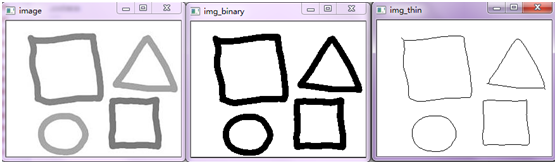
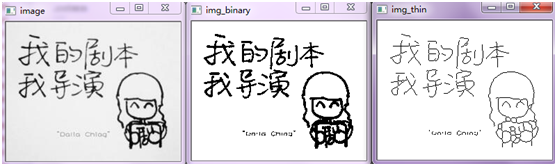
Python - 图像的细化(骨架抽取)
1、简介
图像的细化主要是针对二值图而言。
所谓骨架,可以理解为图像的中轴,一个长方形的骨架,是它的长方向上的中轴线。
圆的骨架是它的圆心,直线的骨架是它自身,孤立点的骨架也是自身。
2、骨架的获取
骨架的获取主要有两种方法:
(1)基于烈火模拟
设想在同一时刻,将目标的边缘线都点燃,火的前沿以匀速向内部蔓延,当前沿相交时火焰熄灭,火焰熄灭点的结合就是骨架。
(2)基于最大圆盘
目标的骨架是由目标内所有内切圆盘的圆心组成。
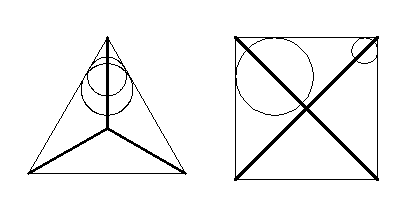
我们来看看典型的圆形的骨架(用粗线表示)。
细化的算法有很多种,但比较常用的算法是查表法。
细化是从原来的图中去掉一些点,但仍要保持原来的形状。
实际上是保持原图的骨架。
判断一个点是否能去掉是以8个相邻点(八连通)的情况来作为判断依据的,具体判断依据为:
1.内部点不能删除
2.鼓励点不能删除
3.直线端点不能删除
4.如果P是边界点,去掉P后,如果连通分量不增加,则P可删除
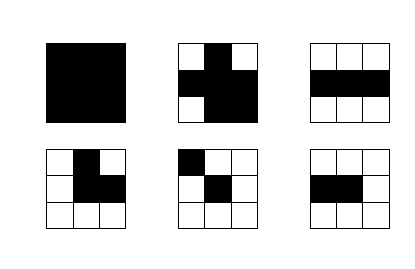
看看上面那些点,就是3*3矩阵中的中心点:
第一个点不能去除,因为它是内部点
第二个点不能去除,它也是内部点
第三个点不能去除,删除后会使原来相连的部分断开
第四个点可以去除,这个点是骨架
第五个点不可以去除,它是直线的端点
第六个点不可以去除,它是直线的端点
对于所有的这样的点,我们可以做出一张表,来判断这样的点能不能删除
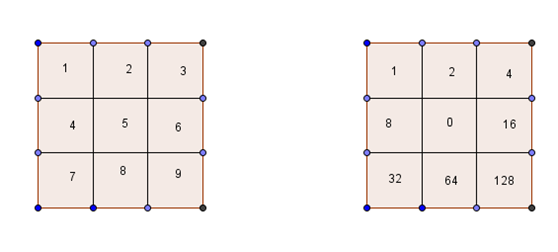
我们对于黑色的像素点,对于它周围的8个点,我们赋予不同的价值,若周围是黑色,我们认为其价值为0,为白色则取九宫格中对应的价值。对于前面那幅图中第一个点,也周围的点都是黑色,所以它的总价值是0,对应于索引表的第一项,前面那幅图中第二点,它周围有三个白色点,它的总价值为1+4+32=37,对应于索引表中第三十八项。
我们用这种方法,把所有点的情况映射到0-255的索引表中
我们扫描原图,对于黑色的像素点,根据周围八点的情况计算它的价值,然后查看索引表中对应项来决定是否要保留这一点。
3、代码实现
#! /usr/bin/env python3 # -*- coding:utf-8 -*- # Author : Ma Yi # Blog : http://www.cnblogs.com/mayi0312/ # Date : 2020-04-24 # Name : test02 # Software : PyCharm # Note : 骨架抽取 import cv2 import copy # 映射表 g_array = [0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0] def thin(img): """ 细化函数,根据算法,运算出中心点的对应值 :param img: 需要细化的图片(经过二值化处理的图片) :return: """ h, w = img.shape i_thin = copy.deepcopy(img) for i in range(h): for j in range(w): if img[i, j] == 0: a = [1] * 9 for k in range(3): for l in range(3): if -1 < (i - 1 + k) < h and -1 < (j - 1 + l) < w and i_thin[i - 1 + k, j - 1 + l] == 0: a[k * 3 + l] = 0 i_sum = a[0] * 1 + a[1] * 2 + a[2] * 4 + a[3] * 8 + a[5] * 16 + a[6] * 32 + a[7] * 64 + a[8] * 128 i_thin[i, j] = g_array[i_sum] * 255 return i_thin def to_binary(img): """ 二值化函数,阈值根据图片的昏暗程序自己设定 :param img: 需要二值化的图片 :return: """ w, h = img.shape i_two = copy.deepcopy(img) for i in range(w): for j in range(h): if img[i, j] < 200: i_two[i, j] = 0 else: i_two[i, j] = 255 return i_two # 入口函数 if __name__ == '__main__': # 读取图片,并显示 image = cv2.imread("1.jpg", 0) img_binary = to_binary(image) img_thin = thin(img_binary) cv2.imshow("image", image) cv2.imshow("img_binary", img_binary) cv2.imshow("img_thin", img_thin) cv2.waitKey(0)
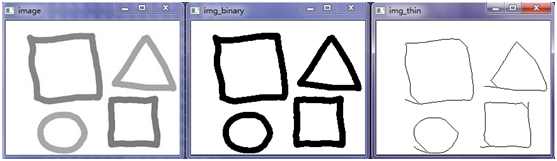
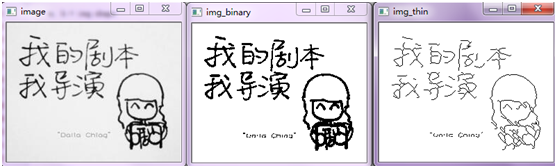
效果不是很好,来看一个最简单的事例:
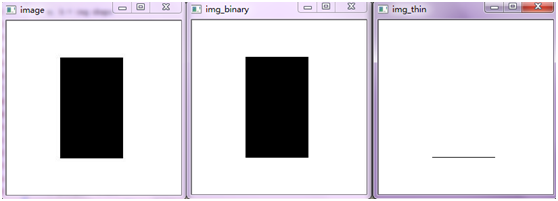
按照前面的分析,我们应该得到一条竖着的线,但实际上我们得到了一条横线。
我们在从上到下,从左到右扫描的时候,遇到第一个点,我们查表可以删除,遇到第二个点,我们查表也可以删除,整个第一行都可以删除。
于是我们查看第二行时,和第一行一样,它也被整个删除了。这样一直到最后一行,于是我们得到最后的结果是一条直线。
解决的办法是:
在每行水平扫描的过程中,先判断每一点的左右邻居,如果都是黑点,则该点不做处理。另外,如果某个黑点被删除了,则跳过它的右邻居,处理下一点。对矩形这样做完一遍,水平方向会减少两像素。然后我们再改垂直方向扫描,方法一样。
这样做一次水平扫描和垂直扫描,原图会“瘦”一圈,多次重复上面的步骤,直到图形不在变化为止。
这一改进让算法的复杂度的运行时间增大一个数量级:
#! /usr/bin/env python3 # -*- coding:utf-8 -*- # Author : Ma Yi # Blog : http://www.cnblogs.com/mayi0312/ # Date : 2020-04-24 # Name : test02 # Software : PyCharm # Note : 图像抽取骨架 import cv2 import copy # 映射表 l_array = [0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0] def v_thin(img): """ 细化函数,根据算法,运算出中心点的对应值 :param img: 需要细化的图片(经过二值化处理的图片) :param array: 映射矩阵array :return: """ h, w = img.shape i_next = 1 for i in range(h): for j in range(w): if i_next == 0: i_next = 1 else: i_m = int(img[i, j - 1]) + int(img[i, j]) + int(img[i, j + 1]) if 0 < j < w - 1 else 1 if img[i, j] == 0 and i_m != 0: a = [0] * 9 for k in range(3): for l in range(3): if -1 < (i - 1 + k) < h and -1 < (j - 1 + l) < w and img[i - 1 + k, j - 1 + l] == 255: a[k * 3 + l] = 1 i_sum = a[0] * 1 + a[1] * 2 + a[2] * 4 + a[3] * 8 + a[5] * 16 + a[6] * 32 + a[7] * 64 + a[8] * 128 img[i, j] = l_array[i_sum] * 255 if l_array[i_sum] == 1: i_next = 0 def h_thin(img): """ 细化函数,根据算法,运算出中心点的对应值 :param img: 需要细化的图片(经过二值化处理的图片) :param array: 映射矩阵array :return: """ h, w = img.shape i_next = 1 for j in range(w): for i in range(h): if i_next == 0: i_next = 1 else: i_m = int(img[i -1, j]) + int(img[i, j]) + int(img[i + 1, j]) if 0 < i < h - 1 else 1 if img[i, j] == 0 and i_m != 0: a = [0] * 9 for k in range(3): for l in range(3): if -1 < (i - 1 + k) < h and -1 < (j - 1 + l) < w and img[i - 1 + k, j - 1 + l] == 255: a[k * 3 + l] = 1 i_sum = a[0] * 1 + a[1] * 2 + a[2] * 4 + a[3] * 8 + a[5] * 16 + a[6] * 32 + a[7] * 64 + a[8] * 128 img[i, j] = l_array[i_sum] * 255 if l_array[i_sum] == 1: i_next = 0 def xi_hua(img, num=10): for i in range(num): v_thin(img) h_thin(img) return img def to_binary(img): """ 二值化函数,阈值根据图片的昏暗程序自己设定 :param img: 需要二值化的图片 :return: """ w, h = img.shape i_two = copy.deepcopy(img) for i in range(w): for j in range(h): if img[i, j] < 200: i_two[i, j] = 0 else: i_two[i, j] = 255 return i_two # 入口函数 if __name__ == '__main__': # 读取图片,并显示 image = cv2.imread("1.jpg", 0) img_binary = to_binary(image) cv2.imshow("image", image) cv2.imshow("img_binary", img_binary) img_thin = xi_hua(img_binary) cv2.imshow("img_thin", img_thin) cv2.waitKey(0)
运行的效果: