
CS61B-union-find(并查集)算法
一、备注:union-find又名Disjoint-Sets,所以union-find是不允许有重复数据的。
二、应用:解决动态连通性问题
三、分析:当不断有新节点加入时,需要完成的操作:(1)判断2个节点是否在同一个集合中isConnected(p, q);(2)将某一个节点所在集合中的节点都合并到另一个节点所在的集合中 connect(p, q)
四、思路:(1)定义一种数据结构(数组)表示已知的连接
(2)基于此数据结构实现高效的操作
五、实现:
先能完成功能,再分析效率进行迭代优化
1.quick-find算法实现
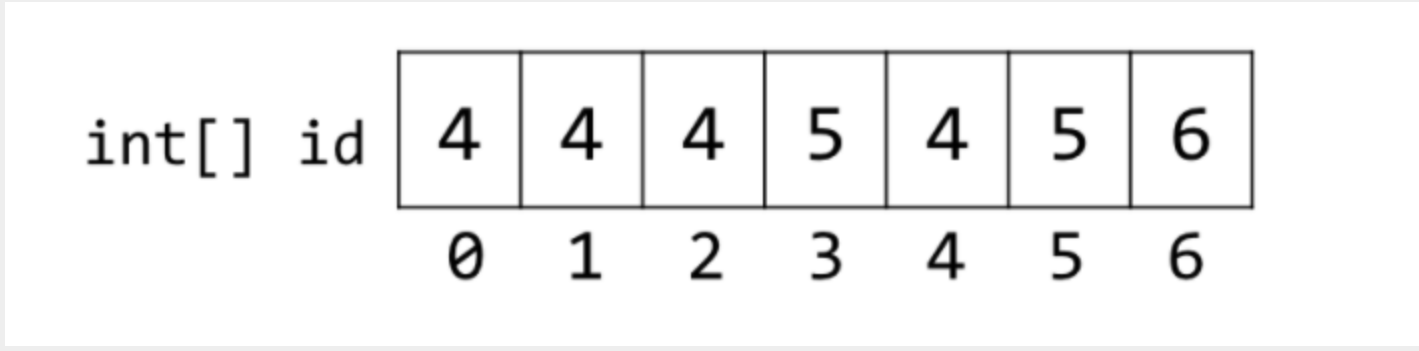
使用数组,索引表示数据,值表示集合的标号,如:0, 1, 2, 4都在一个集合(4)中;3, 5在同一个集合(5)中,6在一个集合(6)中。
对于isConnected(p, q):可以使用 id[p] == id[q]进行判断
对于connect(p, q):可以遍历一次数组,将值等于id[p]的改成id[q](或者反过来,id[q]的值改成id[p]也行)
1 //定义一个接口,后面的算法也会用到 2 public interface UnionFind { 3 boolean isConnected(int p, int q); 4 5 void connect(int p, int q); 6 }
1 //quick-find代码实现 2 public class QuickFind implements UnionFind { 3 private int[] id; 4 public QuickFind(int N) { 5 id = new int[N]; 6 for (int i = 0; i < id.length; i++) { 7 id[i] = i; //表示初始化的状态 8 } 9 } 10 @Override 11 public boolean isConnected(int p, int q) { 12 return (id[p] == id[q]); 13 } 14 15 @Override 16 public void connect(int p, int q) { 17 int pid = id[p]; 18 int qid = id[q]; 19 if (pid == qid) { 20 return; 21 } 22 for (int i = 0; i < id.length; i++) { 23 if (id[i] == pid) { 24 id[i] = qid; 25 } 26 } 27 } 28 }
时间复杂度分析:查找操作(isConnected)是O(1),合并操作是O(n),因此叫做quick-find。但对于实际中大规模的问题,每增加一对输入,就要遍历一次数组,效率太低。
2、quick-union算法实现
实现前的说明:
-
此处需要引入树的结构进行可视化展示;另外,若要完成以上2个操作,需要先找到每棵树的根节点。因为假设输入是(p,q):
(1)若p和q的根节点相同则属于同一个集合,返回true;
(2)若要将p和q所在的集合进行合并时,将某一棵树的根节点挂到另一棵树的根节点上。
所以需要加一个寻找根节点 find(int p)的操作。
一个具体的实例如下:
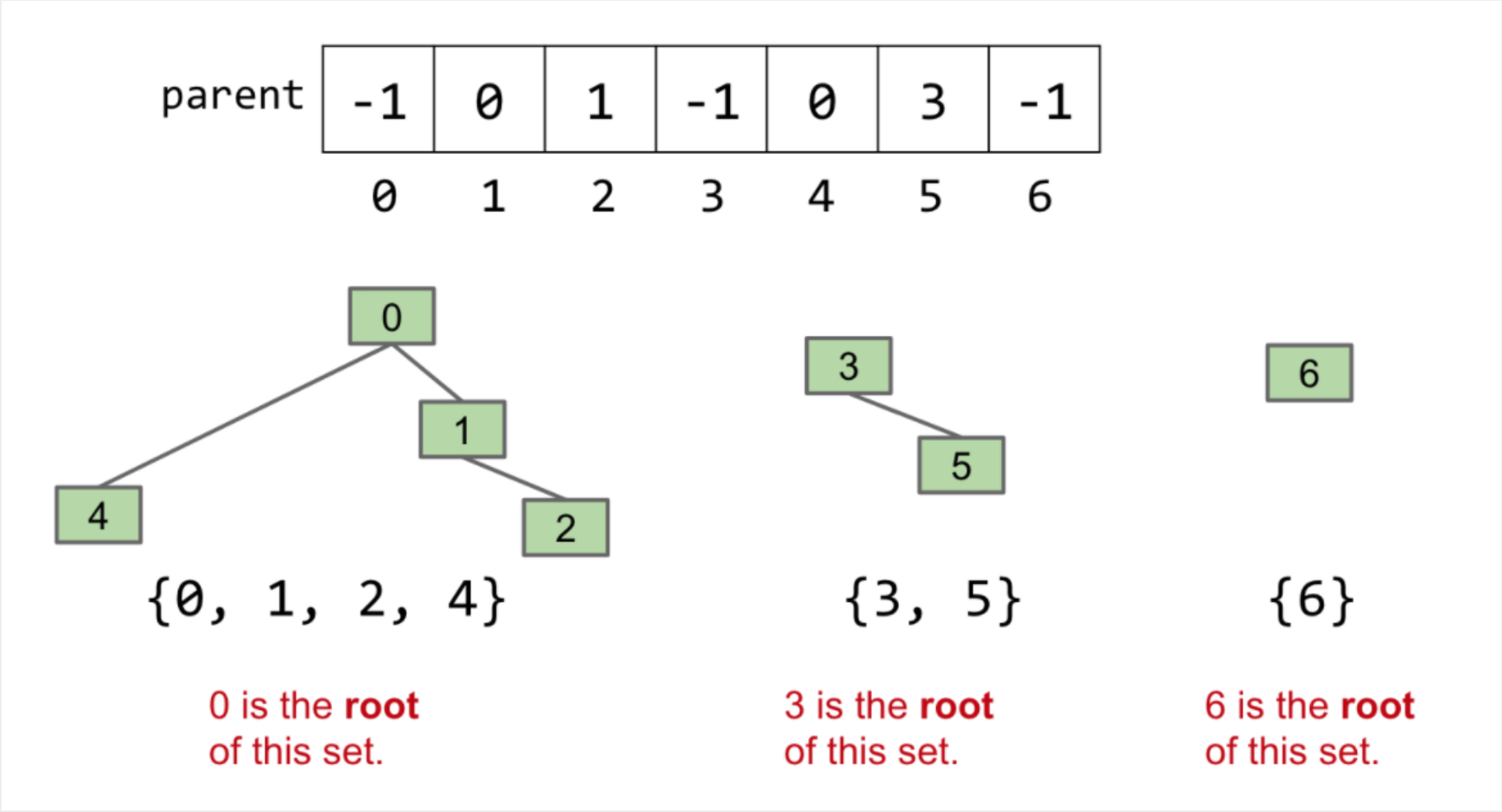
以{0, 1, 2, 4}为例:数组的索引即代表存储的每一个数据,4的父节点是0,因此索引4的值0;2的父节点是1,因此索引2的值1;0是根节点没有父节点,因此以一个负数表示(这里取-1)
1 //quick-union代码实现 2 public class QuickUnion implements UnionFind { 3 private int[] parent; 4 public QuickUnion(int N) { 5 parent = new int[N]; 6 for (int i = 0; i < N; i++) { 7 parent[i] = i; 8 } 9 } 10 11 //寻找根节点 12 private int find(int p) { 13 while (parent[p] >= 0) { 14 p = parent[p]; 15 } 16 return p; 17 } 18 19 @Override 20 public boolean isConnected(int p, int q) { 21 return (find(p) == find(q)); 22 } 23 24 @Override 25 public void connect(int p, int q) { 26 if (find(p) == find(q)) { 27 return; 28 } 29 int pid = find(p); 30 int qid = find(q); 31 parent[pid] = qid; 32 } 33 }
时间复杂度分析:由于quick-union的查、并都用了find方法,因此在最坏的情况下(退化成一条链)都是O(n);但相比于quick-find在合并上很多情况要好。当然,这只是中间一个过渡方案。
3、Weighted Quick Union(加权Quick Union)
quick-union为了让时间复杂度尽可能小,合并后的树的高度应当尽可能小。定义树的大小是指树的所有节点数。因此合并时,应当将小树连接到大树上。至于树的大小,可以选择另外建一个数组来保存,也可以将根节点的值设为大小的负数,即取代上面Quick Union的-1的位置。
1 //Weighted Quick Union代码实现 2 public class WeightedQuickUnion implements UnionFind { 3 private int[] parent; 4 private int[] size; 5 public WeightedQuickUnion(int N) { 6 parent = new int[N]; 7 size = new int[N]; 8 for (int i = 0; i < parent.length; i++) { 9 parent[i] = i; //表示初始化的状态 10 } 11 for (int i = 0; i < parent.length; i++) { 12 size[i] = 1; 13 } 14 } 15 16 private int find(int p) { 17 while (parent[p] >= 0) { 18 p = parent[p]; 19 } 20 return p; 21 } 22 23 @Override 24 public boolean isConnected(int p, int q) { 25 return (find(p) == find(q)); 26 } 27 28 @Override 29 public void connect(int p, int q) { 30 if (find(p) == find(q)) { 31 return; 32 } 33 if (size[p] > size[q]) { 34 parent[find(q)]= find(p); 35 size[p] += size[q]; 36 } else { 37 parent[find(p)]= find(q); 38 size[q] += size[p]; 39 } 40 } 41 }
时间复杂度分析:由于加权quick-union的构造原因,导致任一节点的最大深度等于整棵树的高度——logN。所以find在最坏情况下,即叶子节点去找跟节点的时间复杂度是logN,又由于查找和合并都是用的find方法,所以时间复杂度都是logN
4、Weighted Quick Union with Path Compression(路径压缩的加权quick-union)
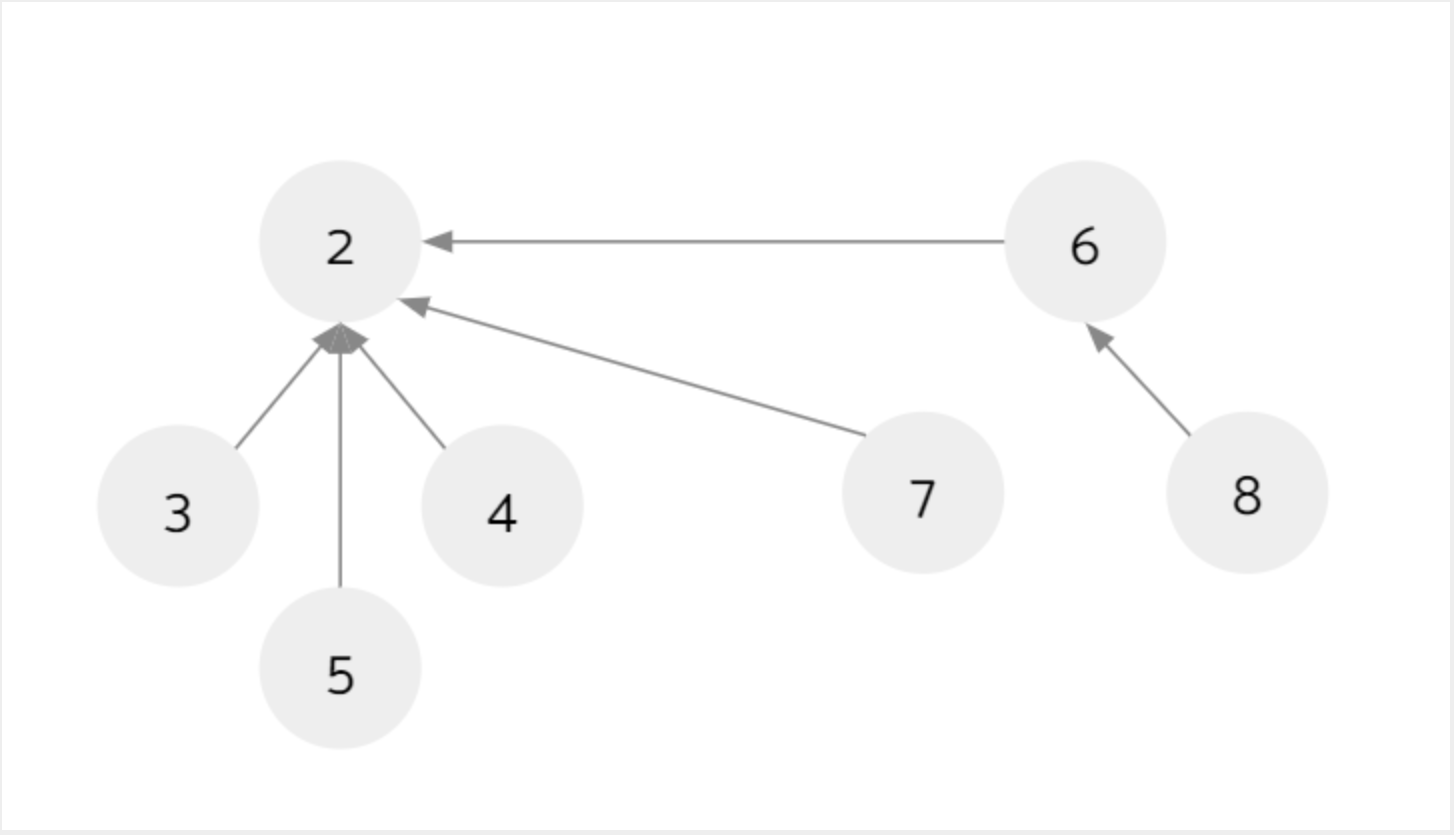
在查找根节点时,将过程中遍历到的节点的父节点都改成根节点,即connect(5, 7)
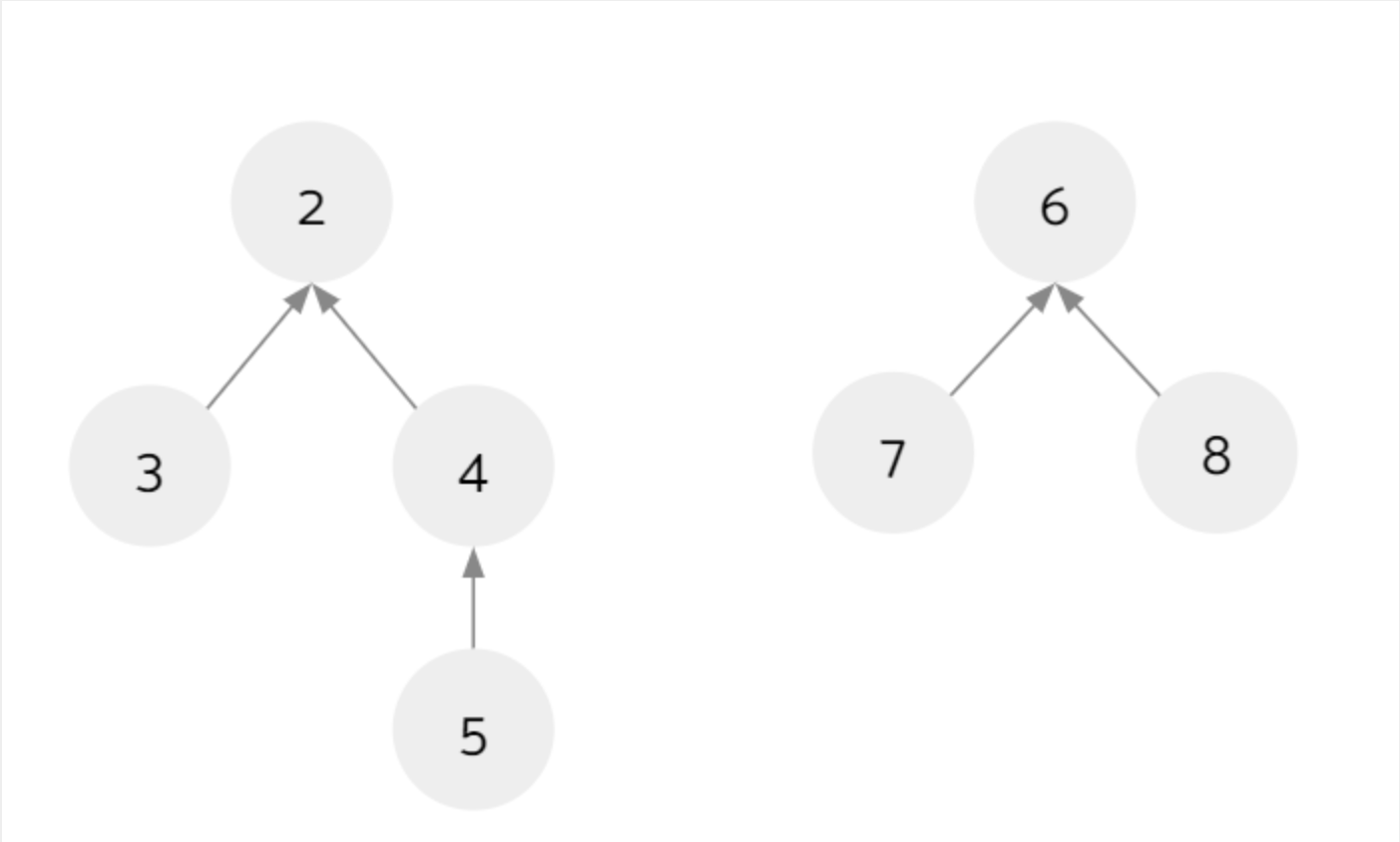
最终变成
1 //Weighted Quick Union with Path Compression的代码在find方法中加一个循环即可 2 private int find(int p) { 3 while (parent[p] >= 0) { 4 p = parent[p]; 5 } 6 int origin = p; 7 while (origin != p) { 8 int tmp = origin; 9 origin = parent[origin]; 10 parent[tmp] = p; 11 } 12 return p; 13 }
复杂度分析:按资料中介绍说,十分接近O(1),已是最优解。
应用:解决动态连通性问题
分析:当不断有新节点加入时,需要完成的操作:(1)判断2个节点是否在同一个集合中 isConnected(p, q);(2)将某一个节点所在集合中的节点都合并到另一个节点所在的集合中 connect(p, q)
思路:(1)定义一种数据结构(数组)表示已知的连接
(2)基于此数据结构实现高效的操作
实现:
先能完成功能,再分析效率进行迭代优化
1.quick-find算法实现
使用数组,索引表示数据,值表示集合的标号,如:0, 1, 2, 4都在一个集合(4)中;3, 5在同一个集合(5)中,6在一个集合(6)中。
对于:可以使用 id[p] == id[q]进行判断
对于connect(p, q):可以遍历一次数组,将值等于id[p]的改成id[q](或者反过来,id[q]的值改成id[p]也行)
1 //定义一个接口,后面的算法也会用到 2 public interface UnionFind { 3 boolean isConnected(int p, int q); 4 5 void connect(int p, int q); 6 } 7 //quick-find代码实现 8 public class QuickFind implements UnionFind { 9 private int[] id; 10 public QuickFind(int N) { 11 id = new int[N]; 12 for (int i = 0; i < id.length; i++) { 13 id[i] = i; //表示初始化的状态 14 } 15 } 16 @Override 17 public boolean isConnected(int p, int q) { 18 return (id[p] == id[q]); 19 } 20 21 @Override 22 public void connect(int p, int q) { 23 int pid = id[p]; 24 int qid = id[q]; 25 if (pid == qid) { 26 return; 27 } 28 for (int i = 0; i < id.length; i++) { 29 if (id[i] == pid) { 30 id[i] = qid; 31 } 32 } 33 } 34 }
时间复杂度分析:查找操作(isConnected)是O(1),合并操作是O(n),因此叫做quick-find。但对于实际中大规模的问题,每增加一对输入,就要遍历一次数组,效率太低。
2、quick-union算法实现
实现前的说明:
-
此处需要引入树的结构进行可视化展示;另外,若要完成以上2个操作,需要先找到每棵树的根节点。因为假设输入是(p,q):
(1)若p和q的根节点相同则属于同一个集合,返回true;
(2)若要将p和q所在的集合进行合并时,将某一棵树的根节点挂到另一棵树的根节点上。
所以需要加一个寻找根节点 find(int p)的操作。
一个具体的实例如下:
以{0, 1, 2, 4}为例:数组的索引即代表存储的每一个数据,4的父节点是0,因此索引4的值0;2的父节点是1,因此索引2的值1;0是根节点没有父节点,因此以一个负数表示(这里取-1)
1 //quick-union代码实现 2 public class QuickUnion implements UnionFind { 3 private int[] parent; 4 public QuickUnion(int N) { 5 parent = new int[N]; 6 for (int i = 0; i < N; i++) { 7 parent[i] = i; 8 } 9 } 10 11 //寻找根节点 12 private int find(int p) { 13 while (parent[p] >= 0) { 14 p = parent[p]; 15 } 16 return p; 17 } 18 19 @Override 20 public boolean isConnected(int p, int q) { 21 return (find(p) == find(q)); 22 } 23 24 @Override 25 public void connect(int p, int q) { 26 if (find(p) == find(q)) { 27 return; 28 } 29 int pid = find(p); 30 int qid = find(q); 31 parent[pid] = qid; 32 } 33 } 34
时间复杂度分析:由于quick-union的查、并都用了find方法,因此在最坏的情况下(退化成一条链)都是O(n);但相比于quick-find在合并上很多情况要好。当然,这只是中间一个过渡方案。
3、Weighted Quick Union(加权Quick Union)
quick-union为了让时间复杂度尽可能小,合并后的树的高度应当尽可能小。定义树的大小是指树的所有节点数。因此合并时,应当将小树连接到大树上。
1 //Weighted Quick Union代码实现 2 public class WeightedQuickUnion implements UnionFind { 3 private int[] parent; 4 private int[] size; 5 public WeightedQuickUnion(int N) { 6 parent = new int[N]; 7 size = new int[N]; 8 for (int i = 0; i < parent.length; i++) { 9 parent[i] = i; //表示初始化的状态 10 } 11 for (int i = 0; i < parent.length; i++) { 12 size[i] = 1; 13 } 14 } 15 16 private int find(int p) { 17 while (parent[p] >= 0) { 18 p = parent[p]; 19 } 20 return p; 21 } 22 23 @Override 24 public boolean isConnected(int p, int q) { 25 return (find(p) == find(q)); 26 } 27 28 @Override 29 public void connect(int p, int q) { 30 if (find(p) == find(q)) { 31 return; 32 } 33 if (size[p] > size[q]) { 34 parent[find(q)]= find(p); 35 size[p] += size[q]; 36 } else { 37 parent[find(p)]= find(q); 38 size[q] += size[p]; 39 } 40 } 41 }
时间复杂度分析:由于加权quick-union的构造原因,导致任一节点的最大深度等于整棵树的高度——logN。所以find在最坏情况下,即叶子节点去找跟节点的时间复杂度是logN,又由于查找和合并都是用的find方法,所以时间复杂度都是logN
4、Weighted Quick Union with Path Compression(路径压缩的加权quick-union)
在查找根节点时,将过程中遍历到的节点的父节点都改成根节点,即connect(5, 7)
最终变成
1 //Weighted Quick Union with Path Compression的代码在find方法中加一个循环即可 2 private int find(int p) { 3 while (parent[p] >= 0) { 4 p = parent[p]; 5 } 6 int origin = p; 7 while (origin != p) { 8 int tmp = origin; 9 origin = parent[origin]; 10 parent[tmp] = p; 11 } 12 return p; 13 }
总结:
quick-find:重点是find,通过将同一个set的节点设为相等值,能实现O(1)的查找效率
quick-union:重点是union,通过设置父节点,使得合并时查找根节点的时间复杂度能在某些情况下小于O(n)
weighted-quick-union:重点是在quick-union基础上引入size(树的大小),将小树合并到大树下,降低一些树的高度,使得时间复杂度达到O(logn)
weighted-quick-union-with path compression:重点是路径压缩(每次调用find方法时进一步地降低树的高度),使得时间复杂度接近于O(1)
练习:判断下图中A~F哪个可能是路径压缩的带权quick-union
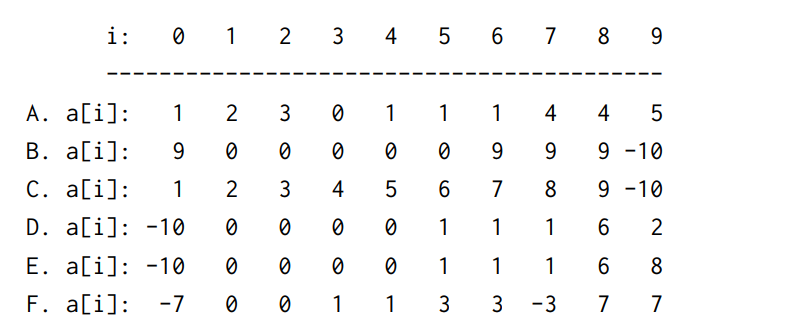
答:只有D可能是,首先带环肯定不是;其次不能有大树连到小树上情况;最后树的高度不能大于lgN
参考资料:Berkeley-CS61B课程 & 《算法第四版》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号