
MySQL容器的访问二
1、创建数据库
CREATE DATABASE [IF NOT EXISTS] <数据库名>
drop database 库名;删除数据库
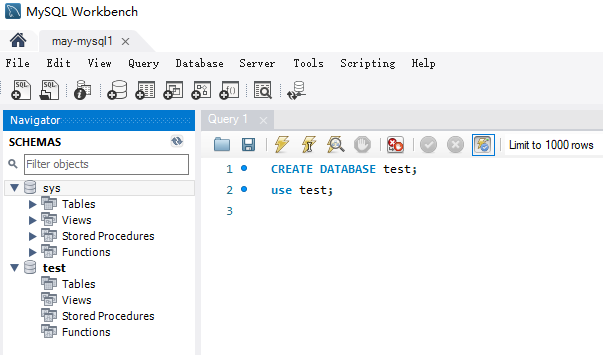
2、数据导出/导入
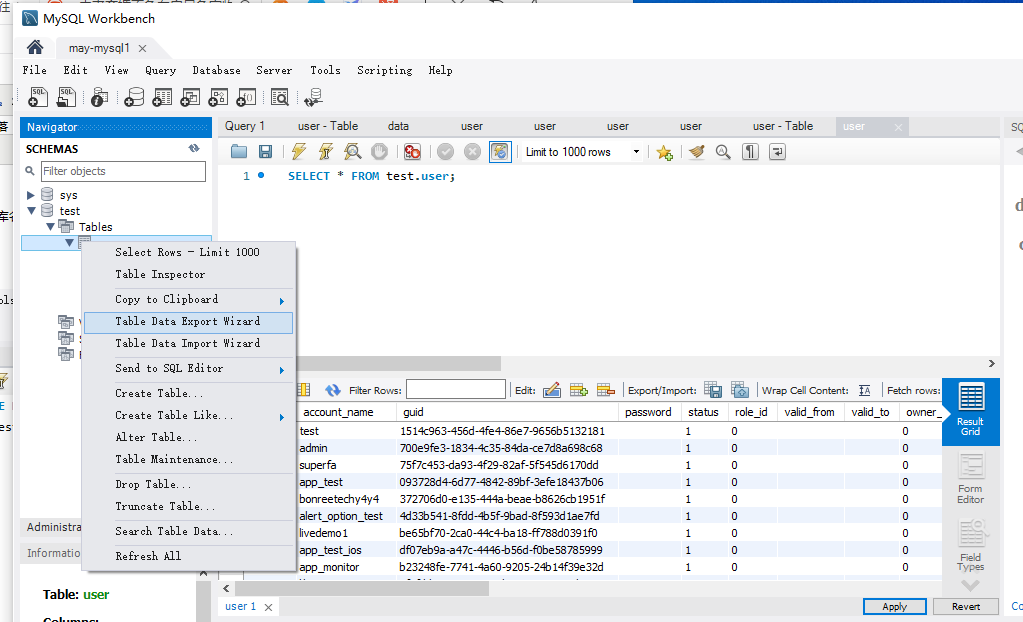
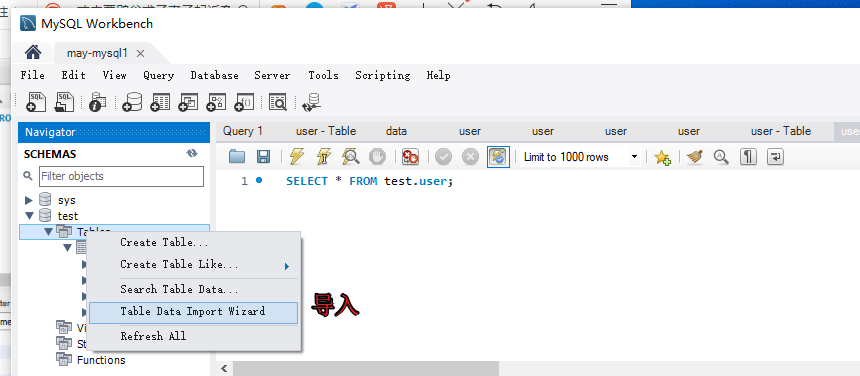
通过工具直接导出/导入
也可以选择导出成一个SQL文件
show variables like '%secure%'; 查看数据库的存储路径。
select * from links into outfile '/tmp/links.csv' ; 文件路径只能选择数据库文件存储路径下

3、数据表相关
查看表:show tables;
查看表结构:show create table 表名; 以SQL语句格式返回
desc 表名; 以表格格式返回
创建表:
CREATE TABLE `test`.`links` (
`id` INT NOT NULL,
`platform_user_id` INT NULL,
`title` VARCHAR(50) NULL,
PRIMARY KEY (`id`),
UNIQUE INDEX `platform_user_id_UNIQUE` (`platform_user_id` ASC) VISIBLE);
删除表:
drop table 表名;
4、查询
SELECT * FROM test.user limit 50;
SELECT * FROM test.user where account_name='test';
SELECT * FROM test.user where account_name='test' and guid='eac7b';
SELECT guid,status,id FROM test.user ;
SELECT guid,status,id FROM test.user where account_name="test";
SELECT * FROM test.user where (id=88772 or account_name='admin') and status=1;
SELECT account_name as name, guid as gid FROM test.user where status=1 ;
SELECT * FROM test.user where id in (88772,88884,175411);
SELECT * FROM test.user where id between 88772 and 88889;
SELECT avg(math) FROM test.students where sex=1 group by sex;
SELECT avg(math) FROM test.students where sex=1 group by sex having avg(math)>50;
(having与where唯一区别是为了区别where:其实是where只能跟着from后,having只能跟着group by后;
having是对一个表的数据进行了分组之后,对“组信息”进行相应 条件筛选。
SELECT * FROM test.students where name like "%tom%";
SELECT * FROM test.students order by english desc;(降序 排序)
SELECT * FROM test.students order by english asc;(升序 排序)
SELect distinct * from test.students ;(查询不重复记录条数)
SELECT * FROM test.students order by english desc,math asc;(以英语的降序排列,如果英语相同,则根据数据的升序排)
SELECT count(id) as 总数 FROM test.students;(查询学生总数)
select * from test.students limit 5 ; (默认是0,从第一条开始显示,显示5条)
select * from test.students limit 2,4; (从第三条开始显示,显示4条)
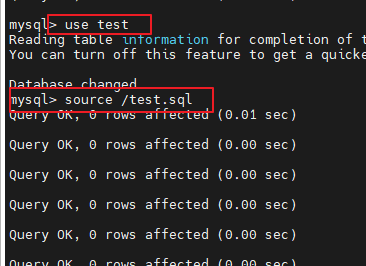
5、数据库备份与还原
备份:未登录状态 mysqldump -u root -p test > /test.sql


还原:还原的时候需要先登录 MySQL,并选中对应的数据库。
删除test数据库中所有表
登录MySQL 选中数据库
source /test.sql ;
6、插入
insert into test.students ( id,name,sex,english,math) values (16,'kk',1,78,90),(17,'dd',2,89,100) ;
修改表字段ID为自增长:
ALTER TABLE `test`.`students`
CHANGE COLUMN `id` `id` INT NOT NULL AUTO_INCREMENT ;
此时不再需要添加ID即可插入数据:
insert into test.students ( name,sex,english,math) values ('kk',1,78,90),('dd',2,89,100) ;
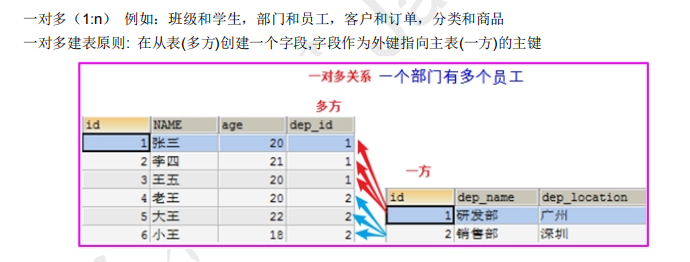
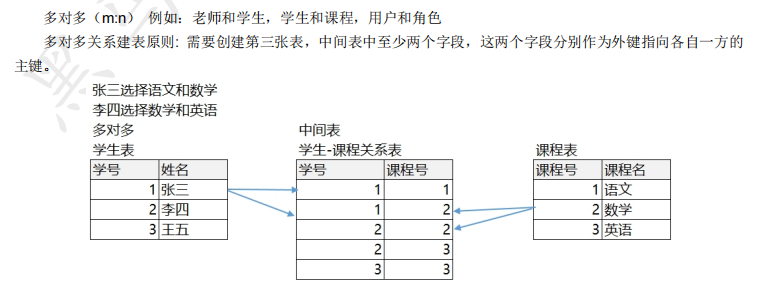
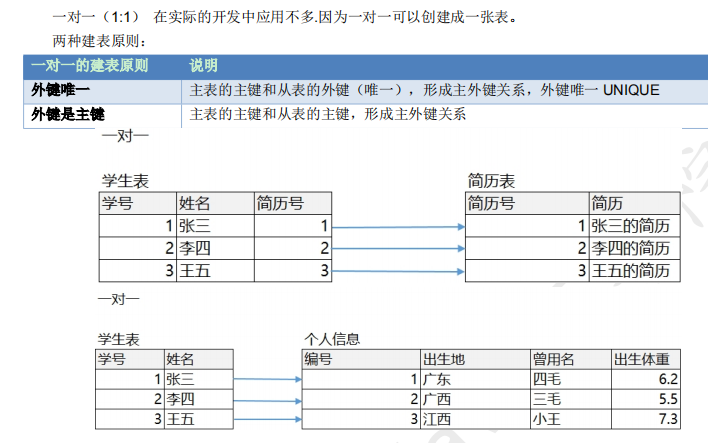
7、多表查询
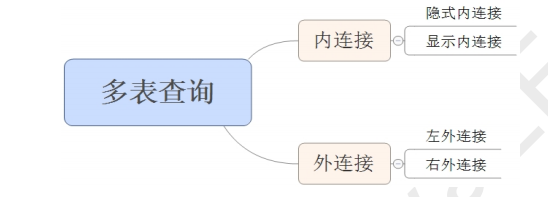
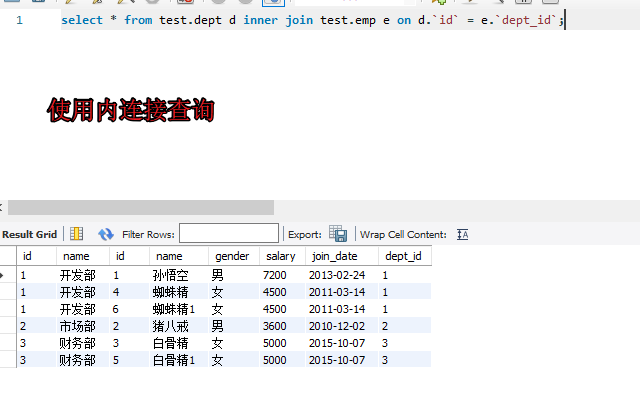
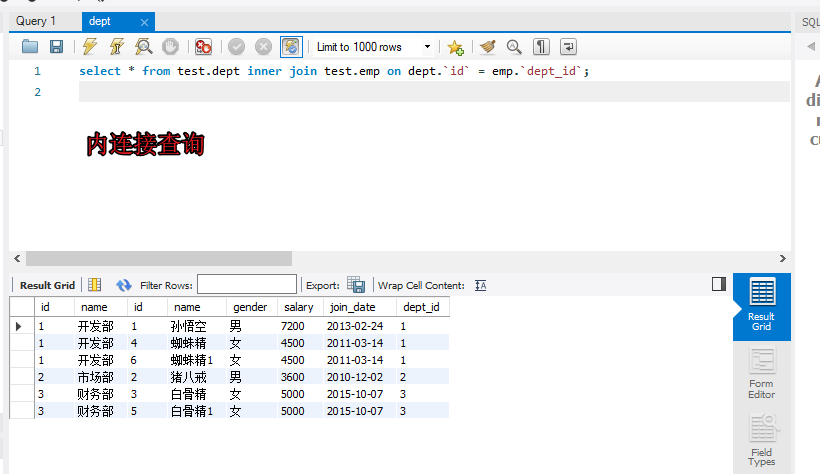
select * from test.emp e inner join test.dept d on e.`dept_id` = d.`id`;
select * from test.emp e inner join test.dept d on e.`dept_id` = d.`id` where e.`name`='孙悟空';
select e.`id`,e.`name`,e.`gender`,e.`salary`,d.`name` from test.emp e inner join test.dept d
on e.`dept_id` = d.`id` where e.`name`='孙悟空';
select e.`id` 编号,e.`name` 姓名,e.`gender` 性别,e.`salary` 工资,d.`name` 部门名字 from
test.emp e inner join test.dept d on e.`dept_id` = d.`id` where e.`name`='孙悟空';
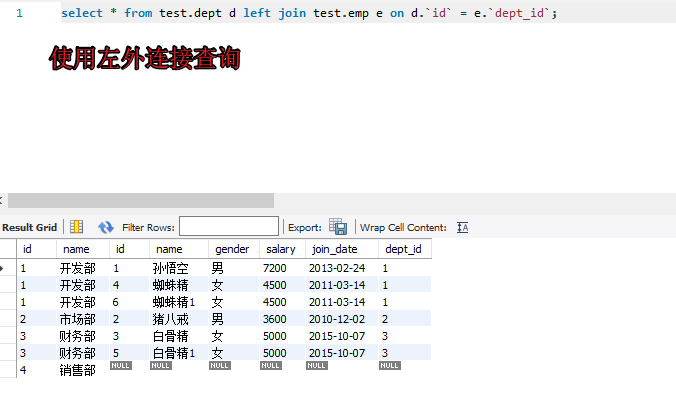
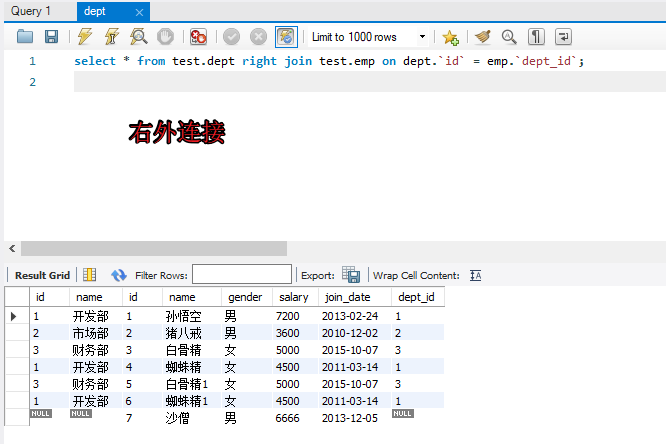
可以理解为:在内连接的基础上保证左表的数据全部显示(左表是部门,右表员工)
8、子查询
select * from test.emp where dept_id = (select id from test.dept where name='市场部');
select * from test.emp where salary < (select avg(salary) from test.emp);
select * from test.dept where id in (select dept_id from test.emp where salary > 5000);
select * from dept d, (select * from emp where join_date >='2011-1-1') e where
9、事务


select @@autocommit;
取消自动提交事务
set @@autocommit = 0;



 浙公网安备 33010602011771号
浙公网安备 33010602011771号