
ODS公共层作业设计方案
结合目前工作,做个笔记。
1.背景:
ODS层属于贴源层,通常都是全量从业务库抽取到数仓,为了不冗余过多的程序,做成公共作业,只需配置补录表即可。
2.相关参数表:
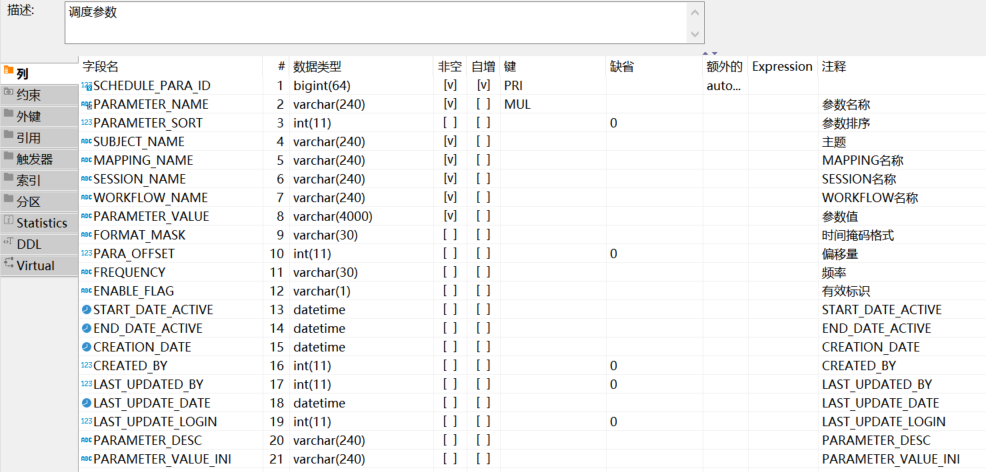
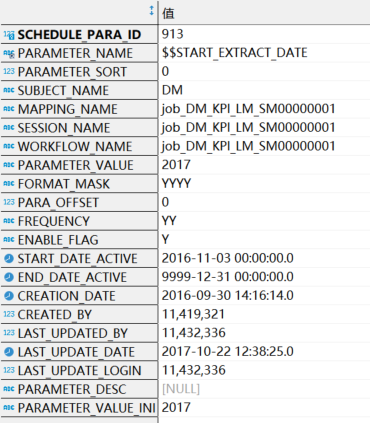
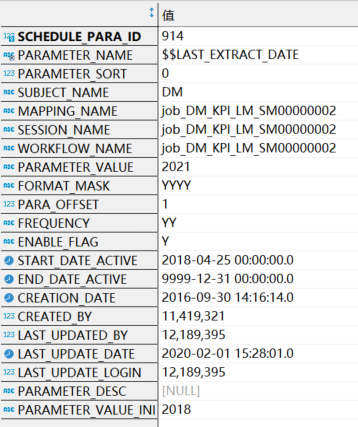
a).apd.apd_fnd_schedule_parameter:存放作业的一些开始结束时间(这里指传的参数),日期格式,时间偏移量等信息。表结构与数据样例如下:
表结构:
数据样例
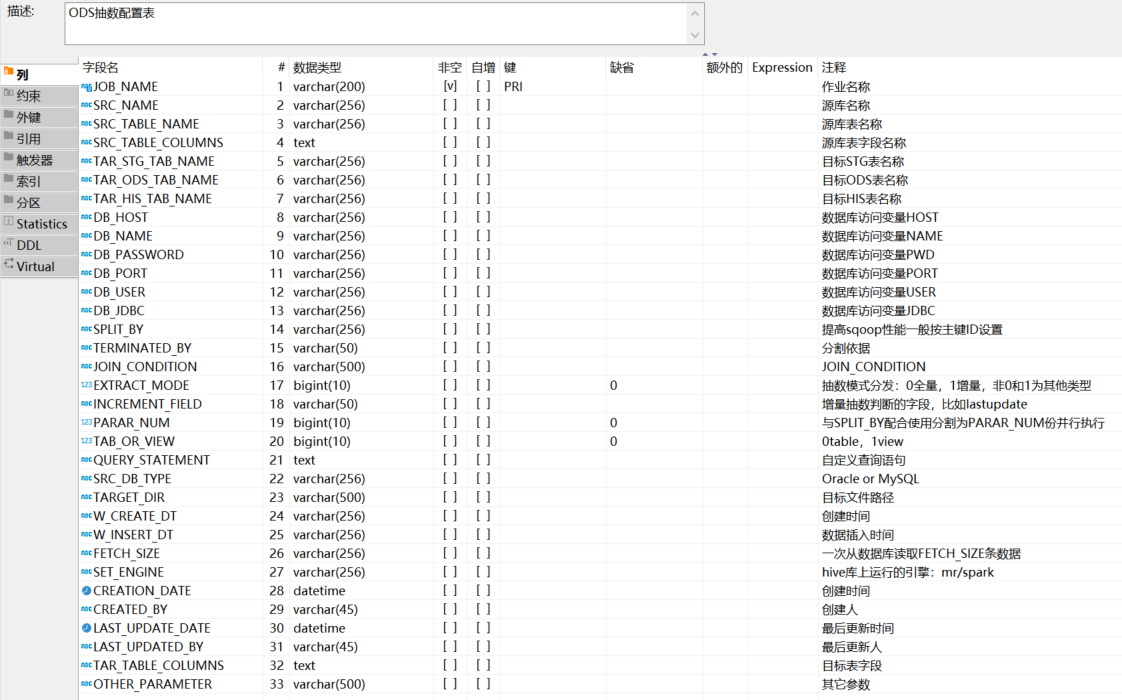
b).apd.apd_ods_parameter:存放数据库连接信息,数据源字段,目标表字段,等信息数据。‘
表结构:
样例数据:

ods表,有3个,分别是stg表,正常表,his表,例如test_stg,test,test_his,描述如下:
test_stg:临时表的作用,主要是用来保存从ods导入过来的数据。
test:当前表,保存的最新的数据。
test_his:历史表,以时间作为分区,例如part_dt,格式为yyyy-mm-dd(2019-08-01)。
3.步骤:
a).读取apd.apd_fnd_schedule_parameter里面的信息,获取时间。
SELECT A.PARAMETER_VALUE AS START_DATE ,B.PARAMETER_VALUE AS END_DATE ,case when A.FREQUENCY = 'DD' THEN date_format(date_sub(str_to_date(A.PARAMETER_VALUE,'%Y-%m-%d'), interval 1 day),'%Y-%m-%d') when A.FREQUENCY = 'MM' THEN date_format(date_sub(str_to_date(A.PARAMETER_VALUE,'%Y-%m-%d'), interval 1 day),'%Y-%m-%d') when A.FREQUENCY = 'YY' THEN date_format(date_sub(str_to_date(A.PARAMETER_VALUE,'%Y-%m-%d'), interval 1 day),'%Y-%m-%d') ELSE '0' END AS BEFORE_DATE ,case when A.FREQUENCY = 'DD' THEN date_format(date_sub(str_to_date(A.PARAMETER_VALUE,'%Y-%m-%d'), interval 1 month),'%Y-%m-%d') when A.FREQUENCY = 'MM' THEN date_format(date_sub(str_to_date(A.PARAMETER_VALUE,'%Y-%m-%d'), interval 1 month),'%Y-%m-%d') when A.FREQUENCY = 'YY' THEN date_format(date_sub(str_to_date(A.PARAMETER_VALUE,'%Y-%m-%d'), interval 1 month),'%Y-%m-%d') ELSE '0' END AS BEFORE_MONTH ,REPLACE(A.PARAMETER_VALUE,'-','') AS CUR_DATE_WID FROM ${MDW_SCHEDULE_PARAMETER_TABLE} A LEFT JOIN ${MDW_SCHEDULE_PARAMETER_TABLE} B ON A.WORKFLOW_NAME = B.WORKFLOW_NAME AND B.PARAMETER_NAME = '$$LAST_EXTRACT_DATE' WHERE A.PARAMETER_NAME = '$$START_EXTRACT_DATE' AND A.WORKFLOW_NAME = '${KETTLE_JOB_NAME}'
b).获取apd.apd_ods_parameter里面的信息。
SELECT C.JOB_NAME ,C.SRC_NAME ,C.SRC_TABLE_NAME ,C.SRC_TABLE_COLUMNS ,C.TAR_STG_TAB_NAME ,C.TAR_ODS_TAB_NAME ,C.TAR_HIS_TAB_NAME ,C.DB_HOST ,C.DB_NAME ,C.DB_PASSWORD ,C.DB_PORT ,C.DB_USER ,C.DB_JDBC ,C.SPLIT_BY ,C.TERMINATED_BY ,C.JOIN_CONDITION ,C.EXTRACT_MODE ,C.INCREMENT_FIELD ,C.PARAR_NUM ,C.TAB_OR_VIEW ,C.QUERY_STATEMENT ,C.SRC_DB_TYPE ,C.TARGET_DIR ,C.FETCH_SIZE ,C.SET_ENGINE ,C.TAR_TABLE_COLUMNS ,C.OTHER_PARAMETER FROM APD_ODS_PARAMETER C WHERE C.JOB_NAME = '${KETTLE_JOB_NAME}';
c).通过sqoop工具,将业务库的数据导入到大数据平台的表。
sqoop import \ --hive-import \ --hive-table ${TAR_STG_TAB_NAME} \ --hive-drop-import-delims \ --hive-overwrite \ --connect '${DB_JDBC}' \ --username ${DB_USER} \ --password ${DB_PASSWORD} \ --query '${QUERY_STATEMENT}' \ --target-dir ${TARGET_DIR} \ --delete-target-dir \ --null-string '\\N' \ --null-non-string '\\N' \ --fields-terminated-by '${TERMINATED_BY}' \ --split-by ${SPLIT_BY} -m ${PARAR_NUM} \ --fetch-size ${FETCH_SIZE} \ --hive-drop-import-delims --lines-terminated-by '\n' \ --mapreduce-job-name ${JOB_NAME} \ ${OTHER_PARAMETER}
d).然后通过hive层面的语法,将ods的stg表同步到正常表,跟his表中。
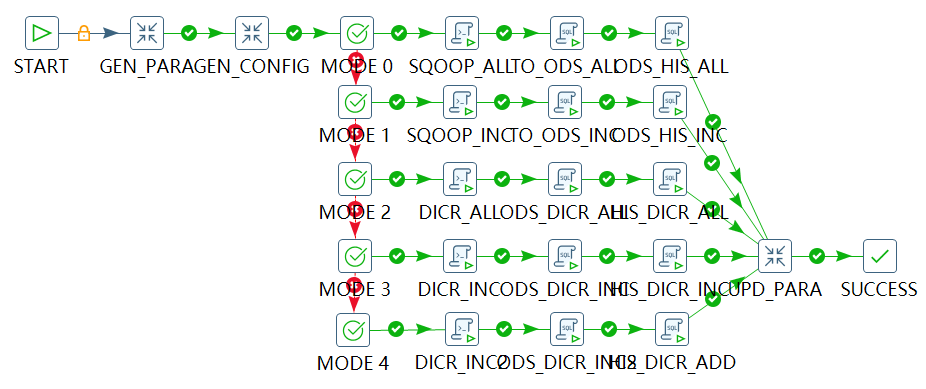
--TO_ODS_ALL set hive.execution.engine = ${SET_ENGINE}; set spark.app.name = ${JOB_NAME}; set mapred.job.name=${JOB_NAME}:TO_ODS_ALL; set mapreduce.job.queuename=${MDW_DEFAULT_QUEUE}; INSERT OVERWRITE TABLE ${TAR_ODS_TAB_NAME} SELECT ${TAR_TABLE_COLUMNS} FROM ${TAR_STG_TAB_NAME} --ODS_HIS_ALL set hive.execution.engine = ${SET_ENGINE}; set spark.app.name = ${JOB_NAME}; set mapred.job.name=${JOB_NAME}:ODS_HIS_ALL; set mapreduce.job.queuename=${MDW_DEFAULT_QUEUE}; INSERT OVERWRITE TABLE ${TAR_HIS_TAB_NAME} PARTITION (PART_DT='${START_DATE}') SELECT * FROM ${TAR_ODS_TAB_NAME}
sqoop参数参考地址:http://www.360doc.com/content/16/1116/10/37253246_606951065.shtml

 浙公网安备 33010602011771号
浙公网安备 33010602011771号