


图书信息库完整解决方案(一)概述
去年因为忙一个图书漂流的项目,大概花了三个月的时间,完成了图书信息库的建立。
截止目前为止,已经收录了200多万条的图书数据,并且每周还在自动更新中,打算将这个项目完整的整理出来,算阶段性工作的一个总结吧。
方案主要功能如下:
1、实现了按照当当图书分类, 抓取每个分类下前100页图书数据的功能。
2、支持按照ISBN获取图书详情信息, 如果库里不存在则优先从当当处获取图书信息,如果当当获取不到再从豆瓣获取。如果当当和豆瓣都存在这本书,则综合两者的图书信息入库。
3、技术难点:主要有两部分,一个是如何解析当当网页,从繁杂的网页结构里取出需要的图书详情信息;另一个是如何避免因长时间的抓取被当当封掉ip,这里采用了一个巧妙的机制,既能不花钱又能建立起自己的代理ip库。
接下来会慢慢来梳理。
PS:纠结来纠结去,还是感觉博客园的编辑和显示比CSDN更友好。
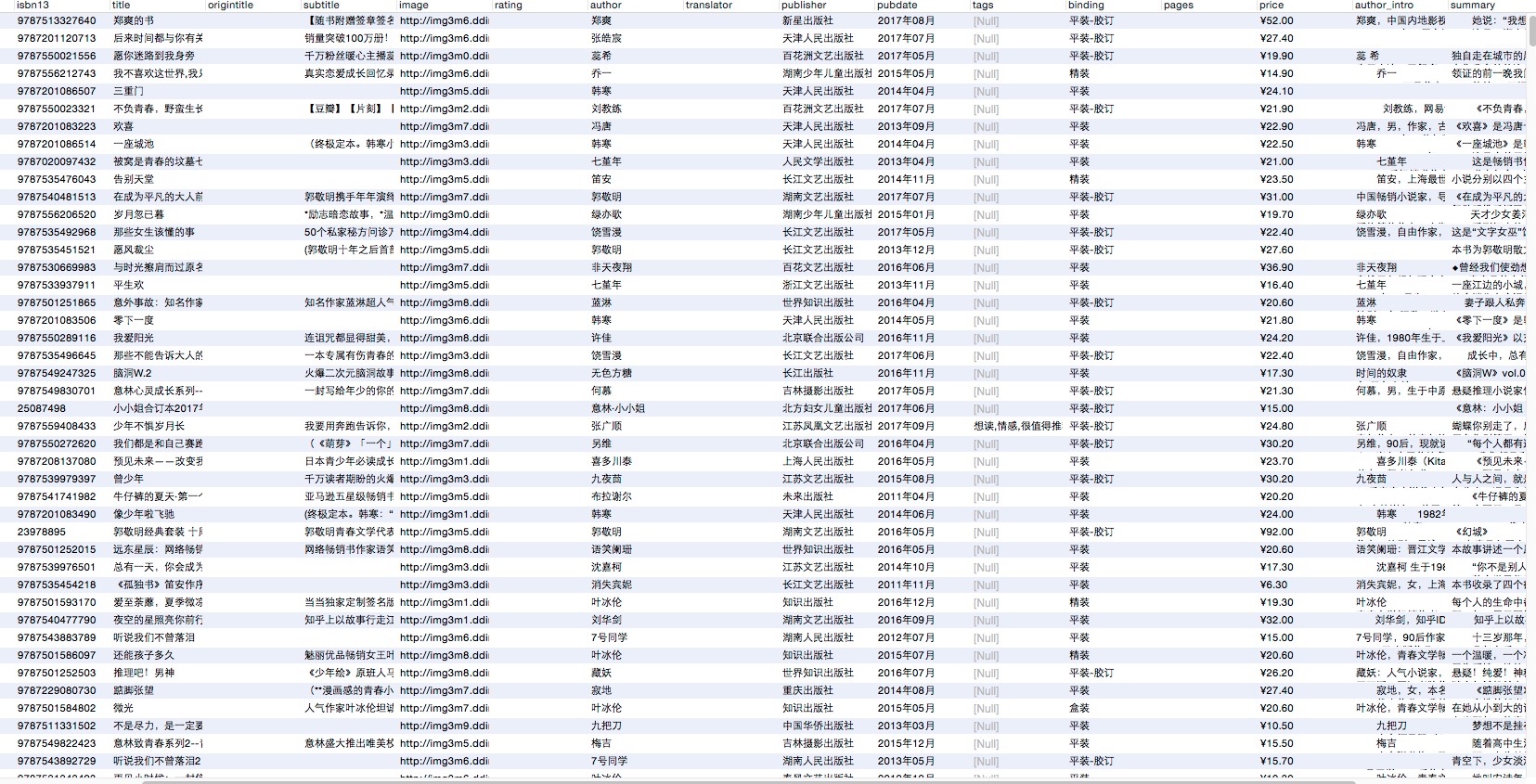
数据库截图:
标签:
图书 ISBN 爬虫


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具