
正则表达式
什么是正则表达式?

用一串特殊字符的组合从一串字符中筛选出满足条件的数据。
如何使用正则表达式
正则表达式是独立的语言,我们需要借助python中re模块使用正则。
字符组
[0123456789] 匹配中括号中任意一个数字,[0-9]可以使用-表示0到9,字母即[a-z] [A-Z],如果要匹配数字和大小字母,那么可以是[0-9a-zA-Z]。
特殊符号
.匹配除换行符以外的任意字符\d匹配数字^匹配字符开头$匹配字符结尾a|b匹配a或者b()匹配括号内表达式也表示一组[^...]匹配除括号内以外的任意字符
量词
表达式在未量词修饰时都是单个匹配,量词只能配合字符和表达式使用,不能单独使用。量词只影响它前面第一个表达式,如ab+,之作用b。
*匹配零次或无数次+匹配一次或无数次?匹配零次或一次{n}匹配n次{n,}匹配n次及以上{m,n}匹配m-n次
ps: 正则表达式中量词默认是贪婪匹配。
贪婪匹配与非贪婪匹配
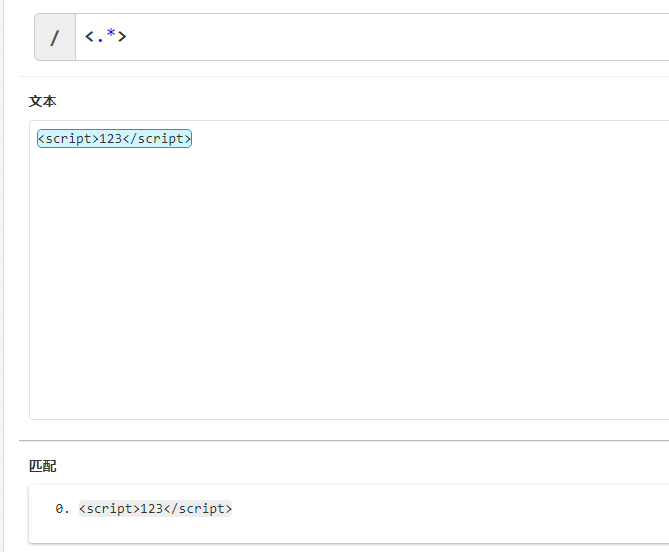
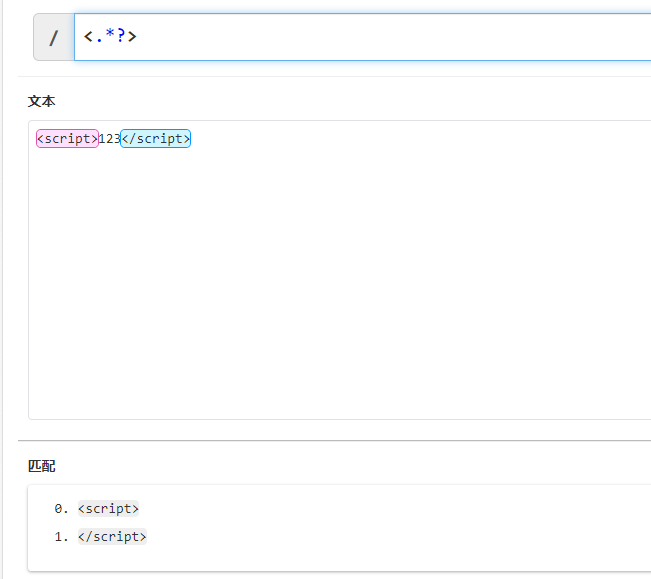
比如我们有一串需要匹配的字符串,<script>123</script>。
<.*>这个表达式会将所有字符都匹配到,默认贪婪匹配会找到最后的>结束。如果我们希望在遇到第一个>就返回匹配的字符,那么需要在量词后面跟?,即<.*?>,这便是非贪婪匹配。如下图,
python内置模块之re
re模块基本方法
import re
# re.findall('正则表达式','待匹配字符') 匹配所有符合条件字符组合成列表
ret = re.findall('a','eva jason')
print(ret) # ['a','a'] 如果未匹配字符返回空列表
# re.search('正则表达式','待匹配字符') 匹配到符合条件的字符直接返回
ret = re.findall('a','eva jason') # 返回结果对象
# 调用结果对象的group方法得到查到的字符
print(ret.group()) # a
# PS:如果未匹配到字符返回None,调用group方法报错
# re.match('正则表达式','待匹配字符') 匹配是否以表达式字符开头
# match与search同样返回对象,调用对象group方法返回字符,未查找到返回None,调用group报错
ret = re.match('a','abc')
print(ret.group()) # a
re模块其他方法
import re
# 先对abcd按a切分为''和'bcd',再按b分别对''和'bcd'切分得到''和'cd'
ret = re.split('[ab]','abcd')
print(res) # ['','','bd']
# sub同str中replace相似,sub匹配符合条件字符替换成第二个参数字符,其中第4个参数可以控制替换次数
ret = re.sub('\d','|','min1xie123xu4')
print(ret) # min|xie|||xu|
# ret = re.sub('\d','|','min1xie123xu4',1)
# print(ret) # min|xie123xu4
# subn同sub类似,返回结果为替换结果和替换次数组成的元组
ret = re.subn('\d','|','min1xie123xu4')
print(ret) # ('min|xie|||xu|', 5)
# 对于频繁使用的正则表达式可以通过compile方法生成正则对象,使用时直接调用,不再需要每次再输一遍正则表达式
# regexp_obj = re.compile('\d+')
# res = regexp_obj.search('absd213j1hjj213jk')
# res1 = regexp_obj.match('123hhkj2h1j3123')
# res2 = regexp_obj.findall('1213k1j2jhj21j3123hh')
# print(res,res1,res2)
# finditer方法匹配字符返回结果对象的迭代器
ret = re.finditer('\d+', 'xie123san56lin89')
print([i.group() for i in ret]) # ['123', '56', '89']
# search分组取值
ret = re.search('^[1-9](\d{14})(\d{2}[0-9x])?$','110105199812067023')
print(ret.group) # 110105199812067023
print(res.group(1)) # 10105199812067
print(res.group(2)) # 023
# 无名分组
ret = re.findall('<<<(\d+)>>>','<<<123>>>')
print(ret) # ['123']
# ?: 取消分组优先展示
ret = re.findall('<<<(?:\d+)>>>','<<<123>>>')
print(ret) # ['<<<123>>>']
# 有名分组
# ?P<组名>
ret = re.search('<(?P<num1>\d{2})(?P<num2>\d)>','<527>')
print(ret) # <_sre.SRE_Match object; span=(0, 5), match='<527>'>
print(ret.group()) # <527>
print(ret.group('num1')) # 52
print(ret.group('num2')) # 7

