shell脚本学习(7)sort
1 sort的格式
sort [options] [files]
sort 参数 文件
2 参数 -t 用单个符char作为默认的字段分隔符, 默认字段分隔符是空白
参数-k 用来定义排序键值字段
一般是 -t分割好字段, 再在字段中
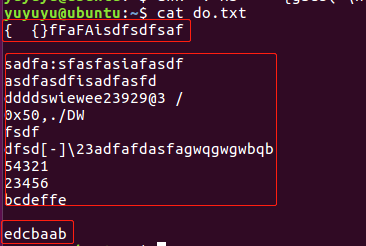
原始数据

t:说明原数据 按:分段
k1 说明指定字段1, 键值会从该字段的开始, 一直到字段结束而非字段的结尾。(也就是范围很大咯)
排序1 这种排序没看出是做什么用的
sort -t: -k1 /etc/passwd
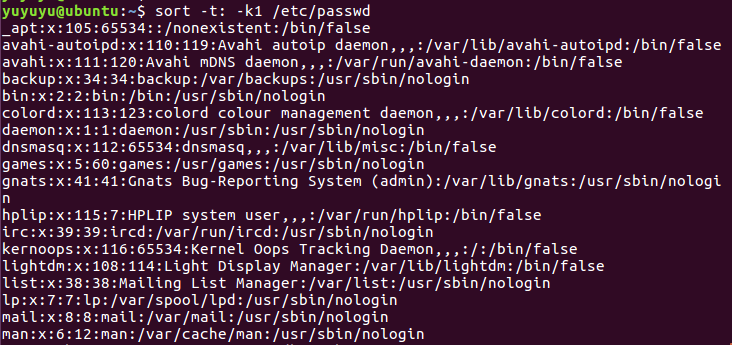
排序2 k用逗号修饰, 表示排序键值由第一个字段值的开始出开始, 结束于第二个字段的结尾位置
这里1,1 是说键值用第一个字段表示
sort -t: -k1,1 /etc/passwd
和上面的结果没差别,但理论上不同
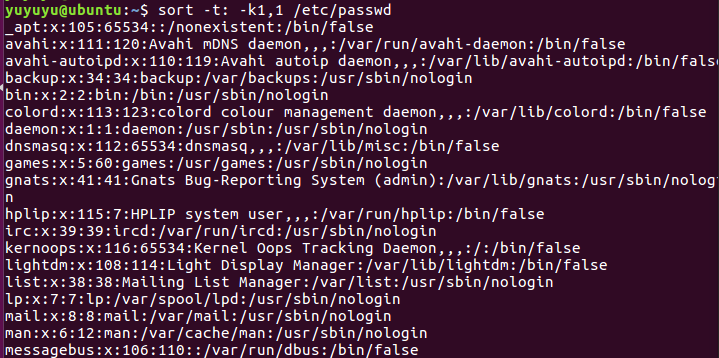
排序3 指定键值为第三段,并按数字比较,然后倒叙
sort -t: -k3,3nr /etc/passwd
k的修饰符 n 表示按照数字(整数)比较
k的修改符 r 表示按照倒置排序
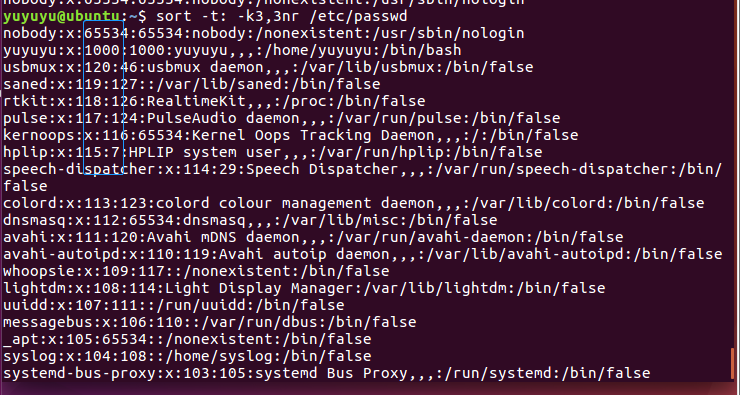
排序 4 先按字段4的整数排序, 再按字段3 的整数排序
通过写两个 -k 字段号,字段号n来实现
sort -t: -k4,4n -k3,3n /etc/passwd
比对这3组可以看出是先看第四字段排序了, 再按第三字段排
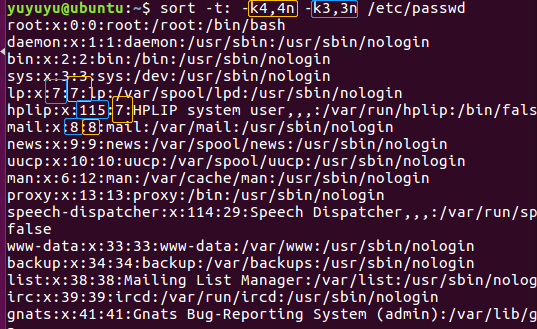
排序 5 只输出位置的排序记录,有点拗口, 就是比对的键值重复出现
sort -t: -k4,4n -u /etc/passwd
比如这个时候就没有两行都带7的了。

排序6 文本块排序
地址和清单, 多行文字当做一个数据块的文本块排序
使用awk gsub配合RS变量(输入数据记录分隔符) ORS变量(输出数据记录分隔符)处理
比如想按这三段来排序
awk -v RS="" '{gsub("\n", "^Z"); print}' do.txt
RS=""把记录按空行隔开
gsub()函数, 能把"\n" 替换成 “^z” 这样输入的问题就被处理了, 接下来只要排序这三行, 最后还原被替换的数据就可以了。

awk -v RS="" '{gsub("\n", "^Z"); print}' do.txt | sort -f
用sort -f不区分字母大小的排序

awk -v RS="" '{gsub("\n", "^Z"); print}' do.txt | sort -f | awk -v ORS="\n\n" '{gsub("^Z", "\n"); print}'
在行和行之间加\n换回原来的格式
ORS=“\n\n” 保持用空白行分割输出记录, 如果只写一个"\n" 效果就作文一样的 ,一行一行没分割的效果。

冒泡 插入 快排少量数据时处理速度都还好,大数据时几乎是n^2
sort排序执行时间和记录的数量成正比, 有被优化调整, 可以省下学排序算法的时间。
稳定性:相同的记录输入顺序,是否在输出是也可以保持原状, sort这方面不稳定, 要加--statble弥补
7 sort的删除重复操作:
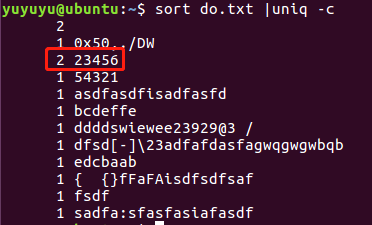
配合uniq -c 计数唯一的, 显示重复的次数
sort do.txt |uniq -c
原始数据:
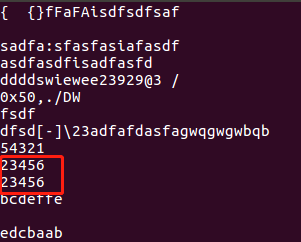
用uniq -c的
显示重复的字段
sort do.txt |uniq -d
-d的功能:只显示重复的数据

显示未重复的字段
sort do.txt |uniq -u
-u的功能:显示未重复的数据



 浙公网安备 33010602011771号
浙公网安备 33010602011771号