1).spark开发环境准备
1.创建 Maven 项目
2.增加 Scala 插件
3.新建scala object
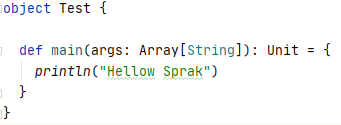
控制台输出

说明环境准备ok
2).WordCount
1.添加依赖关系
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
2.测试spark环境
报错
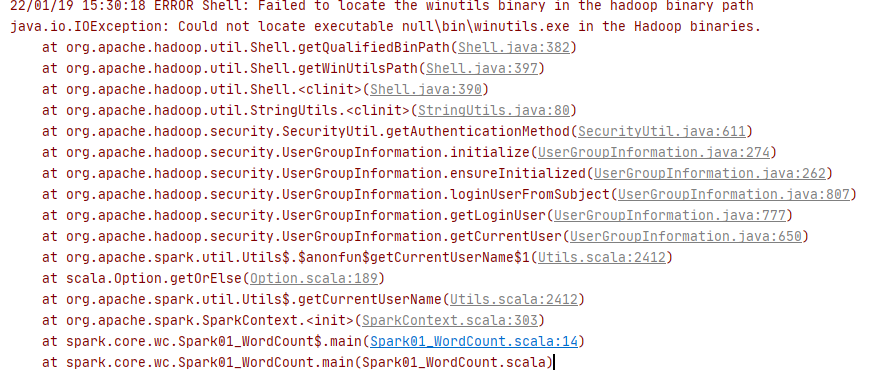
解决方法
下载winutils,配置HADOOP_HOME环境变量
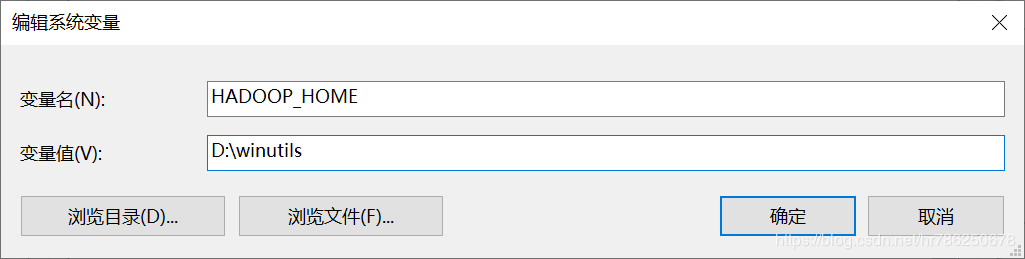
编辑PATH
重启电脑
3.执行业务操作
// TODO 执行业务操作
//1. 读取文件,获取一行一行的数据
// hellow world
val lines: RDD[String] = sc.textFile("data")
//2. 将一行的数据进行拆分,形成一个一个的单词(分词)
// 扁平化:将整体拆分成个体的操作
// “hello world" => hello, world, hello, world
val words: RDD[String] = lines.flatMap(_.split(" "))
//3. 将数据按照单词进行分组,便于统计
// (hello, hello, hello), (world, world)
val wordGroup: RDD[(String, Iterable[String])] = words.groupBy(word => word)
//4. 对分组后的数据进行转换
// (hello, hello, hello), (world, world)
// (hello, 3), (world, 2)
val wordToCount = wordGroup.map {
case ( word, list ) => {
(word, list.size)
}
}
//5. 将转换结果采集到控制台打印出来
val array: Array[(String, Int)] = wordToCount.collect()
array.foreach(println)
data文件夹包含1.txt和2.txt,内容均为

运行结果为

正确


