
记一次Master节点内存爆炸
现象
某天某日突然测试环境计算节点Master内存爆炸,计算引擎参考 如何实现动态指标实时计算
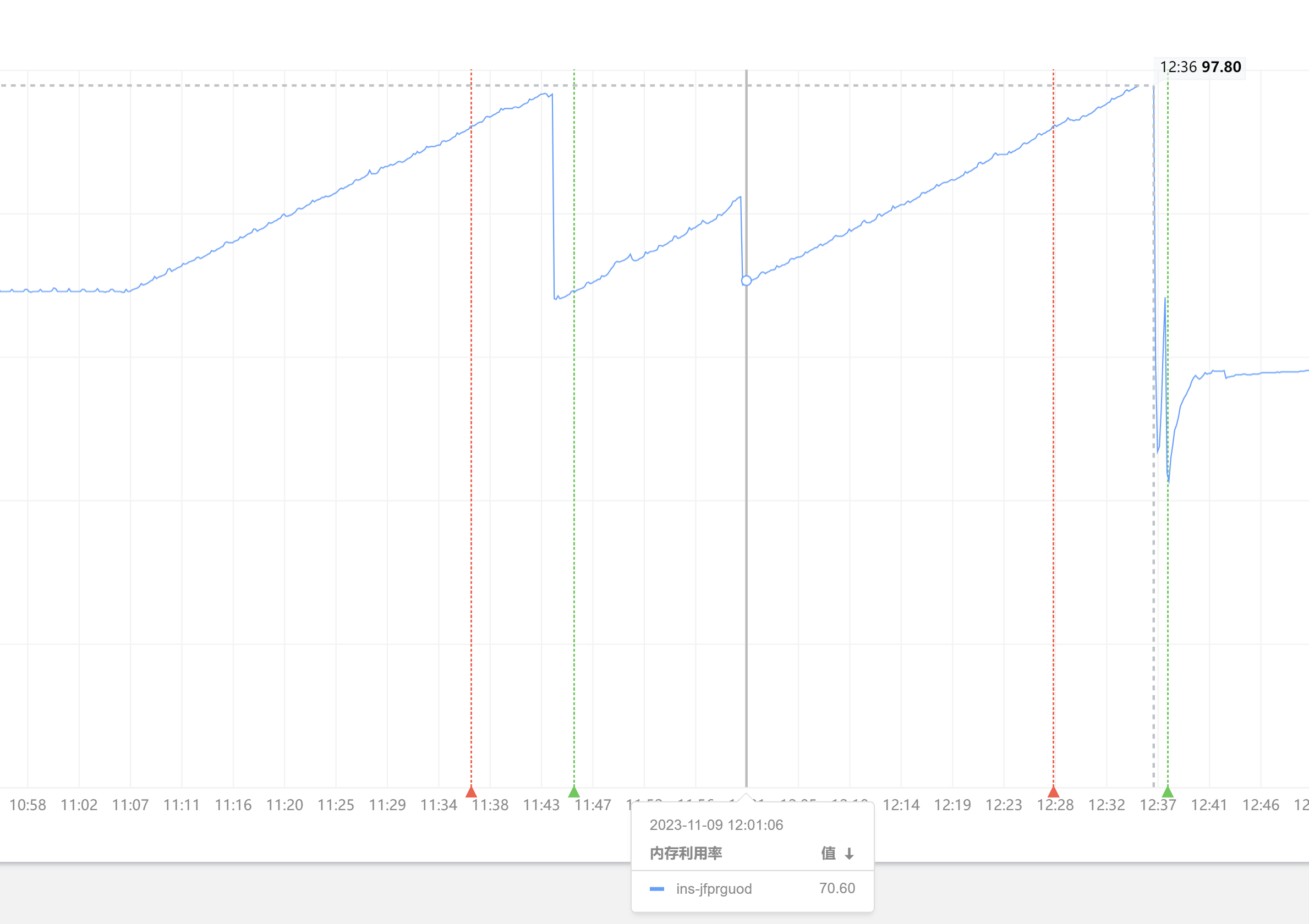
快速诊断
前置小知识
回顾一下指标范式,以及Master工作范围:

● Master 包含一些模块:
- Guard 统一信息入口,将信息传递给Dispatch,当保存完毕后,返回结果,确保信息不丢失。
- Dispatch 负责获取并解析规则,指标依赖解析,状态保存与恢复。
- Schedule 负责指标调度,以及Node状态维护等
当前实时指标组织关系: 规则-组-指标集-指标
变更锁定
通过报警故障时间锁定,测试环境刚上了一个新规则,符合表象。大致有了结论:指标血缘是通过DAG解析维护,是可能存在循环引用的,这样才能内存无限上升。(环路检测当时是放在调度时检测的,单个规则几百个指标很常见,检测成本太大,就关了。)
理想方案
针对当前规则所有指标进行环路检测,找出环路点(参考经典code,两条链路相交)。然后写了三行代码,顿时不知道如何下手:
- 数据库取出来不是LinkNode
- 根本没有头节点
- 也无法确认是多少个指标组成环路
顿了顿,换个思路,才几百个指标,单个指标引用应该不可能超过1000,那么可以找到问题点,再进一步排查,这样代码立马上来,参考如下:
def get_metric(self):
rule = Rule.objects.filter(uk_name='my_rule').first()
groups = rule.groups.all()
counter = defaultdict(int)
for g in groups:
for metric in g.metrics.all():
counter[metric] += 1
tmp = copy.deepcopy(set(counter.keys()))
while tmp:
fathers = set()
for m in tmp:
for f in m.fathers.all():
counter[f] += 1
fathers.add(f)
tmp = fathers
# 打印引用最多的
flag = max(counter.values())
arr = list(counter.items())
res = sorted(arr, key=lambda x: x[1], reverse=True)
print('now flag', len(tmp), res[:3])
if flag > 1000:
import pdb;
pdb.set_trace()
查看输出:
now flag 8 [...]
now flag 8 [...]
now flag 8 [...]
一直持续稳定8个指标,直到阈值进入断点,直接打印出来tmp,看一眼,立马破案。
总结
追求极致的工匠精神是进步的关键,但不可死板,用其他算法快速定位解决问题才是活学活用的表现。事后时间充裕,再慢慢优化检测算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号