第63篇-解释器与编译器适配(二)
这一篇详细介绍相关适配器的代码片段。
1、解释执行切换到编译执行的例程
调用SharedRuntime::gen_i2c_adapter()函数生成解释执行切换到编译执行的例程,如下:
0x00007fe462791120: mov (%rsp),%rax 0x00007fe462791124: movabs $0x7fe46268c360,%r11 0x00007fe46279112e: cmp %r11,%rax // cmp当第一个操作数大于等于第二个操作数时,设置ZF或CF为1 // JBE指令的完整写法是“Jump if Below or Equal”,即“如果小于等于则跳转到L_fail”。 // 其作用是当CF=1或ZF=1时跳转,否则继续执行后面的指令。 // 如果比较失败就跳转到L_fail 0x00007fe462791131: jbe 0x00007fe46279114a // 直到这里,说明%rax大于%r11 0x00007fe462791137: movabs $0x7fe46278c360,%r11 0x00007fe462791141: cmp %r11,%rax // 当第一个操作数大于第二个操作数时,设置CF为1 // 如果CF为1时,跳转到L_ok位置 0x00007fe462791144: jb 0x00007fe4627911e7 -- L_fail -- 0x00007fe46279114a: movabs $0x7fe462687420,%r11 0x00007fe462791154: cmp %r11,%rax 0x00007fe462791157: jbe 0x00007fe462791170 0x00007fe46279115d: movabs $0x7fe46268be58,%r11 0x00007fe462791167: cmp %r11,%rax 0x00007fe46279116a: jb 0x00007fe4627911e7 0x00007fe462791170: mov %rsp,-0x28(%rsp) 0x00007fe462791175: sub $0x80,%rsp 0x00007fe46279117c: mov %rax,0x78(%rsp) 0x00007fe462791181: mov %rcx,0x70(%rsp) 0x00007fe462791186: mov %rdx,0x68(%rsp) 0x00007fe46279118b: mov %rbx,0x60(%rsp) 0x00007fe462791190: mov %rbp,0x50(%rsp) 0x00007fe462791195: mov %rsi,0x48(%rsp) 0x00007fe46279119a: mov %rdi,0x40(%rsp) 0x00007fe46279119f: mov %r8,0x38(%rsp) 0x00007fe4627911a4: mov %r9,0x30(%rsp) 0x00007fe4627911a9: mov %r10,0x28(%rsp) 0x00007fe4627911ae: mov %r11,0x20(%rsp) 0x00007fe4627911b3: mov %r12,0x18(%rsp) 0x00007fe4627911b8: mov %r13,0x10(%rsp) 0x00007fe4627911bd: mov %r14,0x8(%rsp) 0x00007fe4627911c2: mov %r15,(%rsp) 0x00007fe4627911c6: movabs $0x7fe473e147a8,%rdi 0x00007fe4627911d0: movabs $0x7fe462791170,%rsi 0x00007fe4627911da: mov %rsp,%rdx 0x00007fe4627911dd: and $0xfffffffffffffff0,%rsp 0x00007fe4627911e1: callq 0x00007fe4738c143c 0x00007fe4627911e6: hlt -- L_ok -- 0x00007fe4627911e7: mov %rsp,%r11 0x00007fe4627911ea: and $0xfffffffffffffff0,%rsp 0x00007fe4627911ee: push %rax 0x00007fe4627911ef: mov %r11,%rax 0x00007fe4627911f2: mov 0x48(%rbx),%r11 0x00007fe4627911f6: mov 0x8(%rax),%rsi 0x00007fe4627911fa: mov %rbx,0x248(%r15) 0x00007fe462791201: mov %rbx,%rax 0x00007fe462791204: jmpq *%r11
注意生成的汇编代码会以函数传入的实参的不同而不同,例如传入的实参是2时的汇编如下:
// 正确时跳转到这里 // Must preserve(维护) original SP for loading incoming arguments because // we need to align the outgoing(离开的) SP for compiled code. 0x00007fffe110a267: mov %rsp,%r11 // Ensure compiled code always sees stack at proper alignment 0x00007fffe110a26a: and $0xfffffffffffffff0,%rsp // %rsp按照16字节对齐 // push the return address and misalign 不重合 the stack that youngest frame always sees // as far as(只要,直到...为止) the placement of the call instruction 0x00007fffe110a26e: push %rax // Put saved SP in another register 0x00007fffe110a26f: mov %r11,%rax // Will jump to the compiled code just as if compiled code was doing it. // Pre-load the register-jump target early, to schedule it better. 0x00007fffe110a272: mov 0x48(%rbx),%r11 // 获取Method:_from_compiled_entry值存储到%r11中 // Now generate the shuffle code. Pick up all register args and move the // rest through the floating point stack top. 0x00007fffe110a276: mov 0x8(%rax),%rsi // saved_sp+0x8移动到%rsi,准备参数的操作,%rsi是第2个参数用的指定寄存器 0x00007fffe110a27a: mov %rbx,0x248(%r15) // 将%rbx的值存储到JavaThread::_callee_target中,%rbx应该是Method* // put Method* where a c2i would expect should we end up there // only needed becaus of c2 resolve stubs return Method* as a result in rax 0x00007fffe110a281: mov %rbx,%rax 0x00007fffe110a284: jmpq *%r11
在跳转之前的栈帧如下图所示。

2、编译执行切换到解释执行的例程
调用SharedRuntime::gen_c2i_adapter()函数生成编译执行切换到解释执行的例程,在这个函数中首先会调用patch_callers_callsite()函数,生成的例程如下:
调用生成的汇编代码如下:
// %rbx中存储的是Method*,比较Method::_code属性与NULL_WORD 0x00007fffe110a2b4: cmpq $0x0,0x50(%rbx) // 如果Method::_code为NULL,则跳转到L 0x00007fffe110a2bc: je 0x00007fffe110a3a4 // Method::_code属性不为空时才会执行下面的汇编 0x00007fffe110a2c2: mov %rsp,%r13 // 保存当前的栈指针 // Schedule(安排) the branch target address early. // Call into the VM to patch the caller, then jump to compiled callee // rax isn't live so capture return address while we easily can // 将返回地址保存到%rax中,因为编译的方法在调用方法时,会压入 // 返回地址,所以(%rsp)获取的是返回地址 0x00007fffe110a2c5: mov (%rsp),%rax 0x00007fffe110a2c9: and $0xfffffffffffffff0,%rsp // 对齐栈 // 省略调用push_CPU_state()方法生成的汇编 // ... // %rbx->c_rarg0,其中%rbx中存储的是Method*,因为调用函数的第1个参数要求Method* 0x00007fffe110a334: mov %rbx,%rdi // %rax->c_rarg1,%rax中保存的是返回地址,因为调用函数第2个参数要求caller_pc 0x00007fffe110a337: mov %rax,%rsi // 调用SharedRuntime::fixup_callers_callsite()函数 0x00007fffe110a33a: callq 0x00007ffff6a0ec10 // 省略调用pop_CPU_state()方法生成的汇编 // ... // 恢复rsp寄存器 0x00007fffe110a3a1: mov %r13,%rsp // **** L **** // **** skip_fixup ****
从如上汇编可以看出,如果Method::code为NULL,则直接跳转到L,否则调用SharedRuntime::fixup_callers_callsite()函数。
调用的SharedRuntime::fixup_callers_callsite()函数的实现如下 :
// We are calling the interpreter via a c2i. Normally this would mean that
// we were called by a compiled method. However we could have lost a race
// where we went int -> i2c -> c2i and so the caller could in fact be interpreted.
// If the caller is compiled we attempt to patch the caller
// so he no longer calls into the interpreter.
IRT_LEAF(void, SharedRuntime::fixup_callers_callsite(Method* method, address caller_pc))
Method* moop(method);
address entry_point = moop->from_compiled_entry();
// It's possible that deoptimization can occur at a call site which hasn't
// been resolved yet, in which case this function will be called from
// an nmethod that has been patched for deopt and we can ignore the
// request for a fixup.
// Also it is possible that we lost a race in that from_compiled_entry
// is now back to the i2c in that case we don't need to patch and if
// we did we'd leap into space because the callsite needs to use
// "to interpreter" stub in order to load up the Method*. Don't
// ask me how I know this...
CodeBlob* cb = CodeCache::find_blob(caller_pc);
if (!cb->is_nmethod() || entry_point == moop->get_c2i_entry()) {
return;
}
// The check above makes sure this is a nmethod.
nmethod* nm = cb->as_nmethod_or_null();
assert(nm, "must be");
// Get the return PC for the passed caller PC.
address return_pc = caller_pc + frame::pc_return_offset; // 对于x86来说,pc_return_offset的值为0
// There is a benign race here. We could be attempting to patch to a compiled
// entry point at the same time the callee is being deoptimized. If that is
// the case then entry_point may in fact point to a c2i and we'd patch the
// call site with the same old data. clear_code will set code() to NULL
// at the end of it. If we happen to see that NULL then we can skip trying
// to patch. If we hit the window where the callee has a c2i in the
// from_compiled_entry and the NULL isn't present yet then we lose the race
// and patch the code with the same old data. Asi es la vida.带些许无奈口气
if (moop->code() == NULL){
return;
}
if (nm->is_in_use()) {
// Expect to find a native call there (unless 除非; 除非在 it was no-inline cache vtable dispatch)
MutexLockerEx ml_patch(Patching_lock, Mutex::_no_safepoint_check_flag);
if (NativeCall::is_call_before(return_pc)) {
NativeCall *call = nativeCall_before(return_pc);
//
// bug 6281185. We might get here after resolving a call site to a vanilla
// virtual call. Because the resolvee uses the verified entry it may then
// see compiled code and attempt to patch the site by calling us. This would
// then incorrectly convert the call site to optimized and its downhill from
// there. If you're lucky you'll get the assert in the bugid, if not you've
// just made a call site that could be megamorphic into a monomorphic site
// for the rest of its life! Just another racing bug in the life of
// fixup_callers_callsite ...
//
RelocIterator iter(nm, call->instruction_address(), call->next_instruction_address());
iter.next();
assert(iter.has_current(), "must have a reloc at java call site");
relocInfo::relocType typ = iter.reloc()->type();
if (
typ != relocInfo::static_call_type &&
typ != relocInfo::opt_virtual_call_type &&
typ != relocInfo::static_stub_type
){
return;
}
address destination = call->destination();
if (destination != entry_point) {
CodeBlob* callee = CodeCache::find_blob(destination);
// callee == cb seems weird. It means calling interpreter thru stub.
if (callee == cb || callee->is_adapter_blob()) {
// static call or optimized virtual
if (TraceCallFixup) {
tty->print("fixup callsite at " INTPTR_FORMAT " to compiled code for", caller_pc);
moop->print_short_name(tty);
tty->print_cr(" to " INTPTR_FORMAT, entry_point);
}
call->set_destination_mt_safe(entry_point);
}
} else { // 满足的条件:destination == entry_point
if (TraceCallFixup) {
tty->print("already patched callsite at " INTPTR_FORMAT " to compiled code for", caller_pc);
moop->print_short_name(tty);
tty->print_cr(" to " INTPTR_FORMAT, entry_point);
}
}
}
}
IRT_END
调用的set_destination_mt_safe()函数的实现如下:
// Similar to replace_mt_safe, but just changes the destination. The
// important thing is that free-running threads are able to execute this
// call instruction at all times. If the displacement field is aligned
// we can simply rely on atomicity of 32-bit writes to make sure other threads
// will see no intermediate states. Otherwise, the first two bytes of the
// call are guaranteed to be aligned, and can be atomically patched to a
// self-loop to guard the instruction while we change the other bytes.
// We cannot rely on locks here, since the free-running threads must run at
// full speed.
//
// Used in the runtime linkage of calls; see class CompiledIC.
// (Cf. 4506997 and 4479829, where threads witnessed garbage displacements.)
void NativeCall::set_destination_mt_safe(address dest) {
debug_only(verify());
// Make sure patching code is locked. No two threads can patch at the same
// time but one may be executing this code.
assert(Patching_lock->is_locked() ||
SafepointSynchronize::is_at_safepoint(), "concurrent code patching");
// Both C1 and C2 should now be generating code which aligns the patched address
// to be within a single cache line except that C1 does not do the alignment on
// uniprocessor systems.
bool is_aligned = ((uintptr_t)displacement_address() + 0) / cache_line_size ==
((uintptr_t)displacement_address() + 3) / cache_line_size;
guarantee(!os::is_MP() || is_aligned, "destination must be aligned");
if (is_aligned) {
// Simple case: The destination lies within a single cache line.
set_destination(dest);
} else if ((uintptr_t)instruction_address() / cache_line_size ==
((uintptr_t)instruction_address()+1) / cache_line_size) {
// Tricky case: The instruction prefix lies within a single cache line.
intptr_t disp = dest - return_address();
#ifdef AMD64
guarantee(disp == (intptr_t)(jint)disp, "must be 32-bit offset");
#endif // AMD64
int call_opcode = instruction_address()[0];
// First patch dummy jump in place:
{
u_char patch_jump[2];
patch_jump[0] = 0xEB; // jmp rel8
patch_jump[1] = 0xFE; // jmp to self
assert(sizeof(patch_jump)==sizeof(short), "sanity check");
*(short*)instruction_address() = *(short*)patch_jump;
}
// Invalidate. Opteron requires a flush after every write.
wrote(0);
// (Note: We assume any reader which has already started to read
// the unpatched call will completely read the whole unpatched call
// without seeing the next writes we are about to make.)
// Next, patch the last three bytes:
u_char patch_disp[5];
patch_disp[0] = call_opcode;
*(int32_t*)&patch_disp[1] = (int32_t)disp;
assert(sizeof(patch_disp)==instruction_size, "sanity check");
for (int i = sizeof(short); i < instruction_size; i++)
instruction_address()[i] = patch_disp[i];
// Invalidate. Opteron requires a flush after every write.
wrote(sizeof(short));
// (Note: We assume that any reader which reads the opcode we are
// about to repatch will also read the writes we just made.)
// Finally, overwrite the jump:
*(short*)instruction_address() = *(short*)patch_disp;
// Invalidate. Opteron requires a flush after every write.
wrote(0);
debug_only(verify());
guarantee(destination() == dest, "patch succeeded");
} else {
// Impossible: One or the other must be atomically writable.
ShouldNotReachHere();
}
}
接着回到gen_c2i_adapter()函数继续执行,生成的汇编代码如下:
0x00007fffe110a3a4: pop %rax // 将返回地址保存到%rax中
0x00007fffe110a3a5: mov %rsp,%r13 // 将sender sp设置到%r13中 0x00007fffe110a3a8: sub $0x10,%rsp // $0x10是要传递的参数加上返回地址的空间 0x00007fffe110a3ac: mov %rax,(%rsp) // 将返回地址存储存储到指定的空间 0x00007fffe110a3b0: mov %rsi,0x8(%rsp) // 将传递的参数写到栈中指定的位置 0x00007fffe110a3b5: mov 0x38(%rbx),%rcx// 将Method::_i2i_entry写入到%rcx中 0x00007fffe110a3b9: jmpq *%rcx // 跳转执行
3、编译执行切换到解释执行的未验证例程
在SharedRuntime::generate_i2c2i_adapters()函数中生成_c2i_unverified_entry,如下:
这个函数首先会调用gen_i2c_adapter()函数生成汇编代码,之前介绍过。然后生成自己的汇编代码,然后再调用gen_c2i_adapter()生成汇编代码,之前已经介绍过。
(也是一个转换入口,为c2i_unverified_entry)
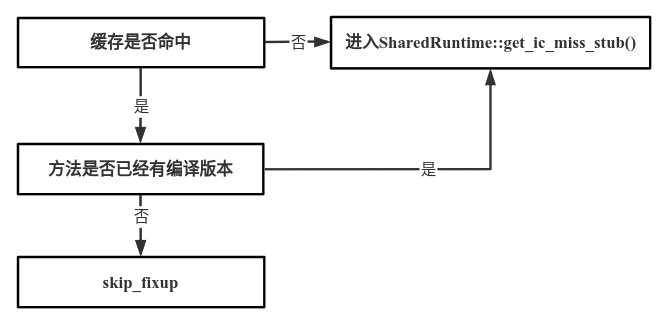
// %rsi中存储的是receiver,获取oop.Klass到%ebx中 0x00007fffe110a287: mov 0x8(%rsi),%ebx // LogKlassAlignmentInBytes=0x3 0x00007fffe110a28a: shl $0x3,%rbx // %rax中存储的是holder,和holder.Klass进行比较 0x00007fffe110a28e: cmp 0x10(%rax),%rbx // CompiledICHolder::_holder_method存储到%rbx 0x00007fffe110a292: mov 0x8(%rax),%rbx // 如果相等,表示缓存命中,跳转到----ok---- 0x00007fffe110a296: je 0x00007fffe110a2a1 // 否则跳转到SharedRuntime::get_ic_miss_stub()函数入口 0x00007fffe110a29c: jmpq 0x00007fffe1105be0 // **** ok **** // 当oop.Klass与holder.Klass相等时跳转到这里执行 // Method might have been compiled since the call site was patched to // interpreted if that is the case treat it as a miss so we can get // the call site corrected. // %rbx中存储的是Method*,获取Method::code与NULL_WORD进行比较 0x00007fffe110a2a1: cmpq $0x0,0x50(%rbx) // 如果相等就跳过修正,跳转到----skip_fixup----,这个调用点在get_c2i_adapter()方法中定义 0x00007fffe110a2a9: je 0x00007fffe110a3a4 // 执行下面的汇编时,表示在调用点要patch到解释器时, // 方法已经编译完成,所以按缓存没有命中处理,这样就会修正调用点 // 跳转到SharedRuntime::get_ic_miss_stub()函数入口 0x00007fffe110a2af: jmpq 0x00007fffe1105be0
执行流程图如下:
公众号 深入剖析Java虚拟机HotSpot 已经更新虚拟机源代码剖析相关文章到60+,欢迎关注,如果有任何问题,可加作者微信mazhimazh,拉你入虚拟机群交流
