Elasticsearch数据库 | Elasticsearch-7.5.0应用基础实战
Elasticsearch 是一个可用于分布式以及符合RESTful 风格的搜索和数据分析引擎。—— Elastic Stack 官网

1|0关于Elasticsearch的“爱恨情仇"
- 或许提起搜索服务器,大部分人都会想起Solr 和 Elasticsearch 甚至以及国产大厂自研等。随着人工智能和大数据时代的到来,甚至还带动了一系列的机器引擎的出现,譬如Splunk等。其中Solr 和 Elasticsearch是基于Lucene的搜索服务器。一般Solr是面向的是全文检索引擎,而Elasticsearch是用于全文搜索、结构化搜索、分析。而对于Splunk机器数据的引擎,可收集、索引和利用所有应用程序、服务器和设备生成的快速移动型计算机数据。可是不论技术如何发展和更替,作为一位程序员,我们要做的不就是即时地维护技术储备知识库和实时更新自己的技术缓存,以及实现可扩展性的技术深度树的增长。
- 关于Elasticsearch,记得当时接触到Elasticsearch的名词的时候,那是2017年的夏天。当时的工作任务是实现一个关于知识库的系统。当时小伙伴们技术选型主要还是偏向Solr+Lucene来的做,有的甚至说直接使用Mysql数据库的自带函数来做。我是在无意中,在网上查询搜索引擎的技术实战的时候,看见了一篇对于Elasticsearch应用实战的应用报告分析,才去查询了Elasticsearch的相关资料。不过,当时网上大部分对于搜索功能的Demo,大部分还是关于Solr 的比较多。也许在那个时候,大部分的技术概念基本都是偏向于技术长期稳定和文档资料全,使用程度相对较重的因素。但是,我个人却留了一个心眼,自己尝试去实战Elasticsearch。
- 第一次,动手实操还是在Windows本机上安装(22G内存)的。其中,安装过程相比利用Tomcat+Solr来说,相对较复杂,而且对于本机的内存和功耗占用较重。个开发基本只能说是能运行起来,可稳定性方面,就有点显得望而却步的感觉。第二次,动手实战是在本机搭建了一个虚拟机去实战(2核8G),可在网络通信方面,当时选的是网络桥接方式,也让我对此觉得很是麻烦。第三次,是自己拥有了自己的阿里云服务器,在上面按照传统部署方式(相对于Docker部署来说),可无奈个人服务器内存较低(2核4G),修改配置JVM等无法启动成功,总是抛出GC日志什么的问题,主要还是当时囊中羞涩的问题,甚至一旦运行Elasticsearch服务,其它的应用便无法启动和 运行。后来,接触了Docker,于是,有了第四次的Elasticsearch实战(单节点部署)。第四次,升级了阿里云服务器的配置(2核8G),最终实现了额自己的第一个Elasticsearch服务。甚至,为在后来工作中,动手实战Elasticsearch分布式集群服务奠定基础。
2|0基本概述
- 似乎从某种意义来说Elasticsearch和MongoDB/Redis/Memcache一样,是一种Nosql数据库。是一个接近实时的搜索平台,从索引这个文档到这个文档能够被搜索到只有一个轻微的延迟,企业应用定位:采用Restful API标准的可扩展和高可用的实时数据分析的全文搜索工具。不过在当时,Elastic Stack只有Elasticsearch、Kibana 和 Logstash用例,还没有包含Beats等。而且在应用方面,除了来当作ELK分布式日志系统搭建外,更多的是Elasticsearch +Elasticsearch-Head插件在满足业务场景方面的需求,能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化等。
- 基本特点:
- 可拓展:支持一主多从且扩容简易,只要cluster.name一致且在同一个网络中就能自动加入当前集群;本身就是开源软件,也支持很多开源的第三方插件
- 高可用:在一个集群的多个节点中进行分布式存储,索引支持shards和复制,即使部分节点down掉,也能自动进行数据恢复和主从切换
- 采用RestfulAPI标准:通过http接口使用JSON格式进行操作数据
- 数据存储的最小单位是文档,本质上是一个JSON 文本
3|0Elasticsearch关键词
- Node : 节点,单个装有Elasticsearch服务并且提供故障转移和实现可扩展的服务器
- Cluster : 集群,一个Elasticsearch-Cluster集群是有一个Node或者至少2个Node组成的服务器,共同服务和分享Node节点数据的具有负载均衡的功能,甚至基于Zookeeper集群的高可用服务等。
- Index : 索引,具有相同或者相似特征的Document文档对象的集合
- Type : 类型,相同Filed字段的文档定义一个Type类型,一个Type可以创建多个Index索引
- Document :文档,一个Document文档可以被用作Index索引的基础信息单元
- Field : 字段列,Field是Elasticsearch的最小单元,相挡当于数据的某一列
- Term:由很多的字节组成。一般将Text类型的Field Value分词之后的每个最小单元叫做Term。
- Shards :分片,Elasticsearch把Index索引分成若干份,每一个部分就是一个Shard分片
- Replicas : 复制,每个Inex索引里每个Shard分片的拷贝或者说是数据备份
4|0Elasticsearch 结构与其它数据库对比
- 数据模型上的对比
| databaseType | databaseName | databaseUnit | databaseTable | databaseRow | databaseColumn |
|---|---|---|---|---|---|
| sql | Mysql | 数据库-database | 表-table | 数据行-row | 数据列-column |
| Nosql | Elasticsearch | 索引-index | 类型-type | 文档-document | 字段列-field |
| Nosql | Hbase | 命名空间-namespace | 域/切片-region | 数据行-row | 数据列-column |
- 使用场景上的对比
| databaseType | databaseName | databaseStorage | databaseTransaction | databaseConsistency | databaseScalability | secondaryIndex | fullText |
|---|---|---|---|---|---|---|---|
| sql | Mysql | 行数数据存储,适用OLTP业务 | Innodb引擎支持 | strong consistency-强一致性 | 单机可拓展粒度不高 | 支持 | 支持 |
| Nosql | Elasticsearch | 索引存储-任何检索业务 | 不支持 | 支持可配置 | 水平拓展 | 支持 | 支持 |
| Nosql | Hbase | 列式数据存储,介于OLTP和OLAP模型之间 | 不支持 | strong consistency-强一致性 和 time consistency-时序一致性 | 水平拓展 | 不支持 | 不支持 |
ps[⚠️注意事项]:
- OLTP: OnLine Transaction Processing联机事务处理过程(OLTP),主要对应传统的关系型数据库,基本操作增删改查,强调事务一致性,比如银行系统、电商系统。
- OLAP:Online Analytical processing 即联机分析处理过程(OLAP),主要对应仓储型数据库,基本读取数据,做复杂数据分析,侧重技术决策支持,提供直观简单的结果。
5|0Elasticsearch原理剖析
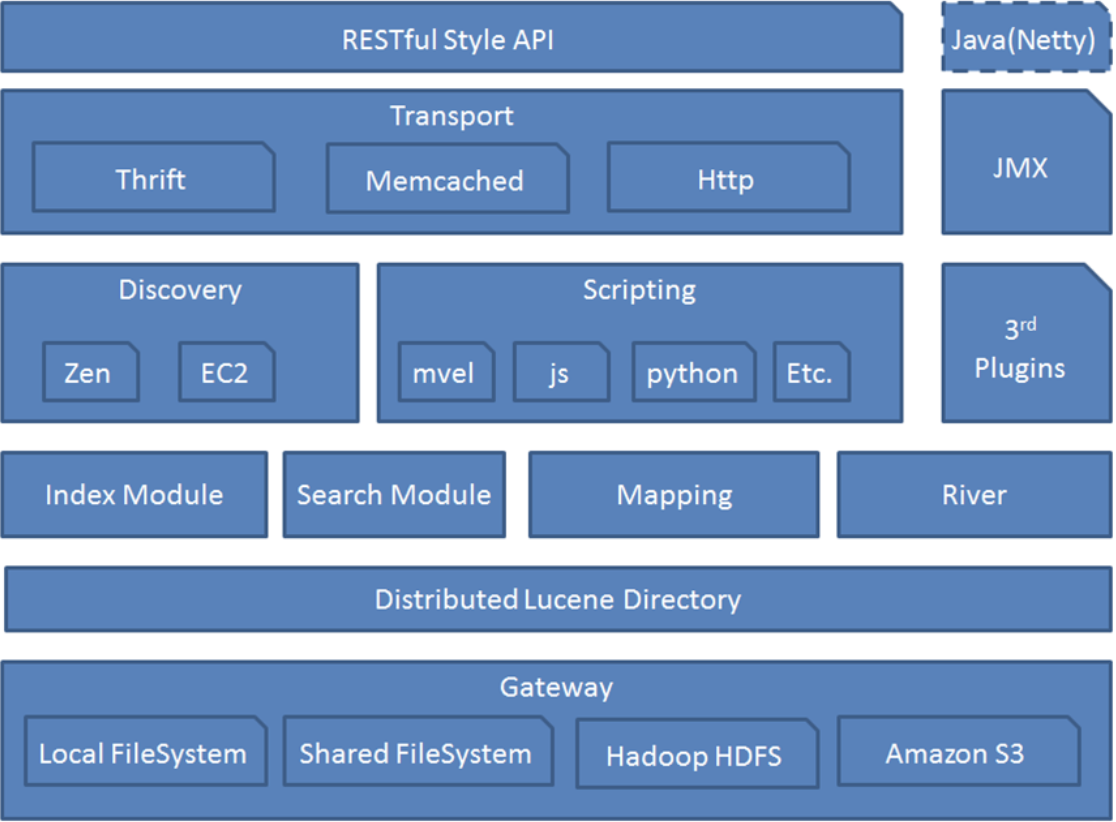
- Gateway[索引数据的存储格式]: Elasticsearch用来存储数据index索引的文件系统,支持多种类型[ Local FileSystem-本地文件系统 Shared FileSystem-分布式文件系统 Hadoop HDFS, Amazon S3 ]
- Distributed Lucene Directory[底层 API框架]:Elasticsearch底层依赖Lucene框架,每一个Elasticsearch节点服务都会有对应的Lucene框架
- Major Module[加工处理方式] : 在Lucene上层,Index Module(创建Index模块)、Search Module(搜索模块)、Mapping(映射)、River(运行在Elasticsearch集群内部的一个插件,主要用来从外部获取获取异构数据,然后在Elasticsearch里创建索引
- Discovery[Elasticsearch发现机制]:Discovery 是Elasticsearch自动发现节点的机制;Zen是用来实现节点自动发现、Master节点选举用;Elasticsearch是基于P2P的系统,它首先通过广播的机制寻找存在的节点,然后再通过多播协议来进行节点间的通信,同时也支持点对点的交互
- Scripting[Elasticsearch脚本执行功能]:Scripting 是脚本执行功能,有这个功能能很方便对查询出来的数据进行加工处理
- Plugins[Elasticsearch插件机制]:Elasticsearch整合第三方的插件的主要实现拓展和整合等,譬如elasticsearch-ik分词插件、elasticsearch-sql sql插件。
- Transport[Elasticsearch传输机制]: 传输模块支持 Thrift, Memcached , HTTP,默认使用 HTTP 传输
- JMX[Elasticsearch基于Java的管理框架]:Java 的管理框架,用来管理 Elasticsearch 应用
- RSTful Style API [Elasticsearch的API支持模式]:基于Netty实现的网络通信,通过RSTful API 和 Elasticsearch 集群进行交互
6|0数据结构
版权声明:本文为博主原创文章,遵循相关版权协议,如若转载或者分享请附上原文出处链接和链接来源。
__EOF__

本文作者:PivotalCloud
本文链接:https://www.cnblogs.com/mazhilin/p/13737482.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:Copyright © 2018-2021 PivotalCloud Technology Systems Incorporated. All rights reserved.
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
本文链接:https://www.cnblogs.com/mazhilin/p/13737482.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:Copyright © 2018-2021 PivotalCloud Technology Systems Incorporated. All rights reserved.
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
分类:
数据库


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 记一次.NET内存居高不下排查解决与启示