结对作业二
git仓库链接和代码规范链接
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 20 |
| • Estimate | • 估计这个任务需要多少时间 | 10 | 20 |
| Development | 开发 | 5010 | 5980 |
| • Discuss | • 结对讨论 | 300 | 240 |
| • Analysis | • 需求分析 | 120 | 120 |
| • Learning | • 学习新技术 | 480 | 800 |
| • Design Spec | • 生成设计文档 | 120 | 60 |
| • Design Review | • 设计复审 | 90 | 60 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 60 | 60 |
| • Design | • 具体设计 | 300 | 40 |
| • Coding | • 具体编码 | 3000 | 4000 |
| • Code Review | • 代码复审 | 120 | 60 |
| • Code Review | • 代码复审 | 120 | 60 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 300 | 480 |
| Reporting | 报告 | 430 | 115 |
| • Test Repor | • 编写文档 | 300 | 300 |
| • Size Measurement | • 计算工作量 | 30 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 100 | 60 |
| 合计 | 5270 | 1100 |
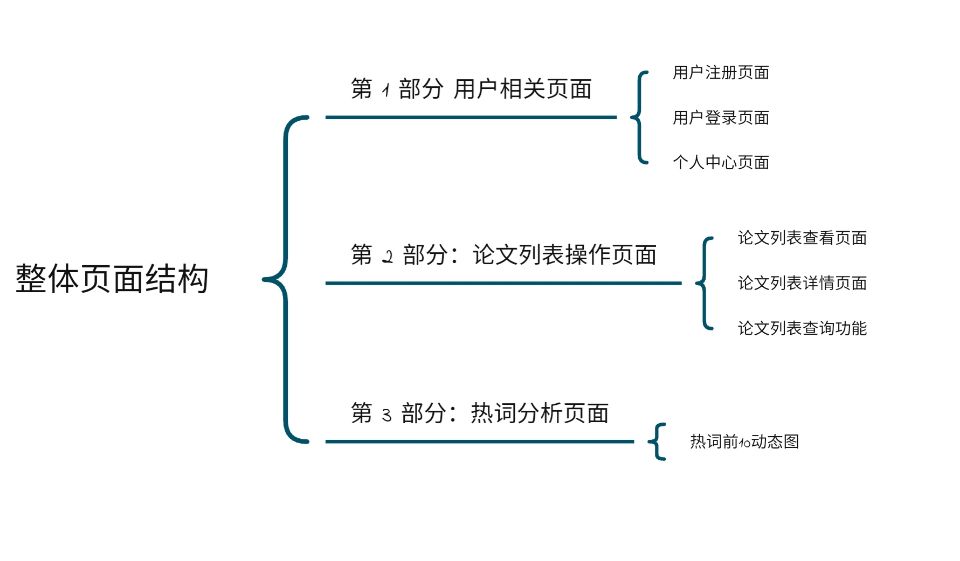
成品展示
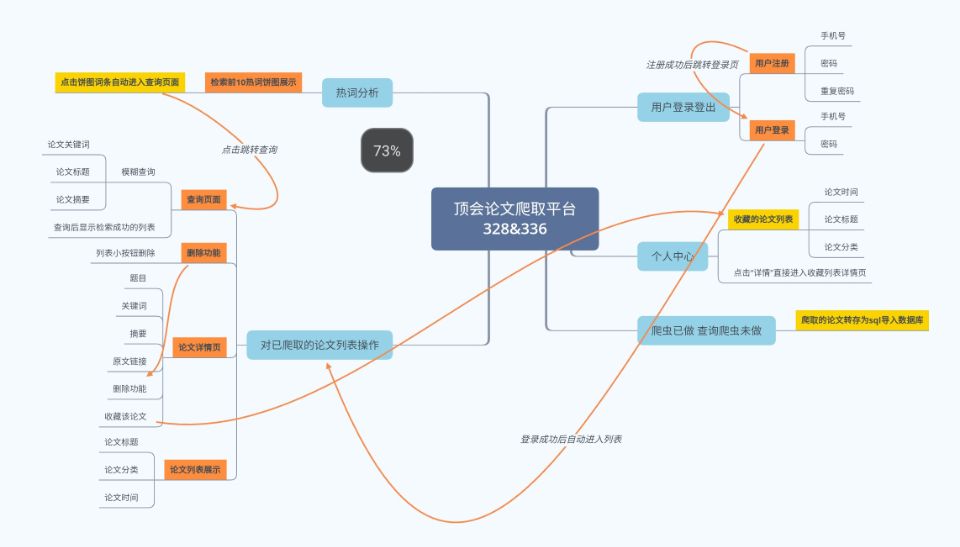
界面结构图

1、用户注册页:
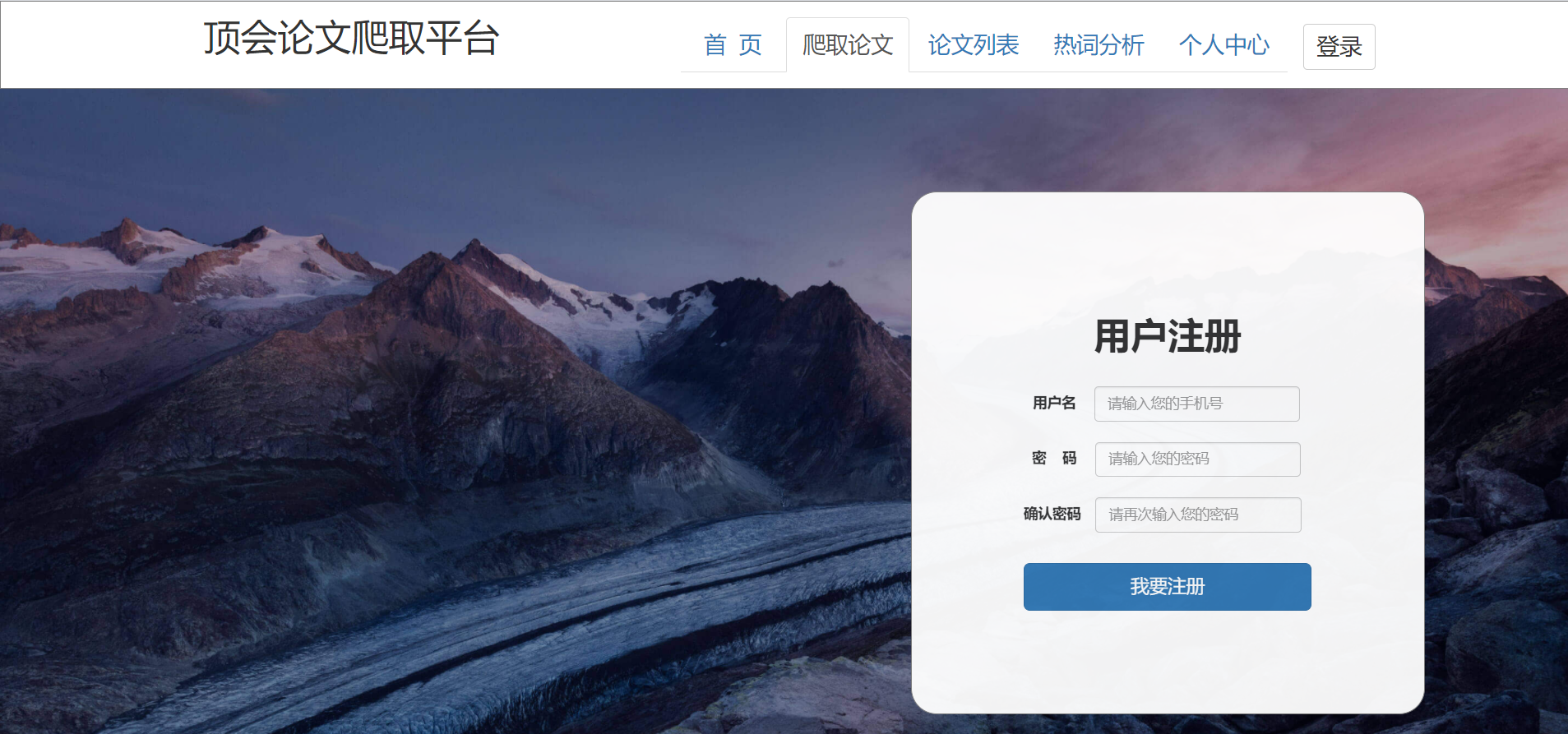
用户输入:输入手机号码、密码、重复密码
前后端交互:前端判定密码以及重复密码是否吻合,后端接收到前端数据将用户数据插入到user表中,并返回status状态码。前端根据返回的状态码判定。
页面展示:注册成功后,页面跳转到用户登录页。
2、用户登录页:
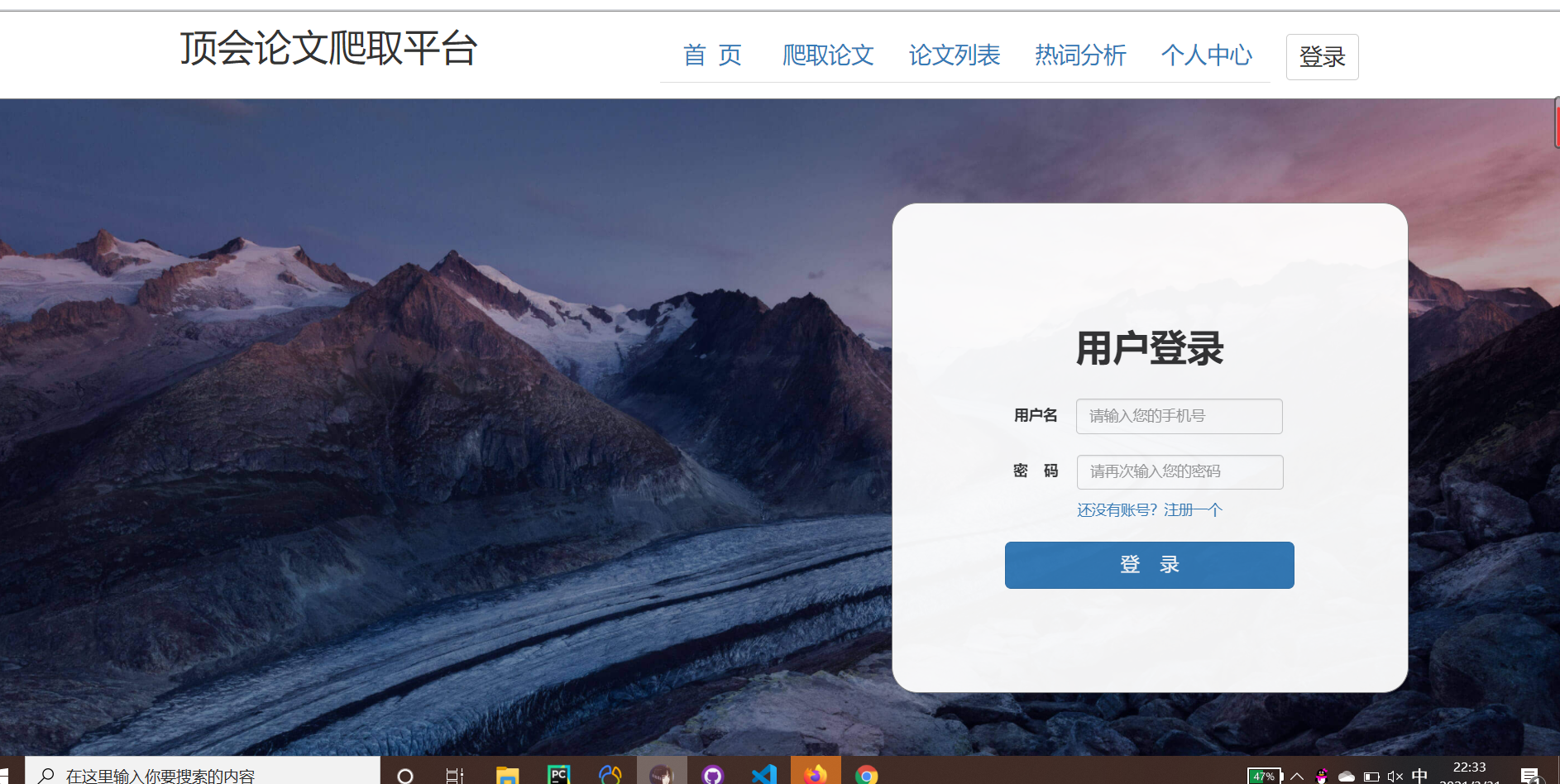
用户输入:输入手机号码、密码
前后端交互:前端将其转变为json传输给后端,后端判断密码是否吻合数据库中的数据,并返回用户id和状态码,传输给前端。
页面展示:登陆成功后,页面跳转到论文列表查看页。
3、论文列表查看页:
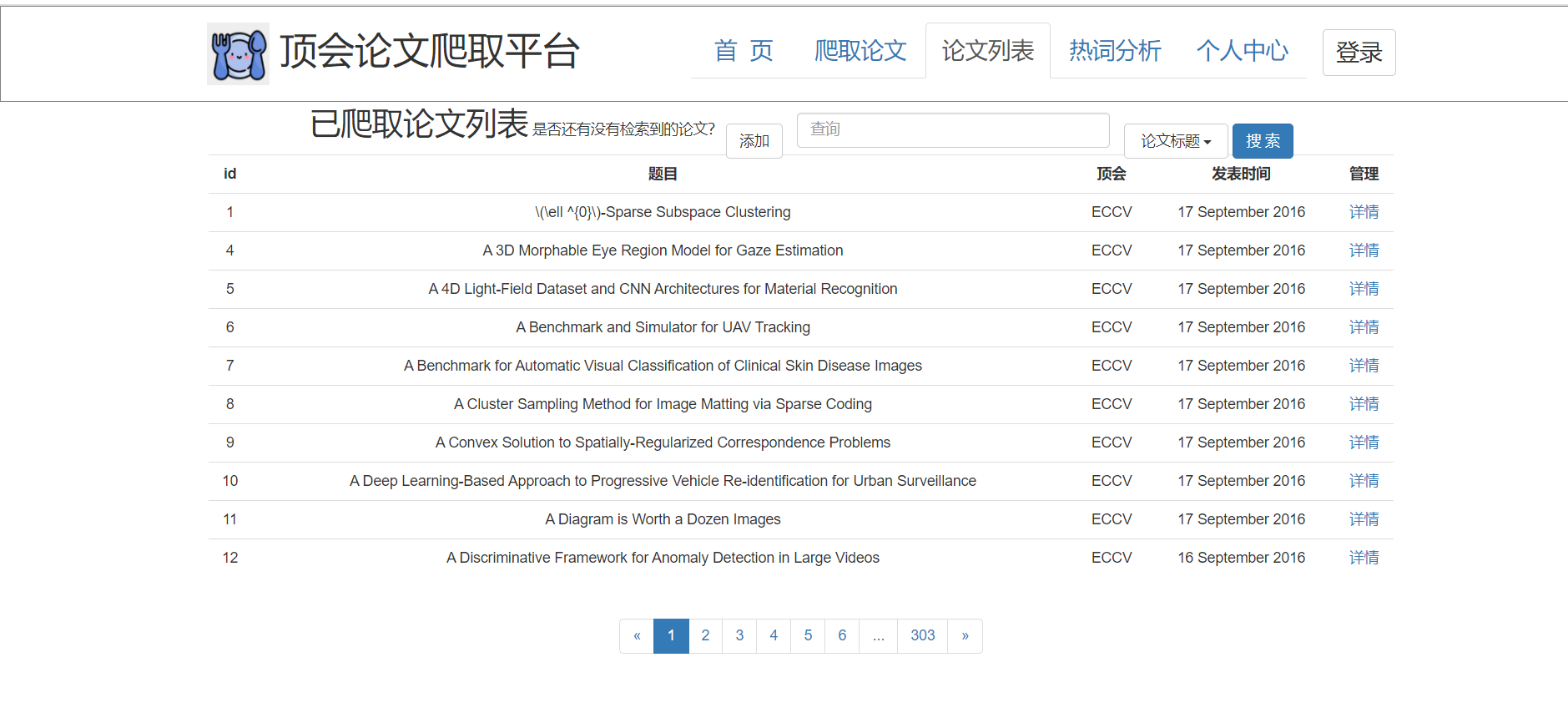
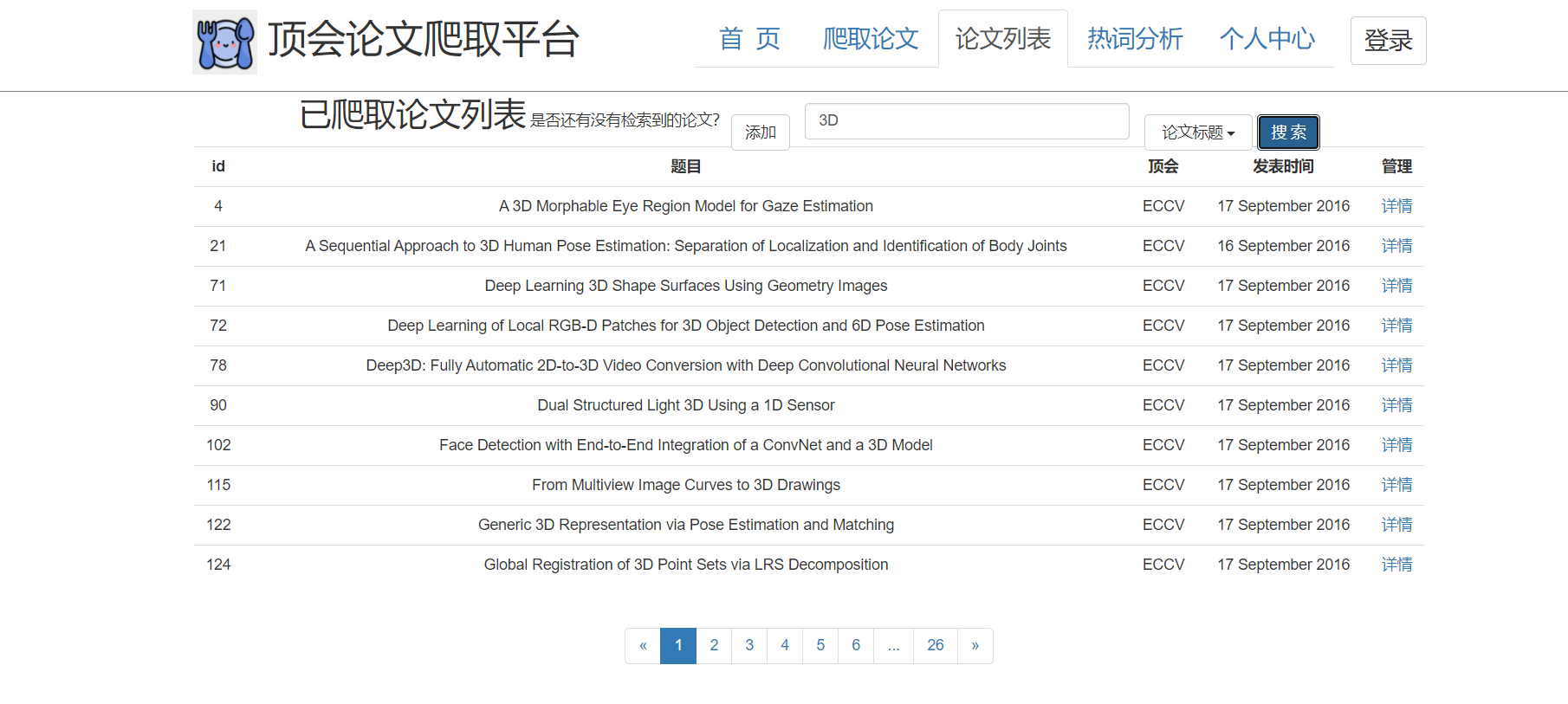
前后端交互:后端返回json数组以及相应的页数、条数返回给前端。点击右上角的查询选择下拉栏,通过选择'标题'、'关键词'、'摘要',进行模糊查询。前端传递字符串给后端,后端检索返回符合条件的json数组。
页面展示:用户可以看到少部分论文信息,包含:论文标题、论文时间、论文分类。点击详情页,自动跳转到论文详情页面。
4、论文详情页:
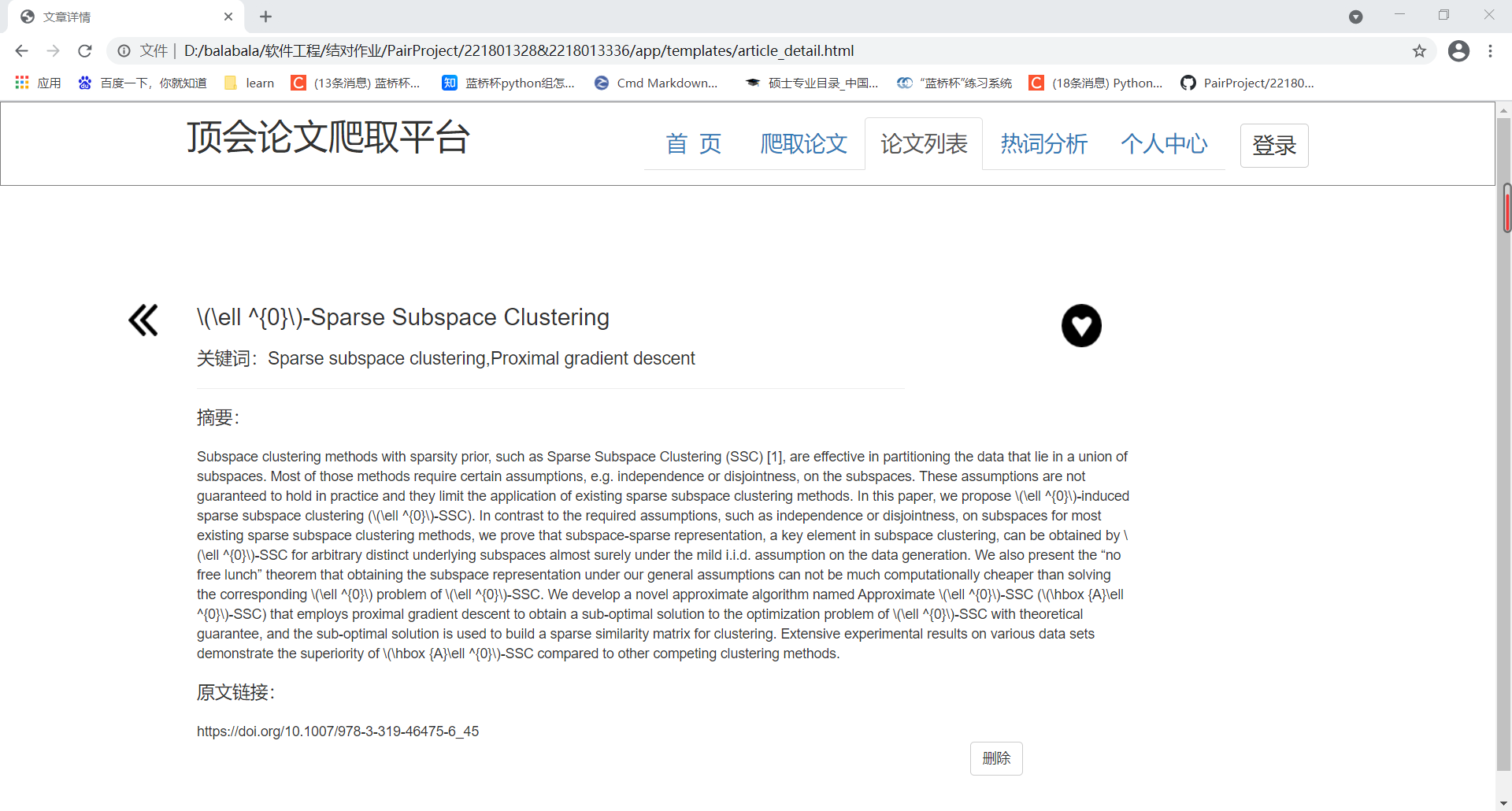
页面展示:在论文详情页中,可以对该篇论文进行删除,点击删除后自动跳转回列表查看页。也可通过左上角"《"返回论文列表查看页。若用户对该篇论文很感兴趣,点击右上角收藏按钮可以收藏该篇论文,在个人中心页可以查看到收藏的论文。
前后端交互:通过论文id标识论文,实现传递论文详情信息和删除论文。
5、个人中心页:
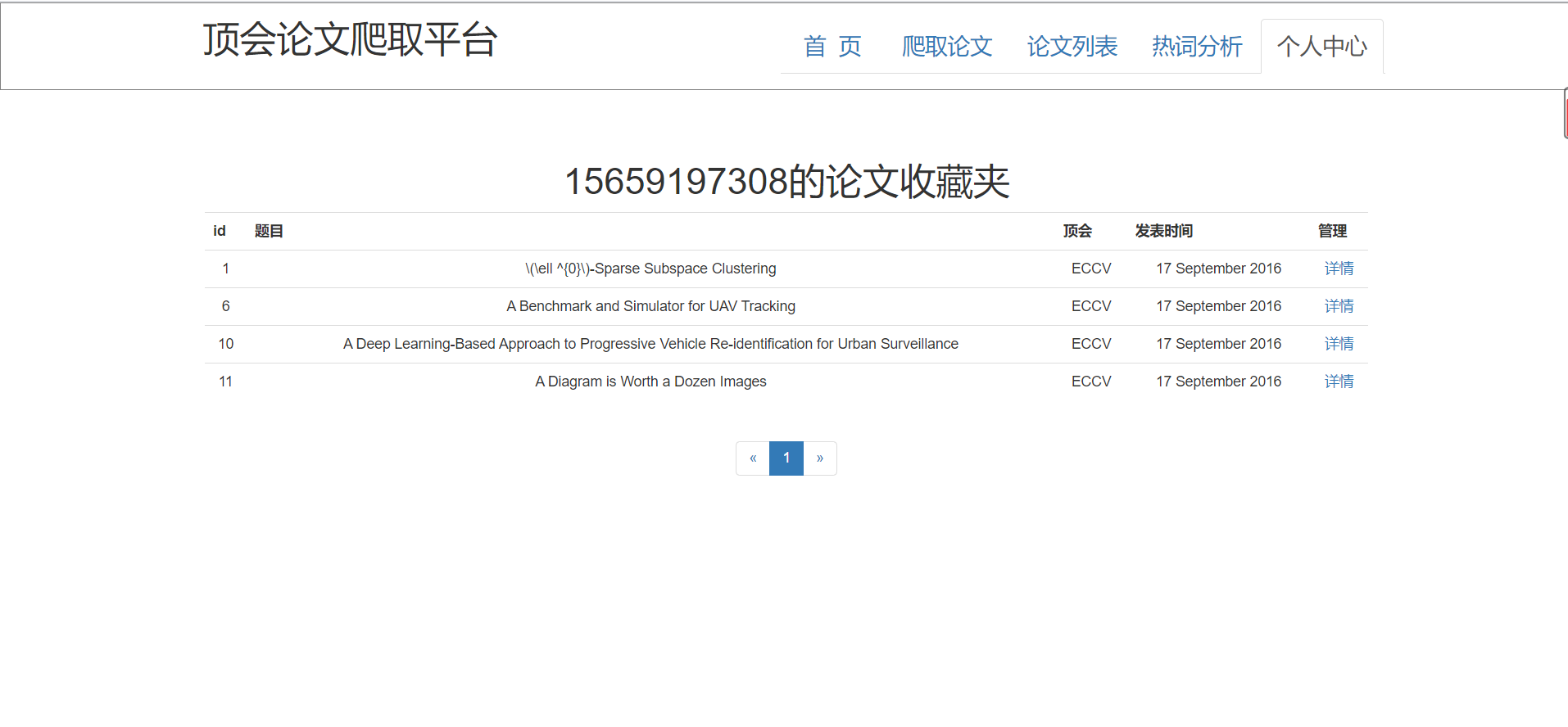
页面展示:在个人中心页可以观察到收藏的论文列表信息,点击可直接跳转详情页。
前后端交互:后端返回该用户收藏的论文
6、热词分析页:
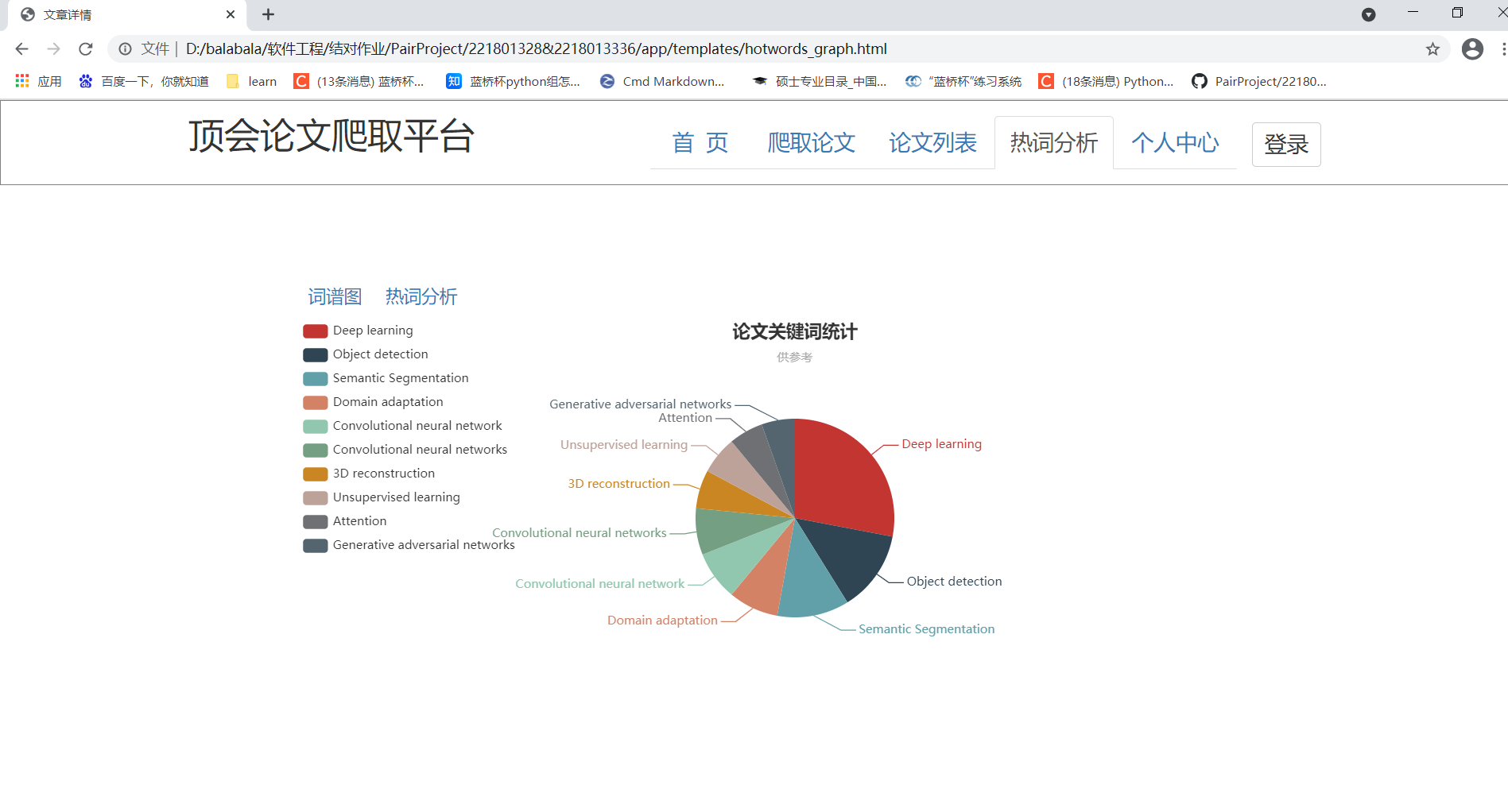
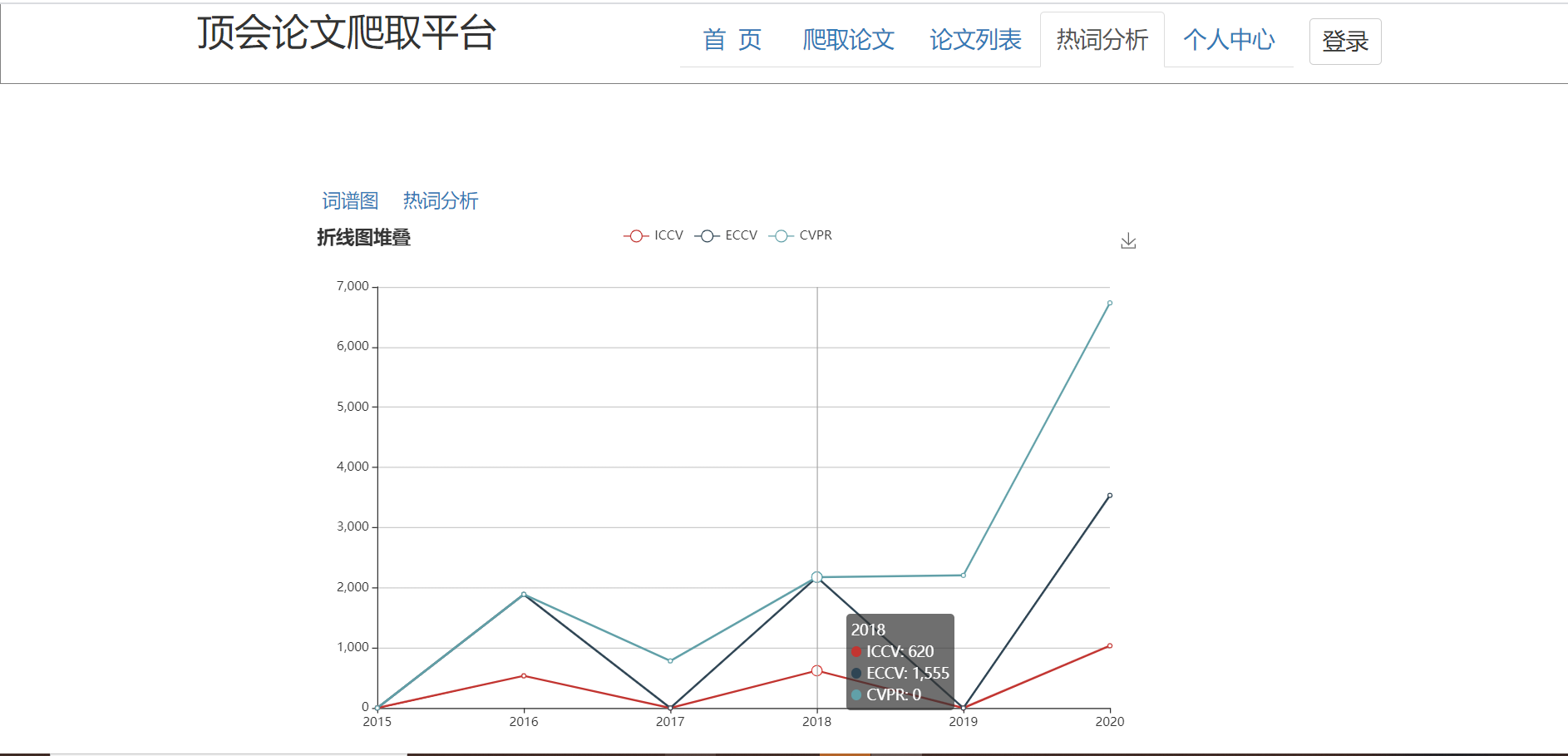
页面展示:返回热词前10的词语以及检索到的个数的json数组。用echarts展示出一个饼图,点击饼图的某一块可以跳转到论文查询页面,所点击的关键词自动填入搜索框,点击搜索即可显示出包含该关键词的论文列表。
前后端交互:
blingbling:如何处理分页功能!
前端传递相关数据以及需要展示的页数和每页需要多少项。
后端查询相关数据后返回总条数和该项数所需的总页数。
由前端实现分页。
结对讨论过程描述
作业要求发布以后,我们就开始讨论并确定了前后端的分工,一个人做前端,一个人做后端,等双方都写得差不多以后再进行前后端交互。因为cyh同学有python基础,所以负责后端,pzy同学想学习web前端,所以负责前端。
分工完成后,我们仔细地看了作业的要求,确定了这次的需求,由上次做原型的cyh同学对原型做了一些修改,接下来就开始对题目要求的功能逐个进行分析。我们对各个功能做了简单的分类,有一些功能是用已知的知识就能做的,有一些还要学习,所以在这以后我们前后端就分头去查找资料,学习需要使用的新技术了。
在编码的过程中,我们也对各个功能进行了更加深入的讨论,并相互沟通遇到的问题,遇到bug时前后端也可以互相帮忙解决。
开始进行前后端交互以后,我们主要采用当面沟通的讨论形式,因为我们是舍友,所以发现问题可以及时沟通,尽快解决。
结对截图
设计实现过程
功能结构图
后端设计实现过程
by.cyh(221801336)
0、pre在看到作业后和队友进行了一系列交流,明确了我后端flask开发,也明确了针对上次原型需求的更改,例如我们打算先放缓个人收藏附加功能的撰写,先完成老师提及的基本功能。在讨论过程中发现,之前的原型作业不太吻合网页的样式,故我用一个下午的时间重新修改了原型的基本样式,再由队友针对于UI进行修改。
1、设计数据库表以及表的连接。
在这一过程中,我发现一开始认为的数据库总是要根据后续需求的更改修改字段,会导致数据库迁移出错。故,一开始便要确定具体需求,并且在数据库中做相应的准备。在开发过程中发现的由于数据过大而更改字段属性也是这次发现的问题。
class User(db.Model):
__tablename__ = 'user'
id = db.Column(db.Integer,primary_key=True,autoincrement=True)
telephone = db.Column(db.String(11))
password = db.Column(db.String(30))
# def __str__(self):
# return "<User(telephone:%s,password:%s)>" % (self.telephone,self.password)
class Paper(db.Model):
__tablename__ = 'paper'
id = db.Column(db.Integer,primary_key=True,autoincrement=True)
numberID = db.Column(db.String(200))
title = db.Column(db.String(500))
keyWord = db.Column(db.String(500))
abstract = db.Column(db.String(10000))
datetime = db.Column(db.String(30))
href = db.Column(db.String(500))
classify = db.Column(db.String(20))
2、紧接着先根据获得的json数据进行解构导入数据库。但由于python识别的字符集并不存在utf8mb4该字符集,故在转换成二进制后导入数据库时会发现表情符的存在(\r\d\s...),这一错误导致我卡在导入json的环节很久。后续,为了节约开发时间,我先将ECCV导入进行数据测试。这一困难尚未找到解决办法。故在思考是否要进行爬虫的手段来填充数据库。
3、在导入数据库结束后,我开始着手撰写接口文档。先将功能划分出来,用户操作分为一个文件夹,论文列表展示及删除等分为一个文件夹,数据分析分为一个文件夹。暂时没有添加附加功能的接口。
4、在撰写接口的时候,发现有些地方在接口文档中表述的不清楚,但忘记及时修改,导致我的接口和文档是有误差的,给前端无形中加了很多工作。由于大部分笔墨都放在了数据库的增删改查中,我发现我对于原生sql语句的掌握非常不熟练,很多时候都需要请教队友才能完成。其他部分,由于python flask框架的便利性,我很迅速的就写完了接口并且测试完成了。但是由于测试的不完全,最后还是在前后端交互时发生了一些问题,所幸也都解决了。
5、前后端交互时我还没有学会部署,于是和队友进行了本地的交互。
6、我新增了个人收藏页接口的编写,并且开始学习爬虫。
7、部署
前端设计实现过程
by.pzy(221801328)
1、界面设计
使用HTML和CSS按照设计的原型来编写界面。使用好看的图片和bootstrap的样式以及自己调整CSS使界面变得美观。
2、数据保存
登陆状态和页面之间的数据传递使用到了localStorage
3、JavaScript编写
使用Vue.js中的指令简化JavaScript的编写,不需要再进行复杂的dom操作
4、前后端交互
前后端分离,前端使用axios发送网络请求,再结合一些vue的指令显示各种信息和列表。
5、图表
使用echarts实现,后端返回echarts需要的data[],前端收到数据后,把数据填到相应的位置从而展示出统计图表。
6、分页
由于论文很多,所以对论文列表进行分页,点击上一页、下一页和点击页码时会从后台查询到一页论文列表,显示到界面上。
代码说明
后端关键代码
采用python-flask框架开发,对于数据库的操作采用sqlalchemy的过滤器以及原生sql语句进行对数据库的增删改查。个人认为这次作业后端的核心在于对于论文列表查询后的数据如何以列表的形式展示给前端(论文展示)以及数据库中表的连接与查询(个人收藏)。
论文列表展示
前端传递page(请求的页数)和item(每个需要的项数)给后端,后端通过数据库查询(符合条件)的信息以
python {'count':counts, 'page':page, 'data': { "id": id, "title": title, "datetime": datetime, "classify": classify } }
这样的形式给前端。
对此后端的python代码如下:
paper1 = request.get_json()
page = int (paper1.get("page"))-1
# 第几页 每页几条
page_item = int(paper1.get("item"))
m = int(page * page_item)
print('select * from paper limit ' + str(m) + ',' + str(page_item) + ';')
paper = db.session.execute('select * from paper limit ' + str(m) + ',' + str(page_item) + ';')
论文模糊查询
python papers = db.session.execute('select * from paper where title like \'' + str1 + '\' limit ' + str(m) + ',' + str(page_item) + ';')
相较于上面的列表展示,模糊查询的难度就增加在了sql语句的撰写。
论文收藏
user_paper = db.Table('user_paper',
db.Column('user_id',db.Integer,db.ForeignKey('user.id'),primary_key=True),
db.Column('paper_id',db.Integer,db.ForeignKey('paper.id'),primary_key=True)
)
在数据库中建立user表和paper表的连接,以达到收藏的目的。在收藏时,通过如下代码进行数据库的添加。
前端关键代码
1、用户权限
登录之后才能访问爬取论文、论文列表、热词分析、个人中心页。
用localStorage.getItem记录登录状态,也给出登出功能。
<li><a :href="isLogin==0?'#':'add_articles.html'" @click="noPermission">爬取论文</a></li>
judgeLogin:function(){
var user = JSON.parse(localStorage.getItem('userid'));
console.log(user);
if(user!=null){
this.isLogin = 1;
}else{
this.isLogin = 0;
}
},
signOut:function() {
this.isLogin = 0;
},
2、分页
前端传递相关数据以及需要展示的页数和每页需要多少项。
后端查询相关数据后返回总条数和该项数所需的总页数。
点击上一页、下一页和点击页码时会发送网络请求,从后台查询到一页论文列表,显示到界面上。
getArticles:function(i=1) {
var flag = this.flag;
//alert(flag);
if(flag==0) {
var that = this;
if(i!='...')
this.pageNo = i;
axios
.post('http://127.0.0.1:5000/paper/list',
{
'page':i,
'item':this.pageSize
})
.then(function (response) {
//数据要分页显示
console.log(response.data);
let {count,data,page} = response.data;
that.lists = data;
that.pageTotal = page;
that.rows = count;
})
.catch(function (error) { // 请求失败处理
console.log(error);
});
switchPage:function(i) {
this.getArticles(i);
},
prePage:function() {
this.getArticles(--this.pageNo);
},
nextPage:function() {
this.getArticles(++this.pageNo);
},
3、统计图表
后端返回符合echarts的数据,再来设置一个点击事件,把点击的关键词传到论文列表页去,显示在搜索框中。
initChart:function(){
var that = this;
axios
.post('http://127.0.0.1:5000/keyword')
.then(function (response) {
that.hotwords = response.data.data.data;
that.drawChart();
})
......
},
drawChart:function(){
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('echart'));
......
series: [
{
......
data: this.hotwords,
......
})
//点击跳转
var that = this;
myChart.on('click',function(param){
var name = param.data.name;
localStorage.setItem('keyword', name);
window.location.href = "article.html";
})
}
4、vue列表显示
使用vue.js的v-for指令
<tr v-for="(v,i) in lists">
<td>{{ v.id }}</td>
<td>{{ v.title }}</td>
<td>{{ v.classify }}</td>
<td>{{ v.datetime}}</td>
<td><a @click="gotoDetail(v.id)">详情</a></td>
</tr>
心路历程和收获
cyh(221801336):
在这次作业中,我复习了之前学习但几乎快忘光了的python-flask框架,在数据库设计和具体接口撰写中又重新回顾了MySQL语句。虽然接口在交互前都有进行测试,但是由于文档没有及时更新和测试数据的不完善,导致交互时候花费了一部分时间来解决这个问题。然后发现前后端交互真的是个很费心费力的事情,由于我还不会部署,交互时还需要使用本地的环境去运行,无形中限制了很多东西。然后由于数据库导入的问题,我又去学习了爬虫。之前很早就有想过要学习这个,但是一直搁置,这次作业反而给了我一个契机,虽然可能也学不会。开发强度真的太大了呜呜呜……
pzy(221801328):
这次作业中,我充分使用了上学期学到的web知识来做出了web前端网页,让我感受到只学理论是不够的,还是要实践才能真实地掌握知识。这次的后端使用python,所以没有使用上学期学的前后端交互的知识,而是学习了vue.js和axios。使用新技术总是会出现一些问题,这就需要时间来解决这些问题,所以还是出现了时间不够的问题,前后端交互花了很多时间。总之,这次作业就是要用到什么就得学什么,写一两个功能基本上就会出现bug,就不断需要debug,一个一个地解决问题。
评价结对队友

cyh(221801336)对pzy:这次结对作业完成的过程中,我和队友进行了充分的沟通。但是由于作业的时间过急或者说未来开发项目给到的学习时间也不充分,导致了双方在沟通过程中遇到很多障碍。pzy同学在每次遇到障碍的时候都耐心的鼓励我,并且帮助我处理相关问题。pzy同学对于知识内部结构的深刻理解也使得我在遇到问题时积极去探寻底层问题。在和队友结对的过程中,我充分体会到了pzy同学的耐心与细心。
pzy(221801328)对cyh:cyh同学学习过python开发,负责了我们作业的后端,这使没有自己写过后端的我只要专心学习前端就可以了。在交流讨论的过程中,因为有了上一次结对的经验,我们沟通得很有效率,讨论问题的时候可以抓住重点,可以一步步地推进进度。在前后端交互的过程中,我们遇到了一些问题,解决这些bug离不开cyh同学很好的配合与协作。
