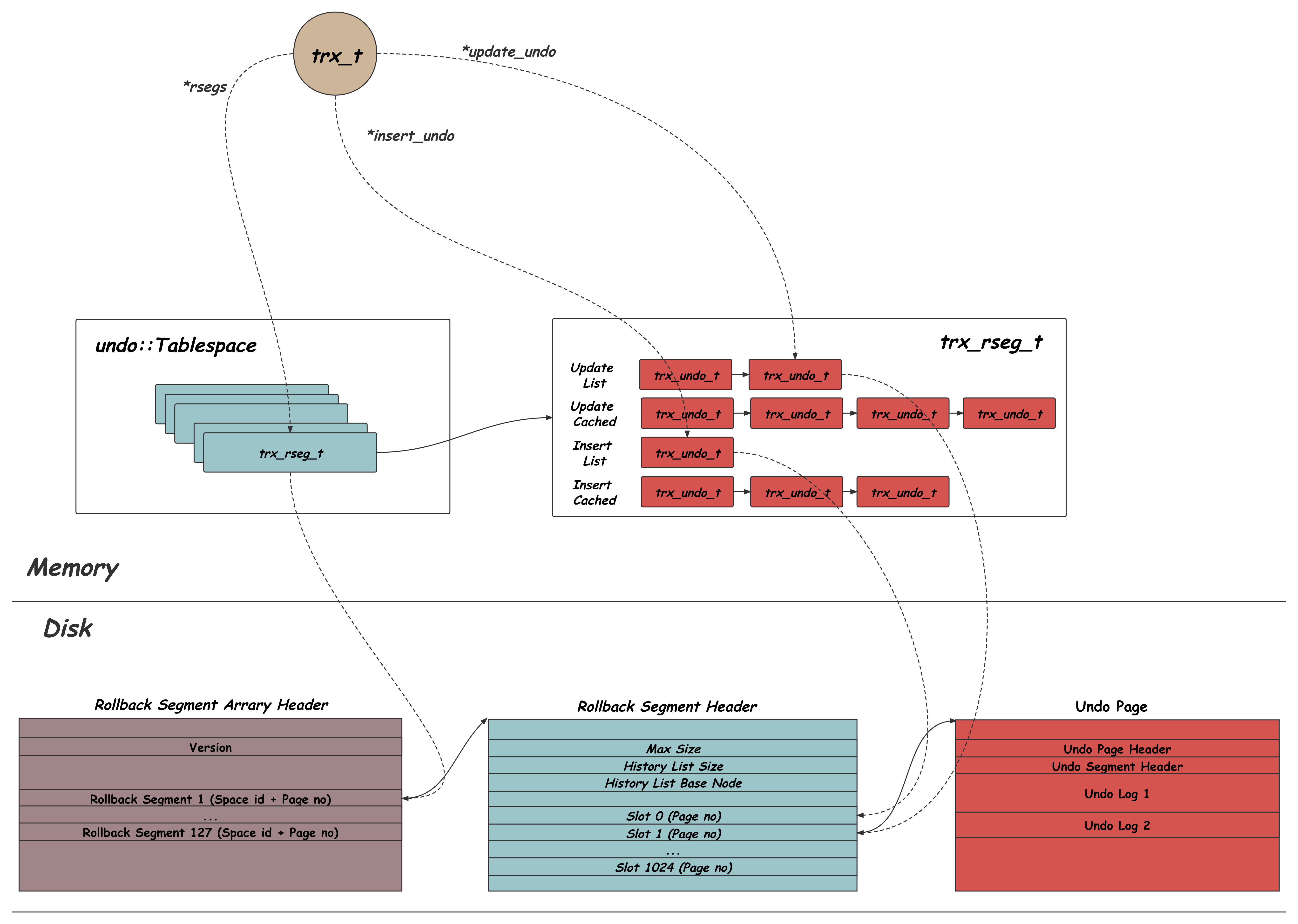
对应每个磁盘Undo Tablespace会有一个undo::Tablespace的内存结构,其中最主要的就是一组trx_rseg_t的集合,trx_rseg_t对应的就是上面介绍过的一个Rollback Segment Header,除了一些基本的元信息之外,trx_rseg_t中维护了四个trx_undo_t的链表,Update List中是正在被使用的用于写入Update类型Undo的Undo Segment;Update Cache List中是空闲空间比较多,可以被后续事务复用的Update类型Undo Segment;对应的,Insert List和Insert Cache List分别是正在使用中的Insert类型Undo Segment。
Undo Log写入
当写事务开始时,会先通过trx_assign_rseg_durable分配一个Rollback Segment,该事务的内存结构trx_t也会通过rsegs指针指向对应的trx_rseg_t内存结构,这里的分配策略很简单,就是依次尝试下一个Active的Rollback Segment。之后当第一次真正产生修改需要写Undo Record的时,会调用trx_undo_assign_undo来获得一个Undo Segment。这里会优先复用trx_rseg_t上Cached List中的trx_undo_t,也就是已经分配出来但没有被正在使用的Undo Segment,如果没有才调用trx_undo_create创建新的Undo Segment。
获得了可用的Undo Segment之后,该事务会在合适的位置初始化自己的Undo Log Header,之后,其所有修改产生的Undo Record都会顺序的通过trx_undo_report_row_operation顺序的写入当前的Undo Log,其中会根据是insert还是update类型,分别调用trx_undo_page_report_insert或者trx_undo_page_report_modify。
当一个Page写满后,会调用trx_undo_add_page来在当前的Undo Segment上添加新的Page,新Page写入Undo Page Header之后继续供事务写入Undo Record,为了方便维护,这里有一个限制就是单条Undo Record不跨page,如果当前Page放不下,会将整个Undo Record写入下一个Page。
当事务结束(commit或者rollback)之后,如果只占用了一个Undo Page,且当前Undo Page使用空间小于page的,这个Undo Segment会保留并加入到对应的insert/update cached list中。否则,insert类型的Undo Segment会直接回收,而update类型的Undo Segment会等待后台的Purge做完后回收。对应的Redo落盘之后,就可以返回用户结果,并且Crash Recovery之后也不会再做回滚处理。
Undo用于回滚
InnoDB中的事务可能会由用户主动触发Rollback;也可能因为遇到死锁异常Rollback;或者发生Crash,重启后对未提交的事务回滚。在Undo层面来看,这些回滚的操作是一致的,基本的过程就是从该事务的Undo Log中,从后向前依次读取Undo Record,并根据其中内容做逆向操作,恢复索引记录。完成回滚的Undo Log部分,会调用trx_roll_try_truncate进行回收,对不再使用的page调用trx_undo_free_last_page将磁盘空间交还给Undo Segment,这个是写入过程中trx_undo_add_page的逆操作。
Undo用于MVCC
在读事务第一次读取的时候获取一份ReadView,并一直持有,其中记录所有当前活跃的写事务ID,由于写事务的ID是自增分配的,通过这个ReadView我们可以知道在这一瞬间,哪些事务已经提交哪些还在运行,根据Read Committed的要求,未提交的事务的修改就是不应该被看见的,对应地,已经提交的事务的修改应该被看到。
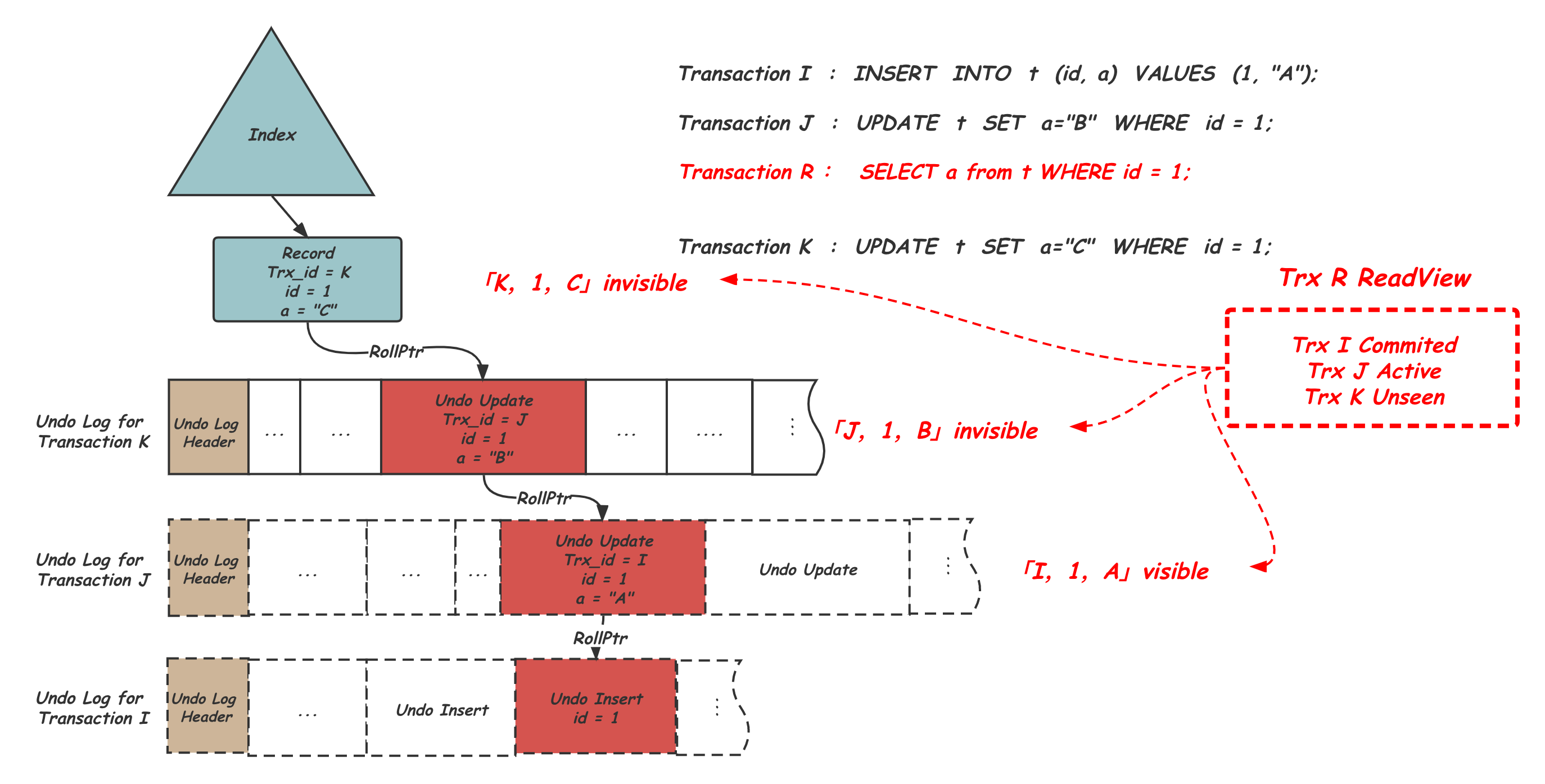
其中记录的trx_id就是做这个可见性判断的,对应的主索引的Record上也有这个值。当一个读事务拿着自己的ReadView访问某个表索引上的记录时,会通过比较Record上的trx_id确定是否是可见的版本,如果不可见就沿着Record或Undo Record中记录的rollptr一路找更老的历史版本。作为Logical Log,Undo中记录的其实是前后两个版本的diff信息,而读操作最终是要获得完整的Record内容的,也就是说这个沿着rollptr指针一路查找的过程中需要用Undo Record中的diff内容依次构造出对应的历史版本,如果是rollptr指向的是insert类型,或者找到了已经Purge了的位置,说明到头了,会直接返回失败。否则,就会解析对应的Undo Record,恢复出trx_id、指向下一条Undo Record的rollptr、主键信息,diff信息,update vector等信息。之后用update vector修改当前持有的Record拷贝中的信息,获得Record的这个历史版本。之后调用自己ReadView的changes_visible判断可见性,如果可见则返回用户。完成这个历史版本的读取。
Undo用于故障恢复
Crash Recovery的过程中会先重放所有的Redo Log,整个Undo的磁盘组织结构,也会作为一种数据类型也会通过上面讲到的这些Redo类型的重放恢复出来。之后在trx_sys_init_at_db_start中会扫描Undo的磁盘结构,遍历所有的Rollback Segment和其中所有的Undo Segment,通过读取Undo Segment Header中的State,可以知道在Crash前,最后持有这个Undo Segment的事务状态。
Undo清理
InnoDB中每个写事务结束时都会拿一个递增的编号trx_no作为事务的提交序号,而每个读事务会在自己的ReadView中记录自己开始的时候看到的最大的trx_no为m_low_limit_no。那么,如果一个事务的trx_no小于当前所有活跃的读事务Readview中的这个m_low_limit_no,说明这个事务在所有的读开始之前已经提交了,其修改的新版本是可见的, 因此不再需要通过undo构建之前的版本,这个事务的Undo Log也就可以被清理了。
事务结束的时候,对于需要Purge的Update类型的Undo Log,会按照事务提交的顺序trx_no,挂载到Rollback Segment Header的History List上。Undo Log回收的基本思路,就是按照trx_no从小到大,依次遍历所有Undo Log进行清理操作。
当需要删除某个Record时,为了保证其之前的历史版本还可以通过Rollptr找到,Record是没有真正删除的,只是打了Delete Mark的标记,并作为一种特殊的Update操作记录了Undo Record。在删除索引上被标记为Delete Mark的Record时,worker线程会在row_purge函数中,循环处理每一个Undo Records,先依次从Undo Record中解析出type、table_id、rollptr、对应记录的主键信息以及update vector。之后将需要删除的记录从所有的二级索引上删除和主索引上删除。
在以上过程结束后,InnoDB尝试清理不再需要的Undo Log,trx_purge_truncate函数中会遍历所有的Rollback Segment中的所有Undo Segment,如果其状态是TRX_UNDO_TO_PURGE,调用trx_purge_free_segment释放占用的磁盘空间并从History List中删除。否则,说明该Undo Segment正在被使用或者还在被cache(TRX_UNDO_CACHED类型),那么只通过trx_purge_remove_log_hd将其从History List中删除。
binlog
锁和事务子系统
(文章没有开源许可证,我是看了文章然后自己总结的)
MySQL的锁和加锁的规则
MySQL是支持MVCC实现并发控制的数据库系统,在MVCC中,读可以分成当前读(Current Read,CR)和快照读(Snapshot Read,SR)。快照读不加锁,读取的是历史版本的记录,当前读是读记录的最新版本,需要加锁。MySQL加锁使用2PL协议,即加锁和解锁是两个不相交的过程。MySQL中的锁有表锁,行锁和页面锁。
在一个MySQL中,一般的简单读操作都是快照读。但是有些特殊的操作是当前读,如:
select * from t where cond lock in share mode;
select * from t where cond for update;
insert into table values(...);
update t set value where cond;
delete from t where cond;
其中,除了第一条语句会对记录加S锁之外,其他都加X锁。
MySQL支持4种隔离级别,一般用得比较多的是RC(Read Committed)和RR(Repeatable Read),RC只对读取到的记录加锁,所以不能控制它的旁边会不会插入新元素,存在幻读,RR会加gap锁以控制其相邻位置不会插入新元素导致幻读。
(接下来是按索引+隔离级别分别考虑加锁的情况,本文略,请参考原文)
事务子系统
有点大的坑,先贴个链接占坑吧
概论:
https://zhuanlan.zhihu.com/p/365415843
细节:
http://mysql.taobao.org/monthly/2015/12/01/
join算法
MySQL中的join算法主要有以下3种:Simple Nested Loop,Index Nested Loop,Block Nested Loop。
Simple Nested Loop是指直接用双重循环完成join的条件检测和配对,效率极低。
Index Nested Loops是指在有索引的列上直接通过索引进行匹配,效率最高,匹配次数只需要。
Block Nested Loop是在Simple Nested Loop的基础上增加一层内层表的缓存,这样子就不需要多次磁盘IO读取表的数据。
调用关系:S几乎不会调用,I在有索引的列上使用,B在I不能满足条件时使用,如果优化器分析发现join条件过多,B的缓存无法发挥效力,也会尝试用S。
参考
http://mysql.taobao.org/monthly/2017/05/01/
https://catkang.github.io/2020/02/27/mysql-redo.html
https://catkang.github.io/2021/10/30/mysql-undo.html
https://dev.mysql.com/blog-archive/mysql-8-0-new-lock-free-scalable-wal-design/
https://zhuanlan.zhihu.com/p/227864607
https://github.com/hedengcheng/tech/blob/master/database/MySQL/MySQL%20%E5%8A%A0%E9%94%81%E5%A4%84%E7%90%86%E5%88%86%E6%9E%90.pdf
https://www.cnblogs.com/xibuhaohao/p/11947041.html
http://mysql.taobao.org/monthly/2015/12/01/
https://zhuanlan.zhihu.com/p/365415843
https://zhuanlan.zhihu.com/p/54275505


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!