
博客作业2---线性表
一、PTA实验作业
题目一:7-1 最长连续递增子序列
1.设计思路
定义n表示顺序表长度,a[n]暂存保存元素,b[n]保存对应元素的递增子序列
List L;
申请空间后将数组元素存于顺序表L;
定义i,j,k=0,num=1;num表示子序列长度,至少为1;
for i=0 to n-1{ 遍历每个元素,求其递增序列
for j=i to n-1{
if(L->data[j+1]>L->data[j]) num++;
else break;
}
b[k++]=num; num=1; 将长度存于数组,重新将num赋值为1
}
找出b[n]中的最大值max,并记录其下标存于x;
for j=x to max+x-1
输出在该区间的元素,即最长子序列;
end;
2.代码截图

3.PTA提交列表说明

- 一开始编译器选错了,导致编译错误;之后对递增子序列理解错误,本身应该算一个,将num的初值该为1; 最后部分正确是最大n的点过不去,将Maxsize的值由100000该为1000000,提交正确。
题目二:6-3 jmu-ds-链表倒数第m个数
1.设计思路
定义指针p=L,q=L,定义e保存倒数m个元素
判断m是否大于0 否return-1;
for i=0 to m 让p走m个节点
p=p->next; 若p为空 return-1;
while(p){ 让p走到尾节点
p=p->next;
q=q->next;
}
e=q->data;
return e;
end
2.代码截图

3.PTA提交列表说明
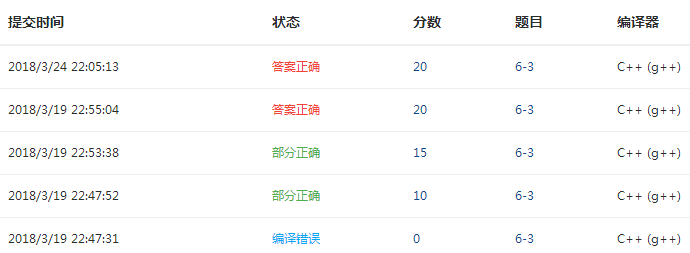
- 没有对m的合理性和指针是否为空进行判断导致部分正确。
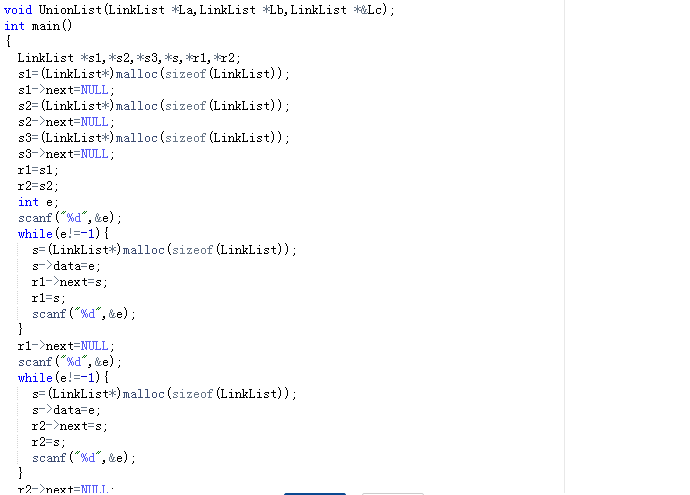
题目三:7-1 两个有序链表序列的合并
1.设计思路
合并链表的函数:
定义指针pa=L->next,pb=L->next,指针r和s用于插入操作
动态申请Lc空间;
r=Lc;
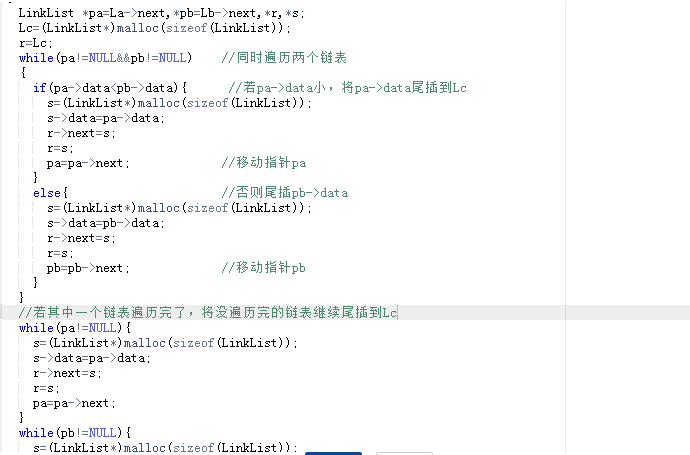
while(pa!=NULL&&pb!=NULL)
{
if(pa->data<pb->data){ 将pa->data尾插到Lc
s=(LinkList*)malloc(sizeof(LinkList));
s->data=pa->data;
r->next=s;
r=s;
pa=pa->next;
}
else{
将pb->data尾插到Lc;
pb=pb->next;
}
}
若其中一个链表遍历完了,将没遍历完的链表继续尾插到Lc
while(pa!=NULL)
{
将pa->data尾插到Lc;
pa=pa->next;
}
while(pb!=NULL)
{
将pb->data尾插到Lc;
pb=pb->next;
}
r->next=NULL;
end
2.代码截图
3.PTA提交列表说明
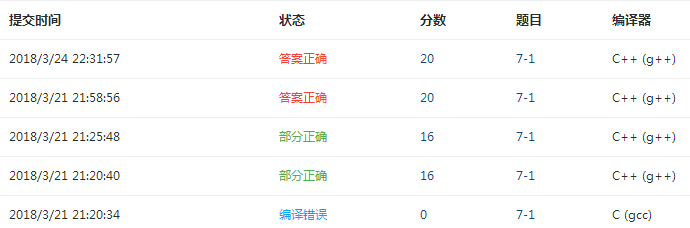
- 链表输出函数写错了导致部分正确。
二、截图本周题目集的PTA最后排名
1.顺序表PTA排名

2.链表PTA排名
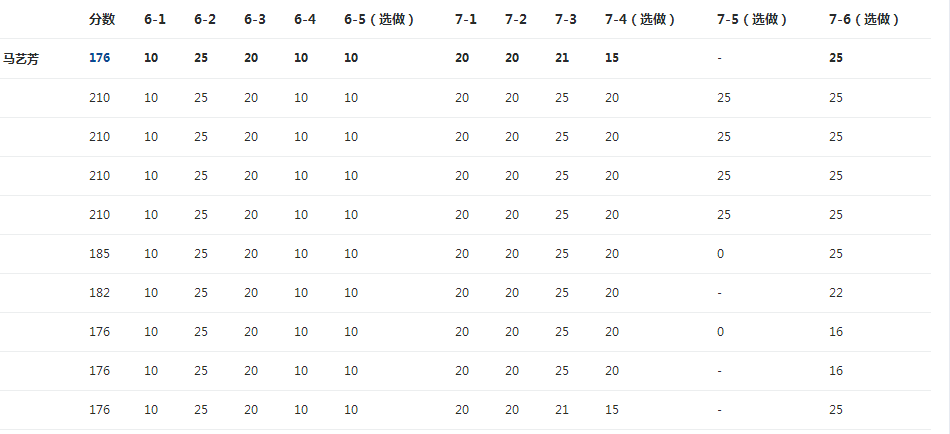
3.我的总分:
236
三、本周学习总结
1.谈谈你本周数据结构学习时间是如何安排,对自己安排满意么,若不满意,打算做什么改变?
- 感觉在数据结构花的时间还是偏少,主要就安排时间做PTA的题目和预习作业,课外就很少安排看书什么的,显然时间安排上有点不合理,之后会适当调整吧,多挤时间去看看书本,巩固一些理论知识和基础知识,也可以学学代码风格。
2.谈谈你对线性表的认识?
- 我觉得线性表是一种很有效的存储数据的结构,特别是链表,很灵活,有利于保存数据,但是理解和应用起来是真的不容易。
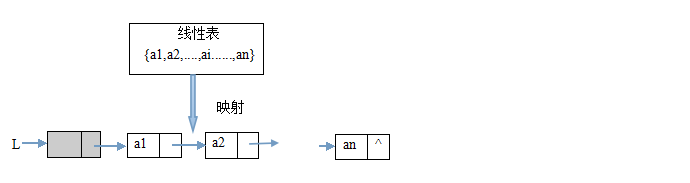
- 线性表:零个或多个相同特性的数据元素的有限序列。首先它是一个序列,元素之间是有顺序 的,第一个元素无前驱,最后一个元素无后继,其他的都有且只有一个前驱和后继。而所有元素按这种1对1的邻接关系构成的整体就是线性表。 线性表有顺序表和链式两类存储结构
- 顺序表:把线性表中的所有元素按照其逻辑顺序,依次存储到从计算机存储器中指定存储位置开始的一块连续的存储空间,如下图所示,即用一维数组来实现顺序表。
![]()
顺序存储结构中只需存放元素自身的信息,因此,存储密度大,空间利用率高;还有就是元素位置可以用元素的下标通过简单的解析式计算出来,所以可以随机存储。这都是顺序表的优点,但是在顺序表,元素的插入和删除运算需要移动许多其他元素的位置,一些长度变化较大的线性表必须按最大需要的空间分配储存。所以在使用线性表时,在选择顺序存储还是链式存储时,可以根据线性表是否很少进行插入和删除操作,或者插入和删除操作总是在尾部进行时,就可以依次为依据选择。 - 链表:在链式存储结构中,每个结点用于存储线性表的一个元素,每个结点不仅包含有所存元素本身的信息(称之为数据域),而且包含有元素之间逻辑关系的信息,即前驱结点包含有后继结点的地址信息,这称为指针域,这样就可以通过前驱结点的指针域方便地找到后继结点。链表由多个结点组成,这些结点的地址可以是连续,也可以不连续,这就是说这些数据元素可以存储在内存中未被占用的任意位置。链表由如下几种形式:
(1)单链表:在每个结点中包含有数据域外,只设置一个指针域,用于指向其后继结点,如图
![]()
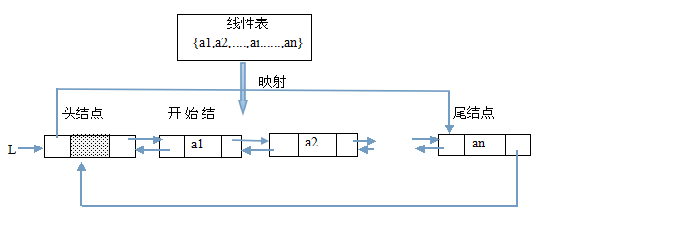
(2)双链表:在每个结点中包含有数值域外,设置有两个指针域,分别用于指向其前驱结点和后继结点。如图
![]()
(3)循环链表:循环链表是另一种形式的链式存储结构。它的特点是表中尾结点的指针域不变,而是指向表头结点,整个链表形成一个环,如下图
循环单链表:
![]()
循环双链表:
![]()
链表的特点:由于每个继节点带有指针域,因此在存储空间上比顺序表要付出较大的代价,所以顺序表比链表的存储密度高。还有链表不具有顺序表的随机存取特点,但在链表中插入或删除操作时,只需修改相关节点的指针域即可,不需要移动节点。



3.代码Git提交记录截图

四、阅读代码
struct student *BubbleSort (struct student *head)
{
struct student *endpt; //控制循环比较
struct student *p; //临时指针变量
struct student *p1,*p2;
p1 = (struct student *) malloc (LEN);
p1->next = head;
head = p1;
for (endpt = NULL; endpt != head; endpt = p)
{
for (p = p1 = head; p1->next->next != endpt; p1 = p1->next)
{
if (p1->next->num > p1->next->next->num)
{
p2 = p1->next->next;
p1->next->next = p2->next;
p2->next = p1->next;
p1->next = p2;
p = p1->next->next;
}
}
}
p1 = head;
head = head->next;
free (p1);
p1 = NULL;
return head;
}
- 这是在网上找的链表的冒泡排序法,相比一般的排序方法比较简洁,其中它增加一个节点p1->next = head,放在第一个节点的前面,主要是为了便于比较。因为第一个节点没有前驱,我们不能交换地址,让head指向p1节点,排序完成后,我们再把p1节点释放掉,如果前面的节点键值比后面节点的键值大,则交换,最后把p1的信息去掉,让head指向排序后的第一个节点,释放p1,p1置为NULL,保证不产生“野指针”,即地址不确定的指针变量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号