很久没有写博客了,最近一直忙于找工作,心都没办法安静下来。通过最近的面试,也给自己暴露了不少问题,其中很重要的一块就是数据库,因为项目的原因,最近两年在文思的香港马会的项目组都没有使用过数据库,所以数据库这一块也成了我的短板,所以也借离职在家这段时间,系统地回顾一下数据库的知识,我会写成一个系列并坚持写下去。
先从select语句写起,因为它是学习T-SQL的基础。首先总结一下select语句逻辑处理顺序,如下,下面按照逻辑顺序来总结。
from
where
group by
having
select
over
distinct
top
order by
from子句
from子句是在逻辑处理阶段第一个要处理的查询子句。它是用来指定要查询的表名,以及对表进行操作的表运算符。下面的例子是对Sales数据库架构中的Orders表进行查询,看sql语句:
SELECT orderid,custid,empid,orderdate,freight FROM Sales.Orders;
执行结果:
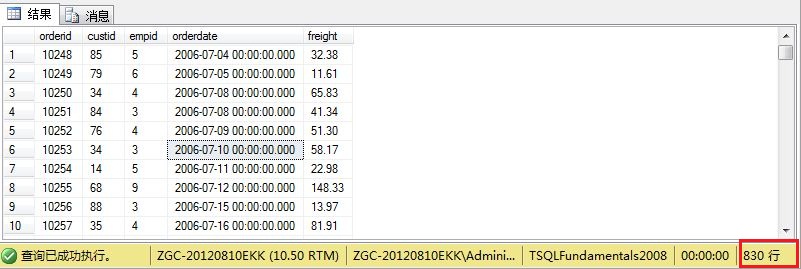
注意:1> 应该总是用数据库架构来限定代码中的对象名称,如Sales.Order。
2> 应该显示指定要查询的列,避免一些额外的代价。
3> select出的结果看起来是以特定的顺序返回(以orderid的升序排列)的, 但不能保证绝对这样。
4> Sql server分隔标识符使用方括号,如[Order Details]
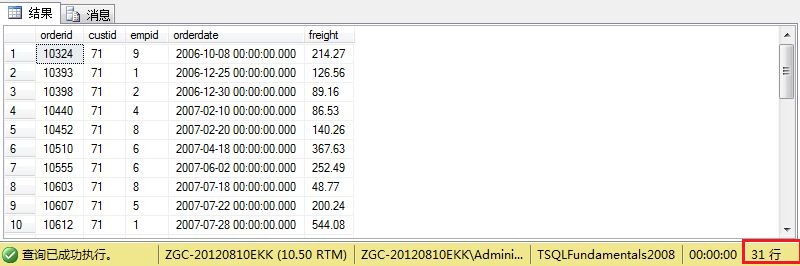
where子句
它的作用是过滤由from阶段返回的行,可以指定一个谓词或逻辑表达式。如where阶段只保留id为71的客户下的订单,sql代码如下:
SELECT orderid,custid,empid,orderdate,freight FROM Sales.Orders WHERE custid=71;
程序输出结果为:
group by子句
group by阶段可以将前面逻辑查询处理阶段返回的行按“组”进行组合,每个组由在group by子句中指定的各元素决定。如对于where阶段返回的数据中出现的每个雇员id和订单年份值的唯一组合,sql代码如下:
SELECT empid , YEAR(orderdate) AS orderyear , SUM(freight) AS totalfreight , COUNT(*) AS numorders FROM Sales.Orders WHERE custid = 71 GROUP BY empid , YEAR(orderdate);
程序输出结果为: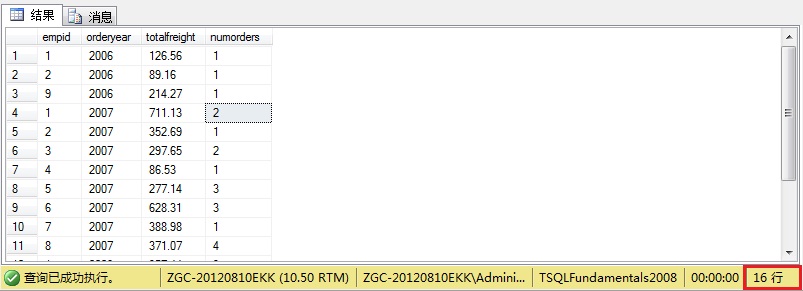
注意:1,group by阶段之后的所有阶段(包括having,select以及order by)的操作对象都是组。比如这里是select。
2,一个元素如果不在group by列表中出现,就只能作为聚合函数(Count,Sum,Avg,Min以及Max)的输入,比如这里的Sum和Count函数。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架