drf认证源码分析
补充:
一、django中间件之路由斜杠的自动添加源码
其实我们每次在写路由的时候,如果在路由层给他设置的是加/,但实际上我们在浏览器中输入的时候并没有加/发现也能调用,前面说了是浏览器内部走了重定向,所以会自动的给我们加上/匹配,但是难道我们就不好奇究竟是谁让他内部走了重定向吗?
想想,它在第一次来的时候没有匹配上路由就会直接重定向,那他肯定是还没走到视图层,在想一想django的请求生命周期,来了请求之后,进入django内部是不是要先经过什么?好像是中间件!!那就必然和中间件有某种关系,然后我们在去查看中间件的源码的时候,发现了果然如此!
# 查看中间件源码的方式 from django.middleware.common import CommonMiddleware MIDDLEWARE = [ 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', # 内部重定向,刚开始没有斜杠会自动加斜杠,内部走了301重定向 'django.middleware.common.CommonMiddleware', # 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', ]
我们看了一下是CommonMiddleware这个中间件做的鬼,那我们就点进去看看!


class CommonMiddleware(MiddlewareMixin): """ "Common" middleware for taking care of some basic operations: - Forbids access to User-Agents in settings.DISALLOWED_USER_AGENTS - URL rewriting: Based on the APPEND_SLASH and PREPEND_WWW settings, this middleware appends missing slashes and/or prepends missing "www."s. - If APPEND_SLASH is set and the initial URL doesn't end with a slash, and it is not found in urlpatterns, a new URL is formed by appending a slash at the end. If this new URL is found in urlpatterns, then an HTTP-redirect is returned to this new URL; otherwise the initial URL is processed as usual. This behavior can be customized by subclassing CommonMiddleware and overriding the response_redirect_class attribute. - ETags: If the USE_ETAGS setting is set, ETags will be calculated from the entire page content and Not Modified responses will be returned appropriately. USE_ETAGS is deprecated in favor of ConditionalGetMiddleware. """ response_redirect_class = http.HttpResponsePermanentRedirect # 点进去看看,发现内部走了重定向 class HttpResponsePermanentRedirect(HttpResponseRedirectBase): status_code = 301
发现在内部其实是走了301重定向
二、django模型表之一对一关系源码
入口
class Book(models.Model): title = models.CharField(max_length=32) price = models.IntegerField() # 就是它👇👇👇 book_detail = models.OneToOneField(to='self') pub_date = models.DateField() publish = models.ForeignKey("Publish") authors = models.ManyToManyField("Author")
内部源码
class OneToOneField(ForeignKey): """ A OneToOneField is essentially the same as a ForeignKey, with the exception that it always carries a "unique" constraint with it and the reverse relation always returns the object pointed to (since there will only ever be one), rather than returning a list. """ # Field flags many_to_many = False many_to_one = False one_to_many = False one_to_one = True related_accessor_class = ReverseOneToOneDescriptor forward_related_accessor_class = ForwardOneToOneDescriptor rel_class = OneToOneRel description = _("One-to-one relationship") def __init__(self, to, on_delete=None, to_field=None, **kwargs): # 这里是直接添加上了unique kwargs['unique'] = True if on_delete is None: warnings.warn( "on_delete will be a required arg for %s in Django 2.0. Set " "it to models.CASCADE on models and in existing migrations " "if you want to maintain the current default behavior. " "See https://docs.djangoproject.com/en/%s/ref/models/fields/" "#django.db.models.ForeignKey.on_delete" % ( self.__class__.__name__, get_docs_version(), ), RemovedInDjango20Warning, 2) on_delete = CASCADE elif not callable(on_delete): warnings.warn( "The signature for {0} will change in Django 2.0. " "Pass to_field='{1}' as a kwarg instead of as an arg.".format( self.__class__.__name__, on_delete, ), RemovedInDjango20Warning, 2) to_field = on_delete on_delete = CASCADE # Avoid warning in superclass # 调用了父类的__init__方法,那我们就看看父类是做的什么 super(OneToOneField, self).__init__(to, on_delete, to_field=to_field, **kwargs)
我们看到实际上他还是调用了父类的__init__,而他的父类就是ForeignKey,所以虽然他是一对一,但是本质上还是调用了父类,也可以说本质上他就是ForeignKey,只不过自己的unique设置了True,可以理解为是外键,然后是一对多,但是我让那个字段变成了唯一,那就是只能对应一个了,所以就是一对一!
三、TOKEN
什么是token?token就是因为浏览器的HTTP是一个无状态无连接的,所以无法用来记录我们的登录状态,于是先诞生了cookie和session,将随机字符串存放在客户端的称为cookie,然后将保存在服务端的叫做session,但是这样子有个弊端,就是当用户越来越多,我们需要一个专门的电脑用来帮我们保存这个session,而且我们还得保证这个电脑一直处于一个开机状态,不能坏,一旦这个电脑挂点,就意味着所有的用户就会在一瞬间都得重新登录,那你这个网站估计也活不了多久,于是就想了一个新的方法,那就是token。
所谓的token就是服务端不在保存这个随机的字符串,我将这个随机的字符串通过某种加密算法,比如摘要算法,将生成的一个随机字符串在用户登录的时候直接发送过去,服务器这边就不保存,在服务器或者是移动端那边自己保存,比如里面的信息可以是这个用户的用户名和一些其他信息,再加上自己的算法产生的随机字符串,这样子就会完美的解决session的哪个问题,用户在下次登录的时候,我直接根据用户信息,取出里面的随机字符串,然后我通过自己的加密算法再算一遍,判断两者相不相同,如果相同,那么就是我这个网站已经登录过的用户,如果不相同,那么就代表着它是一个非法用户!
具体查看请点击https://www.cnblogs.com/liuqingzheng/articles/8990027.html👈👈👈
四、UUID
什么是uuid?
UUID 是 通用唯一识别码(Universally Unique Identifier)的缩写,是一种软件建构的标准,亦为开放软件基金会组织在分布式计算环境领域的一部分。其目的,是让分布式系统中的所有元素,都能有唯一的辨识信息,而不需要通过中央控制端来做辨识信息的指定。如此一来,每个人都可以创建不与其它人冲突的UUID。在这样的情况下,就不需考虑数据库创建时的名称重复问题。目前最广泛应用的UUID,是微软公司的全局唯一标识符(GUID),而其他重要的应用,则有Linux ext2/ext3文件系统、LUKS加密分区、GNOME、KDE、Mac OS X等等。另外我们也可以在e2fsprogs包中的UUID库找到实现。(来自百度百科)。
详细点击连接https://www.cnblogs.com/liuqingzheng/articles/9872350.html👈👈👈
我们这里是主要用他的几个方法来帮我们生成随机的id,并且这个id是全球唯一的,这样就可以保证了我们用户在访问的时候每个用户都有自己的记录状态,而且也不会混乱,具体使用如下。
导入
import uuid
使用
正文:在补充完这些信息之后,我们就正式开始吧!
认证源码分析
认证源码,进入还是从dispatch进入
def dispatch(self, request, *args, **kwargs): """ `.dispatch()` is pretty much the same as Django's regular dispatch, but with extra hooks for startup, finalize, and exception handling. """ self.args = args self.kwargs = kwargs # 这一步就是将原来的request变成了APIView的request request = self.initialize_request(request, *args, **kwargs) # 这里就是将对象自己的request变成了APIView的request方法,此时的request已经是新的request了 self.request = request self.headers = self.default_response_headers # deprecate? try: # 这一步就是权限认证 self.initial(request, *args, **kwargs)
走的是self,还是按照查找顺序查找!
def initial(self, request, *args, **kwargs): """ Runs anything that needs to occur prior to calling the method handler. """ self.format_kwarg = self.get_format_suffix(**kwargs) # Perform content negotiation and store the accepted info on the request neg = self.perform_content_negotiation(request) request.accepted_renderer, request.accepted_media_type = neg # Determine the API version, if versioning is in use. version, scheme = self.determine_version(request, *args, **kwargs) request.version, request.versioning_scheme = version, scheme # Ensure that the incoming request is permitted # 这三个分别是用户认证 self.perform_authentication(request) # 权限认证 self.check_permissions(request) # 频率认证 self.check_throttles(request)
然后我们点开用户认证进行查看
def perform_authentication(self, request): """ Perform authentication on the incoming request. Note that if you override this and simply 'pass', then authentication will instead be performed lazily, the first time either `request.user` or `request.auth` is accessed. """ # 在这里调用了user的方法/属性 request.user
发现在上面调用了request.user,这个user要么是属性,要么是方法,被封装成了属性!是真是假进去一看究竟!
首先我们得知道目前的的这个request是谁!它就是APIView自己写的那个新的request,所以我们还是要去它原来的产生request的类Request中查看,发现他果然有user这个方法
@property def user(self): """ Returns the user associated with the current request, as authenticated by the authentication classes provided to the request. """ if not hasattr(self, '_user'): with wrap_attributeerrors():
# 在返回之前,首先需要走self的这个方法 self._authenticate() return self._user
然后一看它果然是个方法,被封装成了属性,那我们接着去看,它现在的self就是Request对象
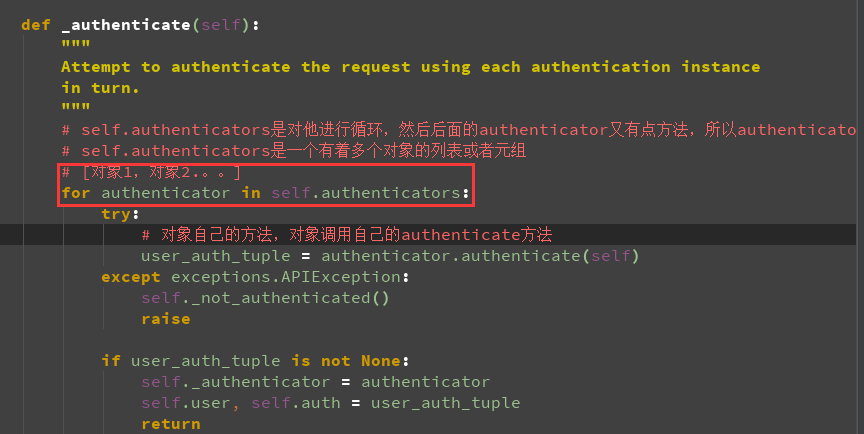
def _authenticate(self): """ Attempt to authenticate the request using each authentication instance in turn. """ # self.authenticators是对他进行循环,然后后面的authenticator又有点方法,所以authenticator肯定是个对象,那么猜测 # self.authenticators是一个有着多个对象的列表或者元组 for authenticator in self.authenticators: try: user_auth_tuple = authenticator.authenticate(self) except exceptions.APIException: self._not_authenticated() raise if user_auth_tuple is not None: self._authenticator = authenticator self.user, self.auth = user_auth_tuple return
点开一看就是这样
class Request(object): """ Wrapper allowing to enhance a standard `HttpRequest` instance. Kwargs: - request(HttpRequest). The original request instance. - parsers_classes(list/tuple). The parsers to use for parsing the request content. - authentication_classes(list/tuple). The authentications used to try authenticating the request's user. """ def __init__(self, request, parsers=None, authenticators=None, negotiator=None, parser_context=None): assert isinstance(request, HttpRequest), ( 'The `request` argument must be an instance of ' '`django.http.HttpRequest`, not `{}.{}`.' .format(request.__class__.__module__, request.__class__.__name__) ) self._request = request self.parsers = parsers or () # 对象自己的方法,是一个这个对象或者元组,接着找 self.authenticators = authenticators or ()
def initialize_request(self, request, *args, **kwargs): """ Returns the initial request object. """ parser_context = self.get_parser_context(request) return Request( request, parsers=self.get_parsers(), # 然后顺着self我们找到了这里,发现他是调用了一个新的方法 authenticators=self.get_authenticators(), negotiator=self.get_content_negotiator(), parser_context=parser_context )
去看看这个方法做了什么,此时的self是我们自己写的那个类的对象,父级没有找父父级,所以就在APIView中找到了
def get_authenticators(self): """ Instantiates and returns the list of authenticators that this view can use. """
# 它走的是对象自身的authentication_classes,如果自身没有就会去找父类的,那么我们只要在这里自定义了,那不就是走我们自己的方法了么!在自己的类中写这个就好!
return [auth() for auth in self.authentication_classes]
那我们自定义不就是我们自己的了
class Books(APIView):
# 自定义的方法 authentication_classes=[MyAuth] def get(self,request): # get是用来获取,得到所有的书籍 book_list = models.Book.objects.all()
那我们看看如果我们不写,接着会走到那里呢?发现它最后走的是settings中的默认配置,所以我们是不是也可以在还没有走settings的配置之前配置,那走的还是我们自己方法,因为settings我们配置了就不会走django默认的了
class APIView(View): # The following policies may be set at either globally, or per-view. renderer_classes = api_settings.DEFAULT_RENDERER_CLASSES parser_classes = api_settings.DEFAULT_PARSER_CLASSES # 我们看到了在那里调用的方法,如果自身没有就会直接来到默认的这里,这里就是settings中配置的 authentication_classes = api_settings.DEFAULT_AUTHENTICATION_CLASSES throttle_classes = api_settings.DEFAULT_THROTTLE_CLASSES permission_classes = api_settings.DEFAULT_PERMISSION_CLASSES content_negotiation_class = api_settings.DEFAULT_CONTENT_NEGOTIATION_CLASS metadata_class = api_settings.DEFAULT_METADATA_CLASS versioning_class = api_settings.DEFAULT_VERSIONING_CLASS # Allow dependency injection of other settings to make testing easier. # settings就是api_settings settings = api_settings schema = DefaultSchema()
最后他给我们返回的是一个列表,并且这个自动加括号调用了,所以我们的猜测是对的,它就是一个列表,里面放的是一个个的对象,并且自动加括号调用,然后我们接着回到刚开始那里
对象调用自己的authenticate方法,那我们自己写一个
class MyAuth(): def authenticate(self): pass
接着看刚才的源码地方
def _authenticate(self): """ Attempt to authenticate the request using each authentication instance in turn. """ # self.authenticators是对他进行循环,然后后面的authenticator又有点方法,所以authenticator肯定是个对象,那么猜测 # self.authenticators是一个有着多个对象的列表或者元组 # [对象1,对象2.。。] for authenticator in self.authenticators: try: # 对象自己的方法,对象调用自己的authenticate方法,现在的这个参数self是什么? # self在Request类中,所以self就是Request对象,那么我们在自己定义的方法中就要接收这个参数 # authenticator是我自己定义的MyAuth类的对象,隐藏了自定义类的self user_auth_tuple = authenticator.authenticate(self) except exceptions.APIException: # 进行了异常的捕获 self._not_authenticated() raise # 接着开始走这个 if user_auth_tuple is not None: # 将authenticator赋值给request,后面我们可以直接调用 self._authenticator = authenticator # 将user_auth_tuple这个东西赋值给这两个,后面我们可以直接用request.user,request.auth来拿到东西 # 是什么东西呢?一喽便知 self.user, self.auth = user_auth_tuple # 这个return仅仅只是用来结束for循环的 return self._not_authenticated()
这个是user_auth_tuple,它里面是两个值,第一个是用户,第二个是token,所以上面解压赋值给了它!
def authenticate(self, request): return (self.force_user, self.force_token)
认证源码结束
权限源码开始
进入和认证源码一样,所以我们只看里面的方法
def check_permissions(self, request): """ Check if the request should be permitted. Raises an appropriate exception if the request is not permitted. """ # 这个我们还是预测和认证是一样的[对象1,对象2.。。] for permission in self.get_permissions(): # 调用对象自己的方法 if not permission.has_permission(request, self): self.permission_denied( request, message=getattr(permission, 'message', None) )
先去看看这个self.get_permissions(),这个就是当前类的对象,然后就找到了当前的这个方法
def get_permissions(self): """ Instantiates and returns the list of permissions that this view requires. """ return [permission() for permission in self.permission_classes]
返回的也是一个个的对象,然后使用列表包裹着,那我们就可以和认证源码一样,自己书写这个permission_classes方法!
# 调用对象自己的方法 if not permission.has_permission(request, self):
如果自己定义的方法有的话就会直接进行校验,没有就会走上面的方法。
频率认证源码1
进入
def initial(self, request, *args, **kwargs): """ Runs anything that needs to occur prior to calling the method handler. """ self.format_kwarg = self.get_format_suffix(**kwargs) # Perform content negotiation and store the accepted info on the request neg = self.perform_content_negotiation(request) request.accepted_renderer, request.accepted_media_type = neg # Determine the API version, if versioning is in use. version, scheme = self.determine_version(request, *args, **kwargs) request.version, request.versioning_scheme = version, scheme # Ensure that the incoming request is permitted # 这三个分别是用户认证 self.perform_authentication(request) # 权限认证 self.check_permissions(request) # 频率认证 self.check_throttles(request)
接着点进去看看
def check_throttles(self, request): """ Check if request should be throttled. Raises an appropriate exception if the request is throttled. """ # [throttle() for throttle in self.throttle_classes] for throttle in self.get_throttles(): # 走对象自己的方法 if not throttle.allow_request(request, self): self.throttled(request, throttle.wait())
self.get_throttles()内部源码
def get_throttles(self): """ Instantiates and returns the list of throttles that this view uses. """ return [throttle() for throttle in self.throttle_classes]
所以需要我们自己重写throttle_classes,和用户认证类似
基于源码实现我们自己的逻辑。
路由层,有些是我自己测试使用的,具体的在视图层,可以查看
"""newBMS URL Configuration The `urlpatterns` list routes URLs to views. For more information please see: https://docs.djangoproject.com/en/1.11/topics/http/urls/ Examples: Function views 1. Add an import: from my_app import views 2. Add a URL to urlpatterns: url(r'^$', views.home, name='home') Class-based views 1. Add an import: from other_app.views import Home 2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home') Including another URLconf 1. Import the include() function: from django.conf.urls import url, include 2. Add a URL to urlpatterns: url(r'^blog/', include('blog.urls')) """ from django.conf.urls import url from django.contrib import admin from app01 import views urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^book/$', views.books), url(r'^publish', views.Publish.as_view()), url(r'^author/', views.Author.as_view()), url(r'myapiview', views.MyApiview.as_view()), url(r'^books/$',views.Books.as_view()), # url(r'^book/(?P<id>\d+)/', views.BookDetail.as_view()) url(r'^login/', views.Login.as_view()) ]
视图层
from django.shortcuts import render,HttpResponse from app01 import models from django.http import JsonResponse import json from django.views import View from rest_framework.views import APIView from app01.myserializer import Myseria,BookSeria from rest_framework.response import Response from rest_framework.exceptions import AuthenticationFailed from app01.Myauths import MyAuth,Mypermison,Mychecktimes from rest_framework.authentication import BaseAuthentication import uuid # Create your views here. def books(request): # print(request.method) back_dic = {'status_code': 100, 'msg': ''} if request.method == 'GET': book_list = models.Book.objects.all() # 这里因为前后端分离,我们都是用json格式进行数据的传输,但是json是不能序列化queryset对象的,所以我们用到了列表生成式 back_dic['data'] = [{'name': book.name, 'price': book.price} for book in book_list] # 还有就是给字典赋值 back_dic['msg'] = '查询成功' return JsonResponse(back_dic) elif request.method == 'POST': # json格式的字符串是在body中,要先解码 res = request.body.decode('utf-8') # json格式反序列化 res1 = json.loads(res) models.Book.objects.create(**res1) # # 我们说了新增数据成功以后可以不返回新增的数据对象,可以直接返回一个信息就好 back_dic['msg'] = '新增完成' return JsonResponse(back_dic) class Author(View): def get(self, request): back_dic = {'status_code': 100, 'msg': 'get ok'} return JsonResponse(back_dic) def post(self, request): back_dic = {'status_code': 102, 'msg': 'post ok'} return JsonResponse(back_dic) class MyApiview(APIView): def get(self, request): return HttpResponse('get ok') def post(self, request): return HttpResponse('post ok') class Publish(APIView): authentication_classes = [MyAuth] permission_classes = [Mypermison, ] throttle_classes = [Mychecktimes] def get(self, request): publish_list = models.Publish.objects.all() publish_ser = Myseria(instance=publish_list, many=True) return Response(publish_ser.data) class Books(APIView): # 认证通过才可以查看所有图书 throttle_classes = [Mychecktimes] authentication_classes = [MyAuth] permission_classes = [Mypermison, ] def get(self,request): # get是用来获取,得到所有的书籍 book_list = models.Book.objects.all() book_ser = BookSeria(instance=book_list, many=True) return Response(book_ser.data) def post(self,request): # print(request.data) # 反序列化增加数据 bookser = BookSeria(data=request.data) # print(bookser) # print(bookser.is_valid()) # 判断是否通过校验 if bookser.is_valid(): # 通过校验去调用create方法 ret = bookser.create(bookser.validated_data) # 返回一个空 return Response() class Login(APIView): #这个是post请求 def post(self,request): back_dic = {'code': 100, 'msg': ''} # print(request.data) name = request.data.get('name') age = request.data.get('age') try: user = models.Author.objects.filter(name=name, age=age).get() back_dic['msg'] = '登录成功' # 登录成功以后应该给客户端返回那个token token = uuid.uuid4() # 将产生的随机token保存到库中 models.Token.objects.update_or_create(author=user, defaults={'token':token}) # 将产生的随机字符串返回给用户 back_dic['token'] = token except AuthenticationFailed as e: back_dic['code'] = 101 back_dic['msg'] = '用户名或者密码错误' except Exception as e: back_dic['code'] = 102 back_dic['msg'] = str(e) return Response(back_dic)
序列化组件
from rest_framework import serializers from app01 import models class Myseria(serializers.Serializer): title = serializers.CharField(source='name') price = serializers.CharField(source='email') # pub_date = serializers.CharField() class BookSeria(serializers.Serializer): title = serializers.CharField() price = serializers.CharField() pub_date = serializers.CharField() publish_id = serializers.CharField() def validate(self, attrs): # print(attrs) # 做全部字段的校验 # if attrs.get('title') == attrs.get('price'): return attrs def create(self, validated_data): ret = models.Book.objects.create(**validated_data) # print('111',ret) return ret
最后就是用户认证相关的
from rest_framework.authentication import BaseAuthentication from rest_framework.throttling import SimpleRateThrottle from rest_framework import permissions from app01 import models from rest_framework.exceptions import AuthenticationFailed # 用户认证校验 class MyAuth(BaseAuthentication): def authenticate(self,request): # print('你到底有没有走我') # 在这里面写认证的逻辑 token = request.GET.get('token') token_obj = models.Token.objects.filter(token=token).first() if token_obj: # print(token_obj) # print(token_obj.author) # 有值表示登录了 return token_obj.author, token_obj else: # 没有值,表示没有登录,抛异常 raise AuthenticationFailed('您还没有登陆呢') # 这个没有写会出现这个错误 #AttributeError: 'MyAuth' object has no attribute 'authenticate_header' # def authenticate_header(self,abc): # pass # 权限校验 class Mypermison(): message = '我这里只有超级VVIP才可以看的呢!' def has_permission(self,request,view): # print(request.data) # print(request.user) # print(view) if request.user.is_vip == 1: # print(111) return True else: # print(222) return False # 频率校验 class Mychecktimes(): scope = 'lxx' dic = {} def get_cache_key(self, request, view): return request.user.pk def allow_request(self, request, view): import time ''' #(1)取出访问者ip # (2)判断当前ip不在访问字典里,添加进去,并且直接返回True,表示第一次访问,在字典里,继续往下走 # (3)循环判断当前ip的列表,有值,并且当前时间减去列表的最后一个时间大于60s,把这种数据pop掉,这样列表中只有60s以内的访问时间, # (4)判断,当列表小于3,说明一分钟以内访问不足三次,把当前时间插入到列表第一个位置,返回True,顺利通过 # (5)当大于等于3,说明一分钟内访问超过三次,返回False验证失败 ''' # 1.获取用户的id uid = self.get_cache_key(request, view) # 判断用户的id在不在字典中,不在添加并且是第一次访问 if uid not in self.dic: print(uid) ctime = time.time() self.dic[uid] = [ctime, ] return True # 在字典中,表示不是第一次登录,那么还要循环打印列表判断时间时间是否大于60s(因为我们这里用的是3/m),所以是60s now = time.time() # 将所有时间大于60的删除 for history in self.dic.get(uid): if now-history > 60: self.dic.get(uid).pop() # 判断列表是否小于3,如果小于说明当前没有超过这个时间 if len(self.dic.get(uid)) < 3: # 将当前时间添加到这个里面 self.dic.get(uid).insert(0, now) return True else: return False def wait(self): import time ctime = time.time() # 这里是我没有将存在用户的时间用变量存起来,发现我这里无法获取,所以我用了这个,因为我如果不写wait方法的话,次数一过就会报错 return 60-(ctime-10)
然后发现我自己的用户认证的频率写的没有别人的好,这里附上刘老师的,仅供参考
class MyThrottles(): VISIT_RECORD = {} def __init__(self): self.history=None def allow_request(self,request, view): #(1)取出访问者ip # print(request.META) ip=request.META.get('REMOTE_ADDR') import time ctime=time.time() # (2)判断当前ip不在访问字典里,添加进去,并且直接返回True,表示第一次访问 if ip not in self.VISIT_RECORD: self.VISIT_RECORD[ip]=[ctime,] return True self.history=self.VISIT_RECORD.get(ip) # (3)循环判断当前ip的列表,有值,并且当前时间减去列表的最后一个时间大于60s,把这种数据pop掉,这样列表中只有60s以内的访问时间, while self.history and ctime-self.history[-1]>60: self.history.pop() # (4)判断,当列表小于3,说明一分钟以内访问不足三次,把当前时间插入到列表第一个位置,返回True,顺利通过 # (5)当大于等于3,说明一分钟内访问超过三次,返回False验证失败 if len(self.history)<3: self.history.insert(0,ctime) return True else: return False def wait(self): import time ctime=time.time() return 60-(ctime-self.history[-1])
然后我们在写完这个以后,还得去settings中配置
REST_FRAMEWORK = { 'DEFAULT_THROTTLE_RATES':{ 'lxx': '3/m' } }
写完之后心里一顿美滋滋,但是我们仔细一看,发现我们的这个东西写死了,既然我们写死了,肯定别人会帮我们写好的,直接去看别人的源码吧!
如果大家不知道如何查看源码,那么就去看官方文档,都有介绍,或者直接将每个需要的模块导入慢慢的查看,看源码是一个痛并快乐的过程!
频率认证源码2
上面我们看的是频率认证的源码,发现只需要我们重写allow_request方法就好,现在我们看的是别人帮我们写好的allow_request的源码,are you ready?go!
进入地方
# 用户认证相关的源码 from rest_framework.authentication import BaseAuthentication # 用户频率相关的源码 from rest_framework.throttling import SimpleRateThrottle # 用户权限相关的源码 from rest_framework import permissions
源码介绍
def allow_request(self, request, view): """ Implement the check to see if the request should be throttled. On success calls `throttle_success`. On failure calls `throttle_failure`. """ if self.rate is None: return True # 在这里将get_cache_key的值给了key,那就是只要我们自己定义了这个方法,就会走我们自己的校验 self.key = self.get_cache_key(request, view) # 判断这个key是否为空 if self.key is None: # 表示用户是第一次登录,直接返回True return True # self.history就是一个用来存放用户登陆时间的[],self.cache.get(self.key, [])就是从缓存中拿到用户的key值,将他赋值给self.history self.history = self.cache.get(self.key, []) # 获取当前时间 self.now = self.timer() # Drop any requests from the history which have now passed the # throttle duration #这一步就是将当前IP的登录时间循环处理,当前时间和最后一个时间小于当前登录时间-我们设置的那个频率次数 while self.history and self.history[-1] <= self.now - self.duration: # 如果满足条件,就将它移除 self.history.pop() #然后判断当前的登录时间列表是不是大于等于我们的自定义的那个次数 if len(self.history) >= self.num_requests: # 满足条件就抛出失败 return self.throttle_failure() # 否则就成功 return self.throttle_success()
然后我们去看看内部是怎么做的--将他写活
我们一个个的查看这里的变量,首先是self.rate,发现在它内部走的是get_rate,那就看看这个是什么
def get_rate(self): """ Determine the string representation of the allowed request rate. """ # 这里就证明了我们必须指定这个scope,不然就直接报错 if not getattr(self, 'scope', None): msg = ("You must set either `.scope` or `.rate` for '%s' throttle" % self.__class__.__name__) raise ImproperlyConfigured(msg) try: return self.THROTTLE_RATES[self.scope] except KeyError: msg = "No default throttle rate set for '%s' scope" % self.scope raise ImproperlyConfigured(msg)
所以最后这个self.rate其实就是我们自己写的scope这个变量
接着我们看看self.get_cache_key看它是什么
def get_cache_key(self, request, view): """ Should return a unique cache-key which can be used for throttling. Must be overridden. May return `None` if the request should not be throttled. """ raise NotImplementedError('.get_cache_key() must be overridden')
看来是要求我们重写书写这个方法了,然后将返回值赋值给self.key,这个self.key就是我们需要的字典的key值,这里就是ip
然后接着查看time
timer = time.time
内部其实就是获取了当前时间,只不过我们在调用这里加()执行了而已
查看self.duration,看看他是怎么做的
def __init__(self): if not getattr(self, 'rate', None):
# self.rate='3/m',通过反射取到的key对应的value,所以就是'3/m'
self.rate = self.get_rate()
# 解压赋值,从后面这个地方,那么它可能就是元组或者列表
self.num_requests, self.duration = self.parse_rate(self.rate)
将self.rate,也就是'3/m'传进去,拿到的这两个东西,看看里面如何操作的
def parse_rate(self, rate): """ Given the request rate string, return a two tuple of: <allowed number of requests>, <period of time in seconds> """ # 进来先判断了'3/m'是否有,也就是我们做没做校验 if rate is None: # 不在的话就说明我们并没有校验,直接返回 return (None, None) # 存在的情况下,对这个做了字符串的切分,得到的是一个['3','m'],然后解压赋值给num,period num, period = rate.split('/') # 将num转成整数然后给了num_requests num_requests = int(num) # 这里其实就是字典的取值,然后为了避免我们写的是'3/min'这种情况,所以对字符串取了第0位 duration = {'s': 1, 'm': 60, 'h': 3600, 'd': 86400}[period[0]] # 最后对应下来,duration就是m对应的60秒 # 将这两个东西返回了出去 return (num_requests, duration)
那么这里的self.num_requests,self.duration分别是3 和60。
接着往下走,看看下面,在失败的情况下,直接调用的函数是return False
def throttle_failure(self): """ Called when a request to the API has failed due to throttling. """ return False
成功的情况下,看看里面的操作
def throttle_success(self): """ Inserts the current request's timestamp along with the key into the cache. """ # 将当前时间添加到0号位置,也就是最后的登录的时间在列表0号位 self.history.insert(0, self.now) # 这一步就是将这个东西存到缓存中,是以一个字典的形式存储,第一个是字典的key值,第二个是字典的value值,第三个是在缓存中的存活时间 self.cache.set(self.key, self.history, self.duration) return True
至此,源码分析完毕,基于源码可以写自己的逻辑,只要我们重新写一个get_cache_key方法就好
# 频率校验 class Mycheck(SimpleRateThrottle): scope = 'lxx' def get_cache_key(self, request, view): return self.get_ident(request)
总结:继承SimpleRateThrottle,定义一个scope,重写get_cache_key()方法,返回self.get_ident(request)
这三个校验都有的是局部使用,局部禁用,全局使用,使用如下
局部使用
from app01.Myauths import MyAuth,Mypermison,Mycheck class Publish(APIView): authentication_classes = [MyAuth] permission_classes = [Mypermison, ] throttle_classes = [Mycheck] def get(self, request): publish_list = models.Publish.objects.all() publish_ser = Myseria(instance=publish_list, many=True) return Response(publish_ser.data)
全局使用,在settings中配置
REST_FRAMEWORK = { 'DEFAULT_AUTHENTICATION_CLASSES':['自己配置的认证相关的东西'], 'DEFAULT_PERMISSION_CLASSES':['自己配置的权限相关的东西'], 'DEFAULT_THROTTLE_CLASSES':['自己配置的频率相关的东西'], 'DEFAULT_THROTTLE_RATES':{ 'lxx': '3/m' } }
局部禁用
class Books(APIView): throttle_classes = [] authentication_classes = [] permission_classes = [] def get(self,request): # get是用来获取,得到所有的书籍 book_list = models.Book.objects.all() book_ser = BookSeria(instance=book_list, many=True) return Response(book_ser.data)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号