第58篇-触发编译
在之前介绍方法调用计数和回边计数时介绍过,当计数值超过阈值时会调用InterpreterRuntime::frequency_counter_overflow()函数对方法或块进行编译。此函数会进一步调用到CompilationPolicy::event()函数,在此函数中会根据当前的编译模式选择合适的编译器去编译。
函数的实现如下:
nmethod* InterpreterRuntime::frequency_counter_overflow(
JavaThread* thread,
address branch_bcp
){
nmethod* nm = frequency_counter_overflow_inner(thread, branch_bcp);
assert(branch_bcp != NULL || nm == NULL, "always returns null for non OSR requests");
// 当为OSR编译并且已经获取到编译后的版本时,重新从lookup_osr_nmethod_for()函数
// 中查找一次
if (branch_bcp != NULL && nm != NULL) {
// 目标方法是一个需要栈上替换的方法,因为frequency_counter_overflow_inner()
// 函数返回的nm没有加载,所以需要再次查找
frame fr = thread->last_frame();
Method* method = fr.interpreter_frame_method();
address bcp = fr.interpreter_frame_bcp();
int bci = method->bci_from(bcp);
nm = method->lookup_osr_nmethod_for(bci, CompLevel_none, false);
}
return nm;
}
在如上函数中,当为非OSR编译时(需要对整个方法进行编译),函数永远返回null,即不会立即执行编译,而是提交任务给后台编译线程编译;当为OSR编译时,传递的branch_bcp参数不为null,在调用的frequency_counter_overflow_inner()函数中通常会等待编译完成后才会返回。
如上函数的第2个参数表明调用计数超过阈值是否发生在循环分支上,如果不是则传递null,如果是则传该循环的跳转分支地址。
调用的frequency_counter_overflow_inner()函数的实现如下:
IRT_ENTRY(nmethod*,InterpreterRuntime::frequency_counter_overflow_inner(
JavaThread* thread,
address branch_bcp
))
// ...
frame fr = thread->last_frame();
// 验证当前方法是被解释执行的,只有解释执行时情况下才能调用此函数
assert(fr.is_interpreted_frame(), "must come from interpreter");
// 获取当前解释执行的方法
methodHandle method(thread, fr.interpreter_frame_method());
// branch_bcp非空时获取其相对于方法字节码起始地址code_base的偏移,否则等于InvocationEntryBci,
// InvocationEntryBci表明这是非栈上替换的方法编译
const int branch_bci = branch_bcp != NULL ? method->bci_from(branch_bcp) : InvocationEntryBci;
const int bci = branch_bcp != NULL ? method->bci_from(fr.interpreter_frame_bcp()) : InvocationEntryBci;
// 获取编译策略
CompilationPolicy* cp = CompilationPolicy::policy();
// 如果要求栈上替换,返回该方法对应的nmethod;否则异步提交一个方法编译的任务给后台编译线程,然后返回NULL
nmethod* osr_nm = cp->event(method, method, branch_bci, bci, CompLevel_none, NULL, thread);
// ... 省略一部分对偏向锁的处理逻辑
return osr_nm;
IRT_END
address frame::interpreter_frame_bcp() const {
intptr_t bcx = interpreter_frame_bcx();
return is_bci(bcx) ? interpreter_frame_method()->bcp_from(bcx) : (address)bcx;
}
inline bool frame::is_bci(intptr_t bcx) {
return ( (uintptr_t)bcx ) <= ((uintptr_t) max_method_code_size) ;
}
如上函数最重要的就是调用了CompilationPolicy的event()函数,关于CompilationPolicy之前在介绍编译策略时介绍过,当使用分层编译时,其使用的是AdvancedThreadsholdPolicy,由于这个类没有实现event()函数,所以会调用到SimpleThreadsholdPolicy::event()函数,此函数的实现如下:
nmethod* SimpleThresholdPolicy::event(
methodHandle method,
methodHandle inlinee,
int branch_bci,
int bci,
CompLevel comp_level,
nmethod* nm,
JavaThread* thread
) {
// ...
if (bci == InvocationEntryBci) { // 编译整个方法
method_invocation_event(method, inlinee, comp_level, nm, thread);
} else { // 编译热点代码
method_back_branch_event(method, inlinee, bci, comp_level, nm, thread);
int highest_level = inlinee->highest_osr_comp_level();
if (highest_level > comp_level) {
osr_nm = inlinee->lookup_osr_nmethod_for(bci, highest_level, false);
}
}
return osr_nm;
}
调用method_invocation_event()函数编译整个方法,调用method_back_branch_event()函数编译热点代码。
当编译的层级高于当前执行的层级时,就应该选择编译的层级。调用lookup_osr_nmethod_for()函数查找当前编译出来的、用来进行栈上替换的本地方法。函数的实现如下:
nmethod* lookup_osr_nmethod_for(int bci, int level, bool match_level) {
return method_holder()->lookup_osr_nmethod(this, bci, level, match_level);
}
调用的lookup_os_nmethod()函数的实现如下:
nmethod* InstanceKlass::lookup_osr_nmethod(
const Method* m,
int bci,
// 表示当前运行的、或已经编译出了可被运行的层级
int comp_level,
// 表示查找某个编译层级的osr nmethod
bool match_level
) const {
nmethod* osr = osr_nmethods_head();
nmethod* best = NULL;
// 当match_level的值为false时,查找的是最高的编译层级的结果,
// 否则就是查找comp_level层级的编译结果
while (osr != NULL) {
if (
osr->method() == m &&
(bci == InvocationEntryBci || osr->osr_entry_bci() == bci)
){
if (match_level) { // 当match_level的值为true时,表示查找特定的编译层级的结果
if (osr->comp_level() == comp_level) {
return osr;
}
} else {
if (best == NULL || (osr->comp_level() > best->comp_level())) {
if (osr->comp_level() == CompLevel_highest_tier) {
return osr;
}
best = osr;
}
}
}
osr = osr->osr_link();
}
if (best != NULL && best->comp_level() >= comp_level && match_level == false) {
return best;
}
return NULL;
}
由于所有编译的OSR版本在完成之后都会在Method类中通过单链表的形式连接起来,所以需要遍历这个列表。当match_level的值为true时,就表示查找指定编译级别下的OSR版本;当match_level的值为false时,表示查找到编译级别最高的OSR版本。
在本篇文章最开始之前介绍的InterpreterRuntime::frequency_counter_overflow()函数,这个函数也会调用如上函数查找最高层级的OSR版本,所以传递的值match_level的值为false。
1、AdvancedThresholdPolicy::method_invocation_event()函数
当需要对整个方法进行编译时,调用AdvancedThresholdPolicy::method_invocation_event()函数,此函数的实现如下:
void AdvancedThresholdPolicy::method_invocation_event(
methodHandle mh,
methodHandle imh,
CompLevel level,
nmethod* nm,
JavaThread* thread
) {
if (should_create_mdo(mh(), level)) {
create_mdo(mh, thread);
}
// 当前环境支持编译任务并且编译任务不再当前的编译队列中时,可能会编译
if (is_compilation_enabled() && !CompileBroker::compilation_is_in_queue(mh, InvocationEntryBci)) {
CompLevel next_level = call_event(mh(), level);
if (next_level != level) {
compile(mh, InvocationEntryBci, next_level, thread);
}
}
}
如上函数还会涉及到统计相关的逻辑,例如可能会调用create_mdo()函数创建MethodData实例并赋值给Method::_method_data属性。
调用的should_create_mdo()函数的实现如下:
// 当方法运行很长时间时还是解释执行,那么需要创建MethodData来统计运行时信息,
// 是否创建MethodData还会考虑编译器的负载情况
bool AdvancedThresholdPolicy::should_create_mdo(
Method* method,
CompLevel cur_level
) {
if (
// 当前的方法在解释执行
cur_level == CompLevel_none &&
// 当编译队列中的CompLevel_full_optimization层
// 级的任务小于(5*C2编译器线程数)时,表示编译器的负载小
CompileBroker::queue_size(CompLevel_full_optimization) <= Tier3DelayOn * compiler_count(CompLevel_full_optimization)
) {
int i = method->invocation_count();
int b = method->backedge_count();
double k = Tier0ProfilingStartPercentage / 100.0;
return call_predicate_helper<CompLevel_none>(i, b, k) || loop_predicate_helper<CompLevel_none>(i, b, k);
}
return false;
}
当前的方法在解释执行并且C2编译器的负载比较小时,我们需要根据现在的统计信息进一步调用call_predicate_helper()或loop_predicate_helper()函数。当2个函数中有1个返回true时,会创建MethodData实例,此用来统计当前的解释执行的运行时信息。
调用的invocation_count()和backedge_count()函数的实现如下:
int Method::invocation_count() {
MethodCounters *mcs = method_counters();
if (TieredCompilation) {
MethodData* const mdo = method_data();
if (
((mcs != NULL) ? mcs->invocation_counter()->carry() : false) ||
((mdo != NULL) ? mdo->invocation_counter()->carry() : false)
) {
return InvocationCounter::count_limit;
} else {
return ((mcs != NULL) ? mcs->invocation_counter()->count() : 0) +
((mdo != NULL) ? mdo->invocation_counter()->count() : 0);
}
} else {
return (mcs == NULL) ? 0 : mcs->invocation_counter()->count();
}
}
int Method::backedge_count() {
MethodCounters *mcs = method_counters();
if (TieredCompilation) {
MethodData* const mdo = method_data();
if (((mcs != NULL) ? mcs->backedge_counter()->carry() : false) ||
((mdo != NULL) ? mdo->backedge_counter()->carry() : false)) {
return InvocationCounter::count_limit;
} else {
return ((mcs != NULL) ? mcs->backedge_counter()->count() : 0) +
((mdo != NULL) ? mdo->backedge_counter()->count() : 0);
}
} else {
return (mcs == NULL) ? 0 : mcs->backedge_counter()->count();
}
}
参考Method::_method_counters和Method::_method_data属性的值,只有返回大一些的回边或方法调用数值,才能在调用call_predicate_helper()或loop_predicate_helper()函数时返回true。2个函数的实现如下:
// i是调用数,b是回边数
template<CompLevel level>
bool SimpleThresholdPolicy::call_predicate_helper(int i, int b, double scale) {
switch(level) {
case CompLevel_none:
case CompLevel_limited_profile:
return
// 方法调用>200 * 2
(i > Tier3InvocationThreshold * scale) ||
// ( 方法调用>100*2 && (方法调用+回边计数)>2000*2 )
(i > Tier3MinInvocationThreshold * scale && i + b > Tier3CompileThreshold * scale);
case CompLevel_full_profile:
return
// 方法调用>5000*2
(i > Tier4InvocationThreshold * scale) ||
// ( 方法调用>600*2 && (方法调用+回边计数)>15000*2 )
(i > Tier4MinInvocationThreshold * scale && i + b > Tier4CompileThreshold * scale);
}
return true;
}
template<CompLevel level>
bool SimpleThresholdPolicy::loop_predicate_helper(int i, int b, double scale) {
switch(level) {
case CompLevel_none:
case CompLevel_limited_profile:
// 回边计数>60000*2
return b > Tier3BackEdgeThreshold * scale;
case CompLevel_full_profile:
// 回边计数>40000*2
return b > Tier4BackEdgeThreshold * scale;
}
return true;
}
当如上两个函数任何一个返回true时,调用create_mdo()函数创建MethodData,函数的实现如下:
void AdvancedThresholdPolicy::create_mdo(methodHandle mh, JavaThread* THREAD) {
if (mh->is_native() || mh->is_abstract() || mh->is_accessor()){
return;
}
if (mh->method_data() == NULL) {
Method::build_interpreter_method_data(mh, CHECK_AND_CLEAR);
}
}
// 创建MethodData,用来收集从编译执行中获取的运行时统计信息
void Method::build_interpreter_method_data(methodHandle method, TRAPS) {
MutexLocker ml(MethodData_lock, THREAD);
if (method->method_data() == NULL) {
ClassLoaderData* loader_data = method->method_holder()->class_loader_data();
MethodData* method_data = MethodData::allocate(loader_data, method, CHECK);
method->set_method_data(method_data);
}
}
AdvancedThresholdPolicy::method_invocation_event()函数在判断了当前环境支持编译任务并且编译任务不再当前的编译队列中时,可能会调用call_event()函数,此函数的实现如下:
CompLevel AdvancedThresholdPolicy::call_event(
Method* method,
CompLevel cur_level
) {
// OSR的编译层级
CompLevel osr_level = MIN2(
(CompLevel) method->highest_osr_comp_level(),
common(&AdvancedThresholdPolicy::loop_predicate, method, cur_level, true)
);
// 方法的编译层级
CompLevel next_level = common(&AdvancedThresholdPolicy::call_predicate, method, cur_level);
// 如果OSR的编译层级比方法编译层级高,那么应该提升方法编译层级,否则在每次方法调用时可能需要
// 进行OSR编译
if (osr_level == CompLevel_full_optimization && cur_level == CompLevel_full_profile) {
MethodData* mdo = method->method_data();
if (mdo->invocation_count() >= 1) {
next_level = CompLevel_full_optimization;
}
} else {
next_level = MAX2(osr_level, next_level);
}
return next_level;
}
如上函数会根据编译策略来决定下一个编译的层次,大部分的编译策略的逻辑都在common()函数中,这个函数在下一篇将会详细介绍。
2、AdvancedThresholdPolicy::method_back_branch_event()函数
调用AdvancedThresholdPolicy::method_back_branch_event()函数进行OSR编译,函数的实现如下:
void AdvancedThresholdPolicy::method_back_branch_event(
methodHandle mh,
methodHandle imh,
int bci,
CompLevel level,
nmethod* nm,
JavaThread* thread
) {
if (should_create_mdo(mh(), level)) {
create_mdo(mh, thread);
}
if (should_create_mdo(imh(), level)) {
create_mdo(imh, thread);
}
if (!is_compilation_enabled()) {
return;
}
CompLevel next_osr_level = loop_event(imh(), level);
CompLevel max_osr_level = (CompLevel)imh->highest_osr_comp_level();
// compilation_is_in_queue()函数判断是否在编译队列中已经存在了这个编译请求,如果
// 不存在,并且要求的编译层次与当前运行的层次不同时,调用compile()函数
if (!CompileBroker::compilation_is_in_queue(imh, bci) && next_osr_level != level) {
compile(imh, bci, next_osr_level, thread);
}
// 判断当前方法是否也已经达到方法编译的条件
CompLevel cur_level, next_level;
// ...
cur_level = comp_level(imh());
next_level = call_event(imh(), cur_level);
if (!CompileBroker::compilation_is_in_queue(imh, bci) && next_level != cur_level) {
compile(imh, InvocationEntryBci, next_level, thread);
}
}
在函数开始时,同样会调用should_create_mdo()判断是否需要创建MethodData实例,如果需要,则调用create_mdo()函数创建并赋值给Method::_method_data变量保存。
调用AdvancedThresholdPolicy::loop_event()函数判断是否需要对方法进行OSR编译。个函数的实现如下:
CompLevel AdvancedThresholdPolicy::loop_event(Method* method, CompLevel cur_level) {
CompLevel next_level = common(&AdvancedThresholdPolicy::loop_predicate, method, cur_level, true);
if (cur_level == CompLevel_none) { // CompLevel_none的值为0,表示解释执行层级
// If there is a live OSR method that means that we deopted to the interpreter
// for the transition.
CompLevel osr_level = MIN2((CompLevel)method->highest_osr_comp_level(), next_level);
if (osr_level > CompLevel_none) {
return osr_level;
}
}
return next_level;
}
此函数与方法编译时一样,调用common()函数根据编译策略来决定下一个编译的层级。
调用的common()函数将在下一篇详细介绍。
整个调用如下图所示。
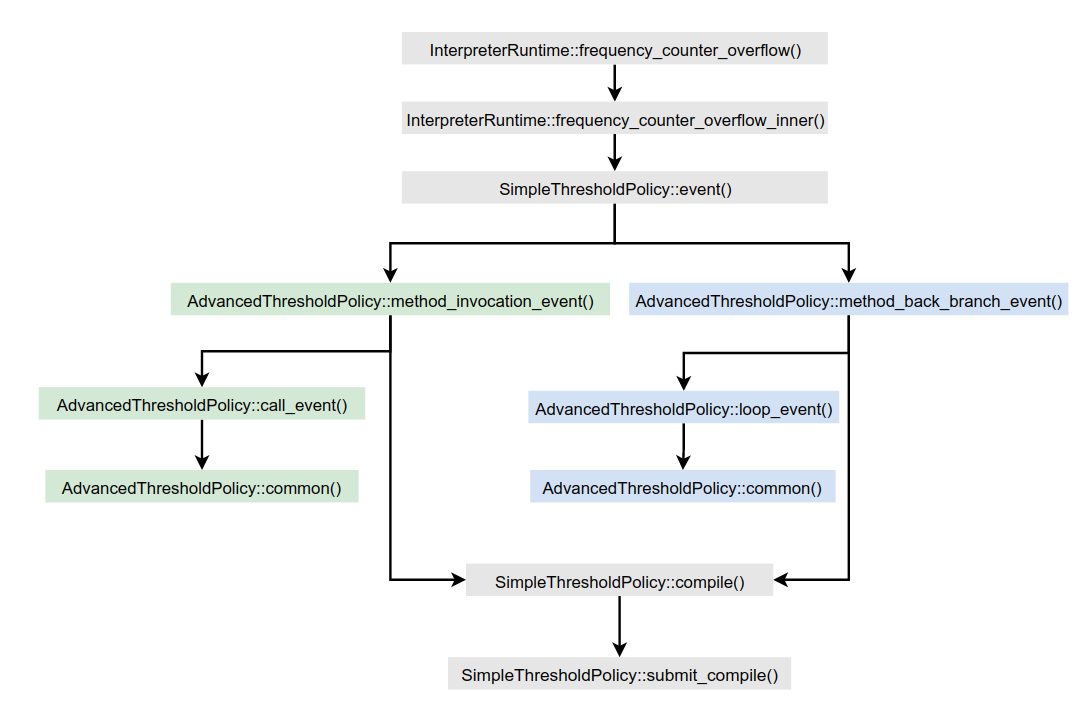
无论是OSR编译还是方法编译,最终都会调用SimpleThresholdPolicy::compile()函数进行。SimpleThresholdPolicy::compile()函数的实现如下:
void SimpleThresholdPolicy::compile(
methodHandle mh,
int bci,
CompLevel level,
JavaThread* thread
) {
// 目标编译层级仍然是解释执行,则直接返回即可
if (level == CompLevel_none) {
return;
}
if (!can_be_compiled(mh, level)) {
// 当要求C2编译器编译,但是can_be_compiled()函数已经返回false,就表示C2编译器无法编译,此时
// 再次调用can_be_compiled()函数判断是否能用C1编译器编译
if (level == CompLevel_full_optimization && can_be_compiled(mh, CompLevel_simple)) {
compile(mh, bci, CompLevel_simple, thread); // 递归调用当前函数
}
return;
}
// 当为OSR编译并且无法在level层级下进行OSR编译时直接返回
if (bci != InvocationEntryBci && mh->is_not_osr_compilable(level)) {
return;
}
// 当前编译任务不再编译队列时,提交OSR或方法编译任务给C1或C2编译任务队列
if (!CompileBroker::compilation_is_in_queue(mh, bci)) {
submit_compile(mh, bci, level, thread);
}
}
当方法或OSR能在level层级下进行编译时,调用submit_compile()函数提交编译任务,submit_compile()函数在后面会详细介绍。
调用CompilationPolicy::can_be_compiled()函数的实现如下:
bool CompilationPolicy::can_be_compiled(methodHandle m, int comp_level) {
// 抽象方法不需要编译
if (m->is_abstract())
return false;
// 太大的方法不需要编译
if (DontCompileHugeMethods && m->code_size() > HugeMethodLimit)
return false;
// 当为一些intrinsic方法时不需要编译
if (!AbstractInterpreter::can_be_compiled(m)) {
return false;
}
if (comp_level == CompLevel_all) { // CompLevel_all的值为-1
if (TieredCompilation) {
// 在分层编译的情况下能可以编译为任何一个编译层级
return !m->is_not_compilable(CompLevel_simple) || !m->is_not_compilable(CompLevel_full_optimization);
} else {
// 非分层编译情况下的处理逻辑
return !m->is_not_compilable(CompLevel_highest_tier);
}
}
// 如果C1或C2编译器可以编译comp_level,则is_compile()函数返回true
else if (is_compile(comp_level)) {
return !m->is_not_compilable(comp_level);
}
return false;
}
如果检查后发现方法需要编译,则调用submit_compile()函数提交编译任务。
bool Method::is_not_compilable(int comp_level) const {
if (number_of_breakpoints() > 0) // 方法含有断点时不允许编译
return true;
// 当方法为internal MethodHandle primitive method且是编译器合成的方法时
if (is_always_compilable())
return false;
// C1或C2编译器是否能编译comp_evel层级的方法
if (comp_level == CompLevel_any)
return is_not_c1_compilable() || is_not_c2_compilable();
if (is_c1_compile(comp_level))
return is_not_c1_compilable();
if (is_c2_compile(comp_level))
return is_not_c2_compilable();
return false;
}
在SimpleThresholdPolicy::compile()函数中,当为OSR编译时,还会调用is_not_osr_compilable()函数判断是否可在level层级下进行编译,函数的实现如下:
bool Method::is_not_osr_compilable(int comp_level) const {
if (is_not_compilable(comp_level))
return true;
// C1或C2编译器是否能编译comp_evel层级的方法
if (comp_level == CompLevel_any)
return is_not_c1_osr_compilable() || is_not_c2_osr_compilable();
if (is_c1_compile(comp_level))
return is_not_c1_osr_compilable();
if (is_c2_compile(comp_level))
return is_not_c2_osr_compilable();
return false;
}
关于调用AdvancedThresholdPolicy::common()函数决定编译策略还是SimpleThresholdPolicy::submit_compile()函数提交编译任务,在接下来的文章都会详细介绍,这里不再过多介绍。
公众号 深入剖析Java虚拟机HotSpot 已经更新虚拟机源代码剖析相关文章到60+,欢迎关注,如果有任何问题,可加作者微信mazhimazh,拉你入虚拟机群交流
