寒假作业2/2
| 这个作业属于哪个课程 | <2021春软件工程实践_W班 (福州大学)> |
|---|---|
| 这个作业要求在哪里 | <软工实践寒假作业2/2> |
| 这个作业的目标 | <1.阅读《构建之法》并提问2.完成词频统计个人作业> |
| 作业正文 | 见下方目录 |
| 其他参考文献 | 菜鸟教程-python学习 CSDN-fork与pull request CSDN-测试用例如何提高代码覆盖率 CSDN-python使用unnitest测试 CSDN-元典排序 知乎-计算机领域的大牛、大神们(包括历史上的以及现在的)有哪些奇闻轶事? |
GitHub地址:详情
作业基本信息 2021-3-3...
目录:
-
任务一
Question1-Chapter3软件工程师的成长
Question2-Chapter3软件工程师的成长
Question3-Chapter5
Question4-Chapter8需求分析
Question5-Chapter8需求分析
Question6-Chapter9项目经理
Question7-Chapter4两人合作
附加题 -
任务二
GitHub项目地址
PSP表格
解题思路描述
代码规范制定链接
设计与实现过程
性能改进
单元测试
异常处理说明
心路历程与收获
任务一
提问
Question1-Chapter3软件工程师的成长
我阅读了第三章关于初级软件工程师成长的5个小点(P49),对于其中的积累问题领域的知识和经验和提升职业技能这两点感触颇深,但对于同样成长的初级工程师如何去量化这两个方面的提升呢(作为学生)?还是说这样的积累是在工作岗位中不断累积最终形成职业的晋升呢?这两个点的掌握程度上级可以通过面试评估出来但作为学生的我们又需要如何去提升它们呢?
A:我个人认为初级软件工程师的成长有小部分在于学生阶段的培养,很大部分在于工作岗位中不断积累的能力。我更倾向于一种说法
在学校里学会学习的能力,在社会运用学习的能力。故此,有工作经验的人总归是更具有优势的,所以才提出来这一问题想知道在学校能否通过某些量化的方式去提升自己的职业素质。
Question2-Chapter3软件工程师的成长
我阅读了第三章练习与讨论中第四个问题。(如下图)我认为这是在程序开发过程中难以避免的问题,然而我们该 如何降低这种问题发生的频率 呢?(个人认为前期的面向对象分析与设计是很重要,可是没有投入到实际实践中空于理论一定是会产生偏差的。即使是我在完成学生成绩系统时,写到后面也会发现冗余的可能影响篇幅巨大的需要修改的地方。)

A:在设计前期先确立一个面向对象系统,然后进行评估测试,在设计出一个demo时通过调查问卷的形式修改系统设计。到后期如果依旧出现这个问题,还是选择重新设计再度修改,否则后期的新的修改可能会产生新的影响。希望能够有其他的回答方向…(再重新回来看认为这个问题有些钻空洞式的回答,毕竟无法去准确评估形势与情况)
Question3-Chapter5
我阅读了第五章对于团队模式的集中分类后,认为功能团队模式是最符合成熟的软件开发流程的,然而究竟是是团队创造项目还是项目主导团队,我依旧对此感到难以权衡。
A:等到团队成熟后应当是项目主导团队,因为懂得擅长之处能够快速高效;在团队初成立时还是应当遵循项目经理的规划走。之所以提出这个问题,是因为在一次赛前我与一位同学交谈,那个时候我们小组尚未确定选题,但是那位同学和我说其实是组长想要做什么项目为此去选择符合他的队员,最终得到一个适合这一项目的团队进行开发,让我思考了许久。
Question4-Chapter8需求分析
我阅读了第八章需求分析,在其中笔者提及调差问卷式的提问具有两个关键疏漏:实际答案并非我们所希望得到的答案(例:选择最喜欢的搜索引擎,用户给的回答可能是使用最频繁的)以及容易带有引导性。于是笔者引导我们去正确的设置调差问卷评估用户需求。然而个人以为,不论是一个新产品的问世还是一个新需求的呈现,无非都是具有极其强烈引导性的,因为我们要抓住用户的痛点,扩大化其痛点。与其不停的让痛点用户模糊的表述需求,似乎选择先行制造界面再引导用户修改效率更高?诚然,这样做会使得软件可能需要进行大规模修改,然后选择题和主观题是不是选择题更容易作答些。但换句话来说这两种方式皆有利有弊,个人偏向于先做demo再询问,私以为效率更高些。
A:已在问题中给出个人理解。
Question5-Chapter8需求分析
我阅读了第八章需求分析中的功能分析四象限,对于其中的杀手功能有一些疑惑。我曾经想要开发一个类似于收集衣服搭配的软件,然而在我的不断设想中(当时还没有接触产品学习)我所谓的功能在不断的增加,新的功能(虚拟试衣)会覆盖之前的功能成为“杀手功能”,可慢慢的我发现这一新出功能慢慢的成为了这个软件中篇幅最大的内容,或者说他的内容超过了原先我认为的用户痛点(也就是搭配模块)。如果出现这种情况我们又该如何应对呢?就像我们常说根据用户需求或是软件发展添加新功能后,慢慢地隐蔽了原先的亮点。一个软件功能的扩充是必不可少的,可如果失去了主次会不会就像没有初心的人逐渐丧失竞争力一般。
A:我个人认为在设计时如果有更冲击的思想点都可以再重新规划重点;如果确立中心了就不必再添加了。然而对这个问题还是请求助教老师能够给予我答复。
回顾这一问题后,我个人认为成熟的产品经理可能就能够合理的规避掉这一问题了。不懂得取舍,系统过于庞大没有重点,那这个软件也就没有了亮点,虽然提供了便捷。专且精才是迎合大众的点。但是不可置否,在未来软件成熟后一定会有系统化的增加功能的用户反馈,那么到那个时候该如何应对呢?
Question6-Chapter9项目经理
在小组开会的过程中,我们总是会抓住很小的但是重要的点讨论非常久的时间,但整个主流框架都没有讨论清楚,花大量的时间在重要的末流过多的浪费了开会的时间,作为项目经理该如何去规避这个问题发生的频率呢?
A:可能提前做好会议大纲会能够起到一些帮助,但还是不足以解决。本质上,开放式的思考回答与独断式的思考回答有利有弊,但针对于项目初期,这两种方式我并不能明确哪种方式更好。
Question7-Chapter4两人合作
在第四章中看到这句话
结对编程中驾驶员和领航员的角色要经常互换,避免长时间紧张工作而导致观察力和判断力下降?
在这句话中我联想到前后端的合作,是否前后端也需要适当的角色互换才能够更理解互相交流时的需求呢?在实际生活中似乎少见这种互换的发生。
A:可能加强沟通交流也可以起到相应效果。角色互换在生活中似乎很少见到。
附加题:大家知道了软件和软件工程的起源,请问软件工程发展的过程中有什么你觉得有趣的冷知识和故事?
来源:知乎

自我小结:在本次课程结束后回顾,你对你提出的问题是否有了新的理解?在实践的过程当中,你用到了哪些知识?
任务二-WordCount编程
一、GitHub项目地址:详情
二、PSP表格
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30+20(后又重新规划) |
| • Estimate | • 估计这个任务需要多少时间 | 60 | 60 |
| Development | • 开发 | 660 | 600 |
| • Analysis | • 需求分析 (包括学习新技术) | 90 | 120 |
| • Design Spec | • 生成设计文档 | 30 | 40 |
| • Design Review | • 设计复审 | 30 | 20 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 120 | 90 |
| • Design | • 具体设计 | 60 | 40 |
| • Coding | • 具体编码 | 60 | 40 |
| • Code Review | • 代码复审 | 60 | 90(寻求性能优化) |
| • Test | • 测试(自我测试,修改代码,提交修改) | 180 | 300 |
| Reporting | 报告 | 120 | 100 |
| • Test Repor | • 测试报告 | 90 | 90 |
| • Size Measurement | • 计算工作量 | 10 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1600 | 1630 |
解题思路描述
1.首先解决文件读入问题。先编写了一个打开文件并将文件内容输出到控制窗的函数,并测试通过。
2.编写函数框架,确立了几个计算文件行数、字符数、单词总数及输出文件单词前十的函数功能。
#启动WordCount
def count_file(file1,file2)
#读取文件内容并输出到控制台 该函数测试通过后已删除
#def read_file(filename)
#将字符串s输出到指定文件路径
def out_file(filename,s)
#清空指定文件内容
def clear_file(filename)
#统计文件的总字符数
def count_chars(file_name)
#计算文件中每一行的字符数
def count_line_chars(content)
#统计文件的有效行数
def count_lines(file_name)
#将文件内容转换为单词元组
def analy_word(file_name)
#统计文件的单词总数(对应输出第2行)
def count_word(file_name)
#统计文件中的各单词出现次数
def count_words(file_name)
3.填充函数。进一步复习python语法,然后根据相关函数补齐功能,并通过自定义的方式测试函数的正确率。
4.通过main函数进行测试,将需要输出的内容输出到控制窗中。编写一个input.txt作为测试用例。
5.将原本输出到控制窗的内容输出到output文件中。
6.将功能模块化,并进行相应的修改与性能提升。
7.进行测试。
8.回顾与总结。
代码规范制定链接
在代码规范制定时,我发现在整个程序书写完毕后最容易产生不匹配的便是空行和注释的填写。还没有养成良好的代码即写即加注释的习惯,需要继续努力。
设计与实现过程
将函数列举出来然后实现。
1.实现计算文件总字符数的函数的关键代码
通过将文件中的每一行内容通过转换成set函数形式然后计算该set的长度,最后添加。
#打开文件 将每行的字符数相加 然后返回字符串
with open(file_name,"r",encoding='utf-8') as file_obj:
for content in file_obj:
c_cs += count_line_chars(content)
#计算文件中每一行的字符数
result = 0
for i in set(content):
result = result + int(content.count(i))
2.实现计算文件有效行数的函数的关键代码
将文件的每一行通过strip函数将换行符'\n'切割下来,以避免计算了空行,然后通过len函数计算实际的有效行数。
#统计文件的有效行数
for line in f:
line = line.strip('\n')
if len(line) == 0:
continue
s += 1
3.实现提取文件词数的函数的关键代码
一开始我将计算单词总数和单词词频的函数分开来,后来复查代码时,为了提高函数速度提取出来。
通过compile函数和strip函数将文章中的单词划分好,再通过lower函数将其中单词最小化,用split函数将空格提取。在words元典中不断添加word,并且重新将words中重复的添加到一起。最后将words元典返回。
def analy_word(file_name):
words = {}
r = re.compile(r"[,!\*\.]")
with open(file_name, "r",encoding='utf-8') as f:
for line in f:
for word in r.sub("", line.strip()).lower().split(" "):
if word in words:
words[word] += 1
words.setdefault(word, 1)
return words
4.实现计算文章单词数量的函数的关键代码
将返回的words元典,通过sum函数将每个values时添加起来。
#统计文件的单词总数(对应输出第2行)
words = analy_word(file_name)
result = sum(words.values())
5.实现计算文章单词词频的函数的关键代码
将words元典采用lambda函数按values降序,按key降序排序。最后输出前十的单词数和出现次数。
#统计文件中的各单词出现次数
words = analy_word(file_name)
words2 = copy.deepcopy(sorted(words.items(), key=lambda k:(k[1],k[0]),reverse=True))
m = 0
s = ""
for i in words2:
if (m<10):
s += str(i[0])+":"+str(i[1])+"\n"
m+=1
性能改进
仔细查看了代码后认为能够提升性能的便是给字符排序的性能提升和录入字符的性能提升。录入字符可采用正则表达式进行分割(但在网络上查阅正则表达式尚不理解,写出来有bug存在故没有进行改动),字符排序采用快速排序替代冒泡排序,可提升性能。
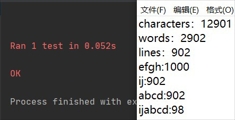
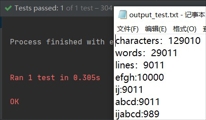
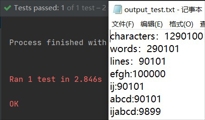
1.0个字符
2.10个字符
3.100个字符
4.1000个字符
5.10000个字符
6.100000个字符
7.1000000个字符
单元测试
1.实现统计文件字符数函数的测试
str内包含了特殊字符,测试了\t \r \n 三个字符的字符数皆为1。
def test_count_char(self):
str = "I have! a \t \r brother? \n"
...
#系统测试
WordCount.count_file(dir,"output_count_char.txt")
#单独测试
WordCount.clear_file("s_output_count_chars.txt")
WordCount.out_file("s_output_count_chars.txt",s)
2.实现统计文件行数函数的测试
测试了\t和\n的区别,以及有效行数的判断,若单纯为\t一行不包含其他字符,也默认为1行。
str = "hello\nworld\t\nwwwwI \thave! a \t \r brother? \naaaaa\n"
...
#系统测试
WordCount.count_file(dir,"output_count_line.txt")
#单独测试
WordCount.clear_file("s_output_count_line.txt")
WordCount.out_file("s_output_count_line.txt", s)
3.实现统计文件词数和词频的测试
测试了特殊字符是否会被记为单词。
str = "I have! a \t \r brother? \n He is four years older than me. "
WordCount.count_file(dir,"output_count_word.txt")
str = "I have a brother.have a brother. He is four years older than me. Now he is fifteen years old, and he is a student of Grade Nine. He is tall and handsome. His classmates like playing with him. He works hard in study. His teachers speak highly of him. Besides, basketball and running are his favorites."
#系统测试
WordCount.count_file(dir, "output_count_words.txt")
#单独测试
WordCount.clear_file("s_output_count_word.txt")
WordCount.out_file("s_output_count_word.txt", s)
WordCount.clear_file("s_output_count_words.txt")
WordCount.out_file("s_output_count_words.txt", s)
使用Coverage计算测试覆盖率:
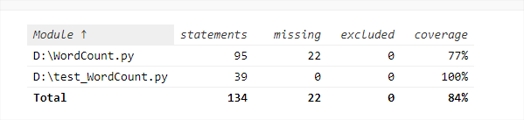
如何优化测试覆盖率:
通俗而言,采用完整业务流程进行测试,采用特定情况流程进行测试,要使得测试点覆盖所有流程就能够达到较高的覆盖率。函数本身有太多的文件打开异常判断,但由于文件打开异常判断无法提取到函数前方,因为文件打开异常有可能随时发生。其他由于字符串为空的判断是根据文件打开异常所写的,但由于打开异常便会自动结束程序所以也无法走到,应当修改这一块的代码。
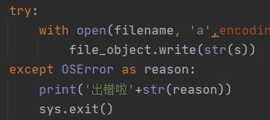
异常处理说明
由于暂时只考虑到文件打开异常和文件不存在异常。
采用try-except语句,当文件不存在时报出异常并终止程序。

心路历程与收获
1.重新温习了python基础语法,重点温习了文件输入输出相关函数。
2.针对出现的错误进行debug,然后发现很多错误出现在编码方式里,有python等级不够的问题也有python自身编码方式的问题,最终修改成功。gebug果然需要耐心与细心才能完成,中间通过百度、寻找同学进行帮助,最终终于解决bug。
3.针对几个函数的填充,我采用了python自带的相应函数。相比而言,python真的比其他语言代码长度简短清晰。
4.模块化的编码方式改变了我以往喜欢在main函数里“大刀阔斧”的排版方式,转变成精短的main函数构造,并且在测试文件中的引用也确实使得这个py文件能够广泛被调用。
5.单元测试模块不断地发现bug寻找解决方式,然后再发现bug…在这一模块中我发觉了前期规划的不够仔细,函数中的细微差错和编码方式问题。这种种问题令我不断的重新返工修改函数。在这一模块花费的时间与我想象中的差距很大,也让我真正的意识到测试的重要性,仅仅是一个小小的WordCount文件就需要我不断的返工修改,以达到相对的顺利,那么未来那些复杂的文件便更需要我们的“无差错”,更需要单元测试的完善与系统化。

