

如何压缩Json格式数据,减少Json数据的体积?【转】
一、背景
最近刚刚做完一个中文汉字笔画排序的功能,链接如下:
其中优化之后,将数据库的内容,序列化成为了json数据,然后通过解析json数据,拿到汉字笔画的相关信息。但是未处理前的json文件,体积较大,有2.13Mb,因此需要压缩才行。
部分数据如下所示:
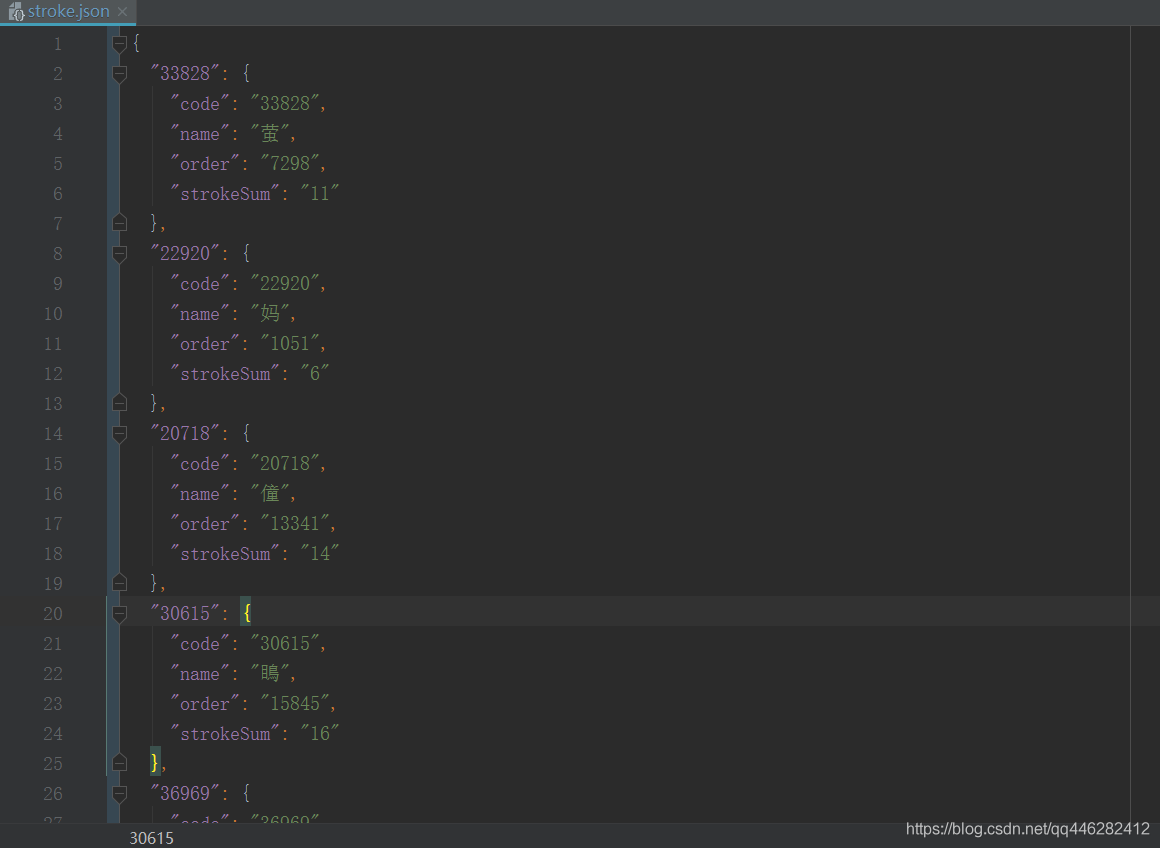
{
"33828": {
"code": "33828",
"name": "萤",
"order": "7298",
"strokeSum": "11"
},
"22920": {
"code": "22920",
"name": "妈",
"order": "1051",
"strokeSum": "6"
},
"20718": {
"code": "20718",
"name": "僮",
"order": "13341",
"strokeSum": "14"
},
"30615": {
"code": "30615",
"name": "瞗",
"order": "15845",
"strokeSum": "16"
},
"36969": {
"code": "36969",
"name": "適",
"order": "13506",
"strokeSum": "14"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
二、常规压缩json
2.1 未处理前的json文件
未处理前的json文件,格式好看但是体积较大。
未处理前的json文件,一共占用125414行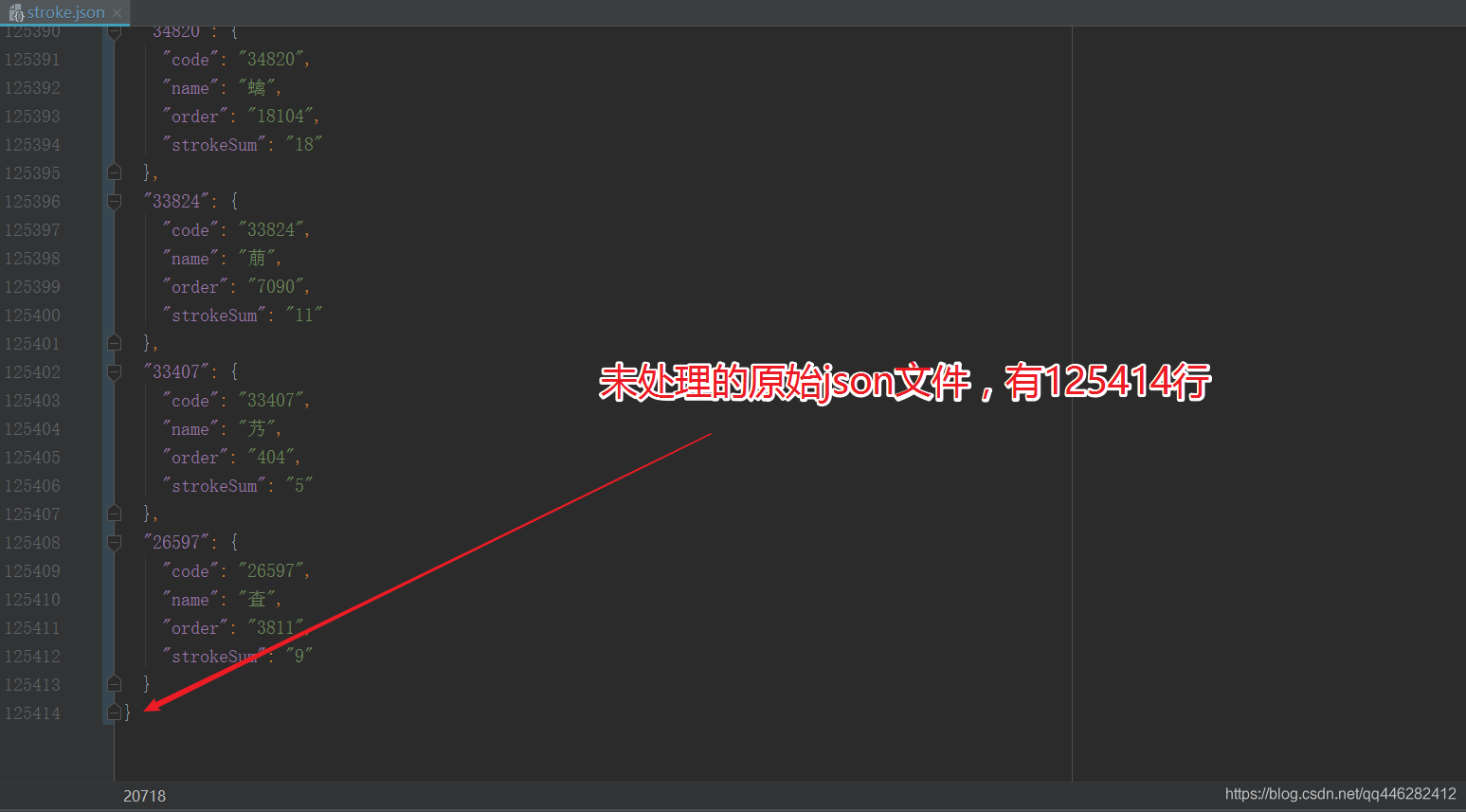
未处理的原始json文件大小为2.13Mb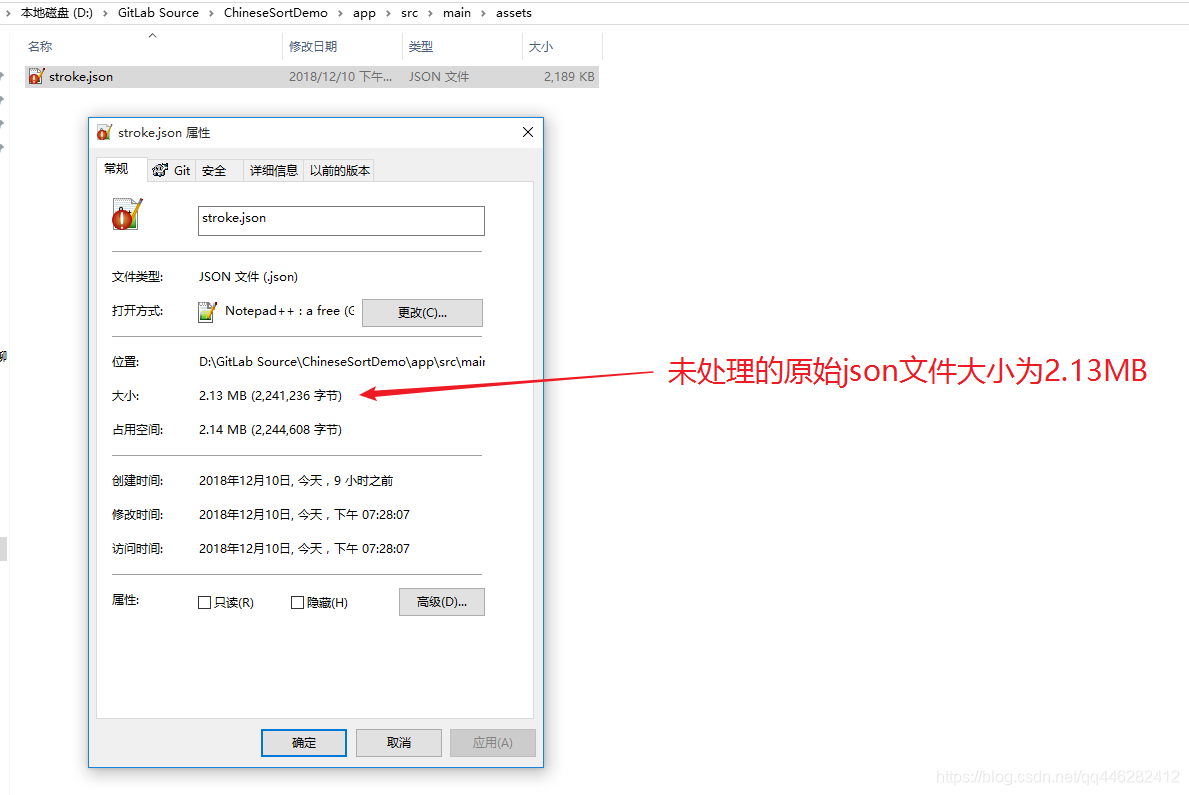
2.2 将JSON压缩成一行,去掉换行和空格字符
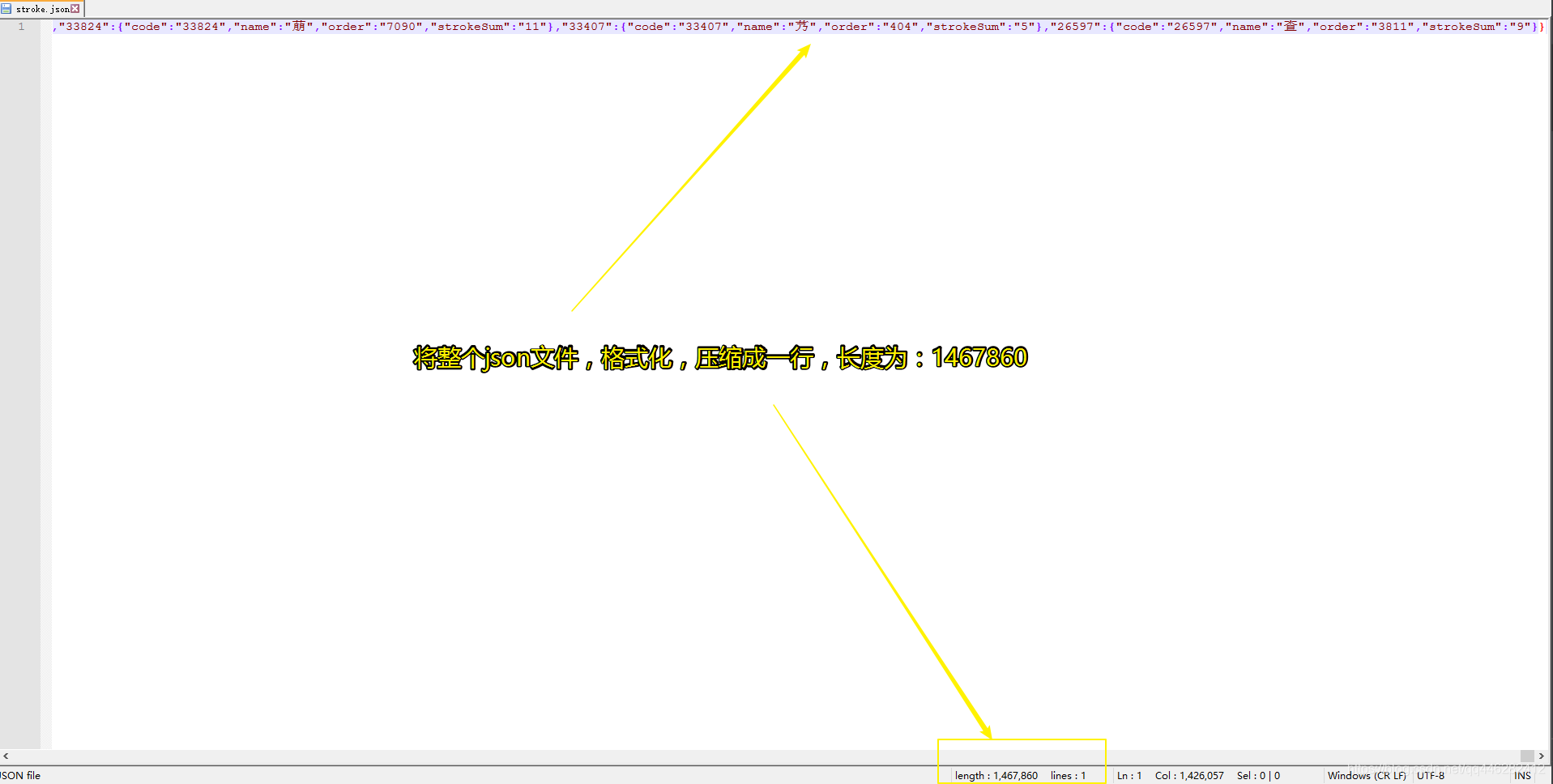
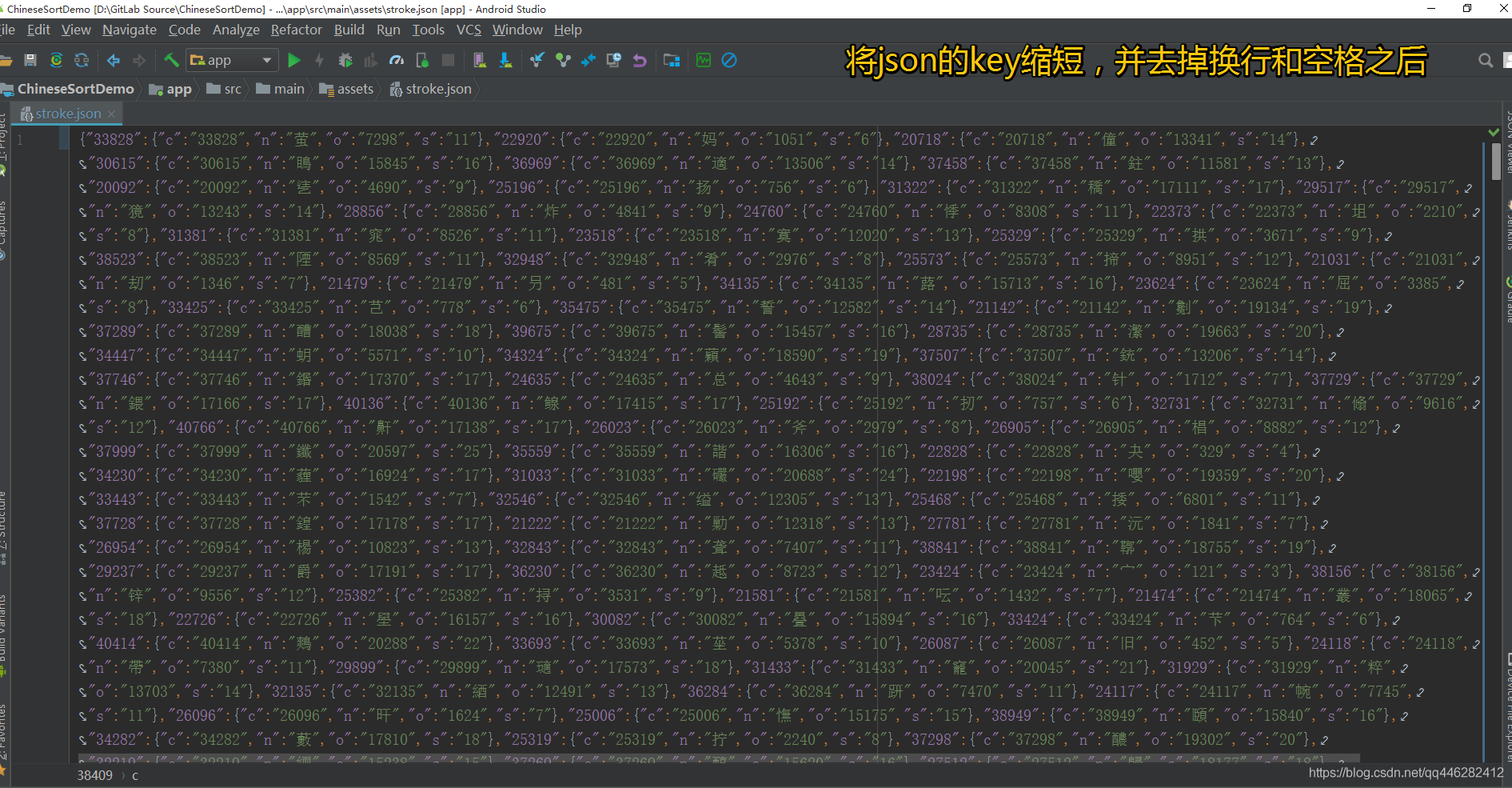
在Android Studio中打开,如下所示:
将JSON压缩成一行,去掉换行和空格字符后的json文件大小为:1.39Mb,只之前的2.13Mb小了整整0.74Mb,这个在移动端是很可观的优化!

2.3 将JSON的key进行缩短
json 是 key-value 结构,如果定义好规范,则可以将 key 尽量缩短,甚至是无意义的字母,但前提是文档一定要写清楚,避免不必要的麻烦。
比如之前的 key-value结构如下所示:
{
"33828": {
"code": "33828",
"name": "萤",
"order": "7298",
"strokeSum": "11"
},
"22920": {
"code": "22920",
"name": "妈",
"order": "1051",
"strokeSum": "6"
},
"20718": {
"code": "20718",
"name": "僮",
"order": "13341",
"strokeSum": "14"
},
"30615": {
"code": "30615",
"name": "瞗",
"order": "15845",
"strokeSum": "16"
},
"36969": {
"code": "36969",
"name": "適",
"order": "13506",
"strokeSum": "14"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
现在我们将key进行优化,使用
c 代替 code
n 代替 name
o 代替 order
s 代替 strokeSum

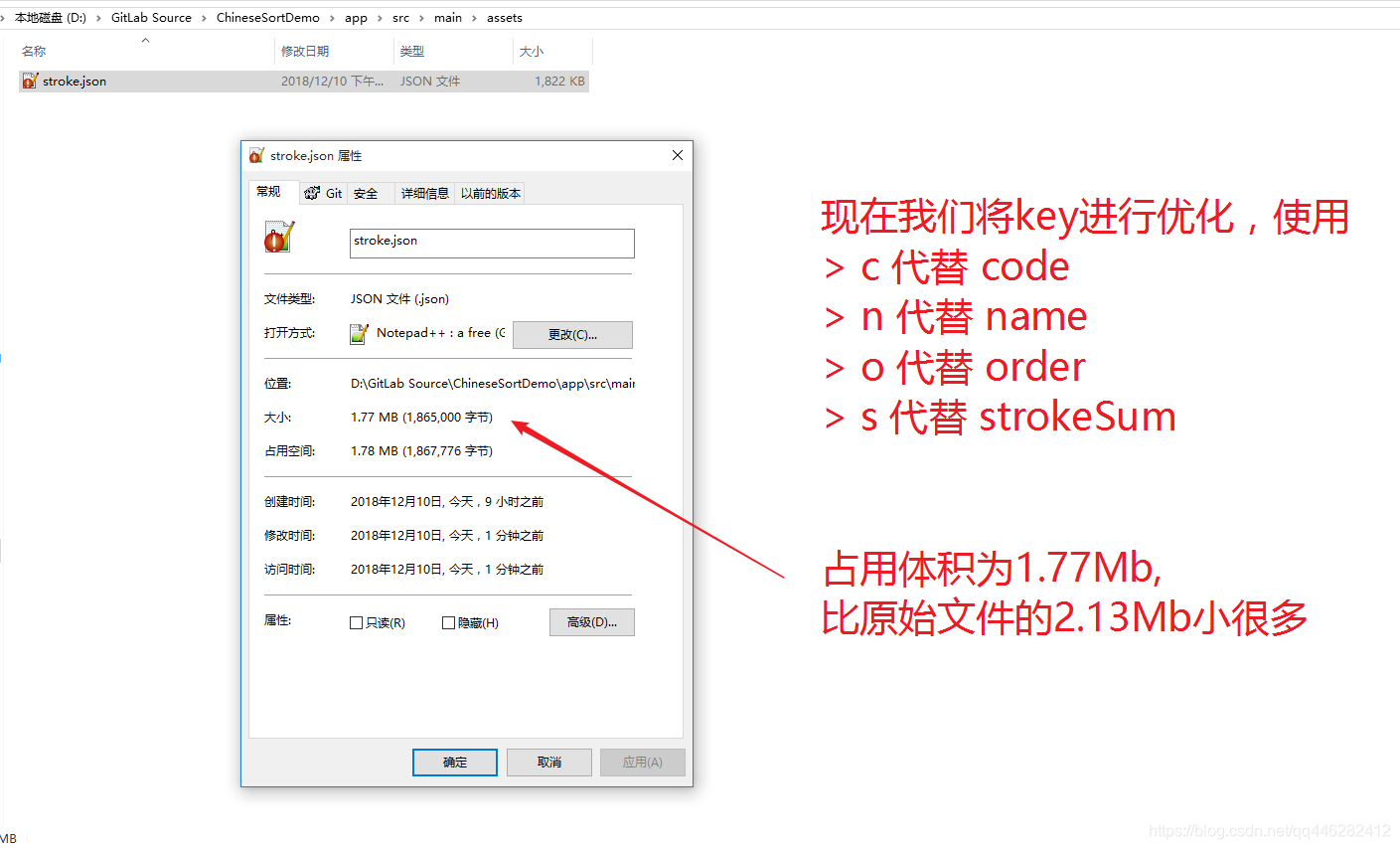
将JSON的key进行缩短优化后的json文件大小为:1.77Mb,只之前的2.13Mb小了整整0.36Mb,这个在移动端是很可观的优化!
然后再将缩短key之后的文件,重复【2.2 将JSON压缩成一行,去掉换行和空格字符】的操作。
再看一看文件大小为1.04Mb,比最开始的原始数据2.13Mb小了整整1.09Mb,这个在移动端是很可观的优化!

当然这样key的名字变化了,对应解析Json的java实体bean也要修改一下。
因为我使用的是jackson来进行json解析的,所以使用注解@JsonProperty来表示一下修改的json文件对应原来的java bean里面的属性,这样解析的时候就不会出错了。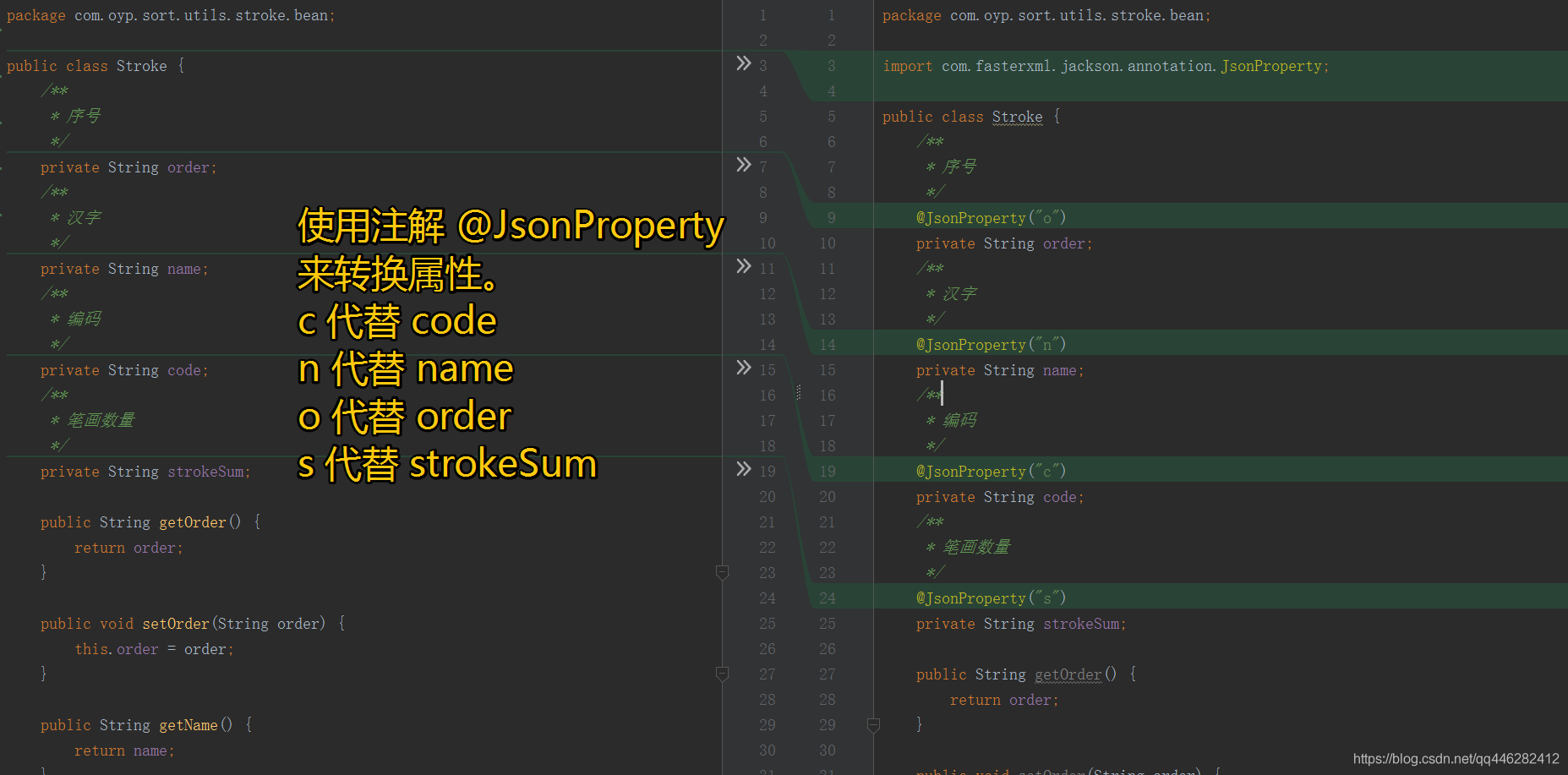
2.4 常规总结
经过上面的常规操作,
我们的json文件大小减少到了1.04Mb,
比最开始的原始数据2.13Mb,
小了整整1.09Mb,
压缩率为51.174%,压缩后体积为原来的48.826%
已经算很给力了,但是这个json文件还是有1.04Mb啊,是否还可以进行压缩呢?答案是肯定的,我们下面介绍下使用算法对该json文件进行压缩。
三、使用压缩算法进行压缩
3.1 使用Deflater压缩json,Inflater解压json
Deflater 是同时使用了LZ77算法与哈夫曼编码的一个无损数据压缩算法。
我们可以使用 java 提供的 Deflater 和 Inflater 类对 json 进行压缩和解压缩,下面是工具类
package com.oyp.sort.utils;
- 1
import android.support.annotation.Nullable;
import android.util.Base64;
import java.io.ByteArrayOutputStream;
import java.util.zip.DataFormatException;
import java.util.zip.Deflater;
import java.util.zip.Inflater;
/**
-
DeflaterUtils 压缩字符串
/
public class DeflaterUtils {
/*-
压缩
/
public static String zipString(String unzipString) {
/*-
https://www.yiibai.com/javazip/javazip_deflater.html#article-start- 1
-
0 ~ 9 压缩等级 低到高- 1
-
public static final int BEST_COMPRESSION = 9; 最佳压缩的压缩级别。- 1
-
public static final int BEST_SPEED = 1; 压缩级别最快的压缩。- 1
-
public static final int DEFAULT_COMPRESSION = -1; 默认压缩级别。- 1
-
public static final int DEFAULT_STRATEGY = 0; 默认压缩策略。- 1
-
public static final int DEFLATED = 8; 压缩算法的压缩方法(目前唯一支持的压缩方法)。- 1
-
public static final int FILTERED = 1; 压缩策略最适用于大部分数值较小且数据分布随机分布的数据。- 1
-
public static final int FULL_FLUSH = 3; 压缩刷新模式,用于清除所有待处理的输出并重置拆卸器。- 1
-
public static final int HUFFMAN_ONLY = 2; 仅用于霍夫曼编码的压缩策略。- 1
-
public static final int NO_COMPRESSION = 0; 不压缩的压缩级别。- 1
-
public static final int NO_FLUSH = 0; 用于实现最佳压缩结果的压缩刷新模式。- 1
-
public static final int SYNC_FLUSH = 2; 用于清除所有未决输出的压缩刷新模式; 可能会降低某些压缩算法的压缩率。- 1
*/
//使用指定的压缩级别创建一个新的压缩器。
Deflater deflater = new Deflater(Deflater.BEST_COMPRESSION);
//设置压缩输入数据。
deflater.setInput(unzipString.getBytes());
//当被调用时,表示压缩应该以输入缓冲区的当前内容结束。
deflater.finish();final byte[] bytes = new byte[256];
ByteArrayOutputStream outputStream = new ByteArrayOutputStream(256);while (!deflater.finished()) {
//压缩输入数据并用压缩数据填充指定的缓冲区。
int length = deflater.deflate(bytes);
outputStream.write(bytes, 0, length);
}
//关闭压缩器并丢弃任何未处理的输入。
deflater.end();
return Base64.encodeToString(outputStream.toByteArray(), Base64.NO_PADDING);
} -
/**
-
解压缩
*/
@Nullable
public static String unzipString(String zipString) {
byte[] decode = Base64.decode(zipString, Base64.NO_PADDING);
//创建一个新的解压缩器 https://www.yiibai.com/javazip/javazip_inflater.html
Inflater inflater = new Inflater();
//设置解压缩的输入数据。
inflater.setInput(decode);final byte[] bytes = new byte[256];
ByteArrayOutputStream outputStream = new ByteArrayOutputStream(256);
try {
//finished() 如果已到达压缩数据流的末尾,则返回true。
while (!inflater.finished()) {
//将字节解压缩到指定的缓冲区中。
int length = inflater.inflate(bytes);
outputStream.write(bytes, 0, length);
}
} catch (DataFormatException e) {
e.printStackTrace();
return null;
} finally {
//关闭解压缩器并丢弃任何未处理的输入。
inflater.end();
}return outputStream.toString();
}
}
-
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
3.1.1 压缩原始的stroke.json数据
然后我们先将原始的stroke.json数据压缩成deFlaterStrokeJson.json。

//原始文件 stroke.json
String strokeJson = LocalFileUtils.getStringFormAsset(context, "stroke.json");
mapper = JSONUtil.toCollection(strokeJson, HashMap.class, String.class, Stroke.class);
// 使用 Deflater 加密
String deFlaterStrokeJson = DeflaterUtils.zipString(strokeJson);
writeFile(deFlaterStrokeJson,"deFlaterStrokeJson.json");
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
其中 writeFile方法是写入到sdcard的方法。
private static void writeFile(String mapperJson, String fileName) {
Writer write = null;
try {
File file = new File(Environment.getExternalStorageDirectory(), fileName);
Log.d(TAG, "file.exists():" + file.exists() + " file.getAbsolutePath():" + file.getAbsolutePath());
// 如果父目录不存在,创建父目录
if (!file.getParentFile().exists()) {
file.getParentFile().mkdirs();
}
// 如果已存在,删除旧文件
if (file.exists()) {
file.delete();
}
file.createNewFile();
// 将格式化后的字符串写入文件
write = new OutputStreamWriter(new FileOutputStream(file), "UTF-8");
write.write(mapperJson);
write.flush();
write.close();
} catch (Exception e) {
Log.e(TAG, "e = " + Log.getStackTraceString(e));
}finally {
if (write != null){
try {
write.close();
} catch (IOException e) {
Log.e(TAG, "e = " + Log.getStackTraceString(e));
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
运行完毕之后,将sdcard中的deFlaterStrokeJson.json导出来,放到assets目录下,以备后续解析使用。
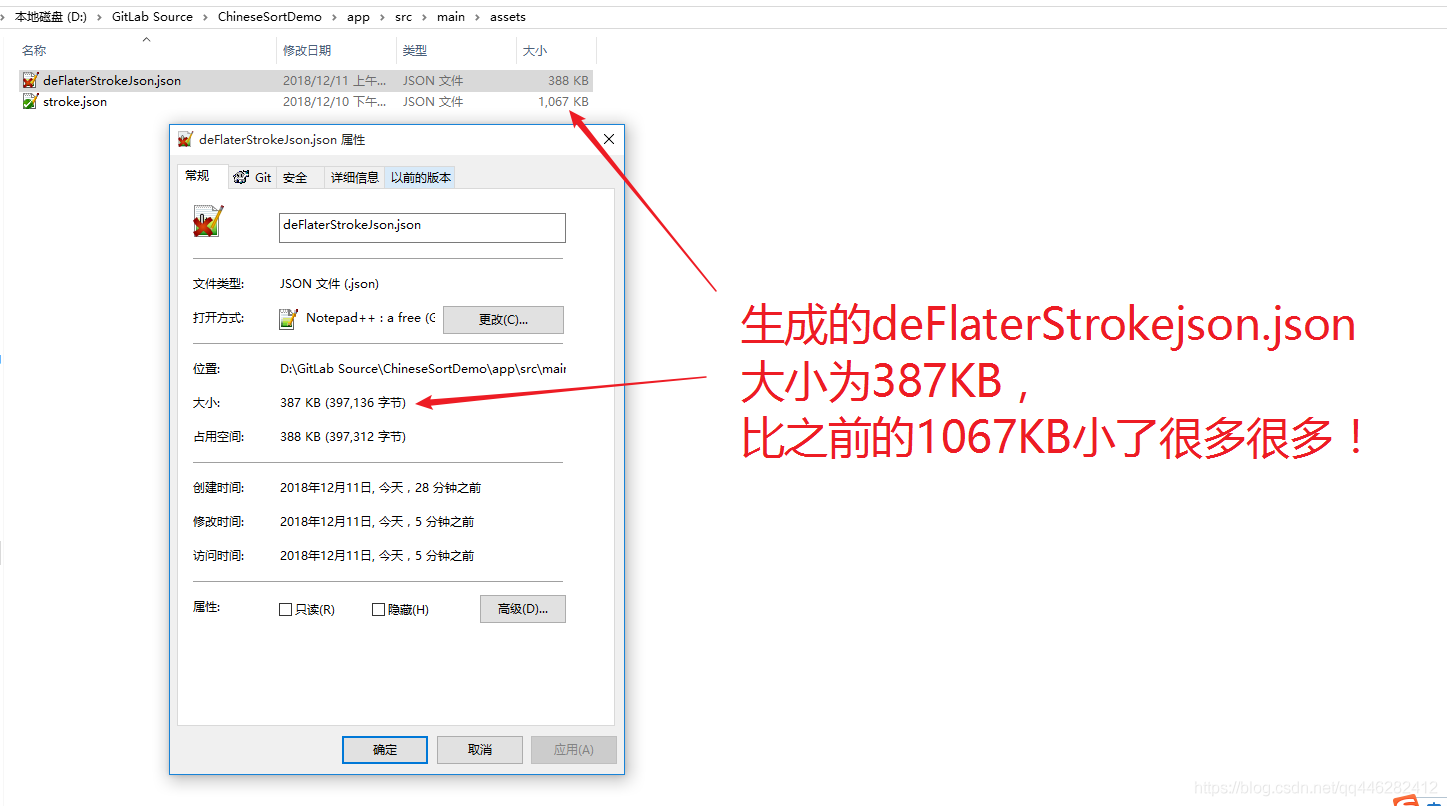
使用Deflater压缩json,压缩后大小为 387KB,比上一次的1067KB,又少了很多很多。
经过Deflater压缩和Base64编码之后的deFlaterStrokeJson.json文件,如下所示:
3.1.2 还原成原始的stroke.json数据
关压缩还不行,我们得使用压缩后的json文件数据啊,因此我们还需要将压缩后的json数据进行解压,操作如下所示:

//使用 Inflater 解密
String deFlaterStrokeJson = LocalFileUtils.getStringFormAsset(context, "deFlaterStrokeJson.json");
String strokeJson = DeflaterUtils.unzipString(deFlaterStrokeJson);
mapper = JSONUtil.toCollection(strokeJson, HashMap.class, String.class, Stroke.class);
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
解压之后运行一切正常!完美!
3.1.3 Deflater压缩总结
经过上面的常规操作,
我们的json文件大小减少到了387KB,
比刚才未使用压缩算法的原始数据1067KB,
小了整整680KB,
压缩率为63.73%,压缩后体积为原来的36.27%
| 优化步骤 | 体积 |
|---|---|
| 1.未处理的原始json | 2.13MB |
| 2.将JSON压缩成一行,去掉换行和空格字符 | 1.39MB |
| 3.将JSON的key进行缩短 | 1.04MB |
| 4.使用Deflater压缩json,Base64编码 | 0.38MB |


3.2 使用Gzip压缩解压json
在我封装的http库里面,有对请求json数据进行Gzip压缩,对服务器返回的json数据进行Gzip解压。这里也来试一下Gzip压缩json。
编写一个 Gzip压缩解压并使用Base64进行编码工具类
package com.oyp.sort.utils;
- 1
import android.text.TextUtils;
import android.util.Base64;
import android.util.Log;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.nio.charset.Charset;
import java.util.zip.GZIPInputStream;
import java.util.zip.GZIPOutputStream;
/**
-
Gzip压缩解压并使用Base64进行编码工具类
/
public class GzipUtil {
private static final String TAG = “GzipUtil”;
/*- 将字符串进行gzip压缩
- @param data
- @param encoding
- @return
*/
public static String compress(String data, String encoding) {
if (data null || data.length() 0) {
return null;
}
ByteArrayOutputStream out = new ByteArrayOutputStream();
GZIPOutputStream gzip;
try {
gzip = new GZIPOutputStream(out);
gzip.write(data.getBytes(encoding));
gzip.close();
} catch (IOException e) {
e.printStackTrace();
}
return Base64.encodeToString(out.toByteArray(), Base64.NO_PADDING);
}
public static String uncompress(String data, String encoding) {
if (TextUtils.isEmpty(data)) {
return null;
}
byte[] decode = Base64.decode(data, Base64.NO_PADDING);
ByteArrayOutputStream out = new ByteArrayOutputStream();
ByteArrayInputStream in = new ByteArrayInputStream(decode);
GZIPInputStream gzipStream = null;
try {
gzipStream = new GZIPInputStream(in);
byte[] buffer = new byte[256];
int n;
while ((n = gzipStream.read(buffer)) >= 0) {
out.write(buffer, 0, n);
}
} catch (IOException e) {
Log.e(TAG, "e = " + Log.getStackTraceString(e));
} finally {
try {
out.close();
if (gzipStream != null) {
gzipStream.close();
}
} catch (IOException e) {
Log.e(TAG, "e = " + Log.getStackTraceString(e));
}<span class="token punctuation">}</span> <span class="token keyword">return</span> <span class="token keyword">new</span> <span class="token class-name">String</span><span class="token punctuation">(</span>out<span class="token punctuation">.</span><span class="token function">toByteArray</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span> Charset<span class="token punctuation">.</span><span class="token function">forName</span><span class="token punctuation">(</span>encoding<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">;</span>- 1
- 2
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
3.2.1 压缩原始的stroke.json数据
//原始文件 stroke.json
String strokeJson = LocalFileUtils.getStringFormAsset(context, "stroke.json");
mapper = JSONUtil.toCollection(strokeJson, HashMap.class, String.class, Stroke.class);
// 使用 GZIP 压缩
String gzipStrokeJson = GzipUtil.compress(strokeJson,CHARSET_NAME);
writeFile(gzipStrokeJson,"gzipStrokeJson.json");
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
运行完毕之后,将sdcard中的gzipStrokeJson.json导出来,放到assets目录下,以备后续解析使用。
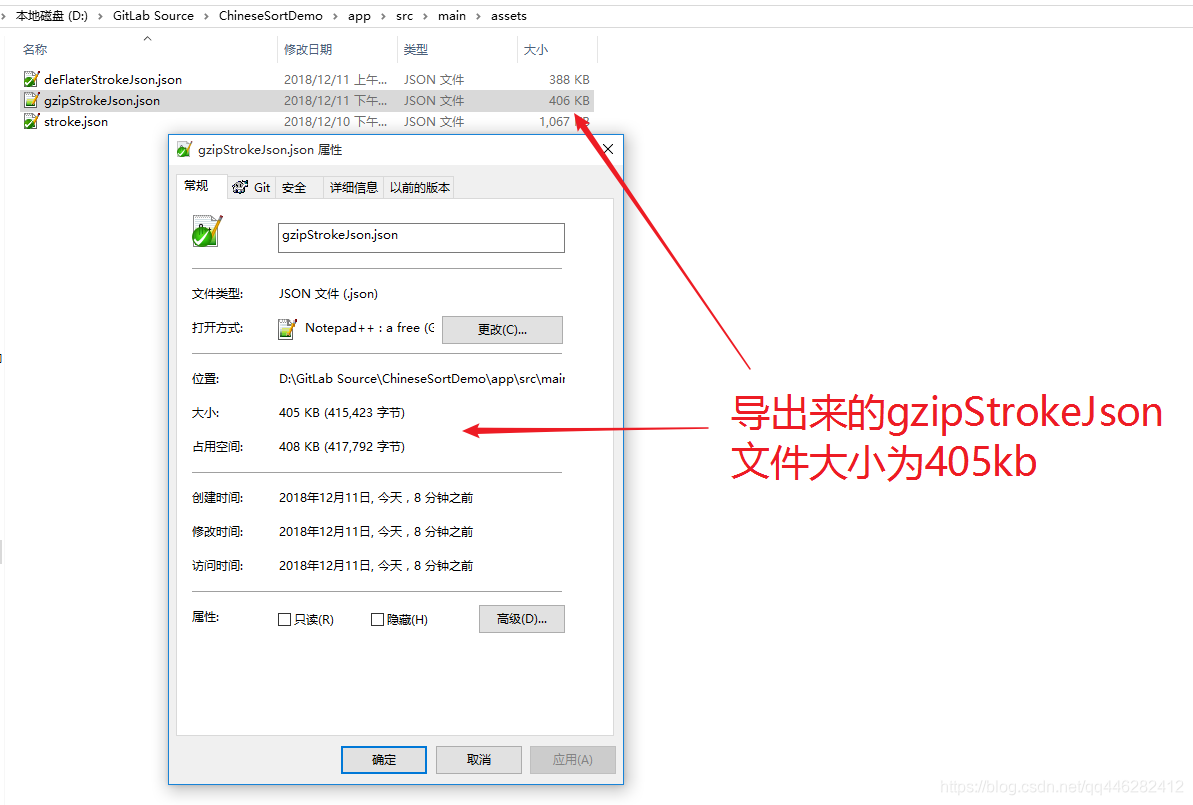
导出来的gzipStrokeJson.json文件为405kb,没有比刚才使用Deflater压缩json后大小为 387KB优秀!
3.2.2 还原成原始的stroke.json数据
关压缩还不行,我们得使用压缩后的json文件数据啊,因此我们还需要将压缩后的json数据进行解压,操作如下所示:

//使用 GZIP 解压
String gzipStrokeJson = LocalFileUtils.getStringFormAsset(context, "gzipStrokeJson.json");
String strokeJson = GzipUtil.uncompress(gzipStrokeJson,CHARSET_NAME);
mapper = JSONUtil.toCollection(strokeJson, HashMap.class, String.class, Stroke.class);
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
解压之后,json解析一切正常!
3.2.3 Gzip压缩总结
经过上面的常规操作,
我们的json文件大小减少到了405kb,
虽然比不上刚才的Deflater压缩:387KB,
但是比刚才未使用压缩算法的原始数据1067KB,
小了整整662KB,
压缩率为62.04%,压缩后体积为原来的37.95%,也是不错的!
四、 其他压缩算法
除了上面的算法之外,我们还可以使用很多其他的压缩算法,进一步压缩json的体积。我们的原始json中还是有很多重复的key值可以进行优化的,下面的算法中有部分可以进行key优化!
https://web-resource-optimization.blogspot.com/2011/06/json-compression-algorithms.html
常见的json压缩算法有CJSON与HPack,其原理都是将key和value进行抽离,节省掉部分的重复的key值造成的空间消耗。
4.1 CJSON
CJSON 的压缩算法, 主要是将资料抽离成 Template 与 Value,节省掉重复的 “Key 值”.
原始JSON:
[{
"x": 100,
"y": 100
},
{
"x": 100,
"y": 100,
"width": 200,
"height": 150
},
{}
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
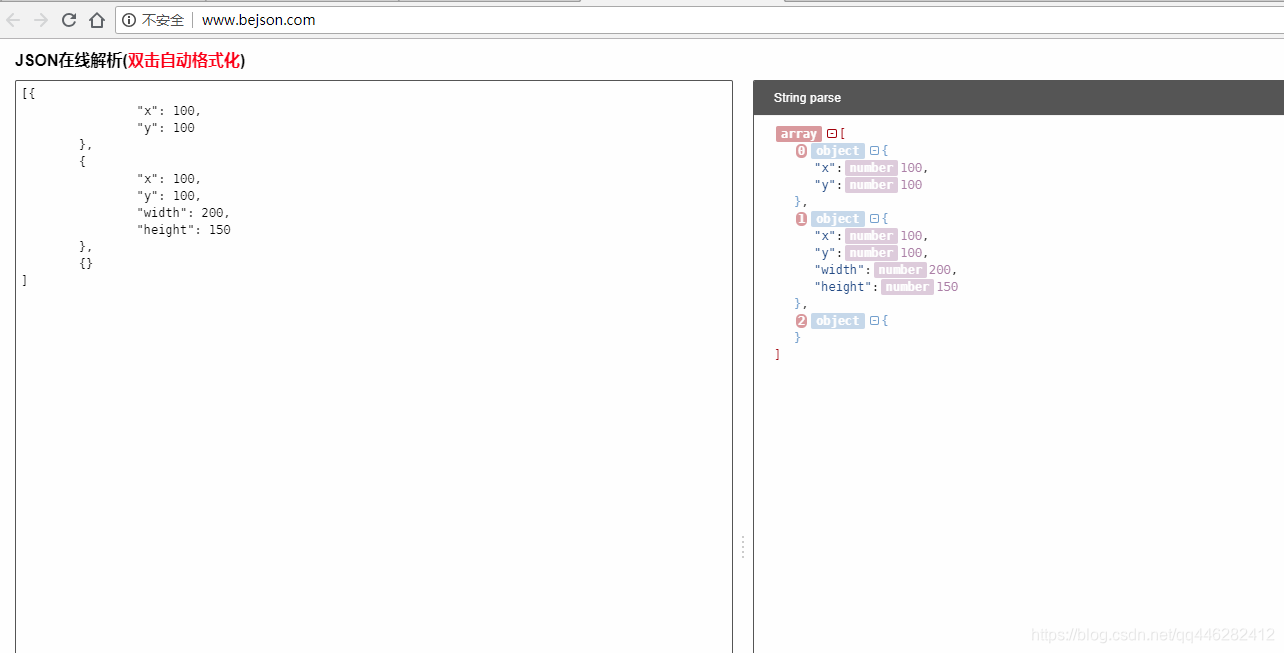
CJSON压缩后:
{
"templates": [
[0, "x", "y"],
[1, "width", "height"]
],
"values": [{
"values": [1, 100, 100]
},
{
"values": [2, 100, 100, 200, 150]
},
{}
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
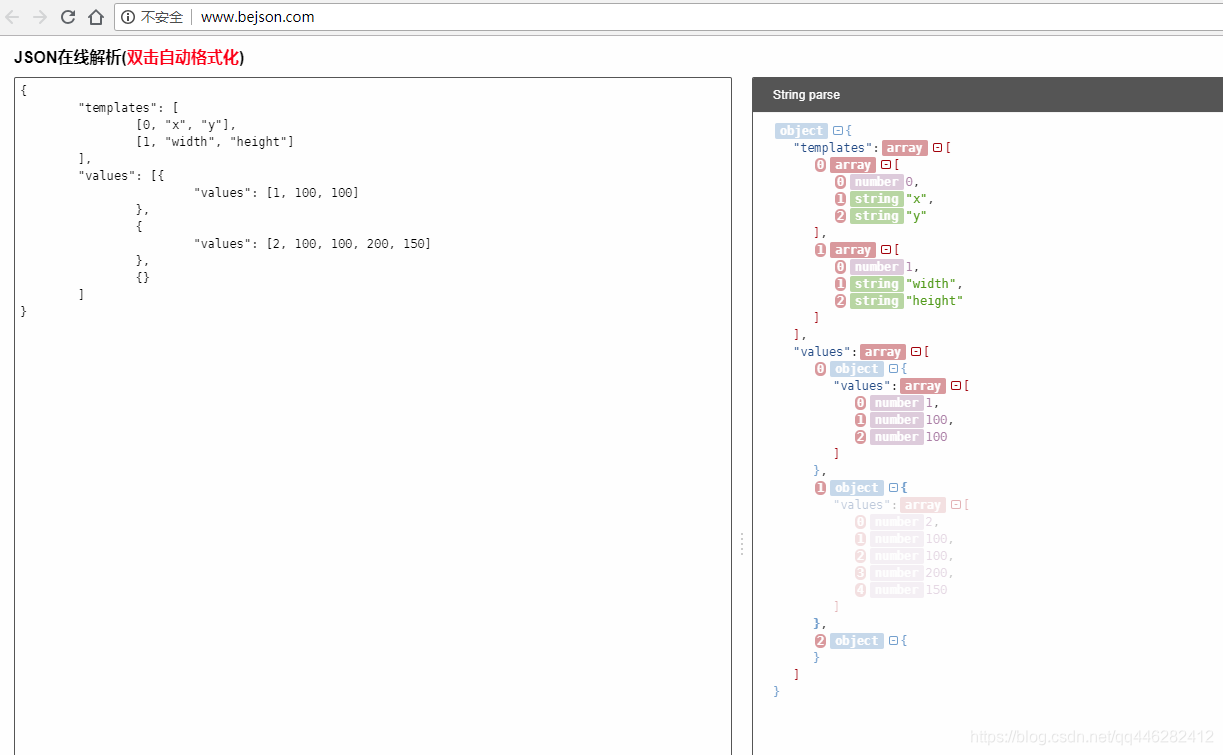
4.2 HPack
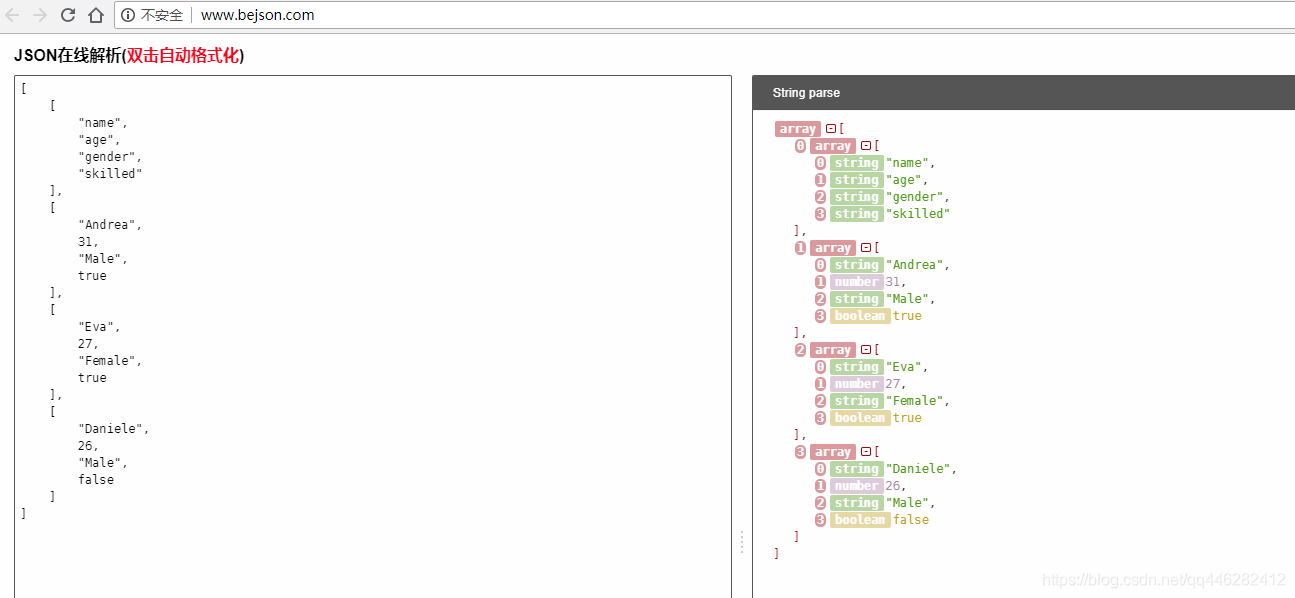
HPack 的压缩算法, 也是将 Key, Value 抽离, 阵列中第一个值, 就是 HPack 的 Template, 后面依序就是 Value.
[
{
"name": "Andrea",
"age": 31,
"gender": "Male",
"skilled": true
},
{
"name": "Eva",
"age": 27,
"gender": "Female",
"skilled": true
},
{
"name": "Daniele",
"age": 26,
"gender": "Male",
"skilled": false
}
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20

压缩之后的数据
[
[
"name",
"age",
"gender",
"skilled"
],
[
"Andrea",
31,
"Male",
true
],
[
"Eva",
27,
"Female",
true
],
[
"Daniele",
26,
"Male",
false
]
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
两种方法都是主要讲json 的 键抽出来统一建成索引,只是最后的格式不同。
HPack 简化后的格式比CJSON 少了许多字符,所以HPack 的压缩效率比较高。数据量越大,效果越明显,应用场景也更加有意义。
如果 JSON 内容太少, CJSON的资料可能反而会比较多。
压缩效果
下图来自:https://www.oschina.net/p/jsonhpack
五、参考资料
-
https://web-resource-optimization.blogspot.com/2011/06/json-compression-algorithms.html
-
该优化的项目源代码:https://github.com/ouyangpeng/ChinesePinyinSortAndStrokeSort/commits/master
https://blog.csdn.net/coolbeliever/article/details/105539398


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· PostgreSQL 和 SQL Server 在统计信息维护中的关键差异
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库
· 上周热点回顾(2.17-2.23)
2017-06-06 30分钟LINQ教程【转】
2017-06-06 Linq之旅:Linq入门详解(Linq to Objects)【转】