


Python项目实践--当当和豆瓣图书爬虫
图书访问接口:
接口地址:
http://api.xiaomafeixiang.com/api/bookinfo?isbn=9787544270878
把isbn替换为实际需要查询图书的isbn编号即可。
一、爬虫架构Scrapy
选用的爬虫框架是Scrapy,具体学习文档可参考:
官方文档:https://scrapy.org/
二、Scrapy爬取动态内容
网页解析部分,如果是静态网页可以直接对返回的数据进行解析。
针对动态网页,最终选用的方案是Selenium Chrome方案。分析过程见以下文档:
Scrapy爬取动态内容(二)Selenium Chrome方案
Scrapy爬取动态内容(三)Selenium Firefox方案
Scrapy爬取动态内容(四)Selenium-Server方案
三、环境部署
Python项目实践--环境准备03 Scrapy + Selenium Chrome工作环境
四、工程结构简介

1、spiders部分
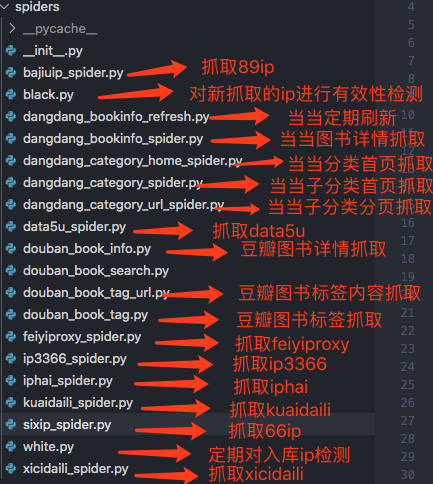
这里主要分为三部分内容:
(1) 抓取各大免费代理,从实际效果来看,可用的合法代理还是比较少的。
(2) 当当图书抓取。
(3) 豆瓣图书抓取。
2、中间件
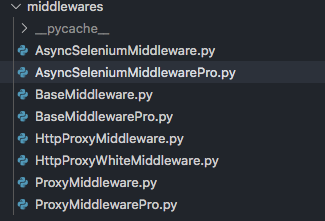
中间件部分针对抓取图书和抓取代理、使用免费代理和付费代理做了区分。
3、管道和数据模型
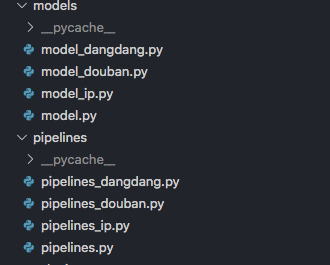
4、selenium部分
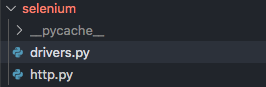
五、代码讲解
(持续整理中)
